
Qualcomm® AI Engine Direct 使用手册(3)
3.3 环境设置
Linux
满足 Linux 平台依赖性后,可以使用提供的 envsetup 设置用户环境.sh 脚本。
在 Linux 主机上打开命令 shell 并运行:
$ source ${QNN_SDK_ROOT}/bin/envsetup.sh
这将设置/更新以下环境变量:
- QNN_SDK_ROOT
- Python路径
- 小路
- LD_LIBRARY_PATH
${QNN_SDK_ROOT} 代表 Qualcomm® 的完整路径AI Engine Direct SDK 根目录。
QNN API 标头位于 ${QNN_SDK_ROOT}/include/QNN 中。
工具位于${QNN_SDK_ROOT}/bin/x86_64-linux-clang中。
目标特定后端和其他库位于${QNN_SDK_ROOT}/lib/*/中。
TensorFlow 设置
请使用 https://pypi.org/project/tensorflow/2.10.1/ 将 TensorFlow 安装为独立的 Python 模块 如果安装 tf-1.15.0 请参阅上面的 python3.6 安装部分。确保TensorFlow
在你的 PYTHONPATH 中使用这个测试代码:
$ python3 -c "import tensorflow"
请参阅机器学习框架了解有关 Qualcomm® 版本的信息AI Engine Direct SDK已通过验证。请注意
安装 1.15.0 或 2.10.1 之外的 TensorFlow 版本可能会更新依赖项(例如 numpy)。
ONNX 设置
请使用 将 ONNX 作为独立的 Python 模块安装https://pypi.org/project/onnx/1.11.0/ 并使用以下测试代码确保 ONNX 位于您的 PYTHONPATH 中:
$ python3 -c "import onnx"
请参阅机器学习框架了解有关 Qualcomm® 版本的信息AI Engine Direct SDK已通过验证。
TFLite 设置
请使用 https://pypi.org/project/tflite/2.3.0/ 将 TFLite 作为独立的 Python 模块安装 并使用以下测试代码确保 TFLite 位于您的 PYTHONPATH 中:
$ python3 -c "import tflite"
请参阅机器学习框架了解有关 Qualcomm® 版本的信息AI Engine Direct SDK已通过验证。
PyTorch 设置
请使用 将 PyTorch v1.13.1 安装为独立的 Python 模块https://pytorch.org/get-started/previous-versions/#v1131 并使用以下测试代码确保 PyTorch 位于您的 PYTHONPATH 中:
$ python3 -c "import torch"
请参阅机器学习框架了解有关 Qualcomm® 版本的信息AI Engine Direct SDK已通过验证。
视窗
满足 Windows 平台依赖关系后,可以使用提供的 envsetup 设置用户环境.ps1 脚本。
首先,以管理员身份打开。Developer PowerShell for VS2022
$ Set-ExecutionPolicy RemoteSigned
然后,执行以下脚本。
$ &"<QNN_SDK_ROOT>\bin\envsetup.ps1"
这将设置/更新以下环境变量:
- QNN_SDK_ROOT
${QNN_SDK_ROOT} 代表 Qualcomm® 的完整路径AI Engine Direct SDK 根目录。
QNN API 标头位于 ${QNN_SDK_ROOT}/include/QNN 中。
工具位于${QNN_SDK_ROOT}/bin/x86_64-linux-clang中。
目标特定后端和其他库位于${QNN_SDK_ROOT}/lib/*/中。
笔记
envsetup.ps1只需要在 Windows 主机上执行。
4. 后端
客户端通过后端与 Qualcomm® 交互AI Engine Direct。一般来说,Qualcomm® AI Engine Direct 后端是一个软件实体 它实现了QNN API,并且通常以 共享库。术语“QNN 后端”和“QNN 后端库”经常互换使用。
QNN 后端库为每个硬件加速器核心提供集成模块化(如概述部分所述)。
QNN SDK 提供了多个后端库。这些库可以在 <QNN_SDK_ROOT>/lib/ 文件夹中找到。 QNN 后端库遵循与平台相关的命名规则(有关更多详细信息,请参阅平台差异)。 在可用后端库表库描述中,我们通过与平台无关的名称来引用后端库。
可用的 QNN SDK 后端库
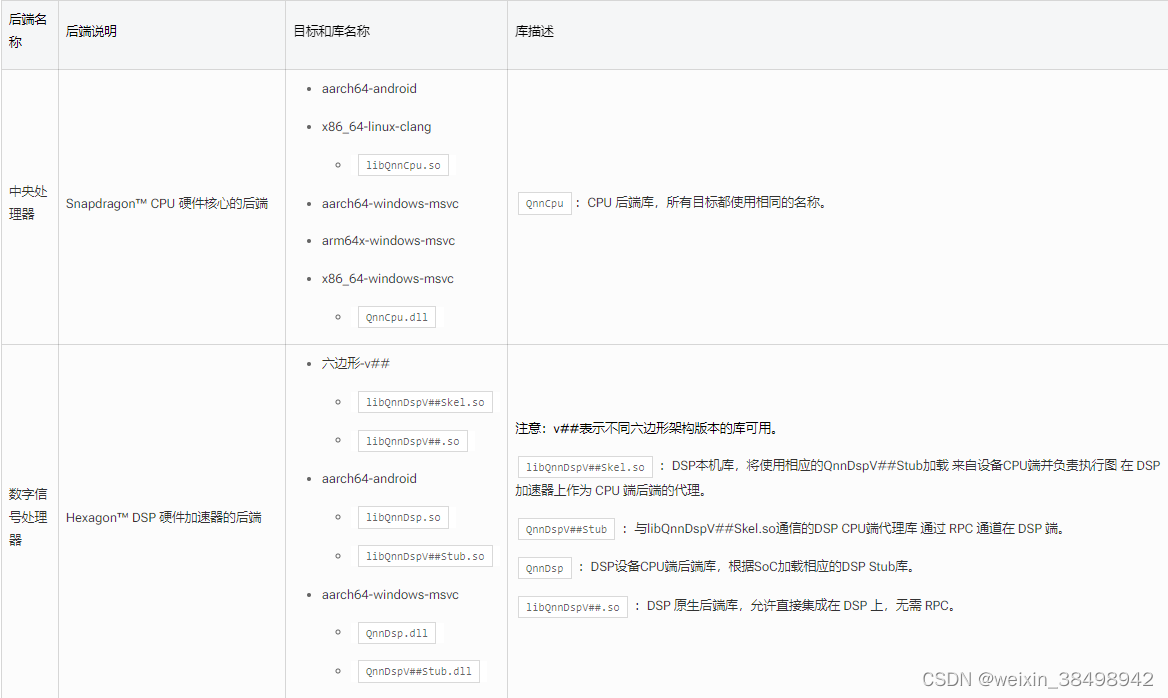

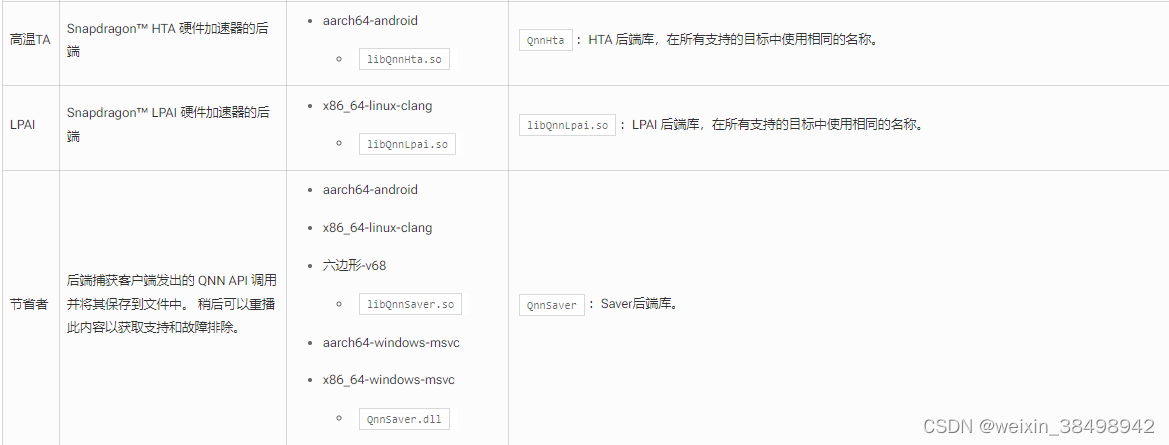
4.1 后端特定页面
4.1.1 数字信号处理器
本节提供特定于 QNN DSP 后端的信息。
API 专业化
本节包含与 DSP 后端 API 专业化相关的信息。所有QNN DSP 后端专业化可在 <QNN_SDK_ROOT>/include/QNN/DSP/ 目录下找到。
QNN DSP 后端 API 的当前版本是:
QNN_DSP_API_VERSION_MAJOR 5
QNN_DSP_API_VERSION_MINOR 0
QNN_DSP_API_VERSION_PATCH 1
QNN DSP 性能基础架构 API
客户端可以调用 QnnBackend_getPerfInfrastruct 加载 QNN DSP 库后,然后调用可用的方法 文件 QnnDspPerfInfrastruct.h。这些 API 允许客户端控制 DSP 加速器的系统设置,从而对加速器进行细粒度控制。 一些用例是:
- 通过控制电压角点来设置投票策略。
- 设置 DCVS 模式以实现适用于用例的不同性能设置。
- 设置加速器的线程数。
笔记:
- 如果 dcvsEnableConfig 为 DCVS 参与标志,则 DCVS 参与标志将设置为 FALSE QnnDspPerfInfrastruct_DcvsEnable_t 未提供。
- 在电源设置调用中,如果未指定电源模式,则电源模式将设置为省电模式 配置的一部分。
4.1.2 HTP
本节提供特定于 QNN HTP 后端的信息。
- API 专业化
- 使用预期
- QNN HTP 支持的操作
- QNN HTP 后端 API
- QNN HTP 性能基础架构 API
- QNN HTP精密
- QNN HTP FP16 SM8550 和 SM8650 输出差异
- QNN HTP 深度学习带宽压缩 (DLBC)
- QNN HTP - 设置 HVX 线程数
- QNN HTP 后端扩展
- QNN HTP 分析
- QNN 上下文二进制大小
- Op写作指南
- 网络设计建议
- VTCM分享
- 子系统重启 (SSR)
- Qmem 图(仅共享缓冲区图)
- 批量推理和多线程推理的好处
API 专业化
本部分包含与 HTP 后端 API 专业化相关的信息。所有 QNN HTP 后端专业化可在 <QNN_SDK_ROOT>/include/QNN/HTP/ 目录下找到。
QNN HTP 后端 API 的当前版本是:
QNN_HTP_API_VERSION_MAJOR 5
QNN_HTP_API_VERSION_MINOR 17
QNN_HTP_API_VERSION_PATCH 0
使用预期
- 调用 QnnGraph_addNode() 的顺序 构建QNN模型应该按照节点依赖顺序完成。
- QnnBackend_registerOpPackage() 接受一个名为“target”的可选参数。下面给出的是“目标”的可接受值- “CPU” - 适用于 linux x86 和 ARM op 软件包- “HTP” - 用于加载到 HTP 上的 op 包。- 空指针- 用于在 ARM 上加载上下文二进制文件 - 加载已注册的 HTP op 包- 对于 linux x86 - 注册 linux x86 op 包
- 加载为不同 HTP 架构生成的上下文二进制文件可能会给出不确定的结果。
QNN HTP 支持的操作
QNN HTP 支持在所有 Qualcomm SoC 上运行量化 8 位和量化 16 位网络。 QNN HTP Quant 运行时支持的操作列表可以在后端支持 HTP 列下查看 支持的操作
QNN HTP 支持在选定的 Qualcomm SoC 上使用 float16 数学运行 float32 网络。 如果 QNN SDK 支持 QNN HTP Float,则 HTP Float 运行时支持的操作列表 可以在支持的操作中的后端支持 HTP_FP16 列中看到
对于支持 QNN HTP Float 的 QNN SDK,请注意,即使 HTP 和 HTP_FP16 在支持的操作的单独列下列出,它们是 单一“逻辑”后端。在选定的 SoC 上,QNN HTP 后端库支持量化和浮点网络。 单独的列是为了区分不同支持的操作列表 量化和浮动 QNN HTP 运行时。
QNN HTP 可变批次
QNN HTP 以有限的方式支持可变批量维度。图执行时的批量维度可以是 图表准备中提供的相应维度的整数倍。所有输入和输出张量必须具有 同一批次的多个。例如,如果图准备中提供的张量维度为 [b,h,w,d],则 可以使用维度为 [n*b,h,w,d] 的张量来执行图,其中 n 是正整数。
QNN HTP 后端 API
File QnnHtpDevice.h 是与 文件 QnnDevice.h。该头文件允许客户端将 QnnDevice 配置为 满足特定的用例。
结构体 QnnHtpGraph_CustomConfig_t 在 文件 QnnHtpGraph.h 中定义 是与 File QnnGraph.h 一起使用的后端专业化标头
QNN HTP 设备配置选项 (QnnHtpDevice_CustomConfig_t)
选项名称选项 说明默认何时使用QNN_HTP_DEVICE_CONFIG_OPTION_SOC用于识别 SoC 型号的整数值QNN_SOC_MODEL_SM8350客户端可以提供 socModel 来指示目标 SoCQNN_HTP_DEVICE_CONFIG_OPTION_ARCH用于配置设备以设置 HTP Arch 的数据结构。驱动程序将使用ops 与此 HTP Arch 兼容QNN_HTP_DEVICE_ARCH_NONE当使用多个设备时,客户端可以作为自定义配置的一部分提供QNN_HTP_DEVICE_CONFIG_OPTION_SIGNEDPD启用签名的进程域。为了使用这个标志,客户端还需要推送一个签名的 dsp 图像到目标False(未签名的进程域)客户端使用签名的进程域。查看 Hexagon SDK 文档了解更多详细信息。
客户端可以设置SocModel如下: 参考Qnn_SocModel_t设置Soc Model。
QnnHtpDevice_CustomConfig_t customConfig;
customConfig.option = QNN_HTP_DEVICE_CONFIG_OPTION_SOC;
customConfig.socModel = QNN_SOC_MODEL_SM8550;
QnnDevice_Config_t devConfig;
devConfig.option = QNN_DEVICE_CONFIG_OPTION_CUSTOM;
devConfig.customConfig =&customConfig;const QnnDevice_Config_t* pDeviceConfig[]={&devConfig,NULL};
客户端可以设置Htp架构如下: 请参考QnnHtpDevice_Arch_t设置Htp Arch。
QnnHtpDevice_CustomConfig_t customConfig;
customConfig.option = QNN_HTP_DEVICE_CONFIG_OPTION_ARCH;
customConfig.arch.arch = QNN_HTP_DEVICE_ARCH_V73;
customConfig.arch.deviceId =0;// Id of device to be used. If single device is used by default 0.
QnnDevice_Config_t devConfig;
devConfig.option = QNN_DEVICE_CONFIG_OPTION_CUSTOM;
devConfig.customConfig =&customConfig;const QnnDevice_Config_t* pDeviceConfig[]={&devConfig,NULL};
客户可以设置签名PD如下:
QnnHtpDevice_CustomConfig_t customConfig;
customConfig.option = QNN_HTP_DEVICE_CONFIG_OPTION_SIGNEDPD;
customConfig.useSignedProcessDomain.useSignedProcessDomain = true;
customConfig.useSignedProcessDomain.deviceId =0;// Id of device to be used. If single device is used by default 0.
QnnDevice_Config_t devConfig;
devConfig.option = QNN_DEVICE_CONFIG_OPTION_CUSTOM;
devConfig.customConfig =&customConfig;const QnnDevice_Config_t* pDeviceConfig[]={&devConfig,NULL};
QNN HTP 上下文配置选项 (QnnHtpContext_CustomConfig_t)

客户端可以按如下方式启用权重共享:
QnnHtpContext_CustomConfig_t customConfig;
customConfig.option = QNN_HTP_CONTEXT_CONFIG_OPTION_WEIGHT_SHARING_ENABLED;
customConfig.weightSharingEnabled = true;// set to false to disable weight sharing
QnnContext_Config_t contextConfig;
contextConfig.option = QNN_CONTEXT_CONFIG_OPTION_CUSTOM;
contextConfig.customConfig =&customConfig;const QnnContext_Config_t* pContextConfig[]={&contextConfig,NULL};
笔记
权重共享功能有一定的要求和限制:
仅支持离线准备。不支持在线准备和ARM离线准备。
仅支持 Hexagon V75 架构。
仅在单个 PD 内支持。跨 PD 或跨不同 VTCM 尺寸和 SoC 共享 不支持。
任何以前生成的二进制文件都不会自动受益于权重共享。用户是 需要重新生成新的序列化二进制文件才能从权重共享中受益。旧的序列化二进制文件 在没有重量共享功能的情况下仍然可以工作。
客户端可以为多个上下文设置共享溢出填充缓冲区详细信息,如下所示:
笔记
此功能仅针对离线准备用例启用。在创建期间 二进制 blob (qnn-context-binary-generator),每个图的溢出填充缓冲区信息 在 x86 上准备时打印如下:
>>>"====== Prepared Graph's Summary ======">>>"Spill fill buffer size = 30081024"
// ===== FIRST CONTEXT =====
QnnHtpContext_CustomConfig_t customConfig;
customConfig.option = QNN_HTP_CONTEXT_CONFIG_OPTION_REGISTER_MULTI_CONTEXTS; QnnHtpContext_GroupRegistration_t groupInfo;
groupInfo.firstGroupHandle =0x0;// New group
groupInfo.maxSpillFillBuffer =30081024;// Max spill-fill buffer across contexts. Must be >0
customConfig.groupRegistration = groupInfo;
QnnContext_Config_t* cfgs[]={&customConfig,NULL};QnnContext_createFromBinary(..., cfgs,...,&contextHandle,...);// ===== SECOND CONTEXT =====
QnnHtpContext_CustomConfig_t customConfig2;
customConfig2.option = QNN_HTP_CONTEXT_CONFIG_OPTION_REGISTER_MULTI_CONTEXTS;
QnnHtpContext_GroupRegistration_t groupInfo2;
groupInfo2.firstGroupHandle = contextHandle;// associated to above contextHandle
groupInfo2.maxSpillFillBuffer =30081024;// same value as above OR don't set this now
customConfig2.groupRegistration = groupInfo2;
QnnContext_Config_t* cfgs2[]={&customConfig2,NULL};QnnContext_createFromBinary(..., cfgs2,...,&contextHandle2,...);// ===== THIRD CONTEXT =====
QnnHtpContext_CustomConfig_t customConfig3;
customConfig3.option = QNN_HTP_CONTEXT_CONFIG_OPTION_REGISTER_MULTI_CONTEXTS;
QnnHtpContext_GroupRegistration_t groupInfo3;
groupInfo3.firstGroupHandle = contextHandle;// associated to above contextHandle
groupInfo3.maxSpillFillBuffer =30081024;// same value as above or don't set this
customConfig3.groupRegistration = groupInfo3;
QnnContext_Config_t* cfgs3[]={&customConfig3,NULL};QnnContext_createFromBinary(..., cfgs3,...,&contextHandle3,...);
QNN HTP 图形配置选项 (QnnHtpGraph_CustomConfig_t)
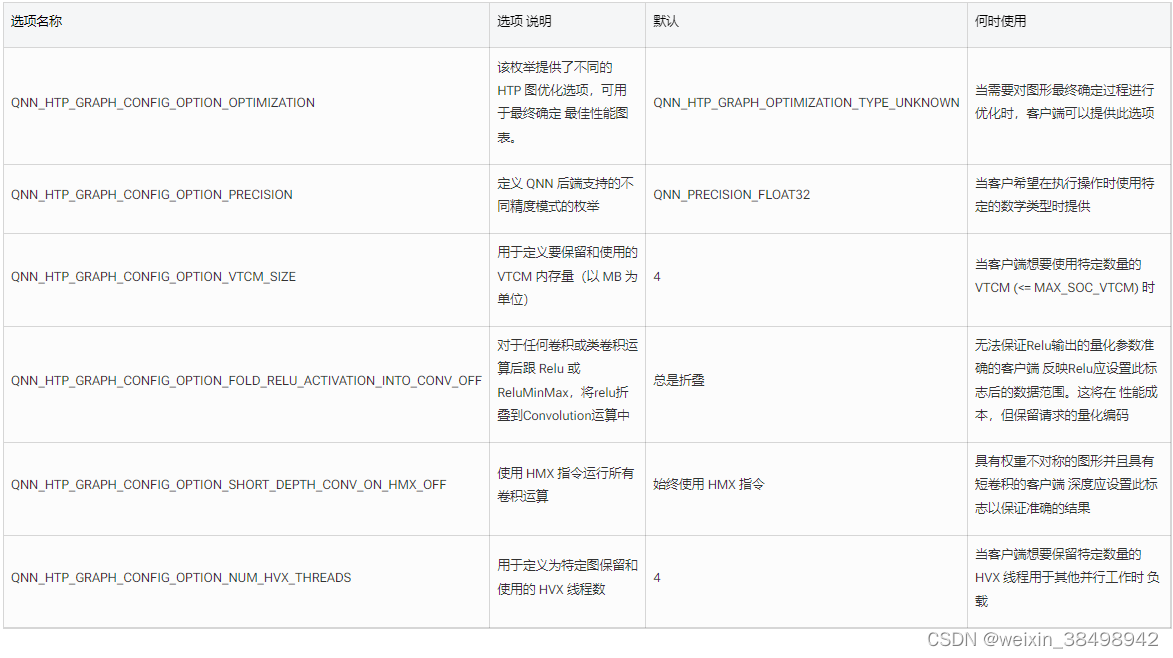
QNN_HTP_GRAPH_OPTIMIZATION_TYPE_FINALIZE_OPTIMIZATION_FLAG = 3 配置将考虑在内 QNN_HTP_DEVICE_CONFIG_OPTION_SOC 配置(如果可能)。当考虑SOC信息时 帐户,O3配置预计在大多数情况下提供更优化的图,但可能会导致 在某些情况下不太理想的图。此外,它可能会产生可能更大的上下文二进制大小,因此 图表加载时间可能会降低。
笔记
建议在以下部分之前参考 Hexagon SDK 文档,因为这很重要 此处描述的功能本质上使用 Hexagon SDK API。
如果用户同时指定 QNN_HTP_DEVICE_CONFIG_OPTION_SOC 和 QNN_HTP_DEVICE_CONFIG_OPTION_ARCH ,HTP后端驱动程序使用QNN_HTP_DEVICE_CONFIG_OPTION_SOC配置并忽略 QNN_HTP_DEVICE_CONFIG_OPTION_ARCH 配置。我们建议使用 QNN_HTP_DEVICE_CONFIG_OPTION_SOC 而不是 QNN_HTP_DEVICE_CONFIG_OPTION_ARCH。
版权归原作者 weixin_38498942 所有, 如有侵权,请联系我们删除。