
Qualcomm® AI Engine Direct 使用手册(15)
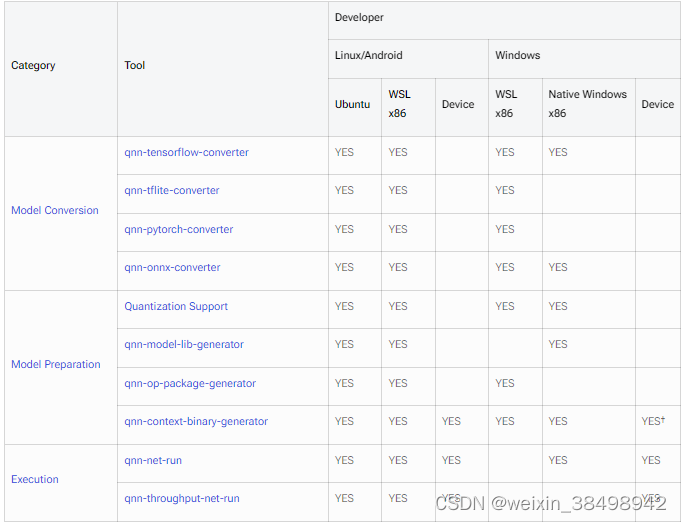
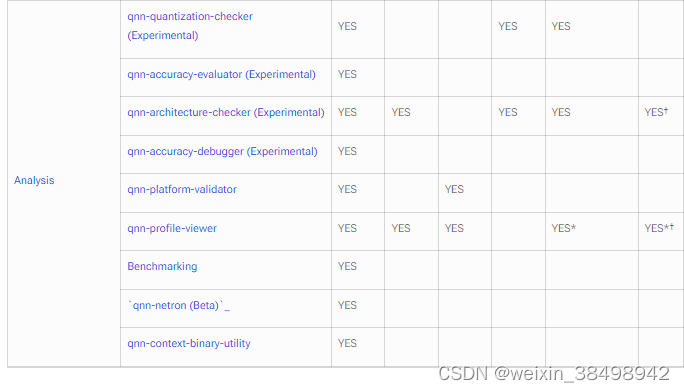
6 工具
本页介绍了适用于 Linux/Android 和 Windows 开发人员的各种 SDK 工具和功能。对于不同开发者的集成流程,请参阅概述页面了解更多信息。
笔记
在本机 Windows 中使用转换器工具时,用户需要通过Python执行(参见下面的示例)
$ python qnn-onnx-converter <选项>
笔记
- 库的扩展名命名:对于 Windows 开发人员,请将以下部分中的所有“.so”文件替换为类似的“.dll”文件。请参阅平台差异了解更多详细信息。
- 有关转换器的更多详细信息,请参阅转换器。
- [*] Windows 平台上的 qnn-profile-viewer 不支持 libQnnGpuProfilingReader.dll。
- [†] 不支持 ARM64EC/X 二进制格式。
6.1 型号转换
qnn-张量流转换器
qnn -tensorflow-converter工具将模型从 TensorFlow 框架转换为 CPP 文件,将模型表示为一系列 QNN API 调用。此外,还会生成包含模型静态权重的二进制文件。
usage: qnn-tensorflow-converter -d INPUT_NAME INPUT_DIM --out_node OUT_NAMES
[--input_type INPUT_NAME INPUT_TYPE][--input_dtype INPUT_NAME INPUT_DTYPE][--input_encoding INPUT_ENCODING [INPUT_ENCODING ...]][--input_layout INPUT_NAME INPUT_LAYOUT][--custom_io CUSTOM_IO][--show_unconsumed_nodes][--saved_model_tag SAVED_MODEL_TAG][--saved_model_signature_key SAVED_MODEL_SIGNATURE_KEY][--quantization_overrides QUANTIZATION_OVERRIDES][--keep_quant_nodes][--disable_batchnorm_folding][--keep_disconnected_nodes][--input_list INPUT_LIST][--param_quantizer PARAM_QUANTIZER][--act_quantizer ACT_QUANTIZER][--algorithms ALGORITHMS [ALGORITHMS ...]][--bias_bw BIAS_BW][--act_bw ACT_BW][--weight_bw WEIGHT_BW][--ignore_encodings][--use_per_row_quantization][--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]][--use_native_input_files][--use_native_dtype][--use_native_output_files]--input_network INPUT_NETWORK
[--debug [DEBUG]][-o OUTPUT_PATH][--copyright_file COPYRIGHT_FILE][--float_bw FLOAT_BW][--float_bias_bw FLOAT_BIAS_BW][--overwrite_model_prefix][--exclude_named_tensors][--op_package_lib OP_PACKAGE_LIB][--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX][--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB][-p PACKAGE_NAME |--op_package_config CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...]][-h][--arch_checker]
Script to convert TF model into QNN
required arguments:-d INPUT_NAME INPUT_DIM,--input_dim INPUT_NAME INPUT_DIM
The names and dimensions of the network input layers specified in the format
[input_name comma-separated-dimensions],for example:'data'1,224,224,3
Note that the quotes should always be included in order to
handlespecial characters, spaces, etc.
For multiple inputs specify multiple --input_dim on the command line like:--input_dim 'data1'1,224,224,3--input_dim 'data2'1,50,100,3--out_node OUT_NODE,--out_name OUT_NAMES
Name of the graph's output nodes. Multiple output nodes should be
provided separately like:--out_node out_1 --out_node out_2
--input_network INPUT_NETWORK,-i INPUT_NETWORK
Path to the source framework model.
optional arguments:--input_type INPUT_NAME INPUT_TYPE,-t INPUT_NAME INPUT_TYPE
Type of data expected by each input op/layer. Type for each input is
|default|ifnot specified. For example:"data" image.Note that the quotes
should always be included in order to handle special characters, spaces,etc.
For multiple inputs specify multiple --input_type on the command line.
Eg:--input_type "data1" image --input_type "data2" opaque
These options get used by DSP runtime and following descriptions state how
input will be handled for each option.
Image:
Input is float between 0-255and the input's mean is 0.0f and the input's
max is 255.0f. We will cast the float to uint8ts and pass the uint8ts to the
DSP.
Default:
Pass the input as floats to the dsp directly and the DSP will quantize it.
Opaque:
Assumes input is float because the consumer layer(i.e next layer)requires
it as float, therefore it won't be quantized.
Choices supported:
image
default
opaque
--input_dtype INPUT_NAME INPUT_DTYPE
The names and datatype of the network input layers specified in the format
[input_name datatype],for example:'data''float32'.
Default is float32 ifnot specified.
Note that the quotes should always be included in order to handle special
characters, spaces, etc.
For multiple inputs specify multiple --input_dtype on the command line like:--input_dtype 'data1''float32'--input_dtype 'data2''float32'--input_encoding INPUT_ENCODING [INPUT_ENCODING ...],-e INPUT_ENCODING [INPUT_ENCODING ...]
Usage:--input_encoding "INPUT_NAME" INPUT_ENCODING_IN
[INPUT_ENCODING_OUT]
Input encoding of the network inputs. Default is bgr.
e.g.--input_encoding "data" rgba
Quotes must wrap the input node name to handle special characters,
spaces, etc. To specify encodings for multiple inputs, invoke
--input_encoding for each one.
e.g.--input_encoding "data1" rgba --input_encoding "data2" other
Optionally, an output encoding may be specified for an input node by
providing a second encoding. The default output encoding is bgr.
e.g.--input_encoding "data3" rgba rgb
Input encoding types:
image color encodings: bgr,rgb, nv21, nv12,...
time_series:for inputs of rnn models;
other:not available above or is unknown.
Supported encodings:
bgr
rgb
rgba
argb32
nv21
nv12
time_series
other
--input_layout INPUT_NAME INPUT_LAYOUT,-l INPUT_NAME INPUT_LAYOUT
Layout of each input tensor. If not specified, it will use the default
based on the Source Framework, shape of input and input encoding.
Accepted values are-
NCDHW, NDHWC, NCHW, NHWC, NFC, NCF, NTF, TNF, NF, NC, F, NONTRIVIAL
N = Batch, C = Channels, D = Depth, H = Height, W = Width, F = Feature, T = Time
NDHWC/NCDHW used for5d inputs
NHWC/NCHW used for4d image-like inputs
NFC/NCF used for inputs to Conv1D or other 1D ops
NTF/TNF used for inputs with time steps like the ones used for LSTM op
NF used for2D inputs, like the inputs to Dense/FullyConnected layers
NC used for2D inputs with 1for batch and other forChannels(rarely used)
F used for1D inputs, e.g. Bias tensor
NONTRIVIAL for everything elseFor multiple inputs specify multiple
--input_layout on the command line.
Eg:--input_layout "data1" NCHW --input_layout "data2" NCHW
--custom_io CUSTOM_IO
Use this option to specify a yaml file for custom IO
--show_unconsumed_nodes
Displays a list of unconsumed nodes,if there any are found. Nodes which are
unconsumed donot violate the structural fidelity of thegenerated graph.--saved_model_tag SAVED_MODEL_TAG
Specify the tag to seletet a MetaGraph from savedmodel. ex:--saved_model_tag serve. Default value will be 'serve' when it is not
assigned.--saved_model_signature_key SAVED_MODEL_SIGNATURE_KEY
Specify signature key to select input and output of the model. ex:--saved_model_signature_key serving_default. Default value will be
'serving_default' when it is not assigned
--disable_batchnorm_folding
--keep_disconnected_nodes
Disable Optimization that removes Ops not connected to the main graph.
This optimization uses output names provided over commandline OR
inputs/outputs extracted from the Source model to determine the main graph
--debug [DEBUG] Run the converter in debug mode.-o OUTPUT_PATH,--output_path OUTPUT_PATH
Path where the converted Output model should be saved.If not specified, the
converter model will be written to a file with same name as the input model
--copyright_file COPYRIGHT_FILE
Path to copyright file. If provided, the content of the file will be added
to the output model.--float_bw FLOAT_BW Use the --float_bw option to select the bitwidth to use when usingfloatforparameters(weights/bias)and activations for all ops or specific Op(via
encodings) selected through encoding, either 32(default)or16.--overwrite_model_prefix
If option passed, model generator will use the output path name to use as
model prefix to name functions in <qnn_model_name>.cpp.(Useful for running
multiple models at once) eg: ModelName_composeGraphs. Default is to use
generic "QnnModel_".--exclude_named_tensors
Remove using source framework tensorNames; instead use a counter for naming
tensors. Note: This can potentially help to reduce the final model library
that will be generated(Recommended for deploying model). Default is False.-h,--help show this help message and exit
Quantizer Options:--quantization_overrides QUANTIZATION_OVERRIDES
Use this option to specify a json file with parameters to use for
quantization. These will override any quantization data carried from
conversion(eg TF fake quantization)or calculated during the normal
quantization process. Format defined as per AIMET specification.--keep_quant_nodes Use this option to keep activation quantization nodes in the graph rather
than stripping them.--input_list INPUT_LIST
Path to a file specifying the input data. This file should be a plain text
file, containing one or more absolute file paths per line. Each path is
expected to point to a binary file containing one input in the "raw" format,
ready to be consumed by the quantizer without any further preprocessing.
Multiple files per line separated by spaces indicate multiple inputs to the
network. See documentation for more details. Must be specified for
quantization. All subsequent quantization options are ignored when this is
not provided.--param_quantizer PARAM_QUANTIZER
Optional parameter to indicate the weight/bias quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--act_quantizer ACT_QUANTIZER
Optional parameter to indicate the activation quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--algorithms ALGORITHMS [ALGORITHMS ...]
Use this option to enable new optimization algorithms. Usage is:--algorithms <algo_name1>... The available optimization algorithms are:"cle"- Cross layer equalization includes a number of methods for equalizing
weights and biases across layers in order to rectify imbalances that cause
quantization errors.--bias_bw BIAS_BW Use the --bias_bw option to select the bitwidth to use when quantizing the
biases, either 8(default)or32.--act_bw ACT_BW Use the --act_bw option to select the bitwidth to use when quantizing the
activations, either 8(default)or16.--weight_bw WEIGHT_BW
Use the --weight_bw option to select the bitwidth to use when quantizing the
weights, currently only 8bit(default) supported.--float_bias_bw FLOAT_BIAS_BW
Use the --float_bias_bw option to select the bitwidth to use when biases are
in float, either 32or16.--ignore_encodings Use only quantizer generated encodings, ignoring any user or model provided
encodings.
Note: Cannot use --ignore_encodings with --quantization_overrides
--use_per_row_quantization
Use this option to enable rowwise quantization of Matmul and FullyConnected
ops.--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]
Use per-channel quantization for convolution-based op weights.
Note: This will replace built-in model QAT encodings when used for a given
weight.Usage "--use_per_channel_quantization" to enable or "--
use_per_channel_quantization false" (default) to disable
--use_native_input_files
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_dtype Note: This option is deprecated, use --use_native_input_files option in
future.
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_output_files
Use this option to indicate the data type of the output files
1.float(default): output the file as floats.2. native: outputs the file that is native to the model. For ex.,uint8_t.--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX
Specifies the number of steps to use for computing quantization encodings
such that scale =(max - min)/ number of quantization steps.
The option should be passed as a space separated pair of hexadecimal string
minimum and maximum values. i.e.--restrict_quantization_steps "MIN MAX".
Please note that this is a hexadecimal string literal andnot a signed
integer, to supply a negative value an explicit minus sign is required.
E.g.--restrict_quantization_steps "-0x80 0x7F" indicates an example 8 bit range,--restrict_quantization_steps "-0x8000 0x7F7F" indicates an example 16
bit range. This argument is required for16-bit Matmul operations.
Custom Op Package Options:--op_package_lib OP_PACKAGE_LIB,-opl OP_PACKAGE_LIB
Use this argument to pass an op package library for quantization. Must be in
the form
<op_package_lib_path:interfaceProviderName>and be separated by a
comma for multiple package libs
-p PACKAGE_NAME,--package_name PACKAGE_NAME
A global package name to be used for each node in the Model.cpp file.
Defaults to Qnn header defined package name
--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB,-cpl CONVERTER_OP_PACKAGE_LIB
Absolute path to converter op package library compiled by the OpPackage
generator. Must be separated by a comma for multiple package libraries.
Note: Libraries must follow the same order as the xml files.
E.g.1:--converter_op_package_lib absolute_path_to/libExample.so
E.g.2:-cpl absolute_path_to/libExample1.so,absolute_path_to/libExample2.so
--op_package_config OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...],-opc OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...]
Path to a Qnn Op Package XML configuration file that contains user defined
custom operations.
Architecture Checker Options(Experimental):--arch_checker Note: This option will be soon deprecated. Use the qnn-architecture-checker tool to achieve the same result.
Note: Only one of:{'package_name','op_package_config'} can be specified
基本命令行用法如下:
$ qnn-tensorflow-converter -i <path>/frozen_graph.pb
-d <network_input_name><dims>--out_node <network_output_name>-o <optional_output_path>--allow_unconsumed_nodes # optional, but most likely will be need for larger models
-p <optional_package_name> # Defaults to "qti.aisw"
qnn-tflite-转换器
qnn-tflite-converter工具将 TFLite 模型转换为 CPP 文件,将模型表示为一系列 QNN API 调用。此外,还会生成包含模型静态权重的二进制文件。
usage: qnn-tflite-converter -d INPUT_NAME INPUT_DIM [--out_node OUT_NAMES][--input_type INPUT_NAME INPUT_TYPE][--input_dtype INPUT_NAME INPUT_DTYPE][--input_encoding INPUT_ENCODING [INPUT_ENCODING ...]][--input_layout INPUT_NAME INPUT_LAYOUT][--custom_io CUSTOM_IO][--dump_relay DUMP_RELAY][--quantization_overrides QUANTIZATION_OVERRIDES][--keep_quant_nodes][--disable_batchnorm_folding][--keep_disconnected_nodes][--input_list INPUT_LIST][--param_quantizer PARAM_QUANTIZER][--act_quantizer ACT_QUANTIZER][--algorithms ALGORITHMS [ALGORITHMS ...]][--bias_bw BIAS_BW][--act_bw ACT_BW][--weight_bw WEIGHT_BW][--ignore_encodings][--use_per_row_quantization][--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]][--use_native_input_files][--use_native_dtype][--use_native_output_files]--input_network INPUT_NETWORK
[--debug [DEBUG]][-o OUTPUT_PATH][--copyright_file COPYRIGHT_FILE][--float_bw FLOAT_BW][--float_bias_bw FLOAT_BIAS_BW][--overwrite_model_prefix][--exclude_named_tensors][--op_package_lib OP_PACKAGE_LIB][--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX][--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB][-p PACKAGE_NAME |--op_package_config CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...]][-h][--arch_checker]
Script to convert TFLite model into QNN
required arguments:-d INPUT_NAME INPUT_DIM,--input_dim INPUT_NAME INPUT_DIM
The names and dimensions of the network input layers specified in the format
[input_name comma-separated-dimensions],for example:'data'1,224,224,3 Note that the quotes should always be included in order to handle special
characters, spaces, etc. For multiple inputs specify multiple --input_dim on the command
line like:--input_dim 'data1'1,224,224,3--input_dim 'data2'1,50,100,3--input_network INPUT_NETWORK,-i INPUT_NETWORK
Path to the source framework model.
optional arguments:--out_node OUT_NAMES,--out_name OUT_NAMES
Name of the graph's output Tensor Names. Multiple output names should be
provided separately like:--out_name out_1 --out_name out_2
--input_type INPUT_NAME INPUT_TYPE,-t INPUT_NAME INPUT_TYPE
Type of data expected by each input op/layer. Type for each input is
|default|ifnot specified. For example:"data" image.Note that the quotes
should always be included in order to handle special characters, spaces,etc.
For multiple inputs specify multiple --input_type on the command line.
Eg:--input_type "data1" image --input_type "data2" opaque
These options get used by DSP runtime and following descriptions state how
input will be handled for each option.
Image:
Input is float between 0-255and the input's mean is 0.0f and the input's
max is 255.0f. We will cast the float to uint8ts and pass the uint8ts to the
DSP.
Default:
Pass the input as floats to the dsp directly and the DSP will quantize it.
Opaque:
Assumes input is float because the consumer layer(i.e next layer)requires
it as float, therefore it won't be quantized.
Choices supported:
image
default
opaque
--input_dtype INPUT_NAME INPUT_DTYPE
The names and datatype of the network input layers specified in the format
[input_name datatype],for example:'data''float32'
Default is float32 ifnot specified
Note that the quotes should always be included in order to handlespecial
characters, spaces, etc.
For multiple inputs specify multiple --input_dtype on the command line like:--input_dtype 'data1''float32'--input_dtype 'data2''float32'--input_encoding INPUT_ENCODING [INPUT_ENCODING ...],-e INPUT_ENCODING [INPUT_ENCODING ...]
Usage:--input_encoding "INPUT_NAME" INPUT_ENCODING_IN
[INPUT_ENCODING_OUT]
Input encoding of the network inputs. Default is bgr.
e.g.--input_encoding "data" rgba
Quotes must wrap the input node name to handle special characters,
spaces, etc. To specify encodings for multiple inputs, invoke
--input_encoding for each one.
e.g.--input_encoding "data1" rgba --input_encoding "data2" other
Optionally, an output encoding may be specified for an input node by
providing a second encoding. The default output encoding is bgr.
e.g.--input_encoding "data3" rgba rgb
Input encoding types:
image color encodings: bgr,rgb, nv21, nv12,...
time_series:for inputs of rnn models;
other:not available above or is unknown.
Supported encodings:
bgr
rgb
rgba
argb32
nv21
nv12
time_series
other
--input_layout INPUT_NAME INPUT_LAYOUT,-l INPUT_NAME INPUT_LAYOUT
Layout of each input tensor. If not specified, it will use the default
based on the Source Framework, shape of input and input encoding.
Accepted values are-
NCDHW, NDHWC, NCHW, NHWC, NFC, NCF, NTF, TNF, NF, NC, F, NONTRIVIAL
N = Batch, C = Channels, D = Depth, H = Height, W = Width, F = Feature, T = Time
NDHWC/NCDHW used for5d inputs
NHWC/NCHW used for4d image-like inputs
NFC/NCF used for inputs to Conv1D or other 1D ops
NTF/TNF used for inputs with time steps like the ones used for LSTM op
NF used for2D inputs, like the inputs to Dense/FullyConnected layers
NC used for2D inputs with 1for batch and other forChannels(rarely used)
F used for1D inputs, e.g. Bias tensor
NONTRIVIAL for everything elseFor multiple inputs specify multiple
--input_layout on the command line.
Eg:--input_layout "data1" NCHW --input_layout "data2" NCHW
--custom_io CUSTOM_IO
Use this option to specify a yaml file for custom IO.--dump_relay DUMP_RELAY
Dump Relay ASM and Params at the path provided with the argument
Usage:--dump_relay <path_to_dump>--show_unconsumed_nodes
Displays a list of unconsumed nodes,if there any are
found. Nodeswhich are unconsumed donot violate the
structural fidelity of thegenerated graph.--disable_batchnorm_folding
--keep_disconnected_nodes
Disable Optimization that removes Ops not connected to the main graph.
This optimization uses output names provided over commandline OR
inputs/outputs extracted from the Source model to determine the main graph
-o OUTPUT_PATH,--output_path OUTPUT_PATH
Path where the converted Output model should be saved.If not specified, the
converter model will be written to a file with same name as the input model
--copyright_file COPYRIGHT_FILE
Path to copyright file. If provided, the content of the file will be added
to the output model.--float_bw FLOAT_BW Use the --float_bw option to select the bitwidth to use when usingfloatforparameters(weights/bias)and activations for all ops or specific Op(via
encodings) selected through encoding, either 32(default)or16.--overwrite_model_prefix
If option passed, model generator will use the output path name to use as
model prefix to name functions in <qnn_model_name>.cpp.(Useful for running
multiple models at once) eg: ModelName_composeGraphs. Default is to use
generic "QnnModel_".--exclude_named_tensors
Remove using source framework tensorNames; instead use a counter for naming
tensors. Note: This can potentially help to reduce the final model library
that will be generated(Recommended for deploying model). Default is False.-h,--help show this help message and exit
Quantizer Options:--quantization_overrides QUANTIZATION_OVERRIDES
Use this option to specify a json file with parameters to use for
quantization. These will override any quantization data carried from
conversion(eg TF fake quantization)or calculated during the normal
quantization process. Format defined as per AIMET specification.--keep_quant_nodes Use this option to keep activation quantization nodes in the graph rather
than stripping them.--input_list INPUT_LIST
Path to a file specifying the input data. This file should be a plain text
file, containing one or more absolute file paths per line. Each path is
expected to point to a binary file containing one input in the "raw" format,
ready to be consumed by the quantizer without any further preprocessing.
Multiple files per line separated by spaces indicate multiple inputs to the
network. See documentation for more details. Must be specified for
quantization. All subsequent quantization options are ignored when this is
not provided.--param_quantizer PARAM_QUANTIZER
Optional parameter to indicate the weight/bias quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--act_quantizer ACT_QUANTIZER
Optional parameter to indicate the activation quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--algorithms ALGORITHMS [ALGORITHMS ...]
Use this option to enable new optimization algorithms. Usage is:--algorithms <algo_name1>... The available optimization algorithms are:"cle"- Cross layer equalization includes a number of methods for equalizing
weights and biases across layers in order to rectify imbalances that cause
quantization errors.--bias_bw BIAS_BW Use the --bias_bw option to select the bitwidth to use when quantizing the
biases, either 8(default)or32.--act_bw ACT_BW Use the --act_bw option to select the bitwidth to use when quantizing the
activations, either 8(default)or16.--weight_bw WEIGHT_BW
Use the --weight_bw option to select the bitwidth to use when quantizing the
weights, currently only 8bit(default) supported.--float_bias_bw FLOAT_BIAS_BW
Use the --float_bias_bw option to select the bitwidth to use when biases are
in float, either 32or16.--ignore_encodings Use only quantizer generated encodings, ignoring any user or model provided
encodings.
Note: Cannot use --ignore_encodings with --quantization_overrides
--use_per_row_quantization
Use this option to enable rowwise quantization of Matmul and FullyConnected
ops.--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]
Use per-channel quantization for convolution-based op weights.
Note: This will replace built-in model QAT encodings when used for a given
weight.Usage "--use_per_channel_quantization" to enable or "--
use_per_channel_quantization false" (default) to disable
--use_native_input_files
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_dtype Note: This option is deprecated, use --use_native_input_files option in
future.
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_output_files
Use this option to indicate the data type of the output files
1.float(default): output the file as floats.2. native: outputs the file that is native to the model. For ex.,uint8_t.--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX
Specifies the number of steps to use for computing quantization encodings
such that scale =(max - min)/ number of quantization steps.
The option should be passed as a space separated pair of hexadecimal string
minimum and maximum values. i.e.--restrict_quantization_steps "MIN MAX".
Please note that this is a hexadecimal string literal andnot a signed
integer, to supply a negative value an explicit minus sign is required.
E.g.--restrict_quantization_steps "-0x80 0x7F" indicates an example 8 bit range,--restrict_quantization_steps "-0x8000 0x7F7F" indicates an example 16
bit range.
Custom Op Package Options:--op_package_lib OP_PACKAGE_LIB,-opl OP_PACKAGE_LIB
Use this argument to pass an op package library for quantization. Must be in
the form <op_package_lib_path:interfaceProviderName>and be separated by a
comma for multiple package libs
--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB,-cpl CONVERTER_OP_PACKAGE_LIB
Absolute path to converter op package library compiled by the OpPackage
generator. Must be separated by a comma for multiple package libraries.
Note: Libraries must follow the same order as the xml files.
E.g.1:--converter_op_package_lib absolute_path_to/libExample.so
E.g.2:-cpl absolute_path_to/libExample1.so,absolute_path_to/libExample2.so
-p PACKAGE_NAME,--package_name PACKAGE_NAME
A global package name to be used for each node in the Model.cpp file.
Defaults to Qnn header defined package name
--op_package_config OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...],-opc OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...]
Path to a Qnn Op Package XML configuration file that contains user defined
custom operations.
Architecture Checker Options(Experimental):--arch_checker Note: This option will be soon deprecated. Use the qnn-architecture-checker tool to achieve the same result.
Note: Only one of:{'package_name','op_package_config'} can be specified
基本命令行用法如下:
$ qnn-tflite-converter -i <path>/model.tflite
-d <network_input_name><dims>-o <optional_output_path>-p <optional_package_name> # Defaults to "qti.aisw"
qnn-pytorch-转换器
qnn-pytorch-converter工具将 PyTorch 模型转换为 CPP 文件,将模型表示为一系列 QNN API 调用。此外,还会生成包含模型静态权重的二进制文件。
usage: qnn-pytorch-converter -d INPUT_NAME INPUT_DIM [--out_node OUT_NAMES][--input_type INPUT_NAME INPUT_TYPE][--input_dtype INPUT_NAME INPUT_DTYPE][--input_encoding INPUT_ENCODING [INPUT_ENCODING ...]][--input_layout INPUT_NAME INPUT_LAYOUT][--custom_io CUSTOM_IO][--dump_relay DUMP_RELAY][--quantization_overrides QUANTIZATION_OVERRIDES][--keep_quant_nodes][--disable_batchnorm_folding][--keep_disconnected_nodes][--input_list INPUT_LIST][--param_quantizer PARAM_QUANTIZER][--act_quantizer ACT_QUANTIZER][--algorithms ALGORITHMS [ALGORITHMS ...]][--bias_bw BIAS_BW][--act_bw ACT_BW][--weight_bw WEIGHT_BW][--ignore_encodings][--use_per_row_quantization][--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]][--use_native_input_files][--use_native_dtype][--use_native_output_files]--input_network INPUT_NETWORK
[--debug [DEBUG]][-o OUTPUT_PATH][--copyright_file COPYRIGHT_FILE][--float_bw FLOAT_BW][--float_bias_bw FLOAT_BIAS_BW][--overwrite_model_prefix][--exclude_named_tensors][--op_package_lib OP_PACKAGE_LIB][--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX][--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB][-p PACKAGE_NAME |--op_package_config CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...]][-h][--arch_checker]
Script to convert PyTorch model into QNN
required arguments:-d INPUT_NAME INPUT_DIM,--input_dim INPUT_NAME INPUT_DIM
The names and dimensions of the network input layers specified in the format
[input_name comma-separated-
dimensions],for example:'data'1,3,224,224
Note that the quotes should always be included in order to handle special
characters, spaces, etc.
For multiple inputs specify multiple --input_dim on the command line like:--input_dim 'data1'1,3,224,224--input_dim 'data2'1,50,100,3--input_network INPUT_NETWORK,-i INPUT_NETWORK
Path to the source framework model.
optional arguments:--out_node OUT_NAMES,--out_name OUT_NAMES
Name of the graph's output Tensor Names. Multiple output names should be
provided separately like:--out_name out_1 --out_name out_2
--input_type INPUT_NAME INPUT_TYPE,-t INPUT_NAME INPUT_TYPE
Type of data expected by each input op/layer. Type for each input is
|default|ifnot specified. For example:"data" image.Note that the quotes
should always be included in order to handle special characters, spaces, etc.
For multiple inputs specify multiple --input_type on the command line.
Eg:--input_type "data1" image --input_type "data2" opaque
These options get used by DSP runtime and following descriptions state how
input will be handled for each option.
Image:
Input is float between 0-255and the input's mean is 0.0f and the input's
max is 255.0f. We will cast the float to uint8ts and pass the uint8ts to the
DSP.
Default:
Pass the input as floats to the dsp directly and the DSP will quantize it.
Opaque:
Assumes
input is float because the consumer layer(i.e next layer)requires
it as float, therefore it won't be quantized.
Choices supported:
image
default
opaque
--input_dtype INPUT_NAME INPUT_DTYPE
The names and datatype of the network input layers specified in the format
[input_name datatype],for example:'data''float32'
Default is float32 ifnot specified
Note that the quotes should always be included in order to handlespecial
characters, spaces, etc.
For multiple inputs specify multiple --input_dtype on the command line like:--input_dtype 'data1''float32'--input_dtype 'data2''float32'--input_encoding INPUT_ENCODING [INPUT_ENCODING ...],-e INPUT_ENCODING [INPUT_ENCODING ...]
Usage:--input_encoding "INPUT_NAME" INPUT_ENCODING_IN
[INPUT_ENCODING_OUT]
Input encoding of the network inputs. Default is bgr.
e.g.--input_encoding "data" rgba
Quotes must wrap the input node name to handle special characters,
spaces, etc. To specify encodings for multiple inputs, invoke
--input_encoding for each one.
e.g.--input_encoding "data1" rgba --input_encoding "data2" other
Optionally, an output encoding may be specified for an input node by
providing a second encoding. The default output encoding is bgr.
e.g.--input_encoding "data3" rgba rgb
Input encoding types:
image color encodings: bgr,rgb, nv21, nv12,...
time_series:for inputs of rnn models;
other:not available above or is unknown.
Supported encodings:
bgr
rgb
rgba
argb32
nv21
nv12
time_series
other
--input_layout INPUT_NAME INPUT_LAYOUT,-l INPUT_NAME INPUT_LAYOUT
Layout of each input tensor. If not specified, it will use the default
based on the Source Framework, shape of input and input encoding.
Accepted values are-
NCDHW, NDHWC, NCHW, NHWC, NFC, NCF, NTF, TNF, NF, NC, F, NONTRIVIAL
N = Batch, C = Channels, D = Depth, H = Height, W = Width, F = Feature, T = Time
NDHWC/NCDHW used for5d inputs
NHWC/NCHW used for4d image-like inputs
NFC/NCF used for inputs to Conv1D or other 1D ops
NTF/TNF used for inputs with time steps like the ones used for LSTM op
NF used for2D inputs, like the inputs to Dense/FullyConnected layers
NC used for2D inputs with 1for batch and other forChannels(rarely used)
F used for1D inputs, e.g. Bias tensor
NONTRIVIAL for everything elseFor multiple inputs specify multiple
--input_layout on the command line.
Eg:--input_layout "data1" NCHW --input_layout "data2" NCHW
--custom_io CUSTOM_IO
Use this option to specify a yaml file for custom IO.--dump_relay DUMP_RELAY
Dump Relay ASM and Params at the path provided with the argument
Usage:--dump_relay <path_to_dump>--disable_batchnorm_folding
--keep_disconnected_nodes
Disable Optimization that removes Ops not connected to the main graph.
This optimization uses output names provided over commandline OR
inputs/outputs extracted from the Source model to determine the main graph
--debug [DEBUG] Run the converter in debug mode.-o OUTPUT_PATH,--output_path OUTPUT_PATH
Path where the converted Output model should be saved.If not specified, the
converter model will be written to a file with same name as the input model
--copyright_file COPYRIGHT_FILE
Path to copyright file. If provided, the content of the file will be added
to the output model.--overwrite_model_prefix
If option passed, model generator will use the output path name to use as
model prefix to name functions in <qnn_model_name>.cpp.(Useful for running
multiple models at once) eg: ModelName_composeGraphs. Default is to use
generic "QnnModel_".--exclude_named_tensors
Remove using source framework tensorNames; instead use a counter for naming
tensors. Note: This can potentially help to reduce the final model library
that will be generated(Recommended for deploying model). Default is False.-h,--help show this help message and exit
Quantizer Options:--quantization_overrides QUANTIZATION_OVERRIDES
Use this option to specify a json file with parameters to use for
quantization. These will override any quantization data carried from
conversion(eg TF fake quantization)or calculated during the normal
quantization process. Format defined as per AIMET specification.--keep_quant_nodes Use this option to keep activation quantization nodes in the graph rather
than stripping them.--input_list INPUT_LIST
Path to a file specifying the input data. This file should be a plain text
file, containing one or more absolute file paths per line. Each path is
expected to point to a binary file containing one input in the "raw" format,
ready to be consumed by the quantizer without any further preprocessing.
Multiple files per line separated by spaces indicate multiple inputs to the
network. See documentation for more details. Must be specified for
quantization. All subsequent quantization options are ignored when this is
not provided.--param_quantizer PARAM_QUANTIZER
Optional parameter to indicate the weight/bias quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--act_quantizer ACT_QUANTIZER
Optional parameter to indicate the activation quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--algorithms ALGORITHMS [ALGORITHMS ...]
Use this option to enable new optimization algorithms. Usage is:--algorithms <algo_name1>... The available optimization algorithms are:"cle"- Cross layer equalization includes a number of methods for equalizing
weights and biases across layers in order to rectify imbalances that cause
quantization errors.--bias_bw BIAS_BW Use the --bias_bw option to select the bitwidth to use when quantizing the
biases, either 8(default)or32.--act_bw ACT_BW Use the --act_bw option to select the bitwidth to use when quantizing the
activations, either 8(default)or16.--weight_bw WEIGHT_BW
Use the --weight_bw option to select the bitwidth to use when quantizing the
weights, currently only 8bit(default) supported.--float_bias_bw FLOAT_BIAS_BW
Use the --float_bias_bw option to select the bitwidth to use when biases are
in float, either 32or16.--ignore_encodings Use only quantizer generated encodings, ignoring any user or model provided
encodings.
Note: Cannot use --ignore_encodings with --quantization_overrides
--use_per_row_quantization
Use this option to enable rowwise quantization of Matmul and FullyConnected
ops.--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]
Use per-channel quantization for convolution-based op weights.
Note: This will replace built-in model QAT encodings when used for a given
weight.Usage "--use_per_channel_quantization" to enable or "--
use_per_channel_quantization false" (default) to disable
--use_native_input_files
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_dtype Note: This option is deprecated, use --use_native_input_files option in
future.
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_output_files
Use this option to indicate the data type of the output files
1.float(default): output the file as floats.2. native: outputs the file that is native to the model. For ex.,uint8_t.--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX
Specifies the number of steps to use for computing quantization encodings
such that scale =(max - min)/ number of quantization steps.
The option should be passed as a space separated pair of hexadecimal string
minimum and maximum values. i.e.--restrict_quantization_steps "MIN MAX".
Please note that this is a hexadecimal string literal andnot a signed
integer, to supply a negative value an explicit minus sign is required.
E.g.--restrict_quantization_steps "-0x80 0x7F" indicates an example 8 bit range,--restrict_quantization_steps "-0x8000 0x7F7F" indicates an example 16
bit range.
Custom Op Package Options:--op_package_lib OP_PACKAGE_LIB,-opl OP_PACKAGE_LIB
Use this argument to pass an op package library for quantization. Must be in
the form <op_package_lib_path:interfaceProviderName>and be separated by a
comma for multiple package libs
--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB,-cpl CONVERTER_OP_PACKAGE_LIB
Absolute path to converter op package library compiled by the OpPackage
generator. Must be separated by a comma for multiple package libraries.
Note: Libraries must follow the same order as the xml files.
E.g.1:--converter_op_package_lib absolute_path_to/libExample.so
E.g.2:-cpl absolute_path_to/libExample1.so,absolute_path_to/libExample2.so
-p PACKAGE_NAME,--package_name PACKAGE_NAME
A global package name to be used for each node in the Model.cpp file.
Defaults to Qnn header defined package name
--op_package_config CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...],-opc CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...]
Path to a Qnn Op Package XML configuration file that contains user defined
custom operations.
Architecture Checker Options(Experimental):--arch_checker Note: This option will be soon deprecated. Use the qnn-architecture-checker tool to achieve the same result.
注意:只能指定以下之一:{‘package_name’, ‘op_package_config’}
基本命令行用法如下:
$ qnn-pytorch-converter -i <path>/model.pt
-d <network_input_name><dims>-o <optional_output_path>-p <optional_package_name> # Defaults to "qti.aisw"
qnn-onnx-转换器
qnn -onnx-converter工具将模型从 ONNX 框架转换为 CPP 文件,将模型表示为一系列 QNN API 调用。此外,还会生成包含模型静态权重的二进制文件。
usage: qnn-onnx-converter [--out_node OUT_NAMES][--input_type INPUT_NAME INPUT_TYPE][--input_dtype INPUT_NAME INPUT_DTYPE][--input_encoding INPUT_ENCODING [INPUT_ENCODING ...]][--input_layout INPUT_NAME INPUT_LAYOUT][--custom_io CUSTOM_IO][--dry_run [DRY_RUN]][-d INPUT_NAME INPUT_DIM][-n][-b BATCH][-s SYMBOL_NAME VALUE][--preserve_io PRESERVE_IO][--dump_custom_io_config_template DUMP_CUSTOM_IO_CONFIG_TEMPLATE][--quantization_overrides QUANTIZATION_OVERRIDES][--keep_quant_nodes][--disable_batchnorm_folding][--keep_disconnected_nodes][--input_list INPUT_LIST][--param_quantizer PARAM_QUANTIZER][--act_quantizer ACT_QUANTIZER][--algorithms ALGORITHMS [ALGORITHMS ...]][--bias_bw BIAS_BW][--act_bw ACT_BW][--weight_bw WEIGHT_BW][--ignore_encodings][--use_per_row_quantization][--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]][--use_native_input_files][--use_native_dtype][--use_native_output_files]--input_network INPUT_NETWORK
[--debug [DEBUG]][-o OUTPUT_PATH][--copyright_file COPYRIGHT_FILE][--float_bw FLOAT_BW][--float_bias_bw FLOAT_BIAS_BW][--overwrite_model_prefix][--exclude_named_tensors][--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX][--op_package_lib OP_PACKAGE_LIB][--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB][-p PACKAGE_NAME |--op_package_config CUSTOM_OP_CONFIG_PATHS [CUSTOM_OP_CONFIG_PATHS ...]][-h][--arch_checker]
Script to convert ONNX model into QNN
required arguments:--input_network INPUT_NETWORK,-i INPUT_NETWORK
Path to the source framework model.
optional arguments:--out_node OUT_NAMES,--out_name OUT_NAMES
Name of the graph's output tensor names. Multiple output
nodes should be provided separately like:--out_name out_1 --out_name out_2
--input_type INPUT_NAME INPUT_TYPE,-t INPUT_NAME INPUT_TYPE
Type of data expected by each input op/layer. Type for
each input is |default|ifnot specified. For example:"data" image.Note that the quotes should always be
included in order to handle special characters,
spaces,etc. For multiple inputs specify multiple
--input_type on the command line. Eg:--input_type "data1" image --input_type "data2" opaque
These options get used by DSP runtime and following
descriptions state how input will be handled for each
option.
Image:
Input is float between 0-255and the input's mean is 0.0f and the input's
max is 255.0f. We will cast the float to uint8ts and pass the uint8ts to
the DSP.
Default:
Pass the input as floats to the dsp
directly and the DSP will quantize it.
Opaque:
Assumes input is float because the consumer layer(i.e next
layer)requires it as float, therefore it won't be
quantized.
Choices supported:
image
default
opaque
--input_dtype INPUT_NAME INPUT_DTYPE
The names and datatype of the network input layers
specified in the format [input_name datatype],for
example:'data''float32'.
Default is float32 ifnot specified.
Note that the quotes should always be included in order to handle special
characters, spaces, etc.
For multiple inputs specify multiple --input_dtype on the command line like:--input_dtype 'data1''float32'--input_dtype 'data2''float32'--input_encoding INPUT_ENCODING [INPUT_ENCODING ...],-e INPUT_ENCODING [INPUT_ENCODING ...]
Usage:--input_encoding "INPUT_NAME" INPUT_ENCODING_IN
[INPUT_ENCODING_OUT]
e.g.--input_encoding "data" rgba
Quotes must wrap the input node name to handle special characters,
spaces, etc. To specify encodings for multiple inputs, invoke
--input_encoding for each one.
e.g.--input_encoding "data1" rgba --input_encoding "data2" other
Optionally, an output encoding may be specified for an input node by
providing a second encoding. The default output encoding is bgr.
e.g.--input_encoding "data3" rgba rgb
Input encoding types:
image color encodings: bgr,rgb, nv21, nv12,...
time_series:for inputs of rnn models;
other:not available above or is unknown.
Supported encodings:
bgr
rgb
rgba
argb32
nv21
nv12
time_series
other
--input_layout INPUT_NAME INPUT_LAYOUT,-l INPUT_NAME INPUT_LAYOUT
Layout of each input tensor. If not specified, it will use the default
based on the Source Framework, shape of input and input encoding.
Accepted values are-
NCDHW, NDHWC, NCHW, NHWC, NFC, NCF, NTF, TNF, NF, NC, F, NONTRIVIAL
N = Batch, C = Channels, D = Depth, H = Height, W = Width, F = Feature, T = Time
NDHWC/NCDHW used for5d inputs
NHWC/NCHW used for4d image-like inputs
NFC/NCF used for inputs to Conv1D or other 1D ops
NTF/TNF used for inputs with time steps like the ones used for LSTM op
NF used for2D inputs, like the inputs to Dense/FullyConnected layers
NC used for2D inputs with 1for batch and other forChannels(rarely used)
F used for1D inputs, e.g. Bias tensor
NONTRIVIAL for everything elseFor multiple inputs specify multiple
--input_layout on the command line.
Eg:--input_layout "data1" NCHW --input_layout "data2" NCHW
Note: This flag does not set the layout of the input tensor in the converted DLC.
Please use --custom_io for that.--custom_io CUSTOM_IO
Use this option to specify a yaml file for custom IO.--preserve_io PRESERVE_IO
Use this option to preserve IO layout and datatype. The different ways of usingthis option are as follows:--preserve_io layout <space separated list of names of inputs and outputs of the graph>--preserve_io datatype <space separated list of names of inputs and outputs of the graph>
In thiscase, user should also specify the string - layout or datatype in the command
to indicate that converter needs to preserve the layout or datatype. e.g.--preserve_io layout input1 input2 output1
--preserve_io datatype input1 input2 output1
Optionally, the user may choose to preserve the layout and/or datatype for all
the inputs and outputs of the graph. This can be done in the following two ways:--preserve_io layout
--preserve_io datatype
Additionally, the user may choose to preserve both layout and datatypes for all
IO tensors by just passing the option as follows:--preserve_io
Note: Only one of the above usages are allowed at a time.
Note:--custom_io gets higher precedence than --preserve_io.--dry_run [DRY_RUN] Evaluates the model without actually converting any ops,and returns
unsupported ops/attributes as well as unused inputs and/or outputs if any.
Leave empty or specify "info" to see dry run as a table,or specify "debug"
to show more detailed messages only"
-d INPUT_NAME INPUT_DIM,--input_dim INPUT_NAME INPUT_DIM
The name and dimension of all the input buffers to the network specified in
the format [input_name comma-separated-dimensions],for example:'data'1,224,224,3.
Note that the quotes should always be included in order to handle special
characters, spaces, etc.
NOTE: This feature works only with Onnx 1.6.0and above
-n,--no_simplification
Do not attempt to simplify the model automatically. This may prevent some
models from properly converting
-b BATCH,--batch BATCH
The batch dimension override. This will take the first dimension of all
inputs and treat it as a batch dim, overriding it with the value provided
here. For example:--batch 6
will result in a shape change from [1,3,224,224] to [6,3,224,224].
If there are inputs without batch dim this should not be used and each input
should be overridden independently using-d option for input dimension
overrides.-s SYMBOL_NAME VALUE,--define_symbol SYMBOL_NAME VALUE
This option allows overriding specific input dimension symbols. For instance
you might see input shapes specified with variables such as :
data:[1,3,height,width]
To override these simply pass the option as:--define_symbol height 224--define_symbol width 448
which results in dimensions that look like:
data:[1,3,224,448]--dump_custom_io_config_template
Dumps the yaml templatefor Custom I/O configuration. This file can be edited
as per the custom requirements and passed using the option --custom_ioUse
this option to specify a yaml file to which the custom IO config template is
dumped.--disable_batchnorm_folding
--keep_disconnected_nodes
Disable Optimization that removes Ops not connected to the main graph.
This optimization uses output names provided over commandline OR
inputs/outputs extracted from the Source model to determine the main graph
--debug [DEBUG] Run the converter in debug mode.-o OUTPUT_PATH,--output_path OUTPUT_PATH
Path where the converted Output model should be saved.If not specified, the
converter model will be written to a file with same name as the input model
--copyright_file COPYRIGHT_FILE
Path to copyright file. If provided, the content of the file will be added
to the output model.--float_bw FLOAT_BW Use the --float_bw option to select the bitwidth to use when usingfloatforparameters(weights/bias)and activations for all ops or specific Op(via
encodings) selected through encoding, either 32(default)or16.--overwrite_model_prefix
If option passed, model generator will use the output path name to use as
model prefix to name functions in <qnn_model_name>.cpp.(Useful for running
multiple models at once) eg: ModelName_composeGraphs. Default is to use
generic "QnnModel_".--exclude_named_tensors
Remove using source framework tensorNames; instead use a counter for naming
tensors. Note: This can potentially help to reduce the final model library
that will be generated(Recommended for deploying model). Default is False.-h,--help show this help message and exit
Quantizer Options:--quantization_overrides QUANTIZATION_OVERRIDES
Use this option to specify a json file with parameters to use for
quantization. These will override any quantization data carried from
conversion(eg TF fake quantization)or calculated during the normal
quantization process. Format defined as per AIMET specification.--keep_quant_nodes Use this option to keep activation quantization nodes in the graph rather
than stripping them.--input_list INPUT_LIST
Path to a file specifying the input data. This file should be a plain text
file, containing one or more absolute file paths per line. Each path is
expected to point to a binary file containing one input in the "raw" format,
ready to be consumed by the quantizer without any further preprocessing.
Multiple files per line separated by spaces indicate multiple inputs to the
network. See documentation for more details. Must be specified for
quantization. All subsequent quantization options are ignored when this is
not provided.--param_quantizer PARAM_QUANTIZER
Optional parameter to indicate the weight/bias quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--act_quantizer ACT_QUANTIZER
Optional parameter to indicate the activation quantizer to use. Must be
followed by one of the following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses an algorithm useful
for quantizing models with long tails present in the weight distribution
"adjusted": Uses an adjusted min/max for computing the range, particularly
good for denoise models "symmetric": Ensures min and max have the same
absolute values about zero. Data will be stored as int#_t data such that the
offset is always 0.--algorithms ALGORITHMS [ALGORITHMS ...]
Use this option to enable new optimization algorithms. Usage is:--algorithms <algo_name1>... The available optimization algorithms are:"cle"- Cross layer equalization includes a number of methods for equalizing
weights and biases across layers in order to rectify imbalances that cause
quantization errors.--bias_bw BIAS_BW Use the --bias_bw option to select the bitwidth to use when quantizing the
biases, either 8(default)or32.--act_bw ACT_BW Use the --act_bw option to select the bitwidth to use when quantizing the
activations, either 8(default)or16.--weight_bw WEIGHT_BW
Use the --weight_bw option to select the bitwidth to use when quantizing the
weights, currently only 8bit(default) supported.--float_bias_bw FLOAT_BIAS_BW
Use the --float_bias_bw option to select the bitwidth to use when biases are
in float, either 32or16.--ignore_encodings Use only quantizer generated encodings, ignoring any user or model provided
encodings.
Note: Cannot use --ignore_encodings with --quantization_overrides
--use_per_row_quantization
Use this option to enable rowwise quantization of Matmul and FullyConnected
ops.--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]
Use per-channel quantization for convolution-based op weights.
Note: This will replace built-in model QAT encodings when used for a given
weight.Usage "--use_per_channel_quantization" to enable or "--
use_per_channel_quantization false" (default) to disable
--use_native_input_files
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_dtype Note: This option is deprecated, use --use_native_input_files option in
future.
Boolean flag to indicate how to read input files:1.float(default): reads inputs as floats and quantizes if necessary based
on quantization parameters in the model.2. native: reads inputs assuming the data type to be native to the
model. For ex.,uint8_t.--use_native_output_files
Use this option to indicate the data type of the output files
1.float(default): output the file as floats.2. native: outputs the file that is native to the model. For ex.,uint8_t.--restrict_quantization_steps ENCODING_MIN, ENCODING_MAX
Specifies the number of steps to use for computing quantization encodings
such that scale =(max - min)/ number of quantization steps.
The option should be passed as a space separated pair of hexadecimal string
minimum and maximum values. i.e.--restrict_quantization_steps "MIN MAX".
Please note that this is a hexadecimal string literal andnot a signed
integer, to supply a negative value an explicit minus sign is required.
E.g.--restrict_quantization_steps "-0x80 0x7F" indicates an example 8 bit range,--restrict_quantization_steps "-0x8000 0x7F7F" indicates an example 16
bit range. This argument is required for16-bit Matmul operations.
Custom Op Package Options:--op_package_lib OP_PACKAGE_LIB,-opl OP_PACKAGE_LIB
Use this argument to pass an op package library for quantization. Must be in
the form <op_package_lib_path:interfaceProviderName>and be separated by a
comma for multiple package libs
--converter_op_package_lib CONVERTER_OP_PACKAGE_LIB,-cpl CONVERTER_OP_PACKAGE_LIB
Absolute path to converter op package library compiled by the OpPackage
generator. Must be separated by a comma for multiple package libraries.
Note: Libraries must follow the same order as the xml files.
E.g.1:--converter_op_package_lib absolute_path_to/libExample.so
E.g.2:-cpl absolute_path_to/libExample1.so,absolute_path_to/libExample2.so
-p PACKAGE_NAME,--package_name PACKAGE_NAME
A global package name to be used for each node in the Model.cpp file.
Defaults to Qnn header defined package name
--op_package_config OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...],-opc OP_PACKAGE_CONFIG [OP_PACKAGE_CONFIG ...]
Path to a Qnn Op Package XML configuration file that contains user defined
custom operations.
Architecture Checker Options(Experimental):--arch_checker Note: This option will be soon deprecated. Use the qnn-architecture-checker tool to achieve the same result.
Note: Only one of:{'package_name','op_package_config'} can be specified
6.2 模型准备
量化支持
量化通过转换器接口支持并在转换时执行。启用量化和转换所需的唯一选项是 –input_list 选项,它为量化器提供给定模型所需的输入数据。上面列出的每个转换器都提供以下选项来启用和配置量化:
Quantizer Options:--quantization_overrides QUANTIZATION_OVERRIDES
Use this option to specify a json file with parameters
to use for quantization. These will override any
quantization data carried from conversion(eg TF fake
quantization)or calculated during the normal
quantization process. Format defined as per AIMET
specification.--input_list INPUT_LIST
Path to a file specifying the input data. This file
should be a plain text file, containing one or more
absolute file paths per line. Each path is expected to
point to a binary file containing one input in the
"raw" format, ready to be consumed by the quantizer
without any further preprocessing. Multiple files per
line separated by spaces indicate multiple inputs to
the network. See documentation for more details. Must
be specified for quantization. All subsequent
quantization options are ignored when this is not
provided.--param_quantizer PARAM_QUANTIZER
Optional parameter to indicate the weight/bias
quantizer to use. Must be followed by one of the
following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses
an algorithm useful for quantizing models with long
tails present in the weight distribution "adjusted":
Uses an adjusted min/max for computing the range,
particularly good for denoise models "symmetric":
Ensures min and max have the same absolute values
about zero. Data will be stored as int#_t data such
that the offset is always 0.--act_quantizer ACT_QUANTIZER
Optional parameter to indicate the activation
quantizer to use. Must be followed by one of the
following options:"tf": Uses the real min/max of the
data and specified bitwidth(default)"enhanced": Uses
an algorithm useful for quantizing models with long
tails present in the weight distribution "adjusted":
Uses an adjusted min/max for computing the range,
particularly good for denoise models "symmetric":
Ensures min and max have the same absolute values
about zero. Data will be stored as int#_t data such
that the offset is always 0.--algorithms ALGORITHMS [ALGORITHMS ...]
Use this option to enable new optimization algorithms.
Usage is:--algorithms <algo_name1>... The
available optimization algorithms are:"cle"- Cross
layer equalization includes a number of methods for
equalizing weights and biases across layers in order
to rectify imbalances that cause quantization errors.--bias_bw BIAS_BW Use the --bias_bw option to select the bitwidth to use
when quantizing the biases, either 8(default)or32.--act_bw ACT_BW Use the --act_bw option to select the bitwidth to use
when quantizing the activations, either 8(default)or16.--weight_bw WEIGHT_BW
Use the --weight_bw option to select the bitwidth to
use when quantizing the weights, currently only 8bit(default) supported.--float_bias_bw FLOAT_BIAS_BW
Use the --float_bias_bw option to select the bitwidth to
use when biases are in float, either 32or16.--ignore_encodings Use only quantizer generated encodings, ignoring any
user or model provided encodings. Note: Cannot use
--ignore_encodings with --quantization_overrides
--use_per_channel_quantization [USE_PER_CHANNEL_QUANTIZATION [USE_PER_CHANNEL_QUANTIZATION ...]]
Use per-channel quantization for
convolution-based op weights. Note: This will replace
built-in model QAT encodings when used for a given
weight.Usage "--use_per_channel_quantization" to
enable or"--use_per_channel_quantization false"(default) to disable
--use_per_row_quantization [USE_PER_ROW_QUANTIZATION [USE_PER_ROW_QUANTIZATION ...]]
Use this option to enable rowwise quantization of Matmul and
FullyConnected op. Usage "--use_per_row_quantization" to enable
or"--use_per_row_quantization false"(default) to
disable. This option may not be supported by all backends.
使用 TF 转换器转换和量化模型的基本命令行用法如下:
$ qnn-tensorflow-converter -i <path>/frozen_graph.pb
-d <network_input_name><dims>--out_node <network_output_name>-o <optional_output_path>--allow_unconsumed_nodes # optional, but most likely will be need for larger models
-p <optional_package_name> # Defaults to "qti.aisw"--input_list input_list.txt
这将使用默认量化器和位宽(8 位用于激活、权重和偏差)来量化网络。
有关量化、选项和算法的更多详细信息,请参阅量化。
qnn-模型库-生成器
笔记
适合想要在 Windows-PC 下或具有 Windows 操作系统的 Qualcomm 设备上执行模型准备工具的开发人员。
qnn-model-lib-generator 位于 SDK 中的 /bin/x86_64-windows-msvc 下,供本机 Windows-PC 使用。
对于想要在 Windows 操作系统设备上运行 qnn-model-lib-generator 的开发人员,它位于 /bin/aarch64-windows-msvc 下。
qnn-model-lib-generator 将尝试使用您平台上的 CMake 命令来生成库。
请确保已安装编译工具(windows平台编译工具),以确保Windows操作系统中的CMake可行。
qnn -model-lib-generator工具将 QNN 模型源代码编译为特定目标的工件。
usage: qnn-model-lib-generator [-h][-c <QNN_MODEL>.cpp][-b <QNN_MODEL>.bin][-t LIB_TARGETS ][-l LIB_NAME][-o OUTPUT_DIR]
Script compiles provided Qnn Model artifacts for specified targets.
Required argument(s):-c <QNN_MODEL>.cpp Filepath for the qnn model .cpp file
optional argument(s):-b <QNN_MODEL>.bin Filepath for the qnn model .bin file(Note:ifnot passed, runtime will fail if.cpp needs any items from a .bin file.)-t LIB_TARGETS Specifies the targets to build the models for. Default: aarch64-android x86_64-linux-clang
-l LIB_NAME Specifies the name to use for libraries. Default: uses name in <model.bin>if provided,else generic qnn_model.so
-o OUTPUT_DIR Location for saving output libraries.
笔记
对于Windows用户,请使用python3执行该工具。
qnn-op-包生成器
qnn-op-package-generator工具用于使用描述包属性的 XML 配置文件生成 QNN op 包的框架代码。该工具将包创建为包含框架源代码和 makefile 的目录,可以编译这些文件以创建共享库对象。
usage: qnn-op-package-generator [-h]--config_path CONFIG_PATH [--debug][--output_path OUTPUT_PATH][-f]
optional arguments:-h,--help show this help message and exit
required arguments:--config_path CONFIG_PATH,-p CONFIG_PATH
The path to a config file that defines a QNN Op
package(s).
optional arguments:--debug Returns debugging information from generating the
package
--output_path OUTPUT_PATH,-o OUTPUT_PATH
Path where the package should be saved
-f,--force-generation
This option will delete the entire existing package
Note appropriate file permissions must be set to use
this option.--converter_op_package,-cop
Generates Converter Op Package skeleton code needed
by the output shape inference for converters
qnn-上下文-二进制生成器
qnn -context-binary-generator工具用于通过使用特定后端并使用qnn-model-lib-generator创建的模型库来创建上下文二进制文件。
usage: qnn-context-binary-generator --model QNN_MODEL.so --backend QNN_BACKEND.so
--binary_file BINARY_FILE_NAME
[--model_prefix MODEL_PREFIX][--output_dir OUTPUT_DIRECTORY][--op_packages ONE_OR_MORE_OP_PACKAGES][--config_file CONFIG_FILE.json][--profiling_level PROFILING_LEVEL][--verbose][--version][--help]
REQUIRED ARGUMENTS:---------------------model <FILE> Path to the <qnn_model_name.so> file containing a QNN network.
To create a context binary with multiple graphs, use
comma-separated list of model.so files. The syntax is
<qnn_model_name_1.so>,<qnn_model_name_2.so>.--backend <FILE> Path to a QNN backend .so library to create the context binary.--binary_file <VAL> Name of the binary file to save the context binary to.
Saved in the same path as --output_dir option with .bin
as the binary file extension. If not provided, no backend binary
is created.
OPTIONAL ARGUMENTS:---------------------model_prefix Function prefix to use when loading <qnn_model_name.so> file
containing a QNN network. Default: QnnModel.--output_dir <DIR> The directory to save output to. Defaults to ./output.--op_packages <VAL> Provide a comma separated list of op packages
and interface providers to register. The syntax is:
op_package_path:interface_provider[,op_package_path:interface_provider...]--profiling_level <VAL> Enable profiling. Valid Values:1. basic: captures execution and init time.2. detailed: in addition to basic, captures per Op timing
for execution.3. backend: backend-specific profiling level specified
in the backend extension related JSON config file.--profiling_option <VAL> Set profiling options:1. optrace: Generates an optrace of the run.--config_file <FILE> Path to a JSON config file. The config file currently
supports options related to backend extensions and
context priority. Please refer to SDK documentation
for more details.--enable_intermediate_outputs Enable all intermediate nodes to be output along with
default outputs in the saved context.
Note that options --enable_intermediate_outputs and--set_output_tensors
are mutually exclusive. Only one of the options can be specified at a time.--set_output_tensors <VAL> Provide a comma-separated list of intermediate output tensor names,for which the outputs
will be written in addition to final graph output tensors.
Note that options --enable_intermediate_outputs and--set_output_tensors
are mutually exclusive. Only one of the options can be specified at a time.
The syntax is: graphName0:tensorName0,tensorName1;graphName1:tensorName0,tensorName1
--backend_binary <VAL> Name of the file to save a backend-specific context
binary to.
Saved in the same path as --output_dir option with .bin
as the binary file extension.--log_level Specifies max logging level to be set. Valid settings:"error","warn","info"and"verbose"--input_output_tensor_mem_type <VAL> Specifies mem type to be used for input and output tensors during graph creation.
Valid settings:"raw"and"memhandle"--version Print the QNN SDK version.--help Show this help message.
有关更多详细信息和选项,请参阅qnn-net-run部分。–op_packages–config_file
版权归原作者 weixin_38498942 所有, 如有侵权,请联系我们删除。