
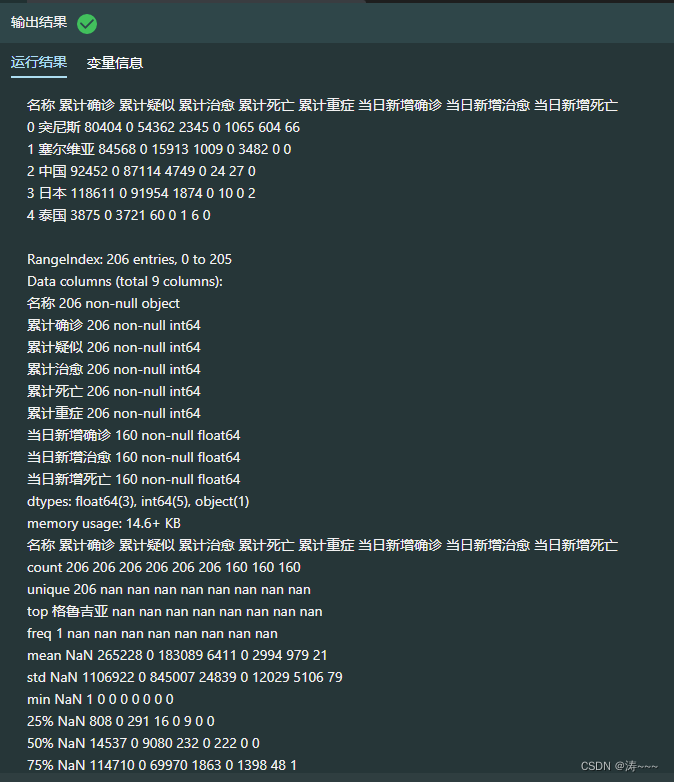
2.2 读取世界各国当日数据
import chardet
import pandas as pd
# 查看文件编码格式
with open('./today_world.csv', 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
# 数据读取
today_world = pd.read_csv("./today_world.csv",encoding=encoding)
# 展示前5行数据
print(today_world.head())
# 查看数据的基本信息
today_world.info()
# 查看数据的描述性统计信息
today_world_des = today_world.describe(include='all')
print(today_world_des)
2.3 计算各国当日现存确诊人数
import pandas as pd
# 计算当日现存确诊
today_world['当日现存确诊'] = today_world['累计确诊']-today_world['累计治愈']-today_world['累计死亡']
today_world.head()

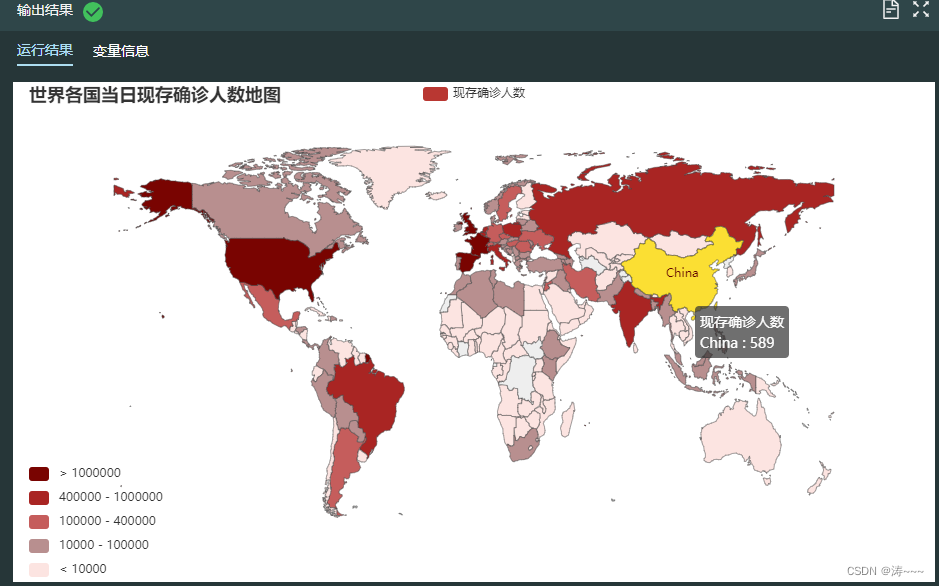
2.4 绘制当日现存确诊人数世界地图
# 将国家中文名称映射为英文名称
today_world['英文名称'] = today_world['名称'].replace(country_name['中文'].values,country_name["英文"].values)
# 获取嵌套列表数据
heatmap_data = today_world[['英文名称','当日现存确诊']].values.tolist()
import pyecharts
# 调整配置项
import pyecharts.options as opts
# Map类用于绘制地图
from pyecharts.charts import Map
# 绘制地图
map_ = Map().add(series_name = "现存确诊人数", # 设置提示框标签
data_pair = heatmap_data, # 输入数据
maptype = "world", # 设置地图类型为世界地图
is_map_symbol_show = False # 不显示标记点
)
# 设置系列配置项
map_.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示国家(标签)名称
# 设置全局配置项
map_.set_global_opts(title_opts = opts.TitleOpts(title="世界各国当日现存确诊人数地图"), # 设置图标题
# 设置视觉映射配置项
visualmap_opts = opts.VisualMapOpts(pieces=[ # 自定义分组的分点和颜色
{"min": 1000000,"color":"#800000"}, # 栗色
{"min": 400000, "max": 1000000, "color":"#B22222"}, # 耐火砖
{"min": 100000, "max": 400000,"color":"#CD5C5C"}, # 印度红
{"min": 10000, "max": 100000, "color":"#BC8F8F"}, # 玫瑰棕色
{"max": 10000, "color":"#FFE4E1"}, # 薄雾玫瑰
],
is_piecewise = True)) # 显示分段式图例
map_.render()
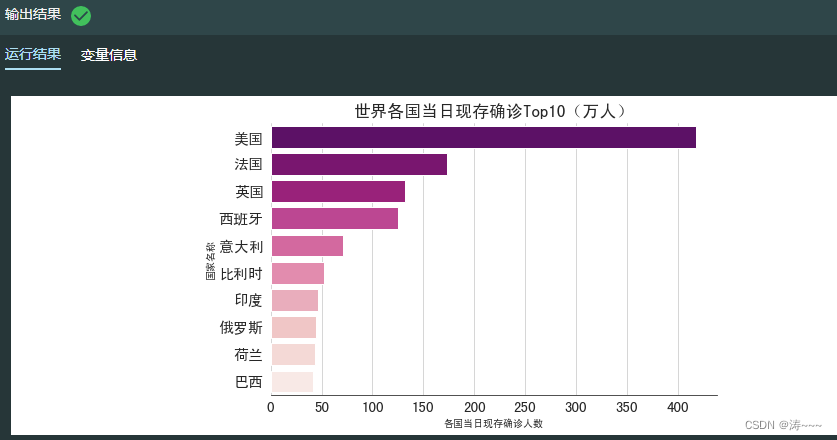
2.5 查看当日现存确诊Top10国家
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 根据当日现存确诊一列,按从大到小进行排序,并选取前十名
today_storeConfirm10 = today_world.sort_values(['当日现存确诊'],ascending=False)[0:10]
fig, ax = plt.subplots(figsize=(8,5))
# 绘制当日现存确诊Top10国家水平条形图
sns.barplot(x=today_storeConfirm10["当日现存确诊"], y=today_storeConfirm10["名称"], data=today_storeConfirm10, palette='RdPu_r')
# 隐藏右边、左边和上边的边框线
sns.despine(left=True)
# 设置坐标轴刻度的字体大小
ax.tick_params(labelsize=15)
# y轴刻度标签单位更改成万人
xlabels = [int(x) for x in ax.get_xticks()/10000]
ax.set_xticklabels(xlabels)
# 将绘图背景颜色更改为透明
ax.patch.set_alpha(0)
#设置x坐标轴上(垂直方向)的栅格线
ax.xaxis.grid(True)
# 设置标题
ax.set_title('世界各国当日现存确诊Top10(万人)', size=17)
ax.set_xlabel('各国当日现存确诊人数')
ax.set_ylabel('国家名称')
plt.show()
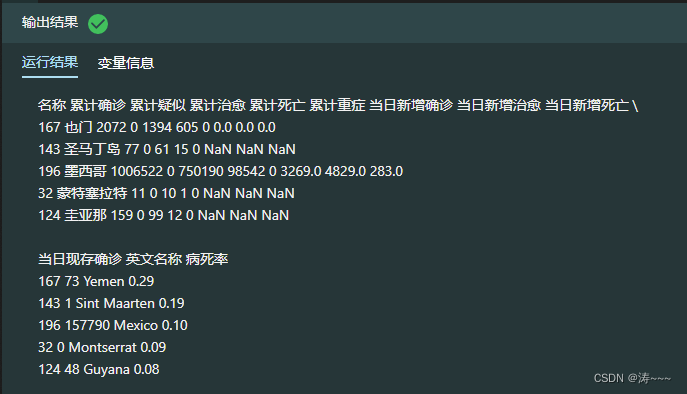
2.6 计算世界各国新冠肺炎病死率
import pandas as pd
# 计算病死率,且保留两位小数
today_world['病死率'] = (today_world['累计死亡']/today_world['累计确诊']).apply(lambda x:format(x,'.2f'))
# 将病死率数据类型转换为float
today_world['病死率'] = today_world['病死率'].astype('float')
# 根据病死率降序排序,并在原数据上进行修改
today_world.sort_values(['病死率'], ascending=False,inplace=True)
# 显示病死率前五国家
today_world.head()
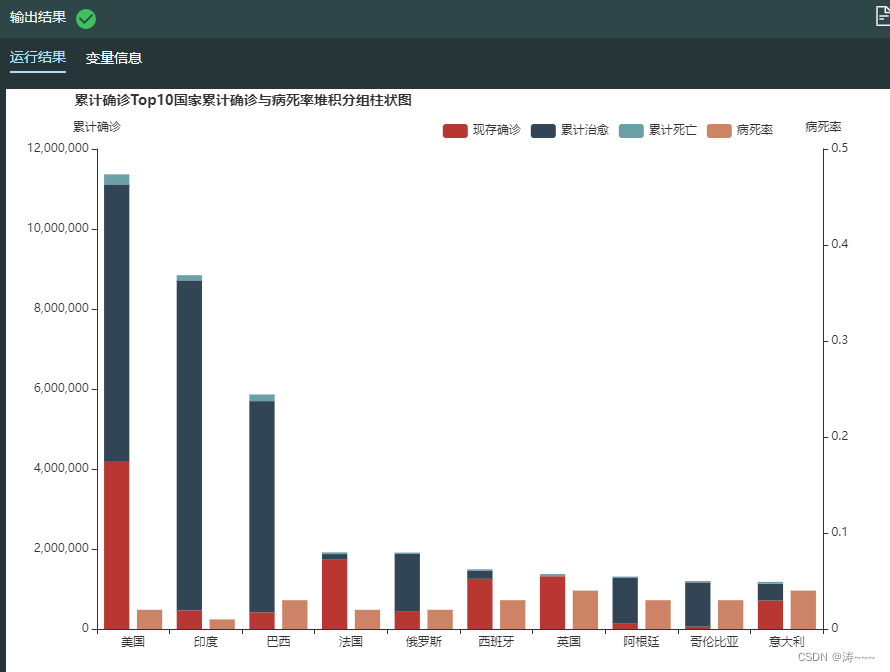
2.7 当前累计确诊人数Top10国家累计确诊人数与病死率堆积分组柱状图
# 累计确诊人数top10国家名称
top10_name = list(today_world["累计确诊"].sort_values(ascending=False)[:10].index)
# 累计确诊人数top10各国家累计治愈、累计死亡、现存确诊、病死率
top10_heal = today_world.loc[top10_name,:]["累计治愈"].values.tolist()
top10_dead = today_world.loc[top10_name,:]["累计死亡"].values.tolist()
top10_state = today_world.loc[top10_name,:]["当日现存确诊"].values.tolist()
top10_deadrate = today_world.loc[top10_name,:]["病死率"].values.tolist()
# 载入绘图类
from pyecharts.charts import Bar
import pyecharts.options as opts
# 实例化绘图类,设定图像宽度和高度
bar_ = Bar(init_opts=opts.InitOpts(width="1000px", height="600px"))
bar_.add_xaxis(top10_name) # 添加x轴数据
bar_.add_yaxis("现存确诊", top10_state, stack="stack1", yaxis_index=0) # 添加y轴数据,指定坐标轴索引为0
bar_.add_yaxis("累计治愈", top10_heal, stack="stack1", yaxis_index=0) # 添加y轴数据,指定坐标轴索引为0
bar_.add_yaxis("累计死亡", top10_dead, stack="stack1", yaxis_index=0) # 添加y轴数据,指定坐标轴索引为0
bar_.add_yaxis("病死率", top10_deadrate, yaxis_index=1) # 添加y轴数据,指定坐标轴索引为1
# 添加额外坐标轴
bar_.extend_axis(
yaxis=opts.AxisOpts(
name="病死率", #名称
type_="value", #类型
min_=0, # 最小范围
max_=0.5, # 最大范围
position="right" # 位置
)
)
# 系列配置项
bar_.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示标签
# 全局配置项
bar_.set_global_opts(yaxis_opts=opts.AxisOpts(name="累计确诊"), # 轴名称
title_opts=opts.TitleOpts(title="累计确诊Top10国家累计确诊与病死率堆积分组柱状图",
title_textstyle_opts=opts.TextStyleOpts(font_size=14),
pos_left='7%'), #图标题
legend_opts = opts.LegendOpts( # 设置图例
pos_right="15%",
pos_top='5%'))# 设置图例位置
# 渲染
bar_.render()
2.8 世界各国当日数据可视化分析(拓展)
# 读取数据
import pandas as pd
today_world = pd.read_csv('./today_world_v1.csv')
输出:None
2.10 读取中国各省当日数据
import chardet
import pandas as pd
# 查看文件编码格式
with open('./today_province.csv', 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
# 数据读取
today_province = pd.read_csv('today_province.csv', encoding=encoding)
# 展示前5行数据
print(today_province.head())
# 查看数据的基本信息
today_province.info()
# 查看数据的描述性统计信息
today_province_des = today_province.describe(include='all')
print(today_province_des)

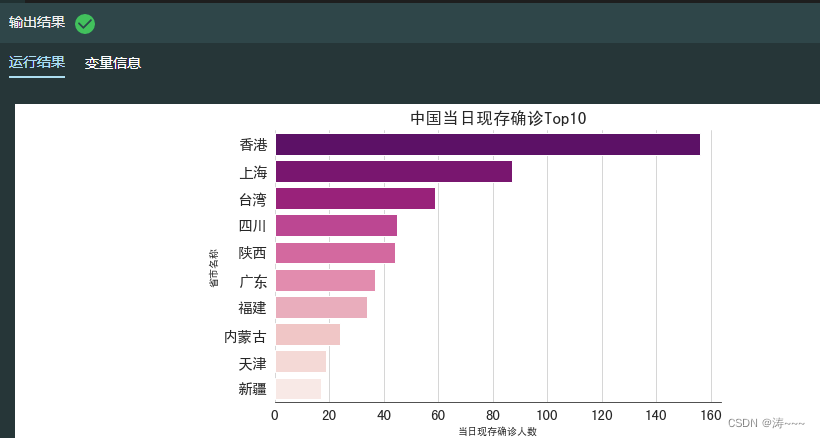
2.11 查看国内当日现存确诊Top10省市
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 计算各省当日现存确诊人数
today_province['当日现存确诊'] = today_province['累计确诊']-today_province['累计治愈']-today_province['累计死亡']
# 根据当日现存确诊一列,按从大到小进行排序,并选取前十名
today_storeConfirm10 = today_province.sort_values(['当日现存确诊'], ascending = False)[:10]
fig, ax = plt.subplots(figsize=(8,5))
# 绘制当日现存确诊Top10省市水平条形图
sns.barplot(x=today_storeConfirm10["当日现存确诊"], y = today_storeConfirm10["名称"], data = today_storeConfirm10, palette='RdPu_r')
# 隐藏右边、左边和上边的边框线
sns.despine(left=True)
# 设置坐标轴刻度的字体大小
ax.tick_params(labelsize=15)
# 将绘图背景颜色更改为透明
ax.patch.set_alpha(0)
#设置x坐标轴上(垂直方向)的栅格线
ax.xaxis.grid(True)
# 设置标题
ax.set_title('中国当日现存确诊Top10', size=17)
ax.set_xlabel('当日现存确诊人数')
ax.set_ylabel('省市名称')
plt.show()
2.12 各省市累计境外输入地图
# 分组聚合计算各省市累计境外输入人数
province_sum = today_input.groupby(by="流入地").sum()
# 提取出各省市名称与累计境外输入人数对应的嵌套列表
province_input = [list(key) for key in zip(today_input['流入地'].drop_duplicates(),province_sum['数量'])]
# 载入绘图类
import pyecharts.options as opts
from pyecharts.charts import Map
# 绘制地图
map_ = Map().add(series_name = "累计境外输入人数", # 设置提示框标签
data_pair = province_input, # 输入数据
maptype = "china", # 设置地图类型为中国地图
is_map_symbol_show = False # 不显示标记点
)
# 设置系列配置项
map_.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 不显示省市(标签)名称
# 设置全局配置项
map_.set_global_opts(title_opts = opts.TitleOpts(title="中国各省累计境外输入人数地图"), # 设置图标题
# 设置视觉映射配置项
visualmap_opts = opts.VisualMapOpts(pieces=[ # 自定义分组的分点和颜色
{"min": 200,"color":"#800000"}, # 栗色
{"min": 100, "max": 200, "color":"#B22222"}, # 耐火砖
{"min": 50, "max": 100,"color":"#CD5C5C"}, # 印度红
{"min": 10, "max": 50, "color":"#BC8F8F"}, # 玫瑰棕色
{"max": 10, "color":"#FFE4E1"}, # 薄雾玫瑰
],
is_piecewise = True)) # 显示分段式图例
# 渲染
map_.render()

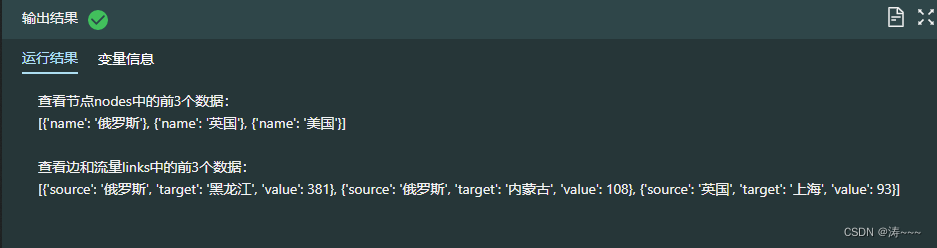
2.13 境外输入桑基图(预处理)
import pandas as pd
today_input = today_input.sort_values('数量', ascending=False)
# 定义节点
nodes = []
for i in range(2):
values = today_input.iloc[:,i].unique() # 每个城市的名称
# print(values)
for value in values:
dic = {}
dic['name'] = value
# print(dic)
# 将字典dic添加到列表nodes中
nodes.append(dic)
# print(nodes)
# 定义边和流量
links = []
for i in today_input.values: # ['俄罗斯' '内蒙古' 108]
dic={}
# print(i)
# 将today_input中对应的值添加到字典dic中
dic['source'] = i[0]
dic['target'] = i[1]
dic['value'] = i[2]
# 将字典dic添加到列表links中
links.append(dic)
# 输出节点、边和流量
print('查看节点nodes中的前3个数据:\n', nodes[:3], '\n')
print('查看边和流量links中的前3个数据:\n', links[:3])
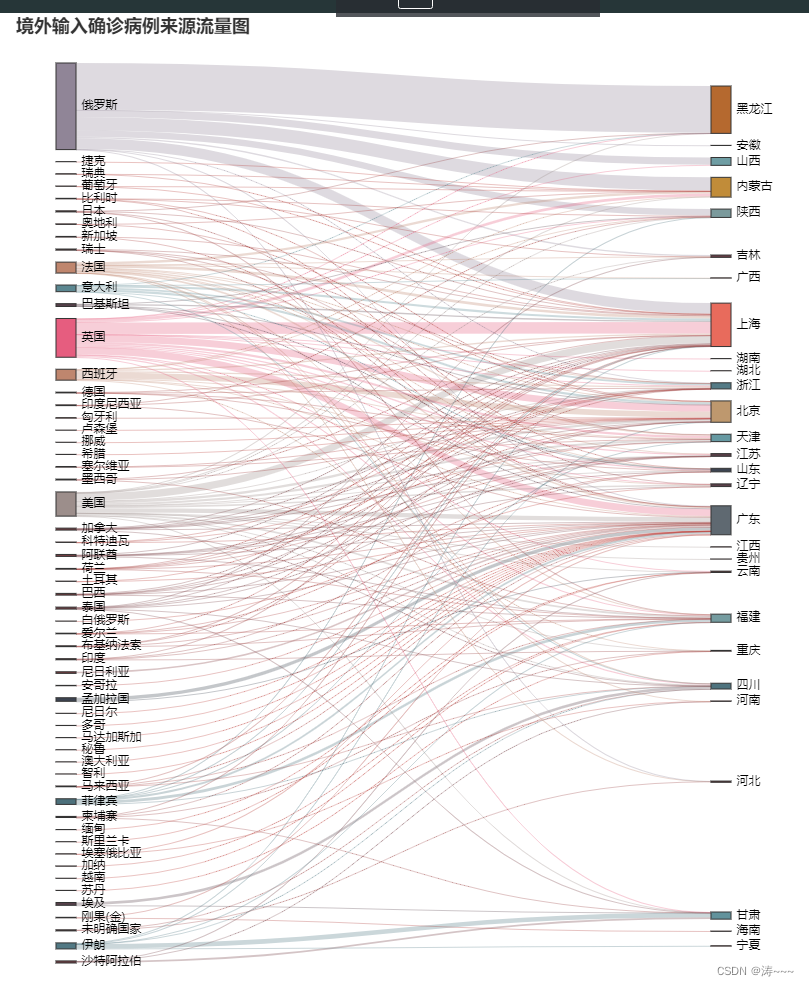
2.14 各省市累计境外输入桑基图
import pyecharts
from pyecharts.charts import Sankey
from pyecharts import options as opts
pic = (Sankey({'height':'1000px'}).add(
'', #图例名称
nodes , #传入节点数据
links , #传入边和流量数据
#设置透明度、弯曲度、颜色
linestyle_opt=opts.LineStyleOpts(opacity = 0.3, curve = 0.5, color = "source"),
#标签显示位置
label_opts=opts.LabelOpts(position= "right"),
#节点之间的距离
node_gap = 12).set_global_opts(title_opts=opts.TitleOpts(title = '境外输入确诊病例来源流量图'))
)
# 渲染图表
pic.render()
2.15 中国各省当日数据可视化分析(拓展)
# 读取数据
import pandas as pd
today_province = pd.read_csv("today_province_v1.csv")
today_input = pd.read_csv('today_input_v1.csv')
输出:None
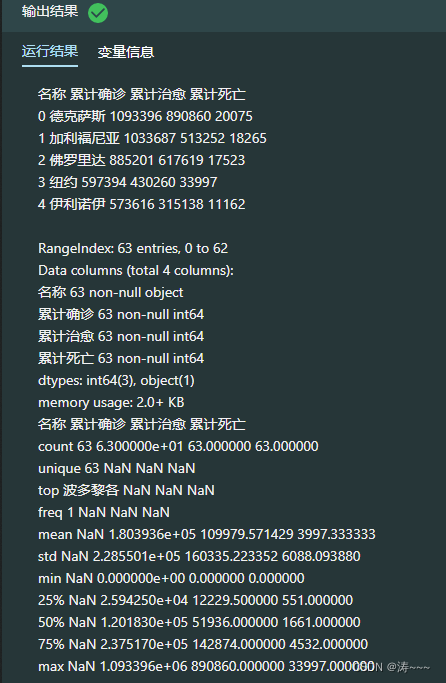
2.17 读取美国各州当日数据
import chardet
import pandas as pd
# 查看文件编码格式
with open('./today_usa.csv', 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
# 数据读取
today_usa = pd.read_csv("./today_usa.csv",encoding=encoding)
# 展示前5行数据
print(today_usa.head())
# 查看数据的基本信息
today_usa.info()
# 查看数据的描述性统计信息
today_usa_des = today_usa.describe(include='all')
print(today_usa_des)
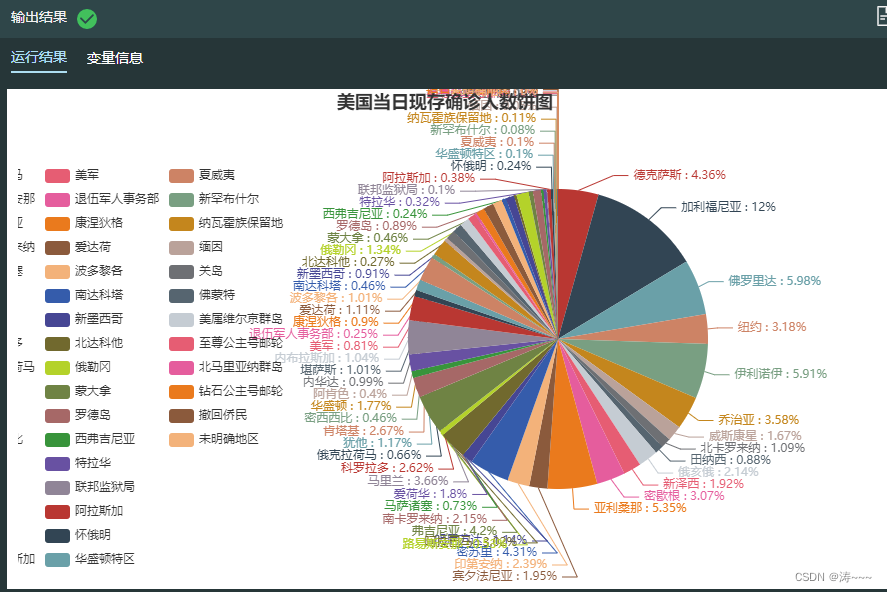
2.18 美国各州当日现存确诊可视化分析
import pandas as pd
from pyecharts.charts import Pie
import pyecharts.options as opts
# 计算当日现存确诊
today_usa['当日现存确诊'] = today_usa['累计确诊']-today_usa['累计治愈']-today_usa['累计死亡']
# 选取名称和当日现存确诊两列,根据当日现存确诊一列从大到小排序,选取前20个数据,保存为嵌套列表
rank_store = today_usa[['名称','当日现存确诊']].values.tolist()
pie = Pie().add("当日现存确诊人数", # 添加提示框标签
rank_store, # 输入数据
center=["60%", "50%"],
radius=150)
pie.set_global_opts(title_opts = opts.TitleOpts(title="美国当日现存确诊人数饼图", # 设置图标题
pos_right = '40%'), # 图标题的位置
legend_opts = opts.LegendOpts( # 设置图例
orient='vertical', # 垂直放置图例
pos_right="70%", # 设置图例位置
pos_top="15%"))
pie.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} : {d}%")) # 设置标签文字形式为(国家:占比(%))
# 在notebook中进行渲染
pie.render()
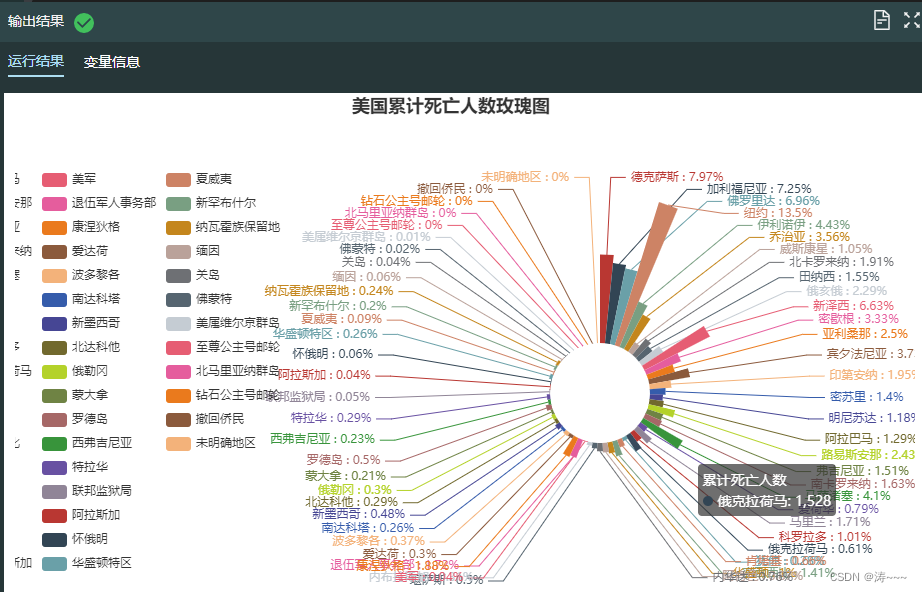
2.19 美国各州累计死亡人数可视化分析
import pandas as pd
from pyecharts.charts import Pie
import pyecharts.options as opts
# 选取名称和累计死亡两列,根据累计死亡一列从大到小排序,选取前20个数据,保存为嵌套列表
rank_dead = today_usa[['名称','累计死亡']].values.tolist()
pie = Pie().add("累计死亡人数", # 添加提示框标签
rank_dead, # 输入数据
radius = ["20%", "80%"], # 设置内半径和外半径
center = ["65%", "60%"], # 设置圆心位置
rosetype = "area") # 玫瑰图模式,通过半径区分数值大小,角度大小表示占比
pie.set_global_opts(title_opts = opts.TitleOpts(title="美国累计死亡人数玫瑰图", # 设置图标题
pos_right = '40%'), # 图标题的位置
legend_opts = opts.LegendOpts( # 设置图例
orient='vertical', # 垂直放置图例
pos_right="70%", # 设置图例位置
pos_top="15%"))
pie.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} : {d}%")) # 设置标签文字形式为(国家:占比(%))
# 在notebook中进行渲染
pie.render()
2.20 各州累计治愈、累计死亡与人口对比气泡图
# 重设索引
today_usa = today_usa.set_index(['名称'])
# print(state_name)
# print(state_name[['颜色']])
# 提取数据
use_data = pd.DataFrame([])
use_data['累计死亡'] = today_usa.loc[state_name[['中文名称']]['中文名称']]['累计死亡']
use_data['累计治愈'] = today_usa.loc[state_name[['中文名称']]['中文名称']]['累计治愈']
use_data['累计确诊'] = today_usa.loc[state_name[['中文名称']]['中文名称']]['累计确诊']
use_data['人口'] = state_name['人口'].values
use_data['颜色'] = state_name['颜色'].values
# print(use_data)
# 定义气泡图点的大小
sizes = pd.cut(use_data['人口'],bins=5,labels=False)
sizes.replace(dict([(0,100),(1,400),(2,800),(3,1500),(4,2000)]),inplace=True)
# 载入绘图库并设置正常显示中文
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 创建绘图框并绘图
fig = plt.figure(figsize=(7,6))
plt.scatter(use_data['累计死亡'] ,use_data['累计治愈'], s=sizes, c=use_data['颜色'])
# 在图上标注累计死亡大于10000且累计治愈大于30000的州名称
use_data_marker = use_data[(use_data['累计死亡']>=10000)&(use_data['累计治愈']>=30000)].iloc[:,:2]
for i,xy in enumerate(zip(use_data_marker['累计死亡'],use_data_marker['累计治愈'])):
plt.annotate(use_data_marker.index[i], xy=xy,xytext=(xy[0],xy[1]+70000))
plt.xlabel('累计死亡') # 横坐标轴标题
plt.ylabel('累计治愈') # 纵坐标轴标题
plt.ylim(-1e4,1e6) # 设置y轴刻度范围
plt.title('美国各州累计治愈、累计死亡与人口对比气泡图')
plt.box(False) # 去掉图边框
plt.show()

2.21 美国各州当日数据可视化分析(拓展)
# 读取数据
import pandas as pd
today_usa = pd.read_csv("today_usa_v1.csv")
输出:None
本文转载自: https://blog.csdn.net/weixin_47219875/article/details/126709032
版权归原作者 涛涛涛不淘 所有, 如有侵权,请联系我们删除。
版权归原作者 涛涛涛不淘 所有, 如有侵权,请联系我们删除。