
文章目录
上一篇
人工智能原理复习–搜索策略(二)
机器学习概述
学习系统的基本结构:
#mermaid-svg-DcbcVpboR5GiQzvJ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .error-icon{fill:#552222;}#mermaid-svg-DcbcVpboR5GiQzvJ .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-DcbcVpboR5GiQzvJ .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-DcbcVpboR5GiQzvJ .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-DcbcVpboR5GiQzvJ .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-DcbcVpboR5GiQzvJ .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-DcbcVpboR5GiQzvJ .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-DcbcVpboR5GiQzvJ .marker{fill:#333333;stroke:#333333;}#mermaid-svg-DcbcVpboR5GiQzvJ .marker.cross{stroke:#333333;}#mermaid-svg-DcbcVpboR5GiQzvJ svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-DcbcVpboR5GiQzvJ .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .cluster-label text{fill:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .cluster-label span{color:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .label text,#mermaid-svg-DcbcVpboR5GiQzvJ span{fill:#333;color:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .node rect,#mermaid-svg-DcbcVpboR5GiQzvJ .node circle,#mermaid-svg-DcbcVpboR5GiQzvJ .node ellipse,#mermaid-svg-DcbcVpboR5GiQzvJ .node polygon,#mermaid-svg-DcbcVpboR5GiQzvJ .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-DcbcVpboR5GiQzvJ .node .label{text-align:center;}#mermaid-svg-DcbcVpboR5GiQzvJ .node.clickable{cursor:pointer;}#mermaid-svg-DcbcVpboR5GiQzvJ .arrowheadPath{fill:#333333;}#mermaid-svg-DcbcVpboR5GiQzvJ .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-DcbcVpboR5GiQzvJ .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-DcbcVpboR5GiQzvJ .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-DcbcVpboR5GiQzvJ .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-DcbcVpboR5GiQzvJ .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-DcbcVpboR5GiQzvJ .cluster text{fill:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ .cluster span{color:#333;}#mermaid-svg-DcbcVpboR5GiQzvJ div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-DcbcVpboR5GiQzvJ :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
环境
学习
知识库
执行
环境向系统的学习部分提供某些信息
学习利用这些信息修改数据库,以怎金系统执行部分完成任务的效能
执行部分根据知识库完成任务,同时把获得的信息反馈给学习部分
最重要的因素是`环境向系统提供的信息
机器学习分类:
- 监督学习:决策树、支持向量机(SVM)、k-临近算法(KNN)
- 无监督学习:k-均值、DBSCAN密度聚类算法、最大期望算法
- 强化学习:环境,奖励,状态 ,动作–> 状态奖励
归纳(示例)学习
归纳学习是一种通过观察和分析现象,发现其中规律和模式,并据此进行预测和决策的方法。归纳学习的基本思想是通过从数据样本中归纳出一般性规律或模式,从而实现对未知数据的预测和分类。
归纳学习是通过一系列的示例(正例和反例)出发,生成一个反映这些示例本质的定义:
- 覆盖所有的正例,而不包含任何反例
- 可用来指导对新例子的分类识别
归纳学习过程可以分为以下几个步骤:
- 数据采集:收集需要学习的数据样本。
- 特征提取:从数据样本中提取出有用的特征,用于归纳学习。
- 模型训练:使用归纳学习算法从数据样本中归纳出一般性规律或模式。
- 模型评估:使用测试数据对归纳模型进行评估,计算出模型的准确率和误差。
- 模型应用:使用归纳模型对新的数据进行分类或预测。
概念描述搜索及获取
- 例子空间:所有可能的正例、反例构成的空间
- 假设空间:所有可能的假设(概念描述)构成的空间
- 顶层假设:最泛化的概念描述,不指定任何的特征值
- 底层假设:最特化(具体)的概念描述,所有特征都给定特征值
- 假设空间的搜索方法:1、特化搜索(宽度优先,自顶向下) 2、泛化搜索(宽度优先,自底向上) 3、双向搜索(版本空间法)
ID3决策树算法
信息的定量描述
衡量信息多少的物理量称为信息量:
- 若概率很大,受信者事先已有所估计,则该消息信息量就很小
- 若概率很小,受信者感觉很突然,该信息所含信息量就很大
使用信息量函数
f
(
p
)
f(p)
f(p)描述,
f
(
p
)
f(p)
f(p)条件:
f ( p ) f(p) f(p) 应是p的严格单调递减函数- 当p = 1时, f ( p ) = 0 f(p) = 0 f(p)=0, 当p = 0时, f ( p ) = ∞ f(p) = \infty f(p)=∞
- 当两个独立事件的联合信息量应等于他们分别的信息量之和
信息量定义
:若一个消息
x
x
x 出现的的概率为
p
p
p, 则这一消息所含信息量为:
I
=
−
log
p
I = - \log{p}
I=−logp
单位:
- 以2为底,单位 b i t bit bit (
常用) - 以e为底,单位 n a t nat nat
- 以10为底,单位 h a r t hart hart
信息熵
所有可能消息的平均不确定性,信息量的平均值
H
(
X
)
=
−
∑
p
(
x
i
)
log
(
p
(
x
i
)
)
H(X) = -\sum{p(x_i)\log{(p(x_i))}}
H(X)=−∑p(xi)log(p(xi))

定义:
M ( C ) M(C) M(C) 为根节点总的信息熵B ( C , A ) B(C, A) B(C,A) 为根据A属性分类后的加权信息熵的和,每一类占全部的比例作为加权,将分完之后的信息熵加权求和g a i n = M ( C ) − B ( C , A ) gain = M(C) - B(C,A) gain=M(C)−B(C,A)信息增益,信息增益越大越好
分别求出每个属性的信息增益,然后将
最大
的作为这个节点的分类属性
步骤:
- 首先求出根节点的信息熵
- 然后按每个特征求出对应的信息增益
- 比较得出最大的信息增益的特征作为给节点的划分属性
- 循环1-3步直到将全部类别分开,或者划分比例达到要求值
d
ID3算法
优点:
- 计算复杂度不高
- 输出结果易于理解
- 可以处理不相关特征数据
缺点:
- 不能处理带有缺失值的数据集
- 在进行算法学习之前需要对数据集中的缺失值进行预处理
- 存在过拟合问题
K近邻算法
一种监督学习分类算法,没有学习过程,在分类时通过类别已知的样本对新样本的类别进行预测。
基本思路:
- 通过以某个数据为中心,分析离其最近的K个邻居的类型,获得该数据可能的类型
- 以少数服从多数的原理,推断出测试样本的类别
只要训练样本足够多,K近邻算法就能达到很好的分类效果
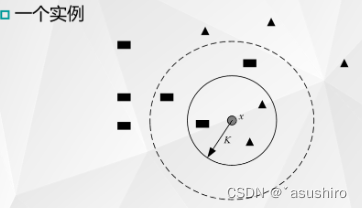
- 当K = 3时,即选择最近的3个点,由于三角形样本所占近邻样本的比例为2/3,于是可以得出圆形输入实例应该为三角形
- 当K = 5时,由于长方形样本栈近邻样本比例为3/5,此时测试样本被归为长方形类别。
步骤:
- 计算测试数据与每个训练数据之间的距离
- 按照距离的递增关系进行排序
- 选取距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回前k个点中出现频率最高的类别做为测试数据的预测分类
优点:
- 简单,便于理解和实现
- 应用范围广
- 分类效果好
- 无需进行参数估计
缺点:
- 样本小时误差难以估计
- 存储所有样本,需要较大存储空间
- 大样本计算量大
- k的取值对结果也有较大影响(k较小对噪声敏感,k过大可能包含别的类样本)
下一篇
人工智能原理课后习题(考试相关的)
`
版权归原作者 ˇasushiro 所有, 如有侵权,请联系我们删除。