

**©PaperWeekly 原创 · 作者 | **孙裕道
**学校 | **北京邮电大学博士生
**研究方向 | **GAN图像生成、情绪对抗样本生成
元学习(meta-learning)是过去几年最火爆的学习方法之一,各式各样的 paper 都是基于元学习展开的。深度学习模型训练模型特别吃计算硬件,尤其是人为调超参数时候,更需要大量的计算。另一个头疼的问题是在某个任务下大量数据训练的模型,切换到另一个任务后,模型就需要重新训练,这样非常耗时耗力。工业界财大气粗有大量的 GPU 可以承担起这样的计算成本,但是学术界因为经费有限经不起这样的消耗。元学习可以有效的缓解大量调参和任务切换模型重新训练带来的计算成本问题。

元学习介绍
元学习希望使得模型获取一种学会学习调参的能力,使其可以在获取已有知识的基础上快速学习新的任务。机器学习是先人为调参,之后直接训练特定任务下深度模型。元学习则是先通过其它的任务训练出一个较好的超参数,然后再对特定任务进行训练。
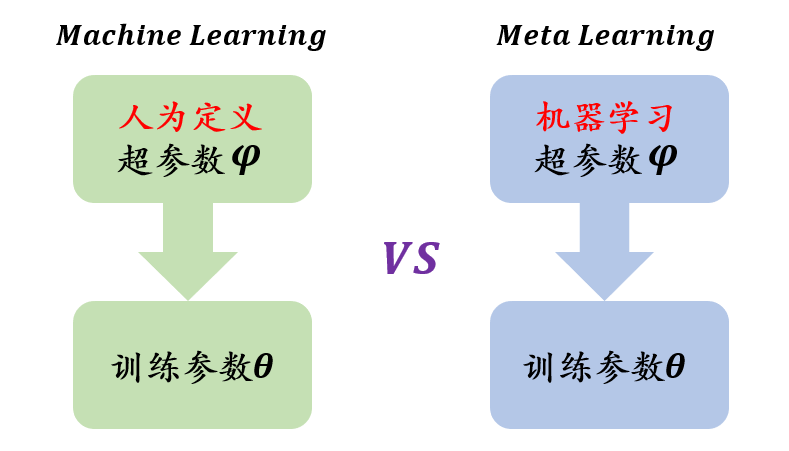
在机器学习中,训练单位是样本数据,通过数据来对模型进行优化;数据可以分为训练集、测试集和验证集。在元学习中,训练单位是任务,一般有两个任务分别是训练任务(Train Tasks)亦称跨任务(Across Tasks)和测试任务(Test Task)亦称单任务(Within Task)。训练任务要准备许多子任务来进行学习,目的是学习出一个较好的超参数,测试任务是利用训练任务学习出的超参数对特定任务进行训练。训练任务中的每个任务的数据分为 Support set 和 Query set;Test Task 中数据分为训练集和测试集。
令 表示需要设置的超参数, 表示神经网络待训练的参数。元学习的目的就是让函数 在训练任务中自动训练出 ,再利用 这个先验知识在测试任务中训练出特定任务下模型 中的参数 ,如下所示的依赖关系:
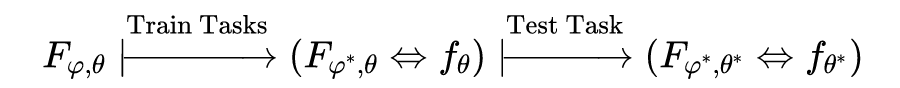
当训练一个神经网络的时候,具体一般步骤有,预处理数据集 ,选择网络结构 ,设置超参数 ,初始化参数 ,选择优化器 ,定义损失函数 ,梯度下降更新参数 。具体步骤如下图所示:
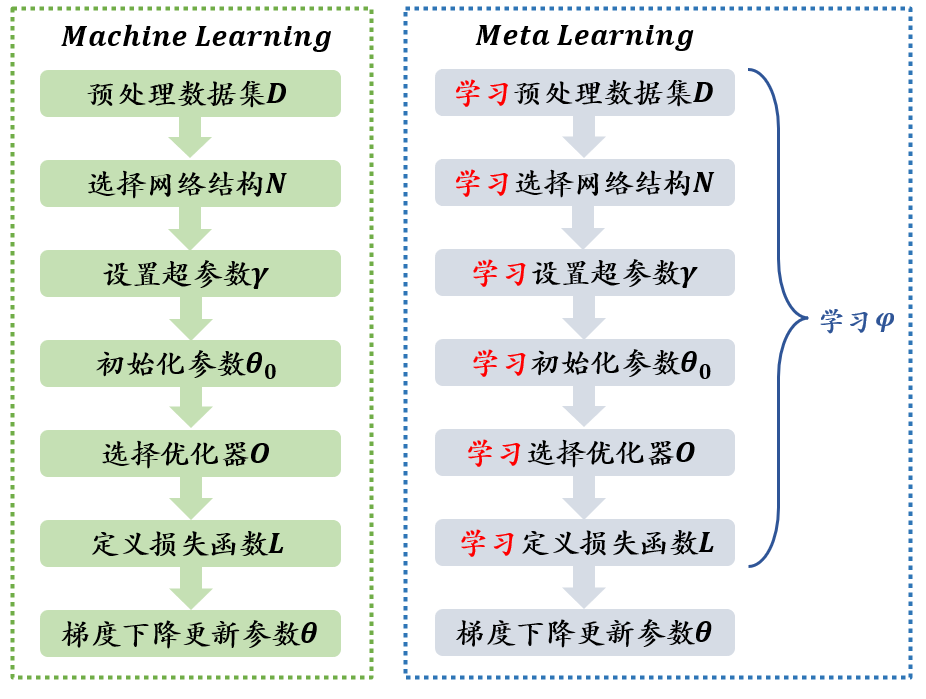
元学习会去学习所有需要由人去设置和定义的参数变量 。在这里参数变量 属于集合为 ,则有:
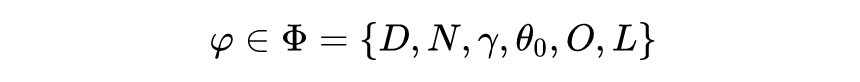
不同的元学习,就要去学集合 中不同的元素,相应的就会有不同的研究领域。
学习预处理数据集 :对数据进行预处理的时候,数据增强会增加模型的鲁棒性,一般的数据增强方式比较死板,只是对图像进行旋转,颜色变换,伸缩变换等。元学习可以自动地,多样化地为数据进行增强,相关的代表作为 DADA。
论文名称:DADA: Differentiable Automatic Data Augmentation
论文链接:https://arxiv.org/pdf/2003.03780v1.pdf
论文详情:ECCV 2020
**学习初始化参数 **:权重参数初始化的好坏可以影响模型最后的分类性能,元学习可以通过学出一个较好的权重初始化参数有助于模型在新的任务上进行学习。元学习学习初始化参数的代表作是 MAML(Model-Agnostic-Meta-Learning)。它专注于提升模型整体的学习能力,而不是解决某个具体问题的能力,训练时,不停地在不同的任务上切换,从而达到初始化网络参数的目的,最终得到的模型,面对新的任务时可以学习得更快。
论文名称:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
论文链接:https://arxiv.org/pdf/1703.03400.pdf
论文详情:ICML2017
学习网络结构 :神经网络的结构设定是一个很头疼的问题,网络的深度是多少,每一层的宽度是多少,每一层的卷积核有多少个,每个卷积核的大小又该怎么定,需不需要 dropout 等等问题,到目前为止没有一个定论或定理能够清晰准确地回答出以上问题,所以神经网络结构搜索 NAS 应运而生。归根结底,神经网络结构其实是元学习地一个子类领域。值得注意的是,网络结构的探索不能通过梯度下降法来获得,这是一个不可导问题,一般情况下会采用强化学习或进化算法来解决。
论文名称:Neural Architecture Search with Reinforcement Learning
论文链接:https://arxiv.org/abs/1611.01578
论文详情:ICLR 2017
学习选择优化器 :神经网络训练的过程中很重要的一环就是优化器的选取,不同的优化器会对优化参数时对梯度的走向有很重要的影响。熟知的优化器有Adam,RMsprop,SGD,NAG等,元学习可以帮我们在训练特定任务前选择一个好的的优化器,其代表作有:
论文名称:Learning to learn by gradient descent by gradient descent
论文链接:https://arxiv.org/pdf/1606.04474.pdf
论文详情:NIPS 2016

元学习训练
元学习分为两个阶段,阶段一是训练任务训练;阶段二为测试任务训练。对应于一些论文的算法流程图,训练任务是在 outer loop 里,测试任务任务是在 inner loop 里。
2.1 阶段一:训练任务训练
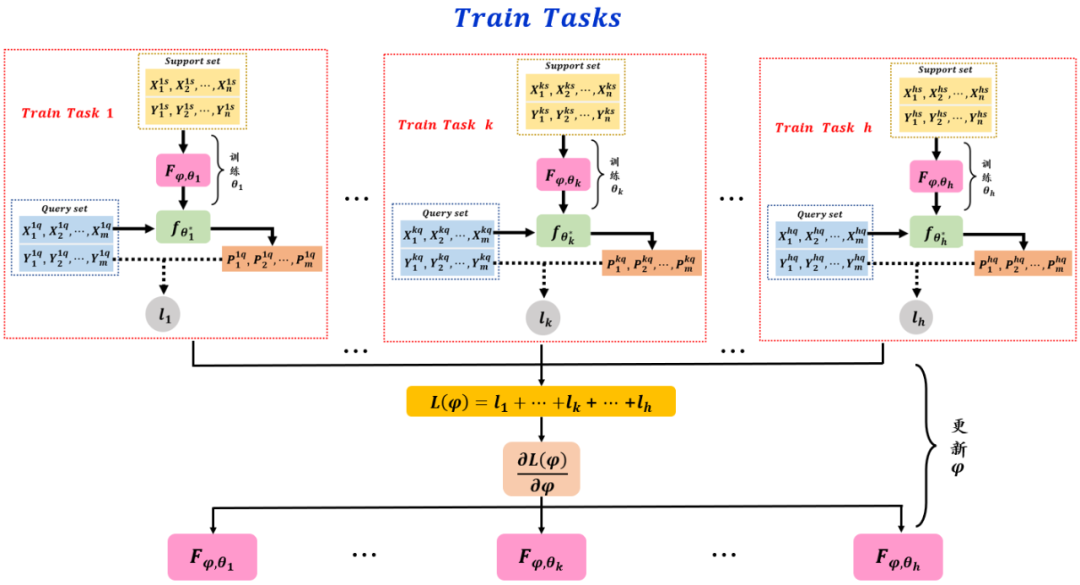
在训练任务中给定 个子训练任务,每个子训练任务的数据集分为 Support set 和 Query set。首先通过这 个子任务的 Support set 训练 ,分别训练出针对各自子任务的模型参数 。然后用不同子任务中的 Query set 分别去测试 的性能,并计算出预测值和真实标签的损失 。接着整合这 个损失函数为 :
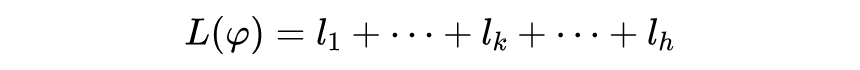
最后利用梯度下降法去求出 去更新参数 ,从而找到最优的超参设置;如果 不可求,则可以采用强化学习或者进化算法去解决。阶段一中训练任务的训练过程被整理在如下的框图中。
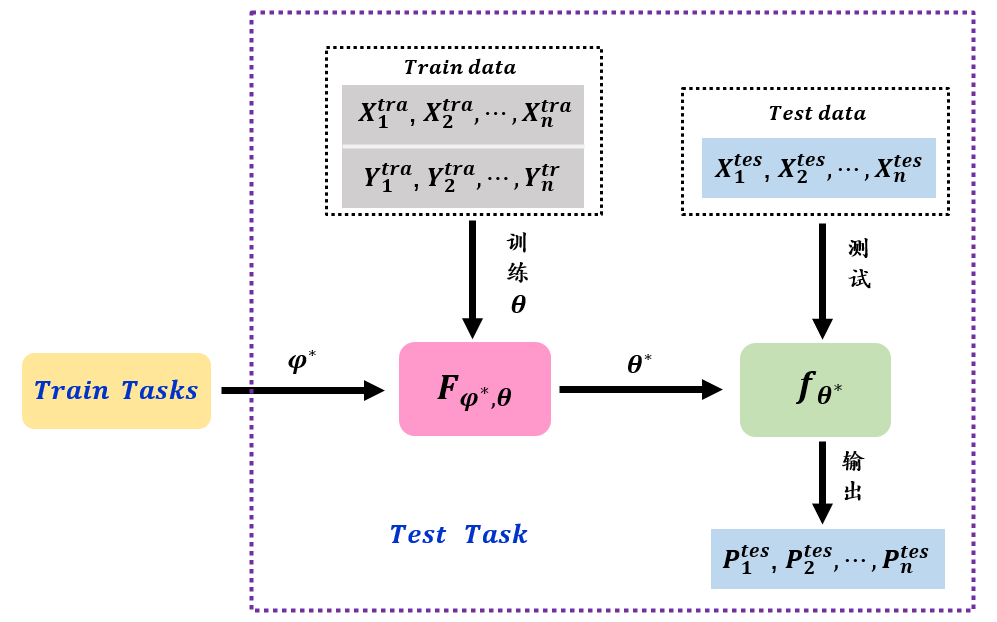
2.2 阶段二:测试任务训练
测试任务就是正常的机器学习的过程,它将数据集划分为训练集和测试集。阶段一中训练任务的目的是找到一个好的超参设置 ,利用这个先验知识可以对特定的测试任务进行更好的进行训练。阶段二中测试任务的训练过程被整理在如下的框图中。

实例讲解
上一节主要是给出了元学习两阶段的学习框架,这一节则是给出实例并加以说明。明确超参 为初始化权重参数,通过元学习让模型学习出一个较优的初始化权重。假设在 AcrossTasks 中有 个子任务,第 个子任务 Support set 和 Query set 分别是 和 。第 个子任务的网络权重参数为 ,元学习初始化的参数为 的原理图如下所示,其具体过程为:
第一步:将所有子任务分类器的网络结构设置为一样的,从 个子任务中随机采样出 个子任务,并将初始权重 赋值给这 个网络结构。
第二步:采样出的 个子任务分别在各自的 Support set 上进行训练并更新参数 。在 MAML 中参数 更新一步,在 Reptile 中参数 更新多步。
第三步:利用上一步训练出的 在 Query set 中进行测试,计算出各自任务下的损失函数 。
第四步:将不同子任务下的损失函数 进行整合得到 。
第五步:求出损失函数 关于 的导数,并对初始化参数 进行更新。
循环以上个步骤,直到达到要求为止。

为了能够更直观的给出利用 更新参数 的过程,我硬着头皮把梯度 的显示表达式给写了出来,具体形式如下所示:
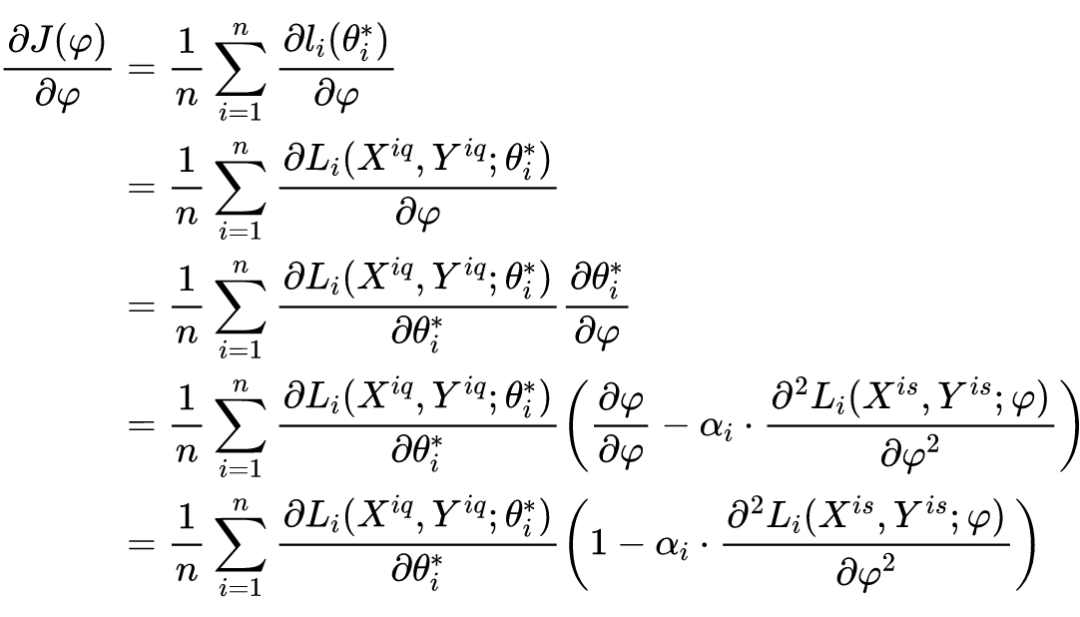
从这个公式中也能隐约的发现整个训练过程的缩影,它已经把所有的变量都囊括了进去,这个公式也直接回答了一个问题,元学习自动学习权重参数 是一个可导问题。
整理到这里有一个问题必须要被回答,元学习学习初始化权重的方法和预训练方法有什么区别?为了能够更直观的对比这两个方法的异同,将预训练的过程整理为如下流程图,具体的过程为:

第一步:前提只有一个神经网路模型其初始化权重参数为 ,从 个子任务中随机采样出 个子任务。
第二步:神经网络模型在采样出的 个子任务中进行训练,得到不同子任务中的损失 。
第三步:将不同子任务下的损失函数 进行整合得到 。
第四步:求出损失函数 关于 的导数,并对初始化参数 进行更新。
循环以上个步骤,直到达到要求为止。对应的在预训练过程中,梯度 的表达式为:
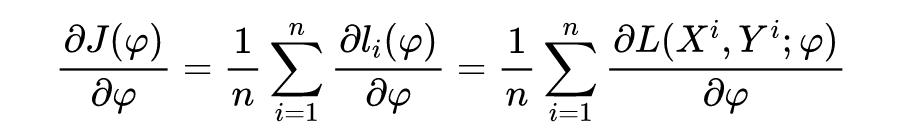
可以发现在相同的网络结构下,预训练是只有一套模型参数在不同的任务中进行训练,元学习是在不同的任务中有不同的模型参数进行训练。对比二者的梯度公式可以发现,预训练过程简单粗暴它想找到一个在所有任务(实际情况往往是大多数任务)上都表现较好的一个初始化参数,这个参数要在多数任务上当前表现较好。元学习过程相对繁琐,但它更关注的是初始化参数未来的潜力。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读

#投 稿 通 道#
** 让你的文字被更多人看到 **
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

版权归原作者 PaperWeekly 所有, 如有侵权,请联系我们删除。