
KITTI数据集详解
数据采集车
以下图片来自KITTI官网:KITT官方link
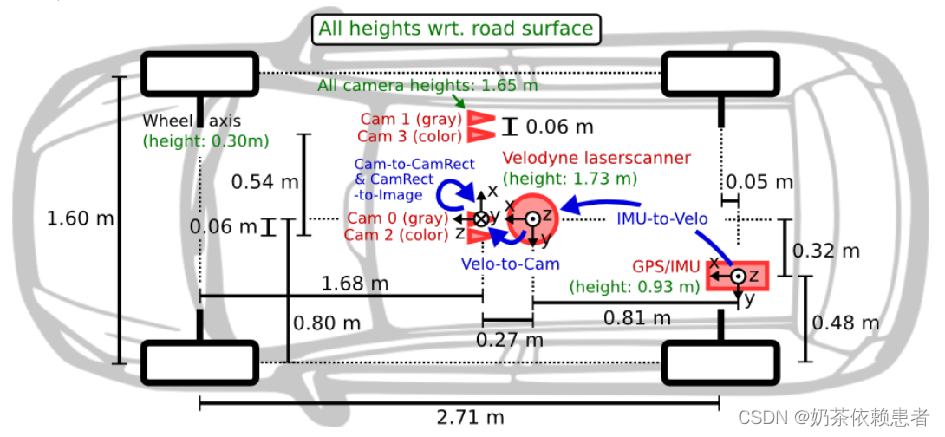
Kitti的数据采集车,顶上是一个64线的velodyne激光雷达,前面有四个摄像头分别是cam0~3,其中0和1是灰度相机,2和3是rgb相机。激光雷达的坐标系遵循右手定则,而相机坐标系遵循左手定则,如图所示。
为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。
四个相机经过了严格的位置矫正,保证yz同值,x同轴,如果想进行lidar与camera的坐标系转换,默认以cam0为基准,即如果是cam0转到velodyne,就直接转,如果是cam其他转velodyne,则先要转到cam0,再转到velodyne,相机和激光的坐标转换后续会详细说明。
目录结构
常见的目录结构如下(参照Det3d):
└── KITTI_DATASET_ROOT
├── training <-- 7481 train data
| ├── image_2 <-- for visualization
| ├── calib
| ├── label_2
| ├── velodyne
| └── velodyne_reduced <-- empty directory
└── testing <-- 7580 test data
├── image_2 <-- for visualization
├── calib
├── velodyne
└── velodyne_reduced <-- empty directory
image_2即2号彩色相机所拍摄的图片(**.png);
calib对应每一帧的外参(.txt);
label_2是每帧的标注信息(.txt);
velodyne是Velodyne64所得的点云文件(.bin**)
视算法任务而定,有些文件夹可能用不到,比如velodyne_reduced,这里是图像和点云融合算法中,裁剪得到的图像范围内的点云文件,如果是单lidar的3D目标检测,这个就用不到了,另外,有一些算法有自己独特的数据增强方式或者数据加载方式(如SECOND),会生成一些.pkl的数据索引字典,或者gt_base等增强数据库。
image_2和velodyne很好理解,就是图像和点云,都能可视化的,下面详细讲讲label和calib。
文件详解
label文件
下面以000000.txt为例:
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
第1个字符串Pedestrian:物体类别:‘Car’, ‘Van’, ‘Truck’,‘Pedestrian’, ‘Person_sitting’, ‘Cyclist’,‘Tram’, ‘Misc’ or ‘DontCare’,共有9类,但常常拿来作为算法之间比较指标的是car、pedestrian、cyclist这三个。注意最后一个’DontCare’标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略’DontCare’区域的预测结果。
第二个数0.00:代表物体是否被截断(指物体是否有部分处于图像边界之外,不是遮挡),从0(非截断)到1(截断)浮动,其中1截断指离开图像边界的对象。
第三个数0:代表物体是否被遮挡,整数0,1,2,3表示被遮挡的程度。
0:完全可见 1:小部分遮挡 2:大部分遮挡 3:完全遮挡(unknown)
第四个数**-0.20**:alpha,物体的观察角度,范围:-pi~pi
是在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角。官方定义写老长,看下面这个图就一目了然了。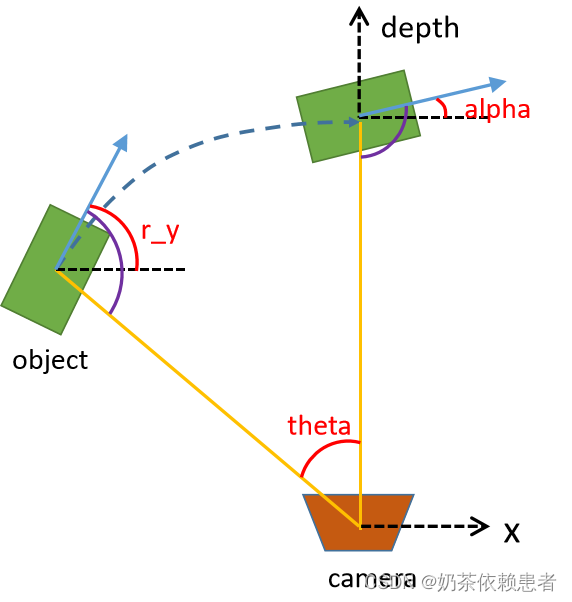
第四个数就是图中的alpha(注意不是theta),我们可以通过几何运算得到alpha和theta的关系:
由于r_y + pi/2 -theta = alpha +pi/2(即图中紫色的角是相等的)
等式两边同时减去pi/2,得到:alpha = r_y - theta
第5~8这四个数712.40 143.00 810.73 307.92:物体的2维边界框xmin,ymin,xmax,ymax,坐标系是在camera坐标系下。
第9~11这三个数1.89 0.48 1.20:3维物体的尺寸,高、宽、长(单位:米)
第12~14这三个数1.84 1.47 8.41:3维物体中心的位置xyz(依然是在camera坐标系下)
第15个数0.01:3维物体的空间方向:rotation_y,依然是在camera坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角,也就是左图中的r_y),范围:-pi~pi
第16个数:检测的置信度,这个数据只在测试集的数据中有,我这里给出的是训练集,所以没有第16个数。
注意:1、默认的长度单位是米,角度单位是弧度
2、各个坐标均在camrea坐标系下
3、区分第四个数和第十五个数,一个是alpha,一个是r_y
calib文件
数据太长了,下面是截图,注意源数据没有空行,我为了方便观看,加了空行,使用的时候要去掉空行,每个txt文件中有7个矩阵,我用红框框出来了。
P0 – P3(3x4):就是对应的cam0 ~ cam3这四个相机矫正后的投影矩阵,每个都是3*4的矩阵(有关投影矩阵的具体知识,可以看网址:投影矩阵),每个矩阵的形式如下:
[fu 0 cu -fubx
0 fv cv 0
0 0 1 0]
其中bx指的是相对于0号摄像头(cam0默认是参考摄像头)的基准值,单位米。
R0_rect(3x3):矫正后的相机矩阵,注意在使用的时候需要reshape成4x4,具体方法是在R(4, 4)处添1,其余6个位置添0。
Tr_velo_to_cam(3x4):velodyne到camera的旋转平移矩阵,此矩阵包含两个模块,左侧3x3的旋转矩阵和右侧13的平移向量,具体使用时也要reshape成44,具体方法是在最后添加一行(0,0,0,1)。
Tr_imu_to_velo(3x4):IMU到velodyne的旋转平移矩阵,结构和使用方法跟Tr_velo_to_cam类似。
calib的使用方法
要将Velodyne坐标中的点x投影到左侧的彩色图像中y:
使用公式:y = P2 * R0_rect *Tr_velo_to_cam * x
将Velodyne坐标中的点投影到其他彩色图像中,只需要替换上面的P2,比如投影到右侧彩色图像中:
使用公式:y = P3 * R0_rect *Tr_velo_to_cam * x
Tr_velo_to_cam * x:是将Velodyne坐标中的点x投影到编号为0的相机(参考相机)坐标系中
R0_rect *Tr_velo_to_cam * x:是将Velodyne坐标中的点x投影到编号为2的相机(参考相机)坐标系中
P2 * R0_rect *Tr_velo_to_cam * x:是将Velodyne坐标中的点x投影到编号为2的相机(参考相机)坐标系中,再投影到编号为2的相机(左彩色相机)的照片上(相机坐标系转像素坐标系)
注意:所有矩阵都存储在主行中,即第一个值对应于第一行。 R0_rect包含一个3x3矩阵,需要将其扩展为4x4矩阵,方法是在右下角添加1,在其他位置添加0。 Tr_xxx是一个3x4矩阵(R | t),需要以相同的方式扩展到4x4矩阵。
版权归原作者 奶茶依赖患者 所有, 如有侵权,请联系我们删除。