
Qualcomm® AI Engine Direct 使用手册(20)
7 转换器
7.1 概述
Qualcomm® AI Engine Direct目前支持四种框架的转换器:Tensorflow、TFLite、PyTorch 和 Onnx。每个转换器至少需要原始框架模型作为输入来生成 Qualcomm® AI Engine 直接模型。有关其他所需的输入,请参阅下面的框架特定部分。
每个转换器的流程是相同的:
转换器工作流程
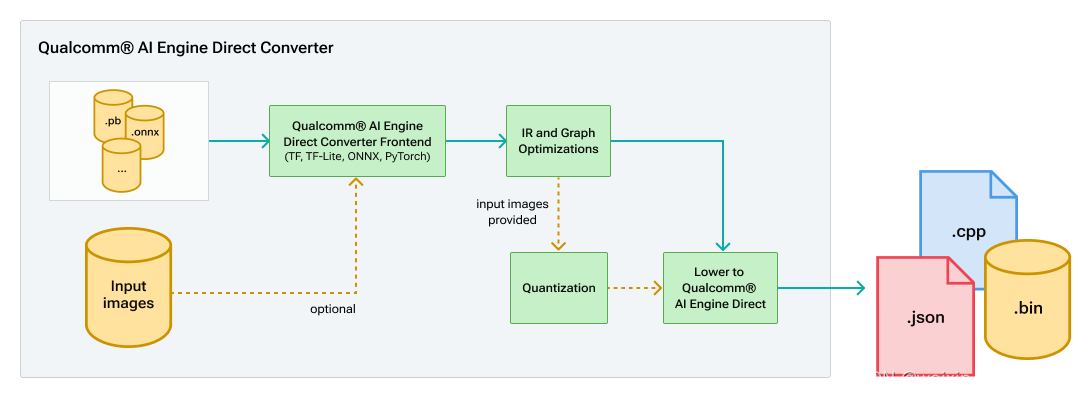
每个转换器有四个主要部分:
- 前端翻译,负责将原始框架模型转换为通用中间表示(IR)
- 通用 IR 代码包含图形和 IR 操作定义以及可应用于翻译图形的各种图形优化。
- 量化器,可以选择调用它来在最终降低为 QNN 之前量化模型。有关详细信息,请参阅量化。
- Qnn 转换器后端负责将 IR 降低到最终的 QnnModel API 调用中。
所有转换器共享相同的 IR 代码和 QNN 转换器后端。每个转换器的输出都是相同的,即model.cpp或model.cpp/model.bin,其中包含最终转换的 QNN 图。转换后的model.cpp包含两个函数:QnnModel_composeGraphs和QnnModel_freeGraphsInfo。这两个函数利用 下面描述的工具实用程序 API。此外,还保存了model_net.json ,它是model.cpp的 json 格式变体。
QNN 模型 JSON 格式
笔记
所有 QNN 枚举/宏值都在字段中解析。
所有输入/输出张量都存储在“tensors”配置部分中,张量名称稍后用于定义节点输入/输出。节点配置中定义的唯一张量是张量参数。
静态输入张量数据不存储在 JSON 中。
{"model.cpp":"<CPP filename goes here>","model.bin":"<BIN filename goes here if applicable else NA>","coverter_command":"<command line used goes here>","copyright_str":"<copyright str goes here if applicable else "">","op_types":["list of unique op types found in graph"]"Total parameters":"total parameter count in graph ( value in MB assuming single precision float)","Total MACs per inference": "total multiply and accumulates in graph count in M),"graph":{"tensors":{
"<tensor_name>:{"id":<generated_id>,"type":<tensor_type>,"dataFormat":<tensor_memory_layout>,"data_type":<tensor_data_type>,"quant_params":{"definition":<enum_value>,"encoding":<enum_value>,"scale_offset":{"offset":<val>,"scale":<val>}}"current_dims":<list_val>,"max_dims":<list_val>,"params_count":<val>("parameter count for node, along with value/total percentage. (only where applicable)")},
"<tensor_name_with_axis_scale_offset_variant>:{"id":<generated_id>,"type":<tensor_type>,"dataFormat":<tensor_memory_layout>,"data_type":<tensor_data_type>,"quant_params":{"definition":<enum_value>,"encoding":<enum_value>,"axis_scale_offset":{"axis":<val>,"num_scale_offsets":<val>,"scale_offsets":[{"scale":<val>,"offset":<val>},...]}}"current_dims":<list_val>,"max_dims":<list_val>},...}"nodes":{
"<node_name>:{"package":<str_val>,"type":<str_val>,"tensor_params":{"<param_name>":{
"<tensor_name_*>:{"id":<generated_id>,"type":<tensor_type>,"dataFormat":<tensor_memory_layout>,"data_type":<tensor_data_type>,"quant_params":{"definition":<enum_value>,"encoding":<enum_value>,"scale_offset":{"offset":<val>,"scale":<val>}"current_dims":<list_val>,"max_dims":<list_val>,"data":<list_val>}}...},"scalar_params":{"param_name":{"param_data_type":<val>}...},"input_names":<list_str_val>,"output_names":<list_str_val>,"macs_per_inference":<val>("multiply and accumulate value for node, along with value/total percentage. (only where applicable)")}...}}}
工具 实用程序 API
工具实用程序 API 包含用于生成 QNN API 调用的帮助程序模块。这些 API 是核心 QNN API 之上的轻量级包装器,旨在减少创建 QNN 图的重复步骤。
工具实用程序 C++ API:- 类层次结构- 文件层次结构- 完整的API
QNN Core C API 参考:C
QNN 模型类
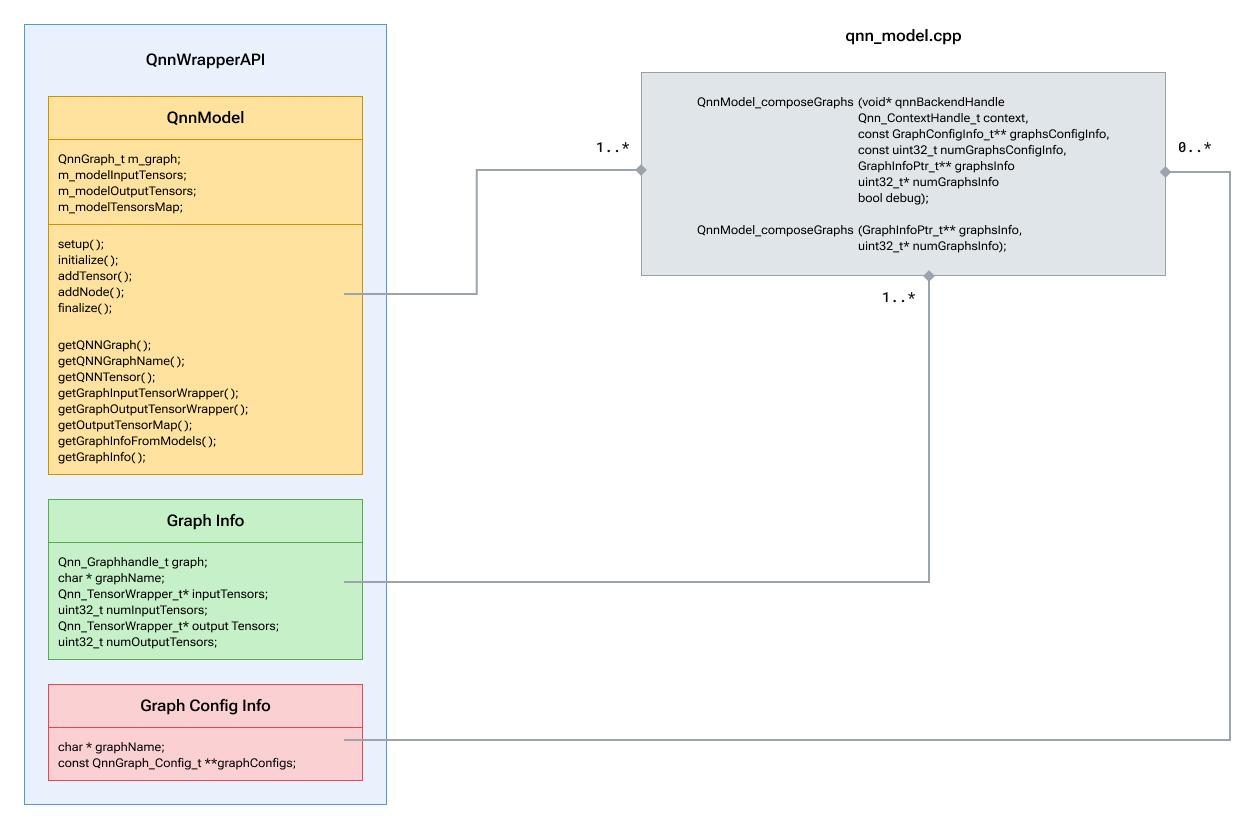
- QnnModel:此类类似于给定上下文中的 QnnGraph 及其张量。应在初始化时提供上下文,并在其中创建一个新的 QnnGraph。有关这些类 API 的更多详细信息,请参阅 QnnModel.hpp、 QnnWrapperUtils.hpp
- GraphConfigInfo:此结构用于从客户端传递 QNN 图配置列表(如果适用)。 有关可用图形配置选项的详细信息,请参阅QnnGraph API 。
- GraphInfo:此结构用于将构造的图及其输入和输出张量传递给客户端。
- QnnModel_composeGraphs:负责使用 QnnModel 类在提供的 QNN 后端上构建 QNN 图。它将通过 graphsInfo 返回构造的图。
- QnnModel_freeGraphsInfo:只有在图表不再使用时才应该调用。
有关将模型集成到应用程序中的更多信息,请参阅集成工作流程。
7.2 张量流转换
与许多其他神经网络运行时引擎一样,QNN 支持低级操作(如元素乘法)和高级操作(如 Prelu)。另一方面,TensorFlow 通常通过将高级操作表示为低级操作的子图来支持高级操作。为了协调这些差异,转换器有时必须将小型操作的子图模式匹配为可在 QNN 中利用的更大的“类层”操作。
7.2.1 模式匹配
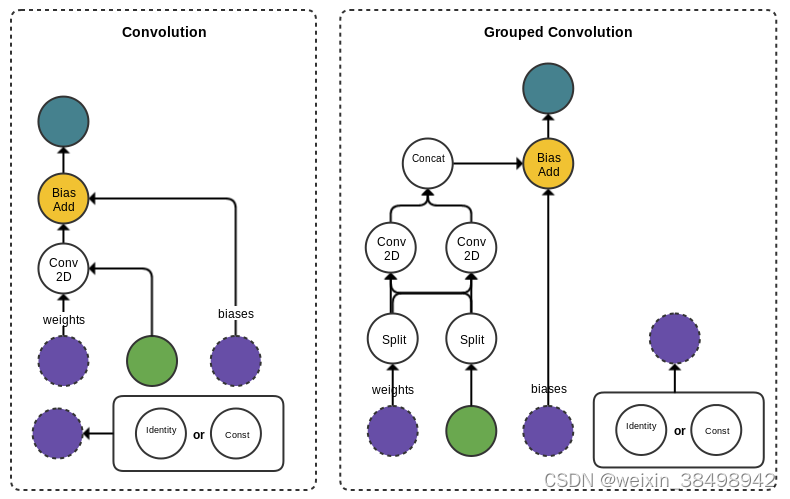
以下是 QNN Tensorflow 转换器中发生的模式匹配的几个示例。在每种情况下,该模式通常由落在层输入和输出之间的任何操作组成,并且权重和偏差等附加参数被吸收到最终的 IR 操作中。

卷积示例:
前奏示例:
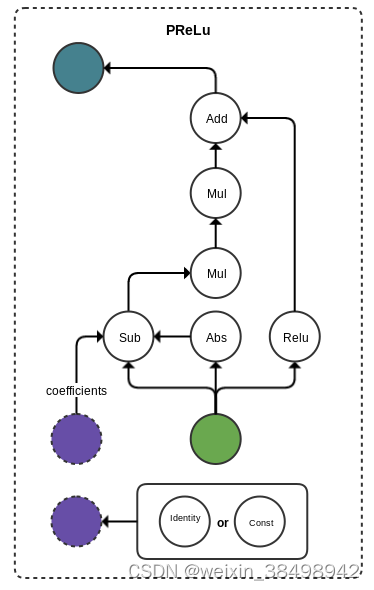
需要记住的重要一点是,这些模式是硬编码在转换器中的。影响这些模式中操作的连接性和顺序的模型更改也可能会破坏转换,因为转换器将无法识别子图并将其映射到适当的层。
TF 转换器还支持将量化感知训练 (QAT) 模型参数传播到最终的 QNN 模型。当调用量化时,这会在转换过程中自动发生。请注意,量化节点的放置也决定了它们是否会被传播。在模式内插入量化节点将导致模式匹配中断和转换失败。插入节点的安全位置是在“类似层”的层之后,以捕获层的激活信息。此外,在权重和偏差之后插入的量化节点可以捕获静态参数的量化信息。
在卷积后插入量化节点的示例:

有关在转换过程中启动量化的更多信息,请参阅量化。
7.2.2 额外必需的参数
由于 Tensorflow 图通常包含一般推理不需要的无关节点,因此需要提供输入节点和维度以及推理所需的最终输出节点。然后,转换器将从图中删除不必要的节点,以确保图形更加紧凑和高效。
要指定转换器的图形输入,请在命令行上传递以下命令:
--input_dim <input_name><comma separated dims>
要指定图形的输出节点,只需传递:
--out_node <output_name>
Tensorflow也有多种输入格式,但仅支持冻结图(.pb文件)或.meta文件。转换器不支持保存的培训课程。
7.2.3 有关 Tensorflow 2.x 支持的说明
qnn-tensorflow-converter 已更新,支持 Tensorflow 2.3 模型的转换。请注意,虽然某些 TF 1.x 模型可能使用 Tensorflow 2.3 作为转换框架进行转换,但通常建议使用与训练模型相同的 TF 版本进行转换。某些较旧的 1.x 模型可能根本无法使用 TF 2.3 进行转换,并且可能需要 TF 1.x 实例才能成功转换。
请注意,一些选项已更新或添加以支持 Tensorflow 2.x 模型。第一个是支持 SavedModel 格式的更改。用户可以通过将目录传递给相同的 input_network 选项来提供 SavedModel 文件的目录:
--input_network <SavedModel path>
用户可以选择传递saved_model_tag来指示来自SavedModel的标签和关联的MetaGraph。默认为“服务”
--saved_model_tag <tag>
最后,用户可以使用签名密钥选择模型的输入和输出。默认值为“默认服务”
--saved_model_signature_key <signature_key>
7.2.4 例子
下面是一个 SSD 模型的示例,需要一张图像输入,但有 4 个输出节点。
qnn-tensorflow-converter --input_network frozen_graph.pb --input_dim Preprocessor/sub 1,300,300,3--output_path ssd_model.cpp --out_node detection_scores --out_node detection_boxes --out_node detection_classes --out_node Postprocessor/BatchMultiClassNonMaxSuppression/map/TensorArrayStack_2/TensorArrayGatherV3 -p "qti.aisw"
7.3 TFLite 转换
将qnn-tflite-converterTFLite 模型转换为等效的 QNN 表示。它采用 .tflite 模型作为输入。
7.3.1 额外必需的参数
TFlite 转换器需要在命令行提供输入节点的名称和尺寸以进行转换。每个输入必须使用相同的参数单独传递。
要指定转换器的图形输入,请在命令行上传递以下命令:
--input_dim <input_name_1><comma separated dims>--input_dim <input_name_2><comma separated dims>
例子
以下是转换 Inception_v3 模型的示例,需要一张图像输入
qnn-tflite-converter --input_network model.tflite --input_dim "input"1,299,299,3--output_path model.cpp
7.4 PyTorch 转换
将qnn-pytorch-converterPyTorch 模型转换为等效的 QNN 表示。它采用 TorchScript 模型 (.pt) 作为输入。
7.4.1 额外必需的参数
PyTorch 转换器需要在命令行提供输入节点的名称和尺寸以进行转换。每个输入必须使用相同的参数单独传递。
要指定转换器的图形输入,请在命令行上传递以下命令:
--input_dim <input_name_1><comma separated dims>--input_dim <input_name_2><comma separated dims>
7.4.2 例子
以下是转换 Inception_v3 模型的示例,需要一张图像输入
qnn-pytorch-converter --input_network model.pt --input_dim "input"1,3,299,299--output_path model.cpp
7.5 Onnx 转换
将qnn-onnx-converter序列化 ONNX 模型转换为等效的 QNN 表示。默认情况下,如果用户环境中可用,它还会运行 onnx-simplifier(请参阅设置)。此外,onnx-simplifier 仅在用户未提供量化覆盖/自定义操作时默认运行,因为简化过程可能会挤压图层,从而阻止使用自定义操作或量化覆盖。如果模型包含 ONNX 函数,转换器始终会内联函数节点。注意:如果转换失败,onnx 转换器支持附加选项“–dry_run”,它将转储有关不支持的操作和关联参数的详细信息。
例子
qnn-onnx-converter --input_network model.onnx --output_path model.cpp
7.6 自定义操作输出形状推断
QNN 转换器要求模型中存在所有操作的输出形状才能成功转换。如果模型中存在自定义操作的输出形状,则可以从模型中推断出来,或者使用框架的形状推断脚本进行推断。当模型中不存在自定义操作的输出形状或无法从框架的形状推断脚本推断出自定义操作的输出形状时,可以通过使用Convter Op Package Generation编译的共享库向转换器提供推断自定义操作输出形状的逻辑 。–converter_op_package_lib编译库可以通过或选项提供, -cpl后跟编译库的绝对路径。转换器采用该库并推断成功模型转换所需的自定义操作的输出形状。多个库必须以逗号分隔。
笔记
–converter_op_package_libor-cpl是一个可选参数,当模型中不存在自定义操作的输出形状或无法从框架的形状推断脚本推断出时,应使用该参数。
例子
qnn-onnx-converter --input_network model.onnx --converter_op_package_lib libExampleLibrary.so
笔记
有关库生成和编译说明,请参阅Convter Op Package Generation 。
仅 ONNX 和 PyTorch 转换器支持自定义操作输出形状推断。
Tensorflow和TFLite转换器不支持自定义操作输出形状推断。
7.7 自定义输入/输出
介绍
自定义 I/O 功能允许用户在加载网络时为输入和输出提供所需的布局和数据类型。网络不是针对模型中指定的输入和输出编译网络,而是针对自定义配置中描述的输入和输出进行编译。当用户打算预处理(在 GPU/CDSP 或任何其他方法上)或离线处理(如 ML commons 允许的)输入数据并避免输入处理中的某些步骤时,可以使用此功能。如果用户了解输入预处理步骤,则可以避免冗余转置和数据类型转换。类似地,在后处理方面,如果要将模型输出馈送到管道中的下一个阶段,则可以将所需的格式和类型配置为当前阶段的输出。
在本节中,术语“模型I/O”是指原始模型的输入和输出数据类型和格式。术语“自定义 I/O”是指用户所需的输入和输出数据类型和格式。
自定义 I/O 配置文件
可以使用配置 yaml 文件来应用自定义 I/O,该文件包含需要修改的每个输入和输出的以下字段。
- IOName:模型中需要根据自定义要求加载的输入或输出的名称。
- 布局:布局字段(可选)有两个子字段:模型和自定义。模型和自定义字段支持有效的 QNN 布局。接受的值为:NCDHW、NDHWC、NCHW、NHWC、NFC、NCF、NTF、TNF、NF、NC、F、NONTRIVIAL,其中,N = 批次、C = 通道、D = 深度、H = 高度、W = 宽度, F = 特征,T = 时间- 模型:指定原始模型中缓冲区的布局。这相当于 –input_layout 选项,并且两者不能一起使用。- 自定义:指定缓冲区所需的自定义布局。该字段需要由用户填写。
- 数据类型:数据类型字段(可选)支持 float32、float16 和 uint8 数据类型。
- QuantParam:QuantParam 字段(可选)具有三个子字段:Type、Scale 和 Offset。- 类型:如果比例和偏移由用户提供,则设置为 QNN_DEFINITION_DEFINED(默认),否则设置为 QNN_DEFINITION_UNDEFINED。- 比例:用户所需的缓冲区比例的浮点值。- 偏移量:用户所需的偏移量的整数值。
例子
考虑具有原始模型 I/O 和自定义 I/O 配置的 ONNX 模型,如下表所示:
输入/输出名称型号输入/输出自定义输入/输出“输入_0”浮动NCHWint8 NHWC“输出_0”浮动NHWC浮动NCHW
那么,需要提供的自定义I/O配置yaml文件内容为
- IOName: input_0
Layout:
Model: NCHW
Custom: NCHW
Datatype: uint8
QuantParam:
Type:
QNN_DEFINITION_DEFINED
Scale:0.12
Offset:2- IOName: output_0
Layout:
Model: NHWC
Custom: NCHW
笔记:
如果输入或输出不需要更改,则可以在配置文件中跳过。
仅当模型输入或输出数据类型为 float、float16、int8 或 uint8 时,才可以使用自定义 I/O 功能修改数据类型。对于其他数据类型,应在配置文件中跳过“数据类型”字段。
用法
–custom_io可以使用选项提供自定义 IO 配置 YAMl 文件qnn-onnx-converter。使用示例如下:
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \
--custom_io <path/to/YAML/file>....
自定义 IO 配置模板文件
–dump_custom_io_config_template可以使用选项获取填充有默认值的自定义 IO 配置文件qnn-onnx-converter。
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \
--input_network ${QNN_SDK_ROOT}/examples/Models/InceptionV3/tensorflow/model.onnx \
--dump_custom_io_config_template <output_folder>/config.yaml
转储的模板文件对于所提供的模型的每个输入和输出都有一个条目。模板文件中的每个字段都填充从该特定输入或输出的模型中获得的默认值。模板文件还包含为用户描述每个字段的注释。
支持的用例
- 模型的输入和输出缓冲区的布局转换。有效的布局转换是以下之间的相互转换:- NCDHW 和 NDHWC- NHWC 和 NCHW- NFC 和 NCF- NTF 和 TNF
- 将数据类型 uint8 或 int8 的量化输入传递给非量化模型。在这种情况下,用户必须提供量化输入的比例和偏移量。
- 用户可以为量化模型的输入和输出提供自定义比例和偏移。量化器生成的比例和偏移量将被用户在 YAML 文件中提供的比例和偏移量覆盖。
用户可以使用–input_data_type和–output_data_type选项qnn-net-run来提供 float 或 uint8_t 类型数据来建模输入/输出。用户可以使用该native选项向模型传递和获取 int8/uint8 数据。默认情况下,qnn-net-run假设数据为 float32 类型,并在量化模型的情况下在输入处执行量化并在输出处执行去量化。
局限性
- 自定义 IO 仅支持提供以下数据类型:float32、float16、uint8、int8。
- 如果用户需要将量化输入(即 int8 或 uint8 类型)传递给非量化模型,则用户必须在 YAML 文件中提供比例和偏移量。在这种情况下,不提供比例和偏移量会引发错误。
7.8 保留 I/O
介绍
保留 I/O 功能允许用户保留原始 ONNX 模型中存在的输入和输出的布局和数据类型。由于 QNN 转换器在模型输入和输出处的默认行为,此功能允许用户避免任何将数据转换为布局和数据类型的预处理或后处理步骤。
用法
使用此选项的不同方法如下:
- 用户可以通过传递–preserve_io以下选项来选择保留所有 IO 张量的布局和数据类型:
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io .... - 用户可以选择为图表的所有输入和输出保留唯一的布局或数据类型,如下所示:
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io layout ....or,$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io datatype.... - 用户可以选择仅保留图形的少数输入和输出的布局或数据类型,如下所示:
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io layout <space separated list of names of inputs and outputs of the graph>....or,$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io datatype <space separated list of names of inputs and outputs of the graph>.... - 用户可以传递和的组合,如下所示:–preserve_io layout–preserve_io datatype
$ ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter \ --preserve_io layout <space separated list of names of inputs and outputs of the graph> \ --preserve_io datatype <space separated list of names of inputs and outputs of the graph>....
仅仅并一起通过是有效的并且等同于仅通过。第 3 点中的用法不能与第 1 点或第 2 点中的用法结合使用,如果一起使用将导致错误。–preserve_io layout–preserve_io datatype–preserve_io
与其他转换器选项一起使用
- –keep_int64_inputs如果使用保留 IO 来保留此类输入的数据类型,则不需要传递。
- –use_native_input_files如果使用保留 IO 来保留数据类型,则在量化的情况下设置为 True。
- –input_layout遵循指定使用的布局。
- –input_dtype如果任何 IO 张量的数据类型不匹配,则与保留 IO 一起使用可能会导致错误。
- 使用 指定的布局和数据类型的–custom_io优先级高于–preserve_io。
由于保留 IO 保留原始模型中 IO 张量的数据类型,因此用户必须使用–use_native_input_filesor 。–native_input_tensor_namesqnn-net-run
版权归原作者 weixin_38498942 所有, 如有侵权,请联系我们删除。