
介绍
自然语言处理(NLP)是一种将非结构化文本处理成有意义的知识的人工智能技术。NLP解决了分类、主题建模、文本生成、问答、推荐等业务问题。虽然TF/IDF矢量化或其他高级词嵌入(如GLOVE和Word2Vec)在此类NLP业务问题上表现出了良好的性能,但这些模型存在局限性就是使用一个向量对词进行编码而不考虑上下文的不同含义。因此,当试图解决理解用户意图所需的问题时,这些模型可能不能很好地执行。一个例子是,当用户与自动聊天机器人交互时,它试图理解用户查询的意图并准确地提供响应。
对于这种情况,NLP中的另一个例子是从下面两个句子中解码上下文意义。
- A thieve robbed a bank.
- He went to river bank.
从以上两种表述中,人们很容易就能看出“bank”有两种不同的含义;然而,机器不能区分,因为上面提到的词嵌入使用相同的标记“bank”,而不管他们的上下文意义。为了克服这一挑战,谷歌从Transformers (BERT)模型开发了最先进的双向编码器表示。
BERT是什么?
BERT是在8亿单词的图书语料库和2500万单词的英语维基百科上训练的预训练模型。在BERT中,“bank”将有两个不同的含义,因为它们的上下文差异。在保持NLP任务的高性能的同时并不会降低模型构建的训练时间。并且可以从BERT中提取新的语言特征用于模型预测。与RNN、LSTM、CNN等深度学习模型相比,BERT的发展速度要快得多。作为高层次的理解,BERT有两种不同的架构变体:BERT base和BERT large。第一个变型有12个Transformers 块,12个注意头,1.1亿参数,后一个变型有24个Transformers ,16个注意头,3.4亿参数。它在使用过程中完成了两个NLP的任务:遮蔽语言建模和下一句预测。
数据集
查看如下的代码我建议具备python,NLP,深度学习和Pytorch框架的基础知识。必须使用Google帐户才能使用Google Colab帐户。
处理数据的方法
在传统的NLP机器学习问题中,我们倾向于清除不需要的文本,例如删除停用词,标点符号,删除符号和数字等。但是,在BERT中,不需要执行此类预处理任务,因为BERT使用了这些 单词的顺序和位置,以了解用户输入的意图。
ML / DL工程师应该从不同方面探索数据集,以真正了解他们手中的数据类型,这是一个好习惯。NLP的典型功能是单词计数,动词计数,形容词计数,数字计数,标点符号计数,双字母组计数,三字组计数等。为简便起见,我已展示了如何对单词计数列进行计数,其中单个标题中使用的总单词数将被计算在内。您可能还需要处理类似于TITLE的Abstract列,以及ABSTRACT和TITLE的组合。
下面的命令创建“ WORD_COUNT”列。
df_raw['WORD_COUNT'] = df_raw['TITLE'].apply(lambda x: len(x.split())
这将生成“ WORD_COUNT”的分布图,即标题的长度。
如您所见,文章标题的大部分以10个单词为中心,这是预期的结果,因为TITLE应该简短,简洁且有意义。
由于我将仅使用“ TITLE”和“ target_list”,因此我创建了一个名为df2的新数据框。df2.head()命令显示训练数据集中的前五个记录。如您所见,两个目标标签被标记到最后的记录,这就是为什么这种问题称为多标签分类问题的原因。
df2 = df_raw[['TITLE', 'target_list']].copy()
df2.head()

同时,设置将用于模型训练的参数。由于我更喜欢使用2*base数字,因此最大长度设置为16,这涵盖了大部分“ TITLE”长度。训练和有效批处理大小设置为32。epoch为4,因为它很容易在几个epoch上过度拟合。我从lr=0.00001开始学习。您可以随意尝试不同的值以提高准确性。
# Sections of config
# Defining some key variables that will be used later on in the training
MAX_LEN = 16
TRAIN_BATCH_SIZE = 32
VALID_BATCH_SIZE = 32
EPOCHS = 4
LEARNING_RATE = 1e-05
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
让我们创建一个称为“ CustomDataset”的通用类。Class从我们的原始输入特征生成张量,并且Pytorch张量可以接受class的输出。它期望具有上面定义的“ TITLE”,“ target_list”,max_len,并使用BERT toknizer.encode_plus函数将输入设置为数字矢量格式,然后转换为张量格式返回。
class CustomDataset(Dataset):
def __init__(self, dataframe, tokenizer, max_len):
self.tokenizer = tokenizer
self.data = dataframe
self.title = dataframe['TITLE']
self.targets = self.data.target_list
self.max_len = max_len
def __len__(self):
return len(self.title)
def __getitem__(self, index):
title = str(self.title[index])
title = " ".join(title.split())
inputs = self.tokenizer.encode_plus(
title,
None,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
return_token_type_ids=True,
truncation=True
)
ids = inputs['input_ids']
mask = inputs['attention_mask']
token_type_ids = inputs["token_type_ids"]
return {
'ids': torch.tensor(ids, dtype=torch.long),
'mask': torch.tensor(mask, dtype=torch.long),
'token_type_ids': torch.tensor(token_type_ids, dtype=torch.long),
'targets': torch.tensor(self.targets[index], dtype=torch.float)
}
数据集的80%用于模型训练,而20%用于验证。测试数据集完全用于测试目的。
train_size = 0.8
train_dataset = df2.sample(frac=train_size,random_state=200)
valid_dataset = df2.drop(train_dataset.index).reset_index(drop=True)
train_dataset = train_dataset.reset_index(drop=True)
print("FULL Dataset: {}".format(df2.shape))
print("TRAIN Dataset: {}".format(train_dataset.shape))
print("TEST Dataset: {}".format(valid_dataset.shape))
training_set = CustomDataset(train_dataset, tokenizer, MAX_LEN)
validation_set = CustomDataset(valid_dataset, tokenizer, MAX_LEN)

我们已经讨论了将张量准备为输入特征的大部分基础工作。现在,构建BERT模型很容易。由于来自模型的冗长输出,我已简化为仅显示模型。我已使用dropout 0.3来随机减少特征,以最大程度地减少第2层的过拟合。第3层采用了768维特征,这些特征是从使用BERT的第2层输出的。它返回6个特征,这是对目标列表的最终预测。
class BERTClass(torch.nn.Module):
def __init__(self):
super(BERTClass, self).__init__()
self.l1 = transformers.BertModel.from_pretrained('bert-base-uncased')
self.l2 = torch.nn.Dropout(0.3)
self.l3 = torch.nn.Linear(768, 6)
def forward(self, ids, mask, token_type_ids):
_, output_1= self.l1(ids, attention_mask = mask, token_type_ids = token_type_ids)
output_2 = self.l2(output_1)
output = self.l3(output_2)
return output
model = BERTClass()
model.to(device)
BCE损失函数用于找出模型预测值与实际目标值之间的误差。使用Adam优化器。损失功能请参见下文。
def loss_fn(outputs, targets):
return torch.nn.BCEWithLogitsLoss()(outputs, targets)
optimizer = torch.optim.Adam(params = model.parameters(), lr=LEARNING_RATE)
同时我还创建了检查点,可以在训练期间保存最佳模型。当需要从停下来的地方继续训练时,这将有助于减少训练时间。创建检查点可以节省时间,以便从头开始进行重新训练。如果您对从最佳模型生成的输出感到满意,则不需要进一步的微调,则可以使用模型进行推断。
def load_ckp(checkpoint_fpath, model, optimizer):
"""
checkpoint_path: path to save checkpoint
model: model that we want to load checkpoint parameters into
optimizer: optimizer we defined in previous training
"""
# load check point
checkpoint = torch.load(checkpoint_fpath)
# initialize state_dict from checkpoint to model
model.load_state_dict(checkpoint['state_dict'])
# initialize optimizer from checkpoint to optimizer
optimizer.load_state_dict(checkpoint['optimizer'])
# initialize valid_loss_min from checkpoint to valid_loss_min
valid_loss_min = checkpoint['valid_loss_min']
# return model, optimizer, epoch value, min validation loss
return model, optimizer, checkpoint['epoch'], valid_loss_min.item()
import shutil, sys
def save_ckp(state, is_best, checkpoint_path, best_model_path):
"""
state: checkpoint we want to save
is_best: is this the best checkpoint; min validation loss
checkpoint_path: path to save checkpoint
best_model_path: path to save best model
"""
f_path = checkpoint_path
# save checkpoint data to the path given, checkpoint_path
torch.save(state, f_path)
# if it is a best model, min validation loss
if is_best:
best_fpath = best_model_path
# copy that checkpoint file to best path given, best_model_path
shutil.copyfile(f_path, best_fpath)
def train_model(start_epochs, n_epochs, valid_loss_min_input,
training_loader, validation_loader, model,
optimizer, checkpoint_path, best_model_path):
# initialize tracker for minimum validation loss
valid_loss_min = valid_loss_min_input
for epoch in range(start_epochs, n_epochs+1):
train_loss = 0
valid_loss = 0
model.train()
print('############# Epoch {}: Training Start #############'.format(epoch))
for batch_idx, data in enumerate(training_loader):
#print('yyy epoch', batch_idx)
ids = data['ids'].to(device, dtype = torch.long)
mask = data['mask'].to(device, dtype = torch.long)
token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)
targets = data['targets'].to(device, dtype = torch.float)
outputs = model(ids, mask, token_type_ids)
optimizer.zero_grad()
loss = loss_fn(outputs, targets)
#if batch_idx%5000==0:
# print(f'Epoch: {epoch}, Training Loss: {loss.item()}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
#print('before loss data in training', loss.item(), train_loss)
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.item() - train_loss))
#print('after loss data in training', loss.item(), train_loss)
print('############# Epoch {}: Training End #############'.format(epoch))
print('############# Epoch {}: Validation Start #############'.format(epoch))
######################
# validate the model #
######################
model.eval()
with torch.no_grad():
for batch_idx, data in enumerate(validation_loader, 0):
ids = data['ids'].to(device, dtype = torch.long)
mask = data['mask'].to(device, dtype = torch.long)
token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)
targets = data['targets'].to(device, dtype = torch.float)
outputs = model(ids, mask, token_type_ids)
loss = loss_fn(outputs, targets)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.item() - valid_loss))
val_targets.extend(targets.cpu().detach().numpy().tolist())
val_outputs.extend(torch.sigmoid(outputs).cpu().detach().numpy().tolist())
print('############# Epoch {}: Validation End #############'.format(epoch))
# calculate average losses
#print('before cal avg train loss', train_loss)
train_loss = train_loss/len(training_loader)
valid_loss = valid_loss/len(validation_loader)
# print training/validation statistics
print('Epoch: {} \tAvgerage Training Loss: {:.6f} \tAverage Validation Loss: {:.6f}'.format(
epoch,
train_loss,
valid_loss
))
# create checkpoint variable and add important data
checkpoint = {
'epoch': epoch + 1,
'valid_loss_min': valid_loss,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()
}
# save checkpoint
save_ckp(checkpoint, False, checkpoint_path, best_model_path)
## TODO: save the model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))
# save checkpoint as best model
save_ckp(checkpoint, True, checkpoint_path, best_model_path)
valid_loss_min = valid_loss
print('############# Epoch {} Done #############\n'.format(epoch))
return model
“train_model”被创建来训练模型,“checkpoint_path”是训练模型的参数将被保存为每个epoch,“best_model”是最好的模型将被保存的地方。
checkpoint_path = '/content/drive/My Drive/NLP/ResearchArticlesClassification/checkpoint/current_checkpoint.pt'
best_model = '/content/drive/My Drive/NLP/ResearchArticlesClassification/best_model/best_model.pt'
trained_model = train_model(1, 4, np.Inf, training_loader, validation_loader, model,
optimizer,checkpoint_path,best_model)
训练结果如下:
############# Epoch 1: Training Start #############
############# Epoch 1: Training End #############
############# Epoch 1: Validation Start #############
############# Epoch 1: Validation End #############
Epoch: 1 Avgerage Training Loss: 0.000347 Average Validation Loss: 0.001765
Validation loss decreased (inf --> 0.001765). Saving model ...
############# Epoch 1 Done #############
############# Epoch 2: Training Start #############
############# Epoch 2: Training End #############
############# Epoch 2: Validation Start #############
############# Epoch 2: Validation End #############
Epoch: 2 Avgerage Training Loss: 0.000301 Average Validation Loss: 0.001831
############# Epoch 2 Done #############
############# Epoch 3: Training Start #############
############# Epoch 3: Training End #############
############# Epoch 3: Validation Start #############
############# Epoch 3: Validation End #############
Epoch: 3 Avgerage Training Loss: 0.000263 Average Validation Loss: 0.001896
############# Epoch 3 Done #############
############# Epoch 4: Training Start #############
############# Epoch 4: Training End #############
############# Epoch 4: Validation Start #############
############# Epoch 4: Validation End #############
Epoch: 4 Avgerage Training Loss: 0.000228 Average Validation Loss: 0.002048
############# Epoch 4 Done #############
因为我只执行了4个epoch,所以完成得很快,我将threshold设置为0.5。你可以试试这个阈值,看看是否能提高结果。
val_preds = (np.array(val_outputs) > 0.5).astype(int)
val_preds
array([[0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
...,
[0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0]])
让我们将精确度和F1得分定义为模型性能的指标。F1将被用于评估。
accuracy = metrics.accuracy_score(val_targets, val_preds)
f1_score_micro = metrics.f1_score(val_targets, val_preds, average='micro')
f1_score_macro = metrics.f1_score(val_targets, val_preds, average='macro')
print(f"Accuracy Score = {accuracy}")
print(f"F1 Score (Micro) = {f1_score_micro}")
print(f"F1 Score (Macro) = {f1_score_macro}")
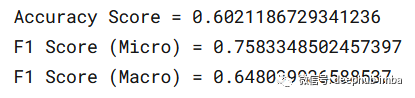
使用混淆矩阵和分类报告,以可视化我们的模型如何正确/不正确地预测每个单独的目标。
from sklearn.metrics import multilabel_confusion_matrix as mcm, classification_report
cm_labels = ['Computer Science', 'Physics', 'Mathematics',
'Statistics', 'Quantitative Biology', 'Quantitative Finance']
cm = mcm(val_targets, val_preds)
print(classification_report(val_targets, val_preds))
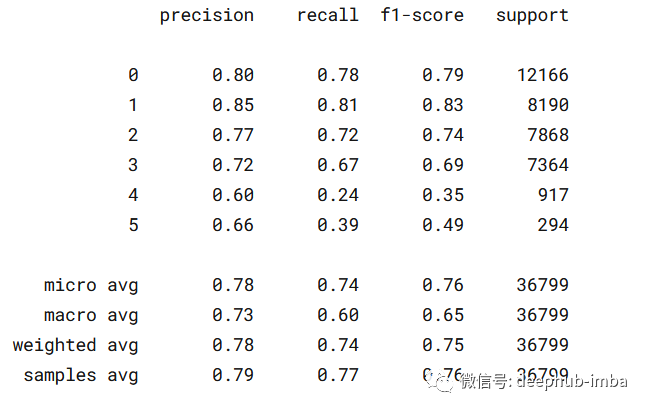
模型预测的准确率为76%。F1得分低的原因是有六个类的预测,通过结合“TITLE”和“ABSTRACT”或者只使用“ABSTRACT”来训练可以提高它。我对这两个案例都进行了训练,发现“ABSTRACT”特征本身的F1分数比标题和标题与抽象相结合要好得多。在没有进行超参数优化的情况下,我使用测试数据进行推理,并在private score中获得0.82分。
有一些事情可以做,以提高F1成绩。一个是微调模型的超参数,你可能想要实验改变学习速率,退出率和时代的数量。在对模型微调的结果满意之后,我们可以使用整个训练数据集,而不是分成训练和验证集,因为训练模型已经看到了所有可能的场景,使模型更好地执行。
你可以在谷歌Colab查看这个项目源代码
https://colab.research.google.com/drive/1SPxxEW9okgnbMdk1ORlfSQI4rjV2tVW_#scrollTo=EJQRHd7VVMap
作者:Kyawkhaung
原文地址:https://kyawkhaung.medium.com/multi-label-text-classification-with-bert-using-pytorch-47011a7313b9
deephub翻译组