
LLMs在回答各种复杂问题时,有时会“胡言乱语”,产生所谓的幻觉。解决这一问题的初始步骤就是创建高质量幻觉数据集训练模型以帮助检测、缓解幻觉。
但现有的幻觉标注数据集,因为领域窄、数量少,加上制作成本高、标注人员水平不一,所以很难变得强大。
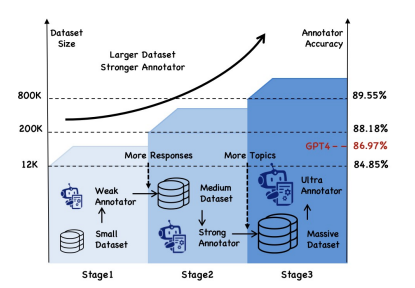
为了解决这个问题,上海AI lab设计了一个迭代自训练框架——ANAH-v2,它像滚雪球一样,一边扩大幻觉检测的数据集,一边提高标注者的准确性。
这个框架利用期望最大化算法,每次循环都会先用现有的幻觉标注工具给新数据打上“幻觉”标签,然后用这些新数据训练一个更厉害的标注工具。
通过迭代,检测工具越来越强,数据集也越来越大。一个仅有7B参数的幻觉标注模型(89.55%)超越了GPT-4的表现(86.97%),并且在幻觉检测基准HaluEval和HalluQA上获得了新的SOTA!
论文标题:
ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models
论文链接:
https://arxiv.org/pdf/2407.04693

方法
1. 善于分析的幻觉标注器
幻觉标注器的目标是识别模型响应中的幻觉,在本文中该过程分为三个阶段,更贴近人类认知判断过程:
- 事实存在判断:标注器评估提供的句子是否包含可验证的事实。如果没有事实内容,该句子被归类为“无事实”,无需进一步标注。

- 参考信息提取:标注器从与问题和答案相关的文档中提取相关参考点。

- 幻觉类型判断:标注器根据提取的参考点确定幻觉类型。如果句子与参考点一致,则分类为“无幻觉”。如果与参考点矛盾,则视为“矛盾幻觉”。如果缺乏支持证据且无法验证,则标记为“不可验证幻觉”。

以上三个阶段将在训练数据中形成多轮对话,用于后续模型训练。
2. 最大期望(EM)算法
本文通过最大期望算法同时扩展数据集和提高标注准确性。对于输入集合,需要同时估计两个隐藏变量,即输出集合和模型参数。具体而言,定义幻觉标注器的输入来自输入集合,包括一个问题、一个待标注的句子和一个参考文档。预期输出包括事实信息、参考文档中的关键参考点和幻觉类型。通过交替执行步和步来最大化的对数似然估计以更新模型参数:
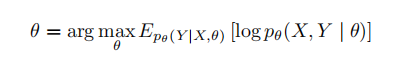
E步:为了提高的估计准确性和稳定性,作者引入了自一致性方法,这提供了分布的更稳健表示。对于每个输入,进行多次采样以产生个独立的输出,其中第个输出样本由事实信息()、参考点()和幻觉类型()组成。使用自一致性度量从所有输出中选择最具代表性的样本:
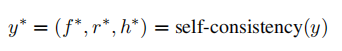
在选择过程中,依次考虑幻觉类型、参考点和事实信息。通过对所有样本进行多数投票来确定最常见的幻觉类型,记为。然后,从包含的输出中获取相应的,形成候选参考集合。通过比较余弦相似性选择最“一致”的参考点。对于中的每个,首先计算它与中其他元素的平均余弦相似性。之后,选择平均余弦相似性最高的参考点:。最后,利用(, ),可以唯一地选择相应的。
M步:在E步的稳健估计之后,M步更新模型参数以最大化所选输出的似然。在第次迭代中将参数更新策略公式化为:
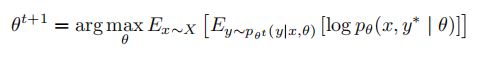
3. 多维数据缩放
基于EM算法,本文框架以迭代方式运行,逐步扩展数据集,包括三个阶段:
阶段1:种子数据和基础标注器本文利用ANAH数据集作为种子数据,其中包含超过700个主题和大约4300个由LLM生成的问题和回答。对于每个回答,ANAH通过人工参与的方法为每个句子提供幻觉类型。本文使用第一节中描述的标注方法,用这些种子数据训练初始幻觉标注器,称为ANAH-v2阶段1。
阶段2:在回答维度上扩展在阶段1中,对于每个问题,ANAH提供GPT-3.5基于参考文档生成的回答,以及InternLM-7B在没有参考文档的情况下生成回答。
本文首先通过收集13个不同规模和系列的开源模型对相同问题的回答来扩展数据集的模型回答。对于每个模型,收集有无参考文档的回答。在过滤掉相似的模型回答后,这些回答使用ANAH-v2阶段1的自一致性pipeline逐句进行标注。新标注的数据与种子数据结合,用于训练ANAH-v2阶段2。
阶段3:在主题维度上扩展本文沿四个类别扩展主题覆盖:地点、人物、事件和事物,与ANAH的配置平行。对于每个主题,根据提供的参考文档生成几个问题。然后,使用阶段2中的相同方法,收集多个模型的回答,并按照阶段2中使用ANAH-v2阶段2标注器的相同程序进行标注。最终数据集结合前几个阶段的数据,用于训练最终版本的标注器。
总体统计
最终数据集涵盖超过3000个主题,约196k个模型回答和约822k个标注句子,包含英文和中文。
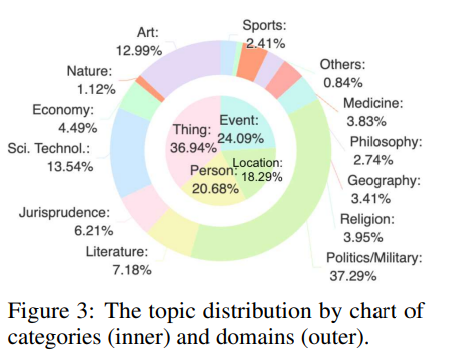
主题覆盖名人、事件、地点和事物,涉及广泛领域,如政治、健康和体育。该数据集规模庞大,覆盖全面。
实验与分析
本文采用了预训练的InternLM2-7B模型来对幻觉标注器进行微调,使用ANAH数据集的子集作为测试集。利用F1和准确率评估标注器在预测幻觉类型方面的性能,还使用RougeL和BertScore 来将生成的文本与人类参考文本进行比较,以考虑语法、连续性、顺序和语义方面。实验结果如下表:
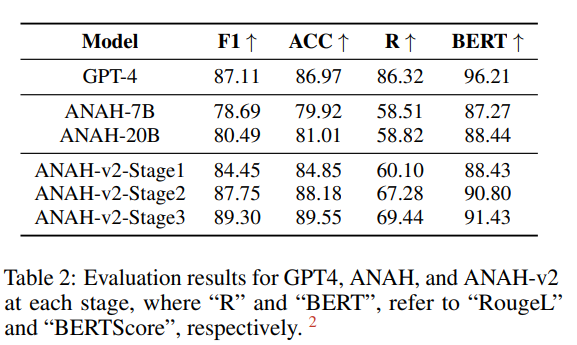
上表的最后三行展示了ANAH-v2在数据扩展各阶段的性能。随着数据集数量的增加,其性能逐步提高。这一趋势突显了幻觉标注框架的可扩展性和有效性。
值得注意的是,ANAH-v2在第二阶段的F1值达到87.78%,准确率达到88.03%,超越了GPT-4。最终,在第三阶段,我们达到了89.30%的F1值和89.55%的准确率。
除此之外,ANAH-v2在第一阶段的准确率(84.85%)已超过参数为20B的ANAH-20B(81.01%),而其参数仅为7B。这种优越性能归功于前文提到的善于分析的幻觉标注器的设计,得到了非常丰富的多轮对话。
消融实验
自一致性的影响
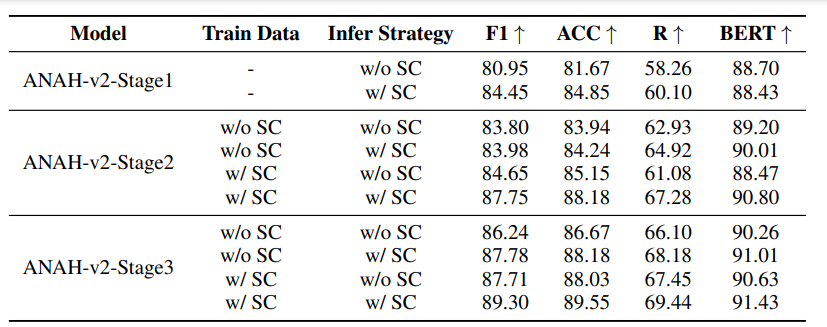
当标注器模型在各个数据扩展阶段使用相同的训练数据时,如下表所示,采用自一致性推理策略(w/ SC)的性能始终优于不采用自一致性策略(w/o SC),即对每个输入只生成一次。因此,自一致性方法提高了幻觉标注估计的准确性和稳定性。
渐进数据缩放的影响
在渐进方法中,第二阶段更新的标注器用于标注额外主题的响应,不断丰富训练数据。相比之下,在非渐进方法中,第一阶段的基本标注器用于生成第三阶段额外训练数据的标注。

在相同规模的训练数据下,使用非渐进数据扩展训练的标注器性能不如使用渐进数据扩展训练的标注器。
训练策略的影响
在默认训练过程中,将新标注的数据与旧数据混合以重新训练标注器。或者仅使用新标注的数据来进一步训练上一阶段的标注器模型。
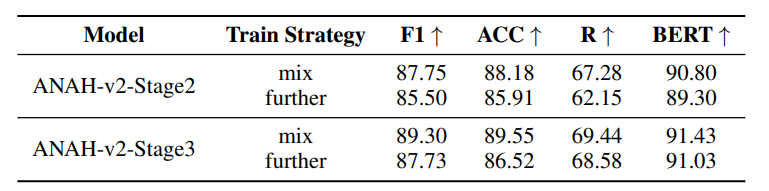
结果表明,混合训练数据的训练策略比仅用新数据进一步训练效果更好。在各个训练阶段整合不同质量的数据提高了标注器模型的鲁棒性。
评估ANAH-v2模型在幻觉检测能力的泛化性
本文进一步验证了微调模型ANAH-v2在其他幻觉检测数据集HaluEval(英文)和HalluQA(中文)上的有效性。让ANAH-v2分别判断回答中是否包含幻觉。
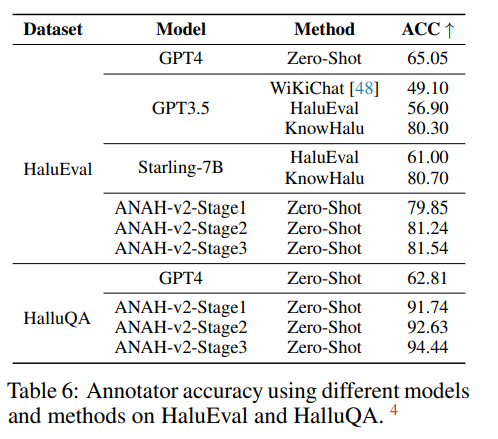
结果显示,标注模型ANAH-v2在HaluEval和HalluQA上均取得了显著的准确率。ANAH-v2第三阶段在zero-shot设置下分别在HaluEval(81.54%)和HalluQA(94.44%)上取得了新的SOTA,这突显了ANAH-v2的泛化能力。此外,ANAH-v2第三阶段的表现优于第一阶段和第二阶段的标注器,这进一步证明了数据扩展策略在处理不熟悉回答时有效地稳定了性能。
ANAH-v2数据集可作为幻觉评估基准
ANAH-v2数据集和标注器可以作为现有模型生成文本中幻觉水平的基准。作者评估了各种不同规模的LLMs在ANAH-v2数据集的上性能。
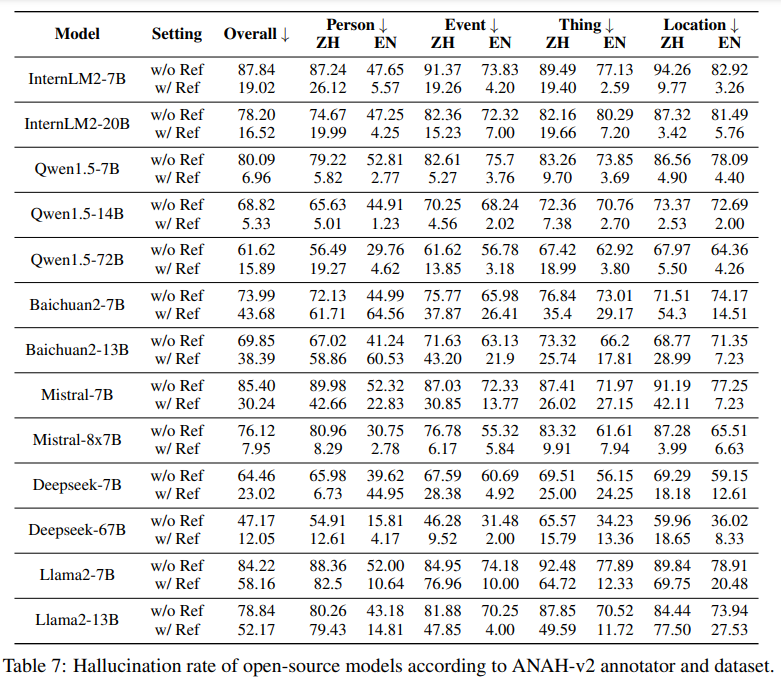
- 所有模型在英文中的表现优于中文,这突显了需要进一步研究以理解和减少语言依赖的差异。
- 所有模型在使用参考文档时的性能都优于不使用参考文档时的性能。Qwen1.5-14B在使用参考文档时实现了最低的幻觉率(5.33%),而Deepseek-67B在没有提供参考文档时实现了最低的幻觉率(47.17%)。
ANAH-v2标注器可用于缓解幻觉
除了用于测量幻觉水平外,ANAH-v2还可以用于缓解幻觉。本文使用了两个模型InternLM2-7B和LLaMA2-7B,通过top-k采样(k=40)生成36个候选响应,然后使用ANAH-v2标注器对这些响应进行重新排序,选择具有最低幻觉率的最佳响应。
为了量化幻觉程度,使用了RougeL、BertScore、NLI和QuestionEval指标测量生成的响应与标准答案和/或参考文档之间的一致性。
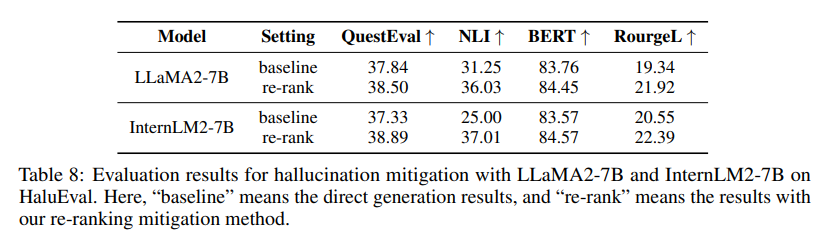
结果显示,通过ANAH-v2标注器进行重新排序后,幻觉水平明显下降。LLaMA2-7B的NLI指标显著提高,从25.00%上升到37.01%。
结语
本文通过迭代自我训练,逐步扩大数据集的多样性和规模,并提高幻觉标注器的准确性。最终得到的ANAH-v2仅用7B参数在各种幻觉检测基准测试中首次超过了GPT-4,并在第三方幻觉检测基准测试中表现出色。
ANAH-v2不仅提供了一个基于的扩展数据集的自动幻觉评估基准,为未来幻觉缓解研究铺平了道路,还通过简单的重新排序策略展示了其在幻觉缓解中的潜力。相信ANAH-v2还可以为更细粒度的RLHF等更多幻觉缓解策略提供帮助。
版权归原作者 夕小瑶 所有, 如有侵权,请联系我们删除。