
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
AI大模型探索之路-实战篇10:数据预处理的艺术:构建Agent智能数据分析平台的基础
AI大模型探索之路-实战篇11: Function Calling技术整合:强化Agent智能数据分析平台功能
AI大模型探索之路-实战篇12: 构建互动式Agent智能数据分析平台:实现多轮对话控制
目录
一、前言
在前面篇章中我们实现了多轮对话控制,本文中我们将实现多轮对话内容的云盘记录,将对话内容记录存储到本地云盘文件夹中;之后再基于对话内容,数据字典、数据库表相关的基本信息实现一个简单的数据分析报告撰写功能
二、本地云盘创建
为了持久化存储对话记录,我们将创建一个本地文件夹,模拟云盘的功能。
1、创建文件目录
定义创建文件目录的函数,作为云盘存储记录
import os
defcreate_directory(directory):"""
根据项目创建云盘目录
"""
base_path ="/root/autodl-tmp/iquery项目/iquery云盘"
full_path = os.path.join(base_path, directory)# 如果目录不存在,则创建它ifnot os.path.exists(full_path):
os.makedirs(full_path)print(f"目录 {directory} 创建成功")else:print(f"目录 {directory} 已存在")
创建文件夹目录
directory ="my_directory"
create_directory(directory)
输出:
2、doc文档操作函数定义
安装依赖pip install python-docx
定义doc文档操作函数,用于向文档追加内容
import os
from docx import Document
defappend_in_doc(folder_name, doc_name, qa_string):""""
往文件里追加内容
@param folder_name=目录名,doc_name=文件名,qa_string=追加的内容
"""
base_path ="/root/autodl-tmp/iquery项目/iquery云盘"## 目录地址
full_path_folder=base_path+"/"+folder_name
## 文件地址
full_path_doc = os.path.join(full_path_folder, doc_name)+".doc"# 检查目录是否存在,如果不存在则创建ifnot os.path.exists(full_path_folder):
os.makedirs(full_path_folder)# 检查文件是否存在if os.path.exists(full_path_doc):# 文件存在,打开并追加内容
document = Document(full_path_doc)else:# 文件不存在,创建一个新的文档对象
document = Document()# 追加内容
document.add_paragraph(qa_string)# 保存文档
document.save(full_path_doc)print(f"内容已追加到 {doc_name}")
3、doc内容追加测试
# 示例用法
append_in_doc('my_directory','example_doc','天青色等烟雨,而我在等你')

三、多轮对话本地云盘存储功能实现
将之前的篇章实现的多轮对话等功能,融入文档记录的功能
1、定义模型客户端
import openai
import os
import numpy as np
import pandas as pd
import json
import io
from openai import OpenAI
import inspect
import pymysql
openai.api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=openai.api_key)
2、定义工具函数生成器
defauto_functions(functions_list):"""
Chat模型的functions参数编写函数
:param functions_list: 包含一个或者多个函数对象的列表;
:return:满足Chat模型functions参数要求的functions对象
"""deffunctions_generate(functions_list):# 创建空列表,用于保存每个函数的描述字典
functions =[]# 对每个外部函数进行循环for function in functions_list:# 读取函数对象的函数说明
function_description = inspect.getdoc(function)# 读取函数的函数名字符串
function_name = function.__name__
system_prompt ='以下是某的函数说明:%s'% function_description
user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\
1.字典总共有三个键值对;\
2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\
3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\
4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\
5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_name
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content": system_prompt},{"role":"user","content": user_prompt}])
json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json",""))
json_str={"type":"function","function":json_function_description}
functions.append(json_str)return functions
max_attempts =4
attempts =0while attempts < max_attempts:try:
functions = functions_generate(functions_list)break# 如果代码成功执行,跳出循环except Exception as e:
attempts +=1# 增加尝试次数print("发生错误:", e)if attempts == max_attempts:print("已达到最大尝试次数,程序终止。")raise# 重新引发最后一个异常else:print("正在重新运行...")return functions
3、两次大模型API调用封装
封装funcation calling中两次大模型API得调用
defrun_conversation(messages, functions_list=None, model="gpt-3.5-turbo"):"""
能够自动执行外部函数调用的对话模型
:param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象
:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象
:param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo
:return:Chat模型输出结果
"""# 如果没有外部函数库,则执行普通的对话任务if functions_list ==None:
response = client.chat.completions.create(
model=model,
messages=messages,)
response_message = response.choices[0].message
final_response = response_message.content
# 若存在外部函数库,则需要灵活选取外部函数并进行回答else:# 创建functions对象
tools = auto_functions(functions_list)#tools = [{'type': 'function', 'function': {'name': 'sunwukong_function', 'description': '定义了数据集计算过程', 'parameters': {'type': 'object', 'properties': {'data': {'type': 'string', 'description': '表示带入计算的数据表,用字符串进行表示'}}, 'required': ['data']}}}, {'type': 'function', 'function': {'name': 'tangseng_function', 'description': '该函数定义了数据集计算过程', 'parameters': {'type': 'object', 'properties': {'data': {'type': 'string', 'description': '必要参数,表示带入计算的数据表,用字符串进行表示'}}, 'required': ['data']}}}]# 创建外部函数库字典
available_functions ={func.__name__: func for func in functions_list}# 第一次调用大模型
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice="auto",)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls:
messages.append(response_message)for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(**function_args)
messages.append({"tool_call_id": tool_call.id,"role":"tool","name": function_name,"content": function_response,})print(messages)## 第二次调用模型
second_response = client.chat.completions.create(
model=model,
messages=messages,)# 获取最终结果
final_response = second_response.choices[0].message.content
else:
final_response = response_message.content
return final_response
4、数据字典读取
# 打开并读取Markdown文件withopen('/root/autodl-tmp/iquery项目/data/数据字典/iquery数据字典.md','r', encoding='utf-8')as f:
md_content = f.read()
md_content
输出:
5、定义数据库表信息查询服务
defsql_inter(sql_query):"""
用于获取iquery数据库中各张表的有关相关信息,\
核心功能是将输入的SQL代码传输至iquery数据库所在的MySQL环境中进行运行,\
并最终返回SQL代码运行结果。需要注意的是,本函数是借助pymysql来连接MySQL数据库。
:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中iquery数据库中各张表进行查询,并获得各表中的各类相关信息
:return:sql_query在MySQL中的运行结果。
"""
mysql_pw ="iquery_agent"
connection = pymysql.connect(
host='localhost',# 数据库地址
user='iquery_agent',# 数据库用户名
passwd=mysql_pw,# 数据库密码
db='iquery',# 数据库名
charset='utf8'# 字符集选择utf8)try:with connection.cursor()as cursor:# SQL查询语句
sql = sql_query
cursor.execute(sql)# 获取查询结果
results = cursor.fetchall()finally:
connection.close()return json.dumps(results)
functions_list =[sql_inter]
6、定义SQL提取函数
import ast
defextract_sql(str):# 使用literal_eval将字符串转换为字典
dict_data = ast.literal_eval(json.dumps(str))# 提取'sql_query'的值
sql_query_value = dict_data['sql_query']+""# 提取并返回'sql_query'的值return sql_query_value
7、对话确认机制改造
defcheck_code_run(messages, functions_list=None, model="gpt-3.5-turbo",auto_run =True):"""
能够自动执行外部函数调用的对话模型
:param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象
:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象
:param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo
:return:Chat模型输出结果
"""# 如果没有外部函数库,则执行普通的对话任务if functions_list ==None:
response = client.chat.completions.create(
model=model,
messages=messages,)
response_message = response.choices[0].message
final_response = response_message.content
# 若存在外部函数库,则需要灵活选取外部函数并进行回答else:# 创建functions对象
tools = auto_functions(functions_list)# 创建外部函数库字典
available_functions ={func.__name__: func for func in functions_list}# 第一次调用大模型
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice="auto",)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls:
messages.append(response_message)for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)if auto_run ==False:print("SQL字符串的数据类型")print(type(function_args))
sql_query = extract_sql(function_args)
res =input('即将执行以下代码:%s。是否确认并继续执行(1),或者退出本次运行过程(2)'% sql_query)if res =='2':print("终止运行")returnNoneelse:print("正在执行代码,请稍后...")
function_response = function_to_call(**function_args)
messages.append({"tool_call_id": tool_call.id,"role":"tool","name": function_name,"content": function_response,})## 第二次调用模型
second_response = client.chat.completions.create(
model=model,
messages=messages,)# 获取最终结果
final_response = second_response.choices[0].message.content
else:
final_response = response_message.content
del messages
return final_response
8、多轮对话封装
import tiktoken
defchat_with_inter(functions_list=None,
prompt="你好呀",
model="gpt-3.5-turbo",
system_message=[{"role":"system","content":"你是一个智能助手。"}],
auto_run =True):print("正在初始化外部函数库")# 创建函数列表对应的参数解释列表
functions = auto_functions(functions_list)print("外部函数库初始化完成")
project_name =input("请输入当前分析项目名称:")
folder_name = create_directory(project_name)print("已完成数据分析文件创建")
doc_name =input("请输入当前分析需求,如数据清理,数据处理,数据分析段等:")
doc_name +='问答'print("好的,即将进入交互式分析流程")# 多轮对话阈值# 多轮对话阈值if'gpt-4'in model:
tokens_thr =6000elif'16k'in model:
tokens_thr =14000else:
tokens_thr =3000
messages = system_message
## 完成给用户输入的问题赋值
user_input = prompt
messages.append({"role":"user","content": prompt})## 计算token大小
embedding_model ="text-embedding-ada-002"# 模型对应的分词器(TOKENIZER)
embedding_encoding ="cl100k_base"
encoding = tiktoken.get_encoding(embedding_encoding)
tokens_count =len(encoding.encode((prompt + system_message[0]["content"])))whileTrue:
answer = check_code_run(messages,
functions_list=functions_list,
model=model,
auto_run = auto_run)print(f"模型回答: {answer}")#####################判断是否记录文档 start#######################whileTrue:
record =input('是否记录本次回答(1),还是再次输入问题并生成该问题答案(2)')if record =='1':
Q_temp ='Q:'+ user_input
A_temp ='A:'+ answer
append_in_doc(folder_name=project_name,
doc_name=doc_name,
qa_string=Q_temp)
append_in_doc(folder_name=project_name,
doc_name=doc_name,
qa_string=A_temp)# 记录本轮问题答案
messages.append({"role":"assistant","content": answer})breakelse:print('好的,请再次输入问题')
user_input =input()
messages[-1]["content"]= user_input
answer = check_code_run(messages,
functions_list=functions_list,
model=model,
auto_run = auto_run)print(f"模型回答: {answer}")########################判断是否记录文档 stop ######################## 询问用户是否还有其他问题
user_input =input("您还有其他问题吗?(输入退出以结束对话): ")if user_input =="退出":del messages
break# 记录新一轮问答
messages.append({"role":"assistant","content": answer})
messages.append({"role":"user","content": user_input})# 计算当前总token数
tokens_count +=len(encoding.encode((answer + user_input)))# 删除超出token阈值的对话内容while tokens_count >= tokens_thr:
tokens_count -=len(encoding.encode(messages.pop(1)["content"]))
函数列表查看
functions_list

9、多轮对话测试
chat_with_inter(functions_list=functions_list,
prompt="介绍一下iquery数据库中的表的情况",
model="gpt-3.5-turbo-16k",
system_message=[{"role":"system","content": md_content}],
auto_run =False)
对话效果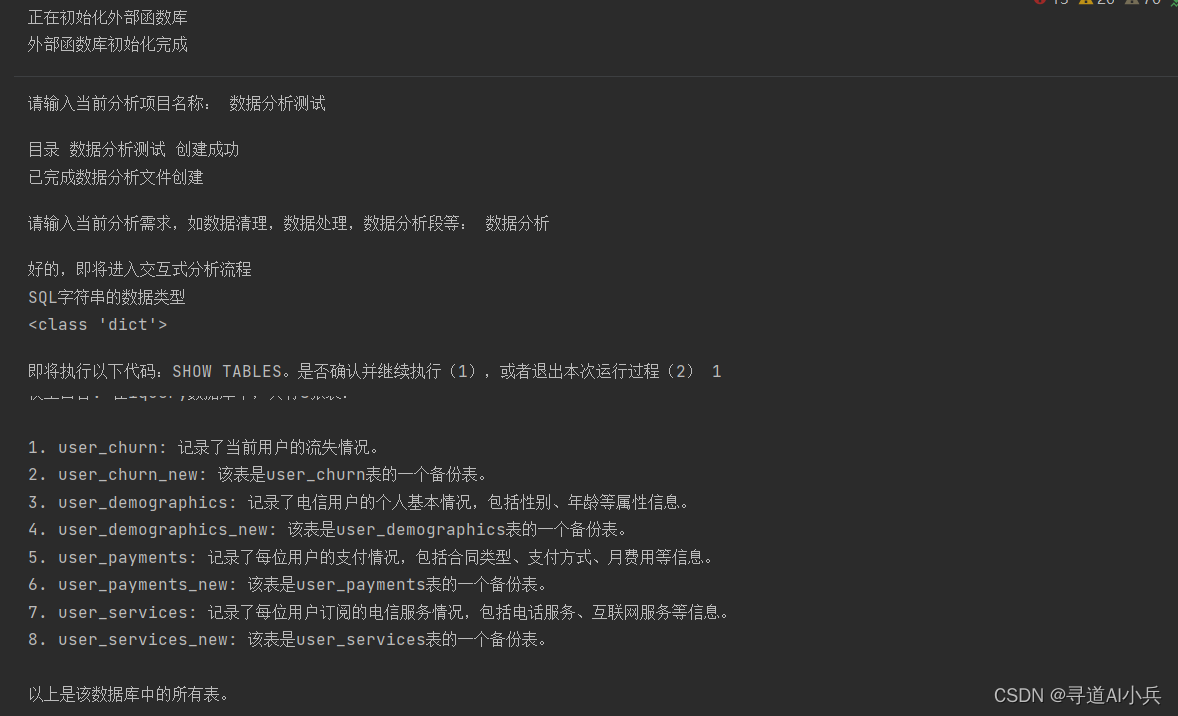
四、数据分析报告撰写初探
1、学习本公司的数据分析业务知识
# 读取业务知识文档withopen('/root/autodl-tmp/iquery项目/data/业务知识/本公司数据分析师业务介绍.md','r', encoding='utf-8')as f:
da_instruct = f.read()
from IPython.display import display, Markdown, Code
display(Markdown(da_instruct))
2、文件内容获取函数定义
实现一个根据项目和文件获取文件内容的方法
## 实现根据项目和文件获取文件内容的方法from docx import Document
import os
defget_file_content(project_name, file_name):"""
实现根据项目名和文件名获取文件内容的方法
@param project_name:项目名,file_name:文件名
@return 文件内容
"""# 构建文件的完整路径
base_path ="/root/autodl-tmp/iquery项目/iquery云盘"
file_path = os.path.join(project_name, file_name)
full_path = os.path.join(base_path, file_path)+".doc"print("打印文件路径:"+full_path)# 确保文件存在ifnot os.path.exists(full_path):return"文件不存在"try:# 加载文档
doc = Document(full_path)
content =[]# 遍历文档中的每个段落,并收集文本for para in doc.paragraphs:
content.append(para.text)# 将所有段落文本合并成一个字符串返回return'\n'.join(content)except Exception as e:returnf"读取文件时发生错误: {e}"
file_content = get_file_content('电信用户行为分析','数据分析问答')
输出:
display(Markdown(file_content))
3、读取数据字典信息
# 读取数据字典withopen('/root/autodl-tmp/iquery项目/data/数据字典/iquery数据字典.md','r', encoding='utf-8')as f:
md_content = f.read()
# 读取问答结果
file_content = get_file_content('电信用户行为分析','数据分析问答')
输出:
4、读取本公司数据分析师业务知识
# 读取业务知识文档withopen('/root/autodl-tmp/iquery项目/data/业务知识/本公司数据分析师业务介绍.md','r', encoding='utf-8')as f:
da_instruct = f.read()
5、撰写分析报告
基于读取到的字典信息,本公司数据分析师业务知识,以及问答内容;都给到大模型,让大模型编写报告
messages=[{"role":"system","content": da_instruct},{"role":"system","content":'iquery数据库数据字典:%s'% md_content},{"role":"system","content":'数据探索和理解阶段问答文本:%s'% file_content},{"role":"user","content":"请帮我编写电信用户行为分析的分析报告中的数据探索和理解部分内容"}]
response = client.chat.completions.create(
model="gpt-3.5-turbo-16k",
messages=messages,)
display(Markdown(response.choices[0].message.content))
五、结语
在本文中,我们不仅建立了一个能够记录多轮对话的本地“云盘”,而且还初步实现了基于对话内容、数据字典和业务知识的数据分析报告自动撰写功能。让我们的Agent智能数据分析平台拥有了,报告生成的能力;这也标志着我们向着完全自动化的数据分析平台又迈进了一大步。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
版权归原作者 寻道AI小兵 所有, 如有侵权,请联系我们删除。