

图 1 由CVPR 2024论文列表高频词生成的词云
IEEE/CVF Computer Vision and Pattern Recognition Conference(CVPR)是计算机视觉和模式识别领域的顶级学术会议之一,每年举办一次,与ICCV和ECCV并称为计算机视觉领域的三大顶级会议。CVPR 2024的会议时间为2024年6月17日至6月21日,会议地点为美国华盛顿州西雅图。根据4月5日CVPR官方发布的结果,会议今年收到了11532篇有效论文提交,有2719篇被接收,整体接收率约为 23.6%。本文将对CVPR2024的录用论文进行可视化分析,为读者跟踪人工智能的研究热点提供一些有价值的参考。本文作者为黄星宇,审校为陆新颖和许东舟。
会议相关链接:https://cvpr.thecvf.com/
一、一图看懂CVPR(2017-2024)发展趋势
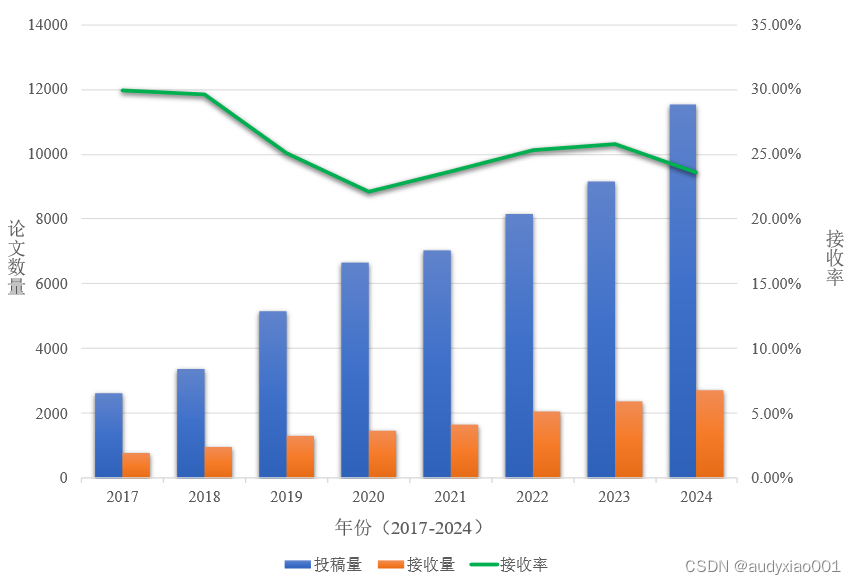
图 2 CVPR(2017-2024)发展趋势
由图2可以看出CVPR近年来的发展趋势。近年来,CVPR的投稿数量逐年攀升,平均每年增加1000-2000篇左右,体现了人们对CVPR会议的看重,以及计算机视觉领域的迅猛发展。同时,论文的接收量也随着投稿量的上升在增加,总体的接收率维持的比较稳定,尽管个别年份会有波动,也体现了会议并没有因为投稿量的增多而降低论文质量。总的来说,CVPR随着计算机视觉领域的发展还会变的更加火热,继续展现其在领域内的权威性。
二、CVPR 2024热点追踪
接下来,对CVPR 2024里出现的高频关键词进行更详细的讨论和分析(个人理解,仅供参考):
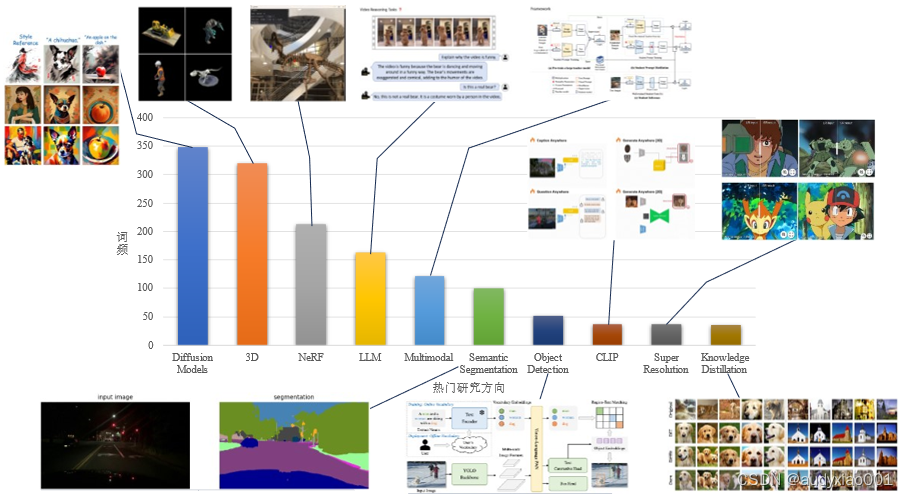
图 3 热门研究方向
2.1 扩散模型(Diffusion Models)
基本概念:扩散模型是一种深度学习框架,被用于生成模型的研究中,尤其是用于创建逼真的合成图像。这类模型通过引入随机噪声到数据中,然后学习逆向这个过程以生成清晰图像,它们在改进图像质量和生成新图像方面显示出了巨大的潜力。
示例论文:DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
全文下载:https://arxiv.org/abs/2403.06951
2.2 3D
基本概念:在计算机视觉领域,3D视觉关注的是从图像和视频中理解和重建三维世界。这包括通过技术如立体视觉、深度感测、光场摄影和结构光扫描等来获取物体和场景的三维结构信息。3D计算机视觉使得机器不仅能识别和分类图像中的对象,还能估计它们在真实世界中的尺寸、形状、位置和姿态。这种技术在自动驾驶汽车、机器人导航、增强现实、虚拟现实以及自动化3D模型创建等众多应用中至关重要。
示例论文:Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
全文下载:https://arxiv.org/abs/2309.13101
2.3 神经辐射场(NeRF)
基本概念:NeRF(Neural Radiance Fields)是一种用于3D场景重建和渲染的深度学习框架,它通过对光线在空间中的行为进行建模来创建高质量的3D图像。NeRF工作原理是利用神经网络来预测在场景的任何给定位置沿任意方向的光线的颜色和密度,通过大量的2D图像训练,网络能够生成新的视角下的3D场景的连续视图,从而实现复杂场景和光照效果的逼真渲染。
示例论文:PIE-NeRF: Physics-based Interactive Elastodynamics with NeRF
全文下载:https://arxiv.org/abs/2311.13099
2.4 大语言模型(LLM)
基本概念:大语言模型(Large Language Model, LLM)是基于深度学习的、训练于大规模文本数据集上的模型,旨在理解和生成人类语言。通过利用数十亿甚至数万亿的参数,这些模型能够捕捉语言的复杂性、多样性以及微妙的语境差异。LLM如GPT(Generative Pre-trained Transformer,GPT)和BERT(Bidirectional Encoder Representations from Transformers,BERT)通过预训练和微调的策略,学会执行多种语言任务,比如文本生成、翻译、摘要、问答和情感分析等。这些模型的关键优势在于其能够根据给定的输入文本生成连贯、相关且多样的输出,推动了自然语言处理技术的发展。
示例论文:VTimeLLM: Empower LLM to Grasp Video Moments
全文下载:https://arxiv.org/abs/2311.18445
2.5 多模态(Multimodal)
基本概念:多模态指的是结合来自多种不同感官通道的信息,比如视觉、语言和声音,来改善和增强机器理解环境的能力。通过这种方式,模型不仅可以处理图像和视频,还可以理解和生成描述这些视觉内容的文本,或者响应语音指令。多模态方法使计算机能够更全面地理解复杂的场景和交互,这在自然语言处理、图像和视频分析、机器人技术、以及改善用户界面的交互体验方面尤为重要。
示例论文:PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
全文下载:https://arxiv.org/abs/2403.02781
2.6 语义分割(Semantic Segmentation)
基本概念:语义分割是计算机视觉领域的一项核心技术,其目标是将图像划分为多个区域,并为每个区域分配一个类别标签,从而使计算机能够理解图像中每个像素属于哪一个类别。这项技术使得机器可以区分并理解图像中的个体物体和整体场景,例如,将道路、行人、车辆和建筑物在街景图像中明确区分开来。语义分割广泛应用于自动驾驶、医疗图像分析、机器人感知以及增强现实等领域,是实现精细视觉识别和理解的基石之一。
示例论文:Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
全文下载:https://arxiv.org/abs/2312.04265
2.7 目标检测(Object Detection)
基本概念:目标检测指的是识别并定位图像或视频中特定对象或特征的过程。这涉及到分析视觉数据,如人脸、车辆、行人或任何特定类别的物体,并通常输出这些对象的边界框或精确位置。检测算法需要区分不同的对象,并在多样化的背景、光照条件、对象尺寸和姿态中保持鲁棒性。目标检测技术广泛应用于多个领域,包括安全监控、自动驾驶汽车、图像编辑软件、人机交互和工业视觉系统。
示例论文:YOLO-World: Real-Time Open-Vocabulary Object Detection
全文下载:https://arxiv.org/abs/2401.17270
2.8 CLIP
基本概念:CLIP (Contrastive Language-Image Pre-training, CLIP)是一种先进的多模态机器学习模型,它通过在大规模的图像和文本数据集上进行预训练,学会理解图像内容和文本描述之间的关联。CLIP模型包含两个主要部分:一个用于处理图像的视觉编码器和一个用于理解文本的语言编码器。这两个编码器共同训练,以预测图像和配对的文字描述之间的正确匹配。CLIP的强大之处在于它对任何图像和任意文本之间关系的泛化能力,这使得它在不同的视觉任务中,如图像分类、对象检测、甚至零样本学习等方面都展示了出色的性能。
示例论文:Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
全文下载:https://arxiv.org/abs/2312.03818
2.9 超分辨率(Super Resolution)
基本概念:超分辨率(Super Resolution)是通过算法增强图像的分辨率,从而改善低分辨率图像的细节和质量。这些技术通过添加丢失的高频信息,或从多个低分辨率图像合成一个高分辨率图像来实现,常见于深度学习方法,如卷积神经网络(CNN)。超分辨率技术在监控视频增强、医学成像、卫星图像处理以及提升消费者电子产品如电视和手机的视觉体验中有广泛的应用。它对于从有限数据中恢复丰富细节,提升图像清晰度和视觉效果具有重要价值。
示例论文:APISR: Anime Production Inspired Real-World Anime Super-Resolution
全文下载:https://arxiv.org/abs/2403.01598
2.10 知识蒸馏(Knowledge Distillation)
基本概念:知识蒸馏(Knowledge Distillation)是一种在计算机视觉领域应用广泛的模型压缩技术,它旨在将一个大型、训练好的复杂模型(称为教师模型)的知识转移至一个更小、更高效的模型(称为学生模型)。通过这种方式,学生模型能够在保持相对较高准确率的同时,减少计算资源的消耗和提高运行效率。这项技术对于在移动设备和边缘计算设备上运行大型深度学习模型尤为重要,广泛应用于图像分类、目标检测和面部识别等计算机视觉任务中。
示例论文:Efficient Dataset Distillation via Minimax Diffusion
全文下载:https://arxiv.org/abs/2311.15529
上述的热门研究方向是根据CVPR 2024的会议论文进行归纳和分析得到的,希望本篇内容能够为读者追踪计算机视觉的研究热点提供一些有价值的参考。
版权归原作者 audyxiao001 所有, 如有侵权,请联系我们删除。