
文章目录
前言
大规模语言模型(Large Language Models,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。
一、语言模型发展历程
语言模型旨在对于人类语言的内在规律进行建模,从而准确预测词序列中未来(或缺失)词的概率。语言模型分为以下四个主要发展阶段:
1. 第一阶段:统计语言模型(Statistical Language Model, SLM)
统计语言模型基于马尔可夫假设,通过n元(n-gram)方法预测下一个词的出现概率。这些模型在信息检索和自然语言处理中得到广泛应用。然而,它们受限于固定上下文长度,难以捕捉长距离依赖关系,且面临数据稀疏问题。
2. 第二阶段:神经语言模型(Neural Language Model, NLM)
神经语言模型利用循环神经网络(RNN)和词嵌入(Word Embedding)来建模文本序列。与n元模型相比,神经网络方法能够更好地处理数据稀疏问题,并且有助于捕捉长距离依赖关系。但是,早期的神经网络模型在长文本建模能力上存在局限性,且不易并行训练。
3. 第三阶段:预训练语言模型(Pre-trained Language Model, PLM)
预训练语言模型通过在大规模无标注数据上进行预训练,学习上下文感知的单词表示。代表性模型如ELMo、BERT和GPT-1,它们确立了“预训练-微调”范式,通过预训练建立基础能力,然后使用有标注数据进行特定任务的适配。这一阶段的模型改进了长文本建模能力,但仍存在优化空间,特别是在并行训练和硬件友好性方面。
4. 第四阶段:大语言模型(Large Language Model, LLM)
大语言模型通过“扩展法则”(增加模型参数规模或数据规模)进一步提升模型性能。同时,在尝试训练更大的预训练语言模型(例如 175B 参数的 GPT-3 和 540B 参数的 PaLM)来探索扩展语言模型所带来的性能极限过程中。这些大规模的预训练语言模型在解决复杂任务时表现出了与小型预训练语言模型(例如 330M 参数的 BERT 和 1.5B 参数的 GPT-2)不同的行为。例如,GPT-3 可以通过“上下文学习”(In-Context Learning, ICL)的方式来利用少样本数据解决下游任务,这种能力称为:涌现能力。为了区分这一能力上的差异,学术界将这些大型预训练语言模型命名为“大语言模型”,同时大规模模型的训练和应用带来了计算资源和环境影响等方面的挑战。
注意:大语言模型不一定比小型预训练语言模型具有更强的任务效果,而且某些大语言模型中也可能不具有某种涌现能力,和训练的数据质量和方式也有很大的关系。
涌现能力: 主要的涌现能力包括以下3种
1)上下文学习能力:在提示中为大语言模型提供指令和多个任务示例;不需要显式的训练或梯度更新,仅输入文本的单词序列 就能为测试样本生成预期的输出。
2)指令遵循:大语言模型能够按照自然语言指令来执行对应的任务。为了获得这一能力,通常需要使用自然语言描述的多任务示例数据集进行微调,称为指令微调(Instruction Tuning)或监督微调(Supervised Fine-tuning)。通过指令微调,大语言模型可以在没有使用显式示例的情况下按照任务指令完成新任务,有效提升了模型的泛化能力。
3)逐步推理:大语言模型则可以利用思维链(Chain-of-Thought, CoT)提示策略来加强推理性能。具体来说,大语言模型可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更为可靠的答案
二、大语言模型的能力特点
1. 丰富的世界知识
相较于传统机器学习模型和早期预训练模型(如BERT、GPT-1),大语言模型通过更大规模的数据预训练,能更全面地吸收世界知识。这使得它们在处理特定领域任务时,不再像传统机器学习算法严重依赖微调相关的技术手段。
2. 通用任务解决能力
大语言模型主要通过预测下一个词元的预训练任务进 行学习,够建立了远强于传统模型的通用任务求解能力。这种能力使其在多个自然语言处理任务中取得卓越表现,逐渐取代了传统的任务特定解决方案。例如,在自然语言处理 领域,很多传统任务(如摘要、翻译等)都可以采用基于大语言模型的提示学习 方法进行解决,而且能够获得较好的任务效果。
3. 复杂任务推理能力
大语言模型在复杂推理任务上展现出较强的能力,例如复杂的知识关系推理和数学问题解答。相比之下,传统方法需针对性修改或特定数据学习,而大模型凭借大规模文本数据预训练,显示出更强的综合推理能力。
4. 人类指令遵循能力
大语言模型通过预训练和微调,获得了较好的人类指令遵循能力,能够直接通过自然语言描述执行任务(提示学习)。这一能力为打造以人为中心的应用服务(如智能音箱、信息助手等)提供了自然而通用的技术路径。
5. 人类对齐能力
随着大语言模型性能的提升,其安全性成为关注焦点。采用基于人类反馈的强化学习技术进行对齐,使得模型在线上部署时能有效阻止功能滥用行为,规避使用风险。
6. 工具使用能力
大语言模型展现了可拓展的工具使用能力,可以通过微调、上下文学习等方式掌握外部工具的使用,如搜索引擎与计算器;类似人类利用技术与工具扩展认知与能力。很多先进的模型都支持多种工具使用,增强任务解决能力。
三、大语言模型关键技术
1. 规模扩展
大语言模型性能提升依赖于参数、数据和算力的增加。OpenAI提出的“扩展法则”定量描述了这种关系,GPT-3验证了千亿参数规模的有效性。
2. 数据工程
模型能力本质上是来源于所见过的训练数据,因此数据工程就变得极为重要,不是简单的扩大数据规模就能够实现的。目前来说,数据工程主要包括三个方面:首先,需要对于数据进行全面的采集,拓宽高质量的 数据来源;其次,需要对于收集到的数据进行精细的清洗,尽量提升用于大模型训练的数据质量;第三,需要进行有效的数据配比与数据课程,加强模型对于数据语义信息的利用效率。这三个方面的数据工程技术直接决定了最后大语言模型的性能水平。
3. 高效预训练
由于参数规模巨大,需要使用大规模分布式训练算法优化大语言模型的神经网络参数。在训练过程中,需要联合使用各种并行策略以及效率优化方法,包括 3D 并行(数据并行、流水线并行、张量并行)、ZeRO(内存冗余消除技术)等。比如训练框架:DeepSpeed和 Megatron-LM。
4. 能力激发
通过指令微调和提示词的设计激发或诱导,增强大语言模型的通用任务求解能力。
1)指令微调方面: 使用自然语言表达的任务描述以及期望的任务输出对于大语言模型进行指令 微调,从而增强大语言模型的通用任务求解能力,提升模型在未见任务上的泛化能力。
2)提示学习方面:设计合适的提示策略去诱导大语言模型生成正确的问题答案。比如:上下文学习、思维链提示等,通过构建特殊的提 示模板或者表述形式来提升大语言模型对于复杂任务的求解能力。提示工程已经 成为利用大语言模型能力的一个重要技术途径。
进一步,大语言模型还具有较好的规划能力,能够针对复杂任务生成逐步求解的解决方案,从而简化通过单一步骤直接求解任务的难度,进一步提升模型在复杂任务上的表现
5. 人类对齐
1)互联网上开放的无标注文本数据的内容覆盖范围较广,可能包含低质量、个人隐私、事实错误的数据信息。因此,经过海量无标注文本预训练的大语言模型可能会生成有偏见、泄露隐私甚至对人类有害的内容。因此,需要保证大语言模型能够较好地符合人类的价值观。
2)目前,比较具有代表性的对齐标准是“3 H 对齐标准”,即 Helpfulness(有用性)、Honesty(诚实性)和 Harmlessness(无害性)。
OpenAI 提出了基于人类反馈的强化学习算法(Reinforcement Learning from Human Feedback, RLHF),将人类偏好引入到大模型的对齐过程中:首先训练能够区分模型输出质量好坏的奖励模型,进而使用强化学习算法来指导语言模型输出行为的调整,让大语言模型能够生成符合人类预期的输出。
6. 工具使用
1)通过让大语言模型学会使用各种工具的调用方式,进而利用合适的工具去实现特定的功能需求。例如,大语言模型可以利用计算器进行精确的数值计算,利用搜索引擎检索最新的时效信息。通过这些插件外挂扩展大语言模型的能力范围。
2)由于大语言模型的能力主要是通过大规模文本数据的语义学习所建立的,因此在非自然语言形式的任务(如数值计算)中能力较为受限。此外, 语言模型的能力也受限于预训练数据所提供的信息,无法有效推断出超过数据时 间范围以及覆盖内容的语义信息。为了解决上述问题,工具学习成为一种扩展大语言模型能力的关键技术。
四、大语言模型的构建过程
大语言模型是一种基于Transformer 结构的神经网络模型;其构建过程就是使用训练数据对于模型参数的拟合过程。他的本质是在做模型参数的优化,希望能够作为通用任务的求解器。通过一种非常符复杂、精细的训练方法来进行构建;这个训练过程可以分为大规模预训练和指令微调与人类对齐两个大阶段;同时又分为四小个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模型。
1.预训练阶段
预训练(Pretraining)阶段需要利用海量的训练数据,包括互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。利用由数千块高性能GPU 和高速网络组成超级计算机,花费数十天完成深度神经网络参数训练,构建基础语言模型(Base Model)。基础大模型构建了长文本的建模能力,使得模型具有语言生成能力,根据输入的提示词(Prompt),模型可以生成文本补全句子。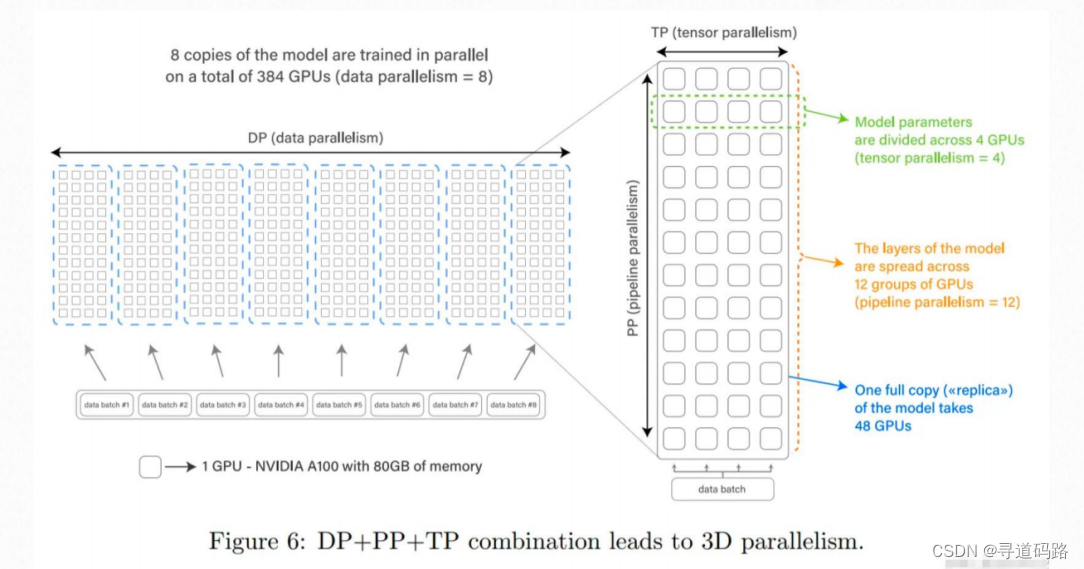
2.有监督微调阶段
1)有监督微调(Supervised Finetuning)也称为指令微调(Instruction Tuning),利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。
2)利用这些有监督数据,使用与预训练阶段相同的语言模型训练算法,在基础语言模型基础上再进行训练,从而得到有监督微调模型(SFT 模型)。经过训练的 SFT 模型具备了初步的指令理解能力和上下文理解能力,能够完成开放领域问题、阅读理解、翻译、生成代码等能力,也具备了一定的对未知任务的泛化能力
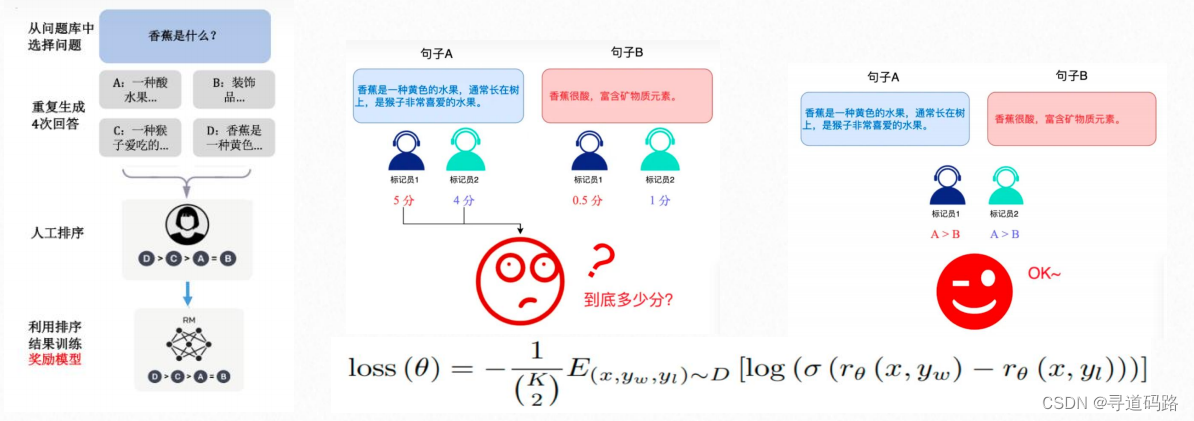
3.奖励建模阶段
奖励建模(Reward Modeling)阶段目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。
奖励模型(Reward Model): 当我们在做完 SFT 后,我们大概率已经能得到一个还不错的模型。但我们回想一下 SFT 的整个过程:我们一直都在告诉模型什么是「好」的数据,却没有给出「不好」的数据。我们更倾向于 SFT 的目的只是将 Pretrained Model 中的知识给引导出来的一种手段,而在SFT数据有限的情况下,我们对模型的「引导能力」就是有限的。这将导致预训练模型中原先「错误」或「有害」的知识没能在 SFT数据中被纠正,从而出现「有害性」或「幻觉」的问题。
4.强化学习阶段
1)强化学习阶段也叫人类对齐,基于人类反馈的强化学习对齐方法 RLHF(Reinforcement Learning from Human Feedback),让模型的输出与人类的期望、需求、价值观对齐。
2)强化学习(Reinforcement Learning)阶段根据数十万用户给出的提示词,利用前一阶段训练的RM模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
3)使用强化学习,在SFT 模型基础上调整参数,使得最终生成的文本可以获得更高的奖励(Reward)。该阶段需要的计算量相较预训练阶段也少很多,通常仅需要数十块GPU,数天即可完成训练。
以下面某位大佬对Llama模型进行预训练,期望能训练出来一个能翻译论语的模型为例:
Pretraining模型
SFT 模型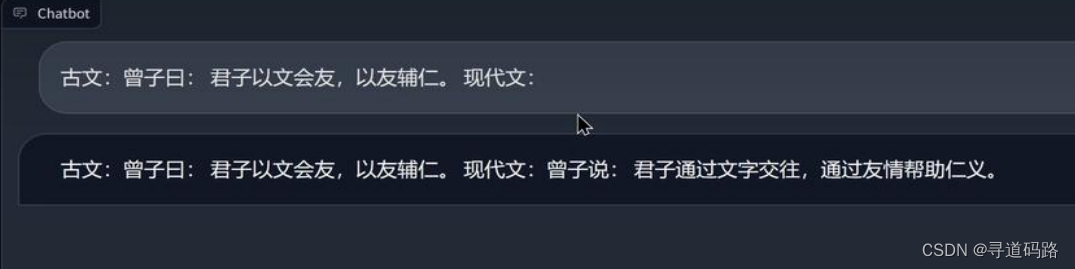 RLHF模型
RLHF模型
🔻系列篇章
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
🔖更多专栏系列文章:AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
版权归原作者 寻道AI小兵 所有, 如有侵权,请联系我们删除。