
1.总结
流程具体操作基本查看查看缺失值、查看重复值、查看数值类型预处理缺失值处理(确定是否处理后,使用筛选方式删除)拆分数据 、标签的特征处理(处理成0/1格式)、特征工程(one-hot编码)数据分析groupby分组求最值数据、seaborn可视化预测拆分数据集、建立模型、训练模型、预测、评估模型
数量查看:条形图
占比查看:饼图
数据分区分布查看:概率密度函数图
2.数据预处理
2.1 导入数据集与库并基本查看数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
dataset = pd.read_csv('data.csv')
2.2 数据的基本查看
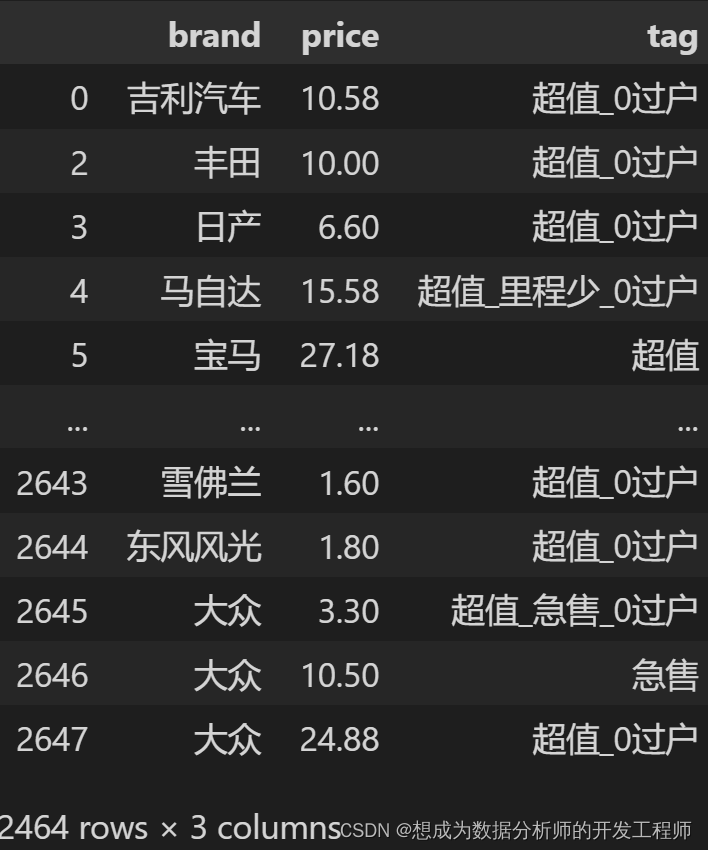
# 整体查看:tag标签中数据需要拆分、并且存在缺失值
dataset.head()# 对数值类型的变量进行查看
dataset.describe()# 查看缺失值数量:缺失值不多,可以直接删了
dataset[dataset['tag'].notna()]
2.3 缺失值处理与获取标签值
# 删选出标签不为NaN的二手车数据(因为缺失值数量不多)
dataset = dataset[dataset["tag"].notna()]
dataset
# 拆分标签
tag_list =[]# apply函数:会自动循环每一行的数据 并且执行中间的匿名函数
dataset['tag'].apply(lambda x:tag_list.extend(x.split("_")))# 对元素去重,再次转换为列表
tag_list =list(set(tag_list))# 获取到所有的标签值
tag_list
2.4 标签的特征处理
与one-hot编码很类似,但是one-hot编码只能存在1位有效状态
'''
新增列:每个tag标签都是一列
若存在这个标签设置为1;不存在为0
'''# 创建DataFrame,列名称是tag_list里的元素
tag_df = pd.DataFrame(columns=tag_list)# 拼接两个DataFrame
df = pd.concat([dataset,tag_df],sort=False)# 将tag_list对应的NaN填充为0
df[tag_list]= df[tag_list].fillna(0)# 将tag中的数据处理为数字(0或1)# 传递的series为一行的数据defset_tag_status(series):
tags = series['tag'].split('_')# 将tag用_进行拆分for t in tags:# 若这一行存在这个标签,就直接把他改成1
series[t]=1return series
# 将df[['tag',*tag_list]]的每一行应用到set_tag_status函数中,删除'tag'列,最后替换掉df[tag_list]部分# *tag_list是拆分这个列表
df[tag_list]= df[["tag",*tag_list]].apply(lambda x:set_tag_status(x), axis=1).drop("tag",axis=1)
df = df.drop("tag",axis=1)# 删除tag列
df.head()
最终效果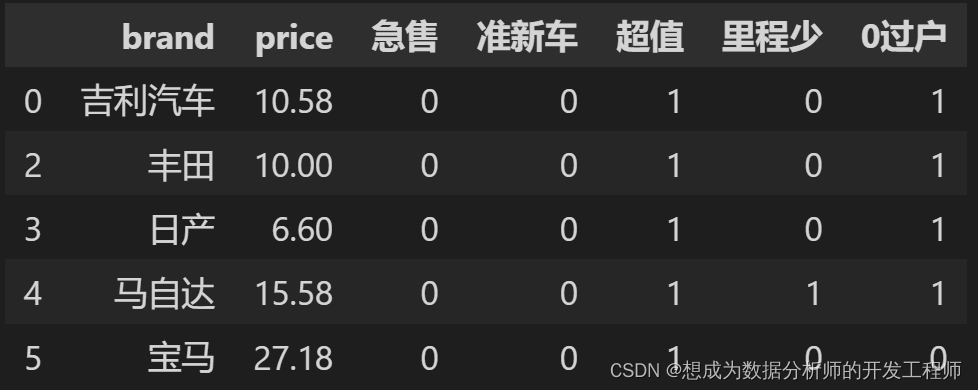
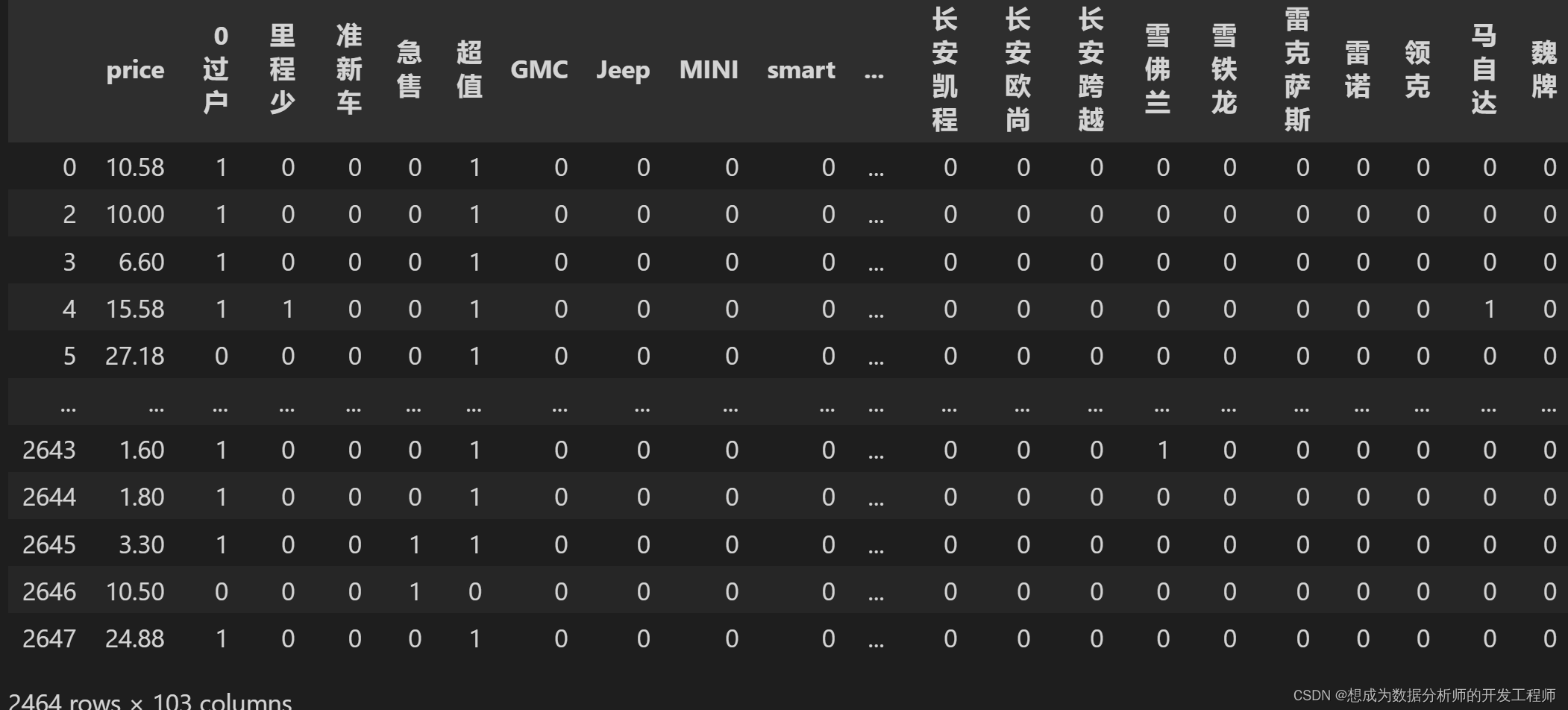
2.5 特征工程(one-hot编码)
什么是ont-hot编码
One-Hot编码是分类变量作为二进制向量的表示。又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候只有一位有效(设置为1),无效的状态标记为0。
# 创建dataframe记录one-hot编码
one_hot_df = pd.get_dummies(df['brand'])# 删除brand列
df.drop("brand",axis=1,inplace=True)# 合并两个dataframe, 以左右两张表相同索引进行合并
df = pd.merge(df, one_hot_df, left_index=True, right_index=True)
df
3.数据分析
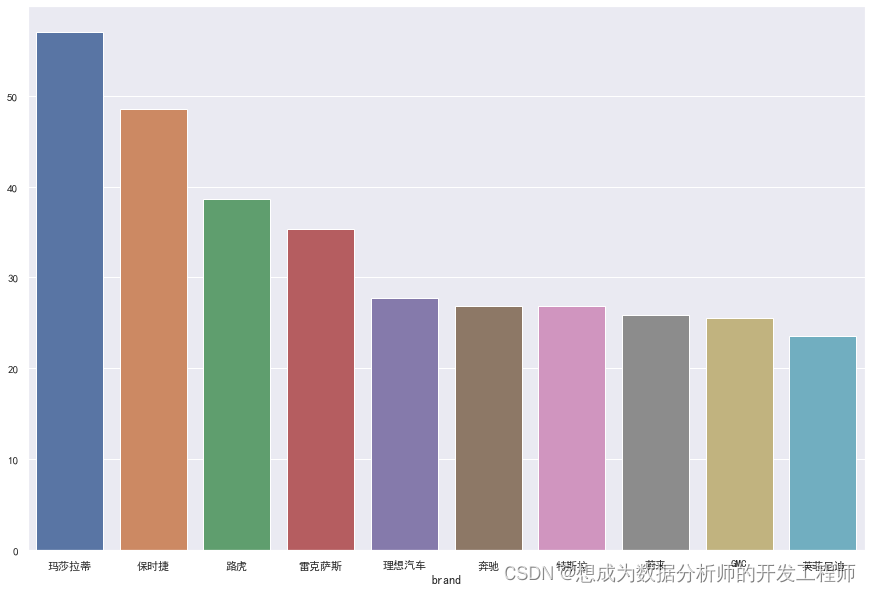
3.1 价格分析
分析平均价格最高的前10个品牌
# 分析平均价格最高的前10个品牌
num_top = df.groupby("brand")['price'].mean().sort_values(ascending=False)[:10]# seaborn绘制条形图
sns.set(font='SimHei')# 设置中文字体
fig = plt.figure(figsize=(15,10))# 设置图像大小
sns.barplot(x=num_top.index, y=num_top.values)# 绘制条形图# plt.xticks(rotation=90) 设置x刻度轴旋转角度
fig.show()
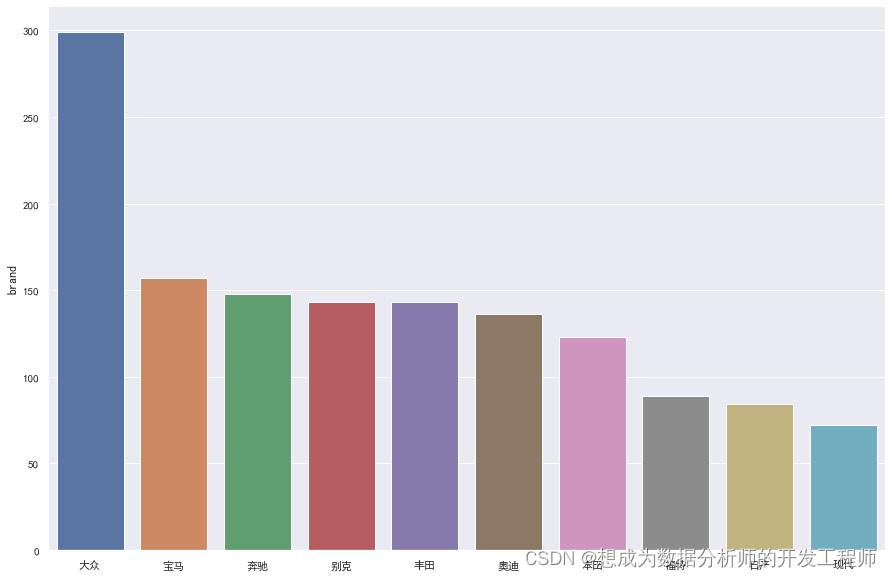
3.2 销量分析——销量分析、销量占比分析
销量最多的前10个品牌
# 销量最多的前10个品牌
amount_top = df["brand"].value_counts(sort=True)[:10]
fig = plt.figure(figsize=(15,10))# 设置图像大小
sns.barplot(x=amount_top.index, y=amount_top)# 绘制条形图# plt.xticks(rotation=90) 设置x刻度轴旋转角度
fig.show()
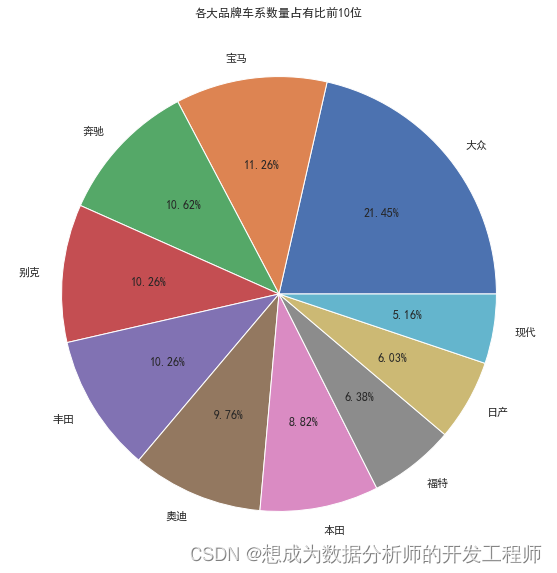
销量占比分析(饼图)
# 销量占比分析(饼图)
fig = plt.figure(figsize=(15,10))# 设置图像大小
plt.pie(amount_top, labels=amount_top.index, autopct="%1.2f%%")# 绘制条形图;设置保留两位小数,数字1可以不写,保留小数点前至少1位数字(防止报错)
plt.title("各大品牌车系数量占有比前10位")# plt.xticks(rotation=90) 设置x刻度轴旋转角度
fig.show()
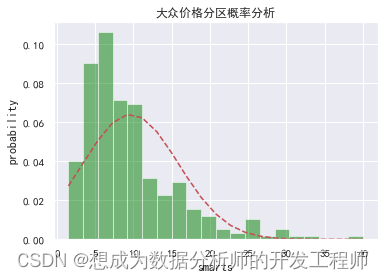
3.3 价格分区概率分析
绘制直方图与概率密度函数图
# 1.数据准备(基本数据)# 获取大众品牌记录
df_dazhong = df[df["brand"]=='大众']
dazhong_mean = df_dazhong["price"].mean()
dazhong_std = df_dazhong['price'].std()
num_bins =20# 条状图数量(分为几组)# 2.绘制直方图# density 代表是否归一化:如果没有归一化,数据会非常大,不成为密度
n, bins, patches = plt.hist(df_dazhong["price"], num_bins, facecolor="green", density=True,alpha=0.5)# 3.准备数据(概率密度)from scipy.stats import norm
# 计算概率密度函数值
y = norm.pdf(bins, dazhong_mean, dazhong_std)# 4.绘制概率密度函数图
plt.plot(bins, y,'r--')
plt.xlabel('smarts')
plt.ylabel('probability')
plt.title('大众价格分区概率分析')
plt.subplots_adjust(left=0.15)
plt.show()
4.建立模型:梯度提升回归算法
# 1.数据准备# 只要除了预测值以外的数据值
X = df[df.columns.difference(['price'])].values
# 预测的目标值的数据
Y = df['price']# 2.导入所需要的库from sklearn.model_selection import train_test_split # 拆分数据集from sklearn.ensemble import GradientBoostingRegressor # 梯度提升回归算法类GBRfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 评估函数# 3.拆分数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=666)# 4.建立模型:# n_estimators:评估指标
gbdt = GradientBoostingRegressor(n_estimators=80)# 5.训练模型
gbdt.fit(X_train, Y_train)# 6.预测
pred = gbdt.predict(X_test)# 7.评估print('MSE',mean_squared_error(Y_test,pred))print('MAE',mean_absolute_error(Y_test,pred))print('RMSE',np.sqrt(mean_squared_error(Y_test,pred)))print('R2',r2_score(Y_test,pred))
本文转载自: https://blog.csdn.net/m0_63953077/article/details/129160610
版权归原作者 想成为数据分析师的开发工程师 所有, 如有侵权,请联系我们删除。
版权归原作者 想成为数据分析师的开发工程师 所有, 如有侵权,请联系我们删除。