
文章目录
LLM大模型的向量数据库应用实战
1 大模型的局限性
大模型的4点局限性
- 缺乏领域特定信息:LLM仅基于公开数据预训练,缺乏领域特定信息、专有/专业数据等非公开数据
- 容易产生幻觉:LLM只能根据现有数据提供信息和答案,如果超出该范围,LLM回提供错误或捏造的信息
- 无法获取最新信息/知识:LLM训练成本十分高昂(训练ChatGPT-3的成本高达 140万美金),LLM无法及时更新知识库
- “不变”的预训练数据:LLM使用的预训练数据可能包含过时或者不正确的信息,并且这些数据无法更正或删除
大模型的4点局限性的改进实践方法
- 缺乏领域特定信息: - 利用向量数据库建立知识库,拓展 LLM 的认知边界- 微调(Fine-tuning)针对专业领域进行特定训练
- 容易产生幻觉: - 使用提示词工程 Prompt Engineering 规定限制
- 无法获取最新信息/知识: - 利用向量数据库为大模型建立记忆,及时更新
- “不变”的预训练数据: - RLHF(Reinforcement Learning from Human Feedback)人工纠正再次微调- 从知识库中删除无效信息
2 向量数据库使用场景以及改建大模型
用向量数据库/知识库改进大模型
向量数据库
- 向量是非结构化数据在高维空间中的表征
- Embedding Model 是将非结构化数据映射到高维空间的工具
- 使用合适的 Embedding Model,向量的近似度代表语义的近似度
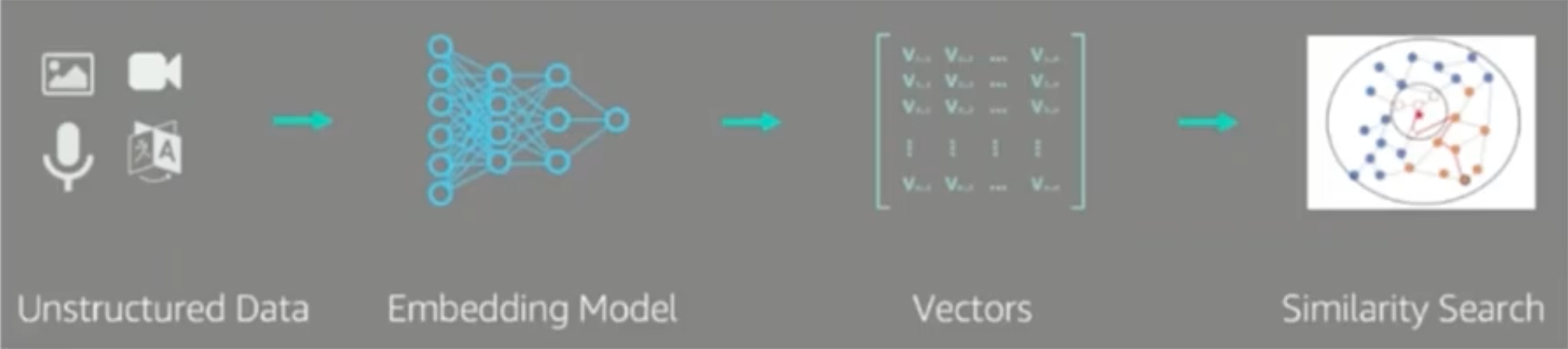
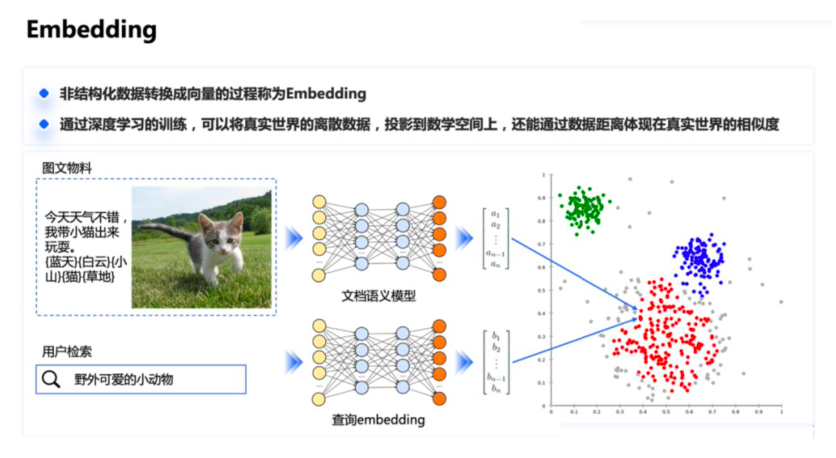
- Embedding过程
向量数据库选型
- 国产:Milvus、Tencent Cloud VectorDB、Zilliz Cloud 等
- 海外:Pincone(免费)、Redis、FAISS、PgVector、Elasticsearch Cloud 等
- 技术架构:

知识库
- 知识图谱
- 全文检索
- 知识库和向量数据库关系 - 大模型应用离不开向量检索
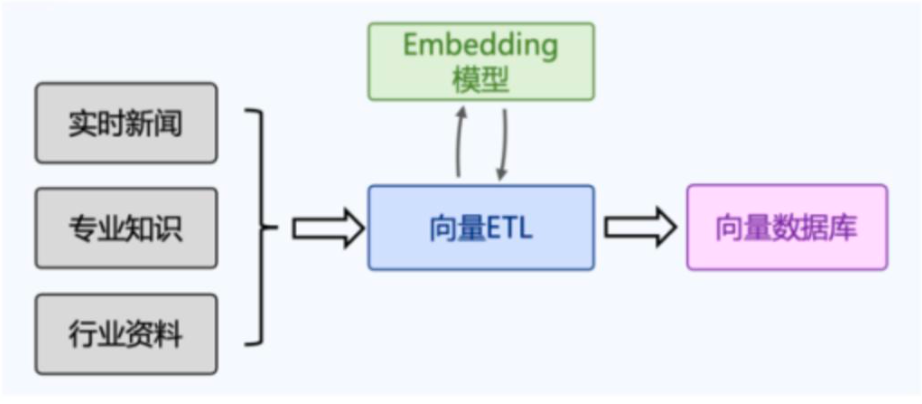
文档检索增强(Retrieval Augmented Generation)
- 利用提前构建好的知识库,通过检索与 Query 相关的知识片段来增强大模型回答效果

😁 RAG 优势——更经济、更具可行性、更具扩展性
- 容易管理
- 更精确和上下文相关的答案
- 适应性强、敏捷性强
- 更好的模糊搜索能力
😌 Fine-tuning 不足
- 适用于较小的知识数据库
- 没有知识访问控制
- 前期成本高,维护成本高
- 知识更新不及时
3 向量数据库应用技术架构剖析
向量数据库应用技术总体架构
- 以一个在线查询为例:
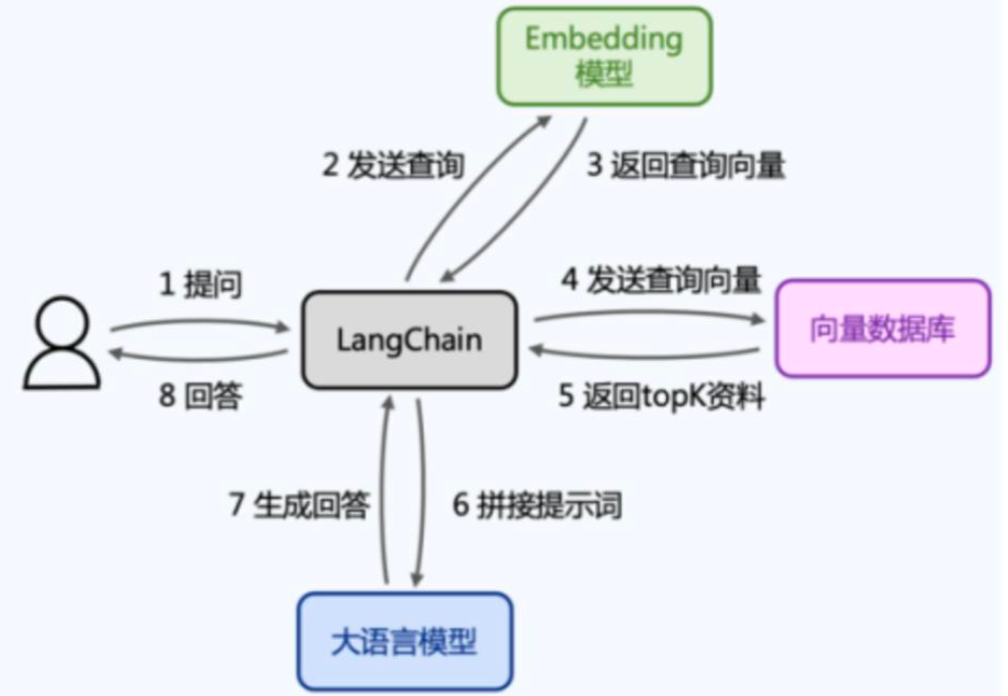
🌰
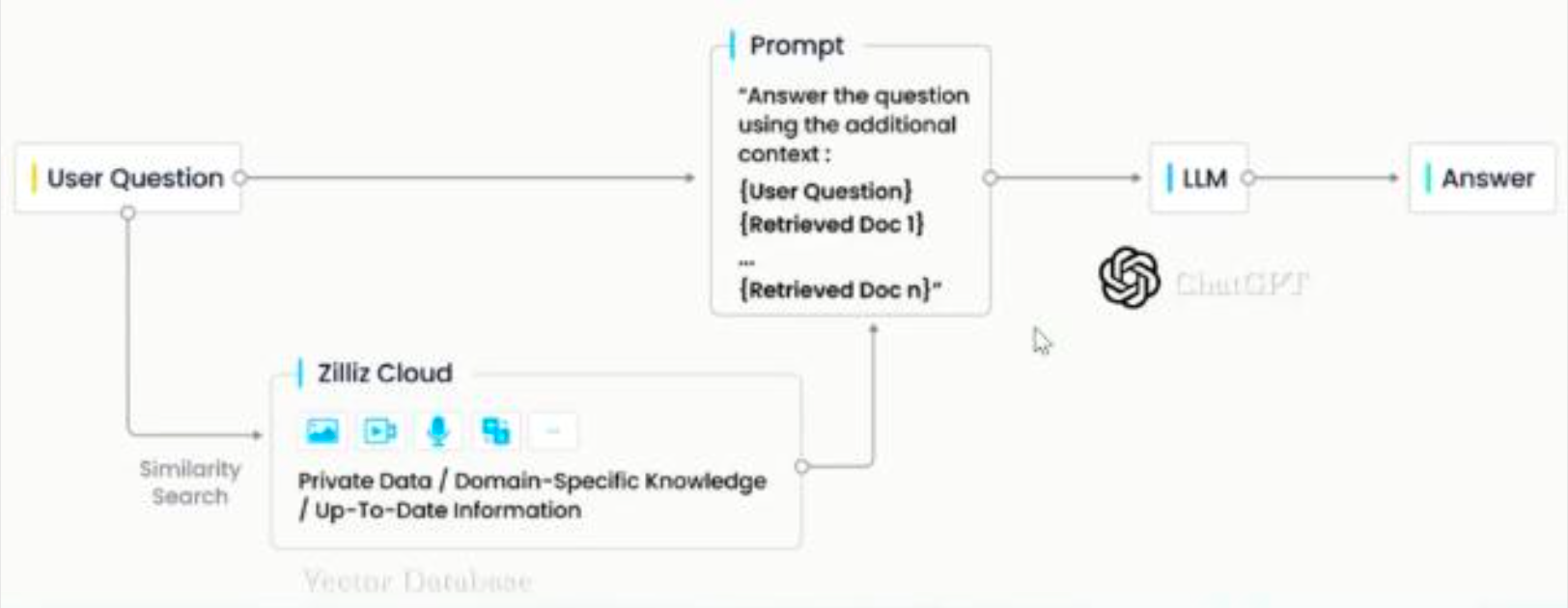
向量数据库应用离线索引技术
离线索引更多优化
- 针对文档特性(语言、内容)选择 Embedding 模型
- 更有针对性的文档分段模型
- 文档转问题,用问题召回

向量数据库应用在线检索技术
在线检索更多优化
- 用户问题改写,使用改写的问题召回
- 多路召回,结合全文检索的结果
- 把问题编造成“假”文档,使用“假”文档召回

4 利用向量检索构建知识库案例实战库
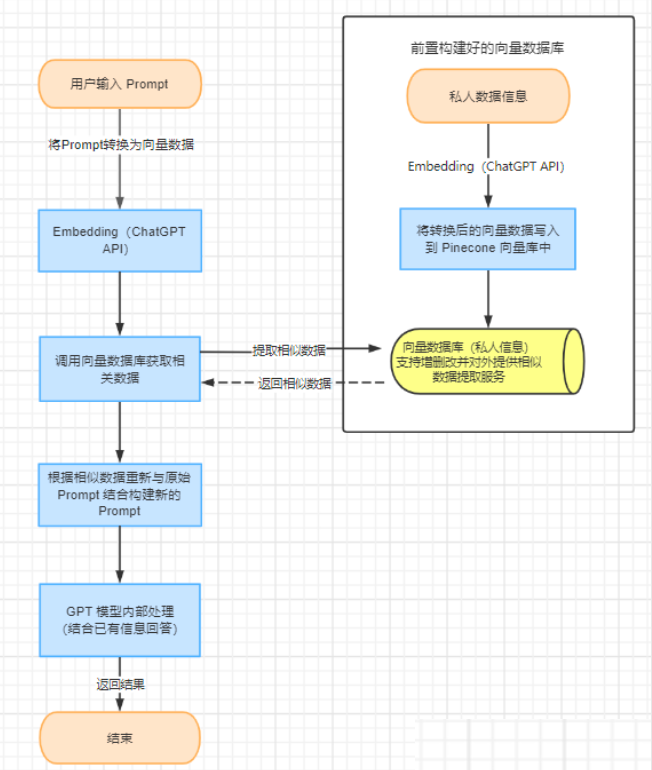
构建私人智能助手整体架构设计
总体流程3大步骤
- 将私人数据转换为向量数据,并写入到向量数据库中
- 根据 Prompt 从向量数据库中提取相似数据
- 结合相似数据重新组装 Prompt,让 ChatGPT 生成回答
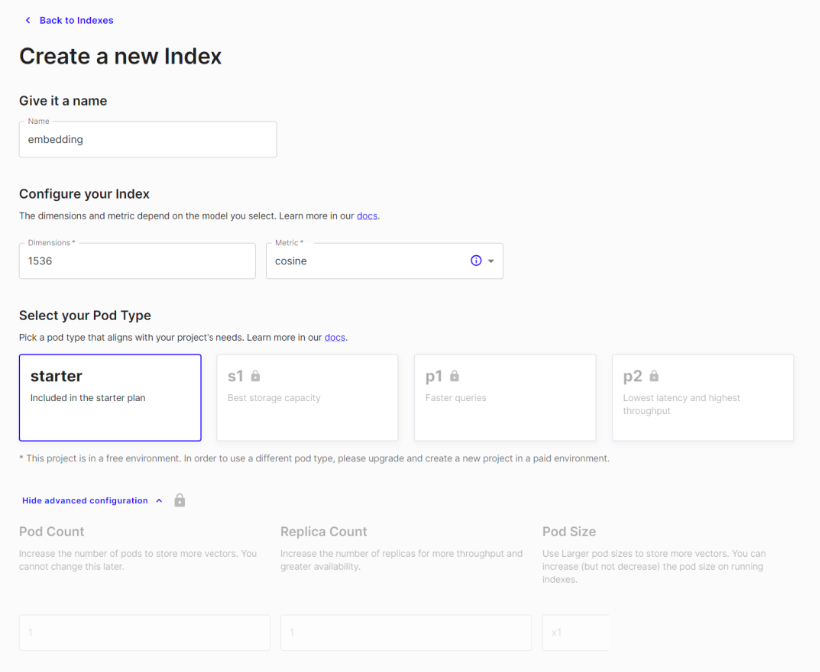
向量数据库选型
- 推荐 Pinecone 向量数据库:https://www.pinecone.io/ - 免费、秒审通过
- 核心三个参数 - 索引名称:满足规范- 特征维度:向量维度,OpenAI 转化为 1536 维- 度量距离指标:提供了3种,推荐 cosine
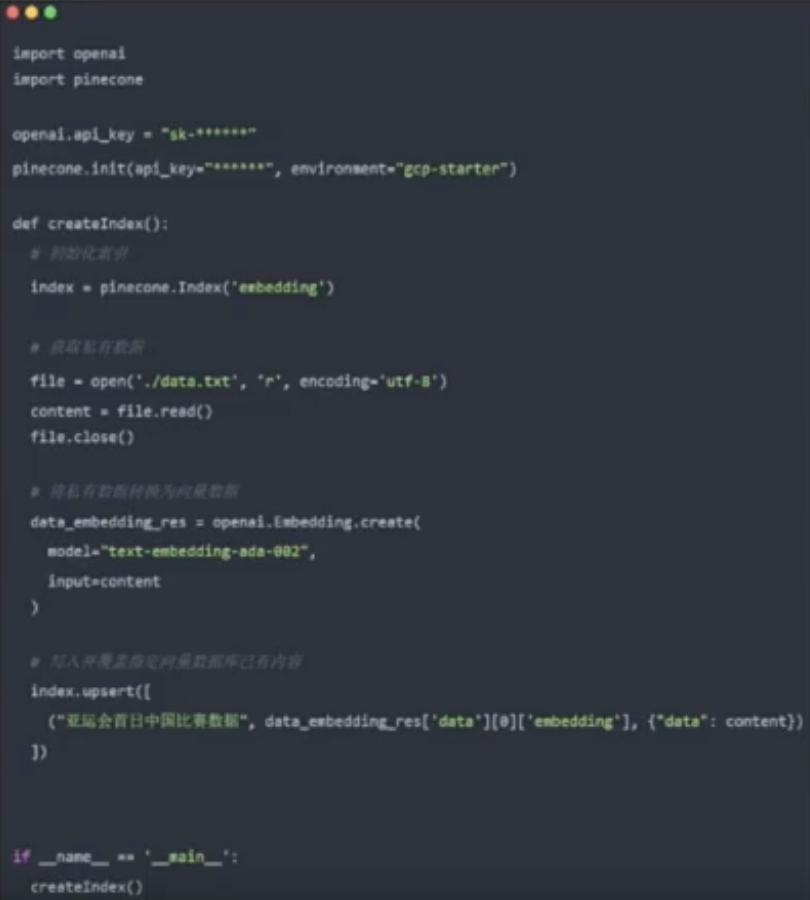
写入向量数据库(离线索引)
- 安装对应的 Python 库:
pip install pinecone-client - 写入向量数据(采用读取文件形式) - 将所有数据从文档中读取出来- 通过 OpenAI Embedding 转换成对应的向量化数据- 将向量化数据存储到 Pinecone 创建的 index 中
- 在 Pinecone 网站查看这份数据
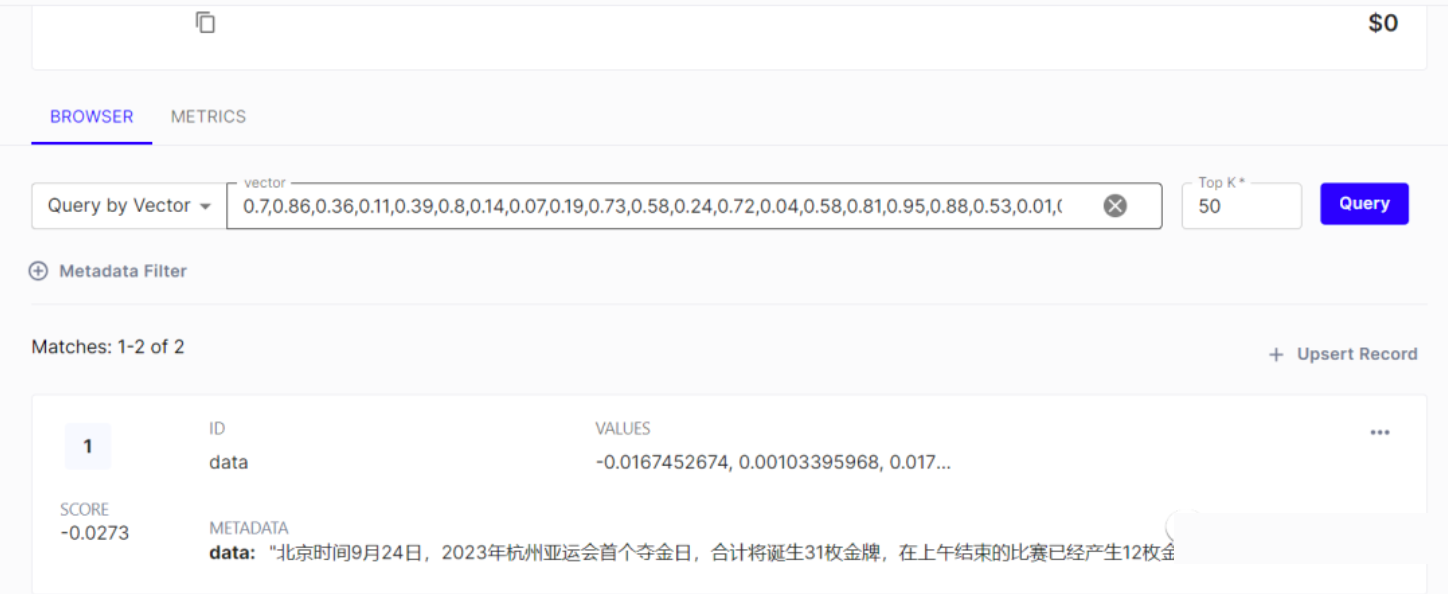
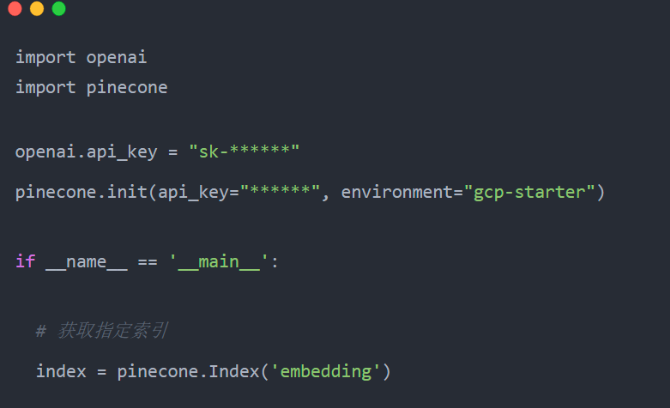
使用向量数据库(在线检索)
- 从 Pinecone 获取指定的索引
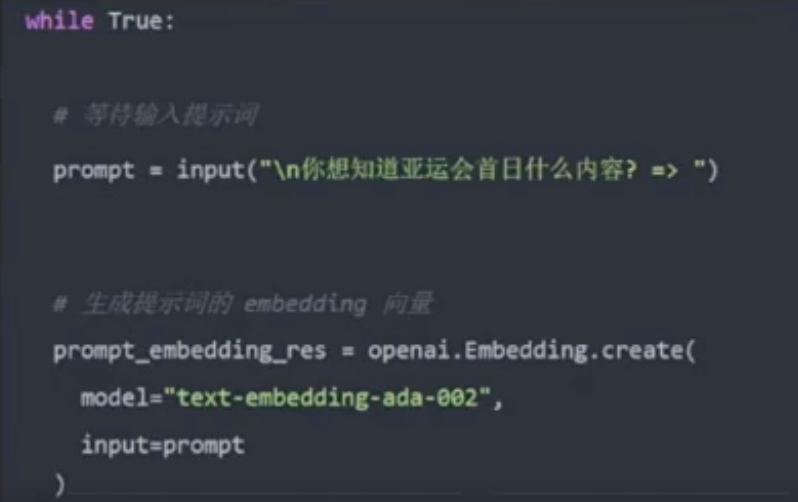
- 将 Prompt 转换为向量数据,从向量数据库提取相似数据
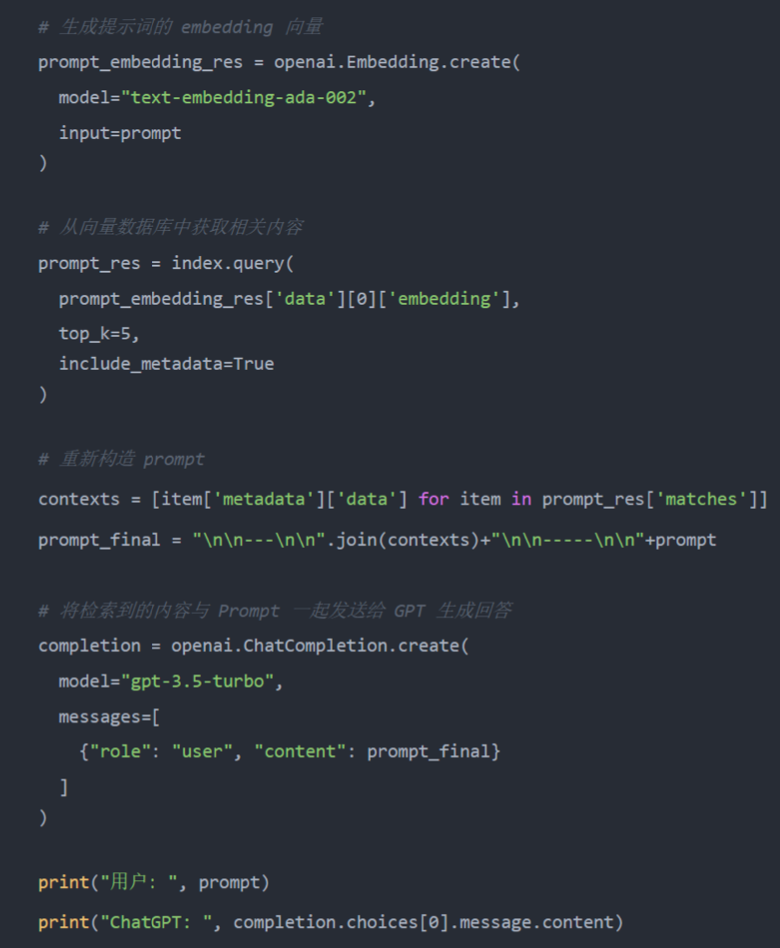
- 将提取的数据与 Prompt 重新构建输入,发送给 ChatGPT
- ChatGPT 整理内容后输出结果
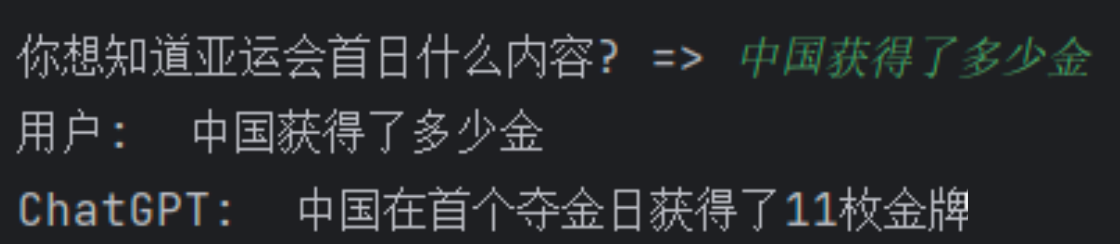
私人助手回答结果
- 关于亚运会首日中国金牌信息,可以看到完美成为了我们的私人智能助手来回答问题
本文转载自: https://blog.csdn.net/yangwei234/article/details/143091504
版权归原作者 讲文明的喜羊羊拒绝pua 所有, 如有侵权,请联系我们删除。
版权归原作者 讲文明的喜羊羊拒绝pua 所有, 如有侵权,请联系我们删除。