

摘要是自然语言处理领域中最具挑战性和最有趣的问题之一。它是一个从多种文本资源(如书籍、新闻文章、博客文章、研究论文、电子邮件和tweet)中生成简洁而有意义的文本摘要的过程。现在,随着大量的文本文档的可用性,摘要是一个更加重要的任务。

那么有哪些不同的方法呢?
萃取总结
这些方法依赖于从一段文本中提取几个部分,比如短语和句子,然后将它们堆在一起创建摘要。因此,在提取方法中,识别出用于总结的正确句子是至关重要的。让我们通过一个例子来理解这一点。
Text: Messi and Ronaldo have better records than their counterparts. Performed exceptionally across all competitions. They are considered as the best in our generation.*
**Abstractive summary:**Messi and Ronaldo have better records than their counterparts. Best in our generation.
正如你在上面看到的,这些粗体的单词被提取出来并加入到一个摘要中——尽管有时这些摘要在语法上可能很奇怪。
摘要式的总结
这些方法使用先进的NLP技术产生一个全新的总结。本摘要的某些部分甚至可能不会出现在原文中。让我们通过一个例子来理解这一点。
**Text:**Messi and Ronaldo have better records than their counterparts. Performed exceptionally across all competitions. They are considered as the best in our generation.
**Abstractive summary:**Messi and Ronaldo have better records than their counterparts, so they are considered as the best in our generation.
摘要文本摘要算法创建新的短语和句子,从原始文本中传递最有用的信息——就像人类一样。
在本文中,我们将重点研究抽象摘要技术,并将利用编解码器架构来解决这一问题。
什么是编码器-解码器架构?
常用的序列-序列模型(编码器-解码器)的整体结构如下图所示
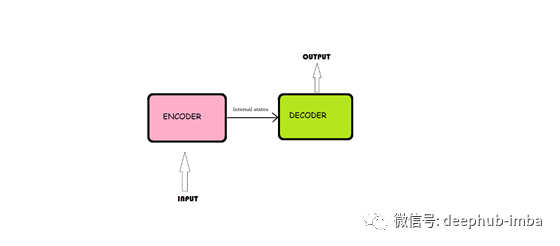
该模型由编码器、中间矢量和解码器三部分组成。
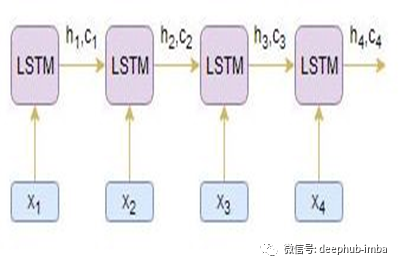
编码器
该编码器基本上由一系列LSTM/GRU单元组成(请查看LSTM/GRU文档以更好地理解架构)。编码器接受输入序列并将信息封装为内部状态向量。解码器使用编码器的输出和内部状态。在我们的文本摘要问题中,输入序列是文本中需要汇总的所有单词的集合。每个单词都表示为x_i,其中i是单词的顺序。
中间(编码器)向量
这是模型的编码器部分产生的最终隐藏状态。用上面的公式计算。这个向量旨在封装所有输入元素的信息,以帮助解码器做出准确的预测。它作为模型的解码器部分的初始隐藏状态。
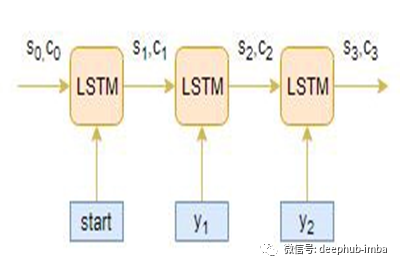
译码器
一种由几个循环单元组成的堆栈,其中每个单元在一个时间步长t预测输出y_t。每个循环单元从前一个单元接受一个隐藏状态,并产生和输出它自己的隐藏状态。在摘要问题中,输出序列是来自摘要文本的所有单词的集合。每个单词都表示为y_i,其中i是单词的顺序。任意隐藏状态h_i的计算公式为:
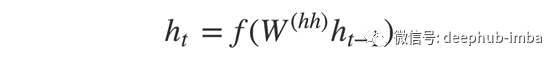
正如你所看到的,我们只是用前一个隐藏状态来计算下一个。
t时刻的输出y_t用公式计算:
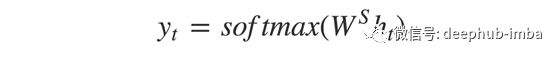
我们使用当前时间步长的隐藏状态和各自的权值W(S)来计算输出。Softmax用于创建一个概率向量,它将帮助我们确定最终的输出(例如回答问题中的单词)。
添加一些注意力
首先,我们需要了解什么是注意力。
为了在时间步长t生成一个单词,我们需要对输入序列中的每个单词给予多少关注?这就是注意力机制概念背后的关键直觉。
让我们用一个简单的例子来理解这一点:
Question: In the last decade, who is the best Footballer?
Answer: Lionel Messi is the best player.
在上面的例子中,问题中的第五个单词和梅西有关,第九个单词足球运动员和第六个单词球员有关。
因此,我们可以增加源序列中产生目标序列的特定部分的重要性,而不是查看源序列中的所有单词。这是注意力机制背后的基本思想。
根据被关注上下文向量的推导方式,有两种不同的注意机制:
Global Attention
在这里,注意力被放在所有的源位置上。换句话说,为了得到参与的上下文向量,我们考虑了编码器的所有隐藏状态。在这个总结任务中,我们将使用Global Attention。
Local Attention
在这里,注意力只放在几个源位置上。在推导参与上下文向量时,只考虑编码器的少数隐藏状态。
现在让我们了解这种注意力是如何真正起作用的:
编码器输出源序列中每个时间步长j的隐藏状态(hj)同样,解码器输出目标序列中每一个时间步长i的隐藏状态(si)我们计算一个称为对齐分数(eij)的分数,在这个分数的基础上,使用一个评分函数将源单词与目标单词对齐。利用score函数从源隐藏状态hj和目标隐藏状态si计算对齐得分。由:

其中eij为目标时间步长i和源时间步长j的对齐得分。
我们使用softmax函数对对齐分数进行归一化,以检索注意力权重(aij):
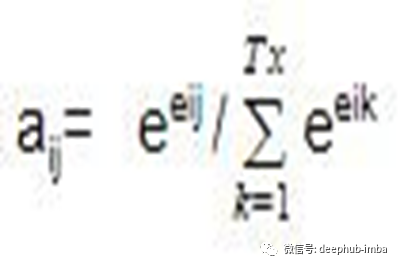
计算编码器hj的注意权值aij与隐藏状态的乘积的线性和,得到上下文向量Ci:
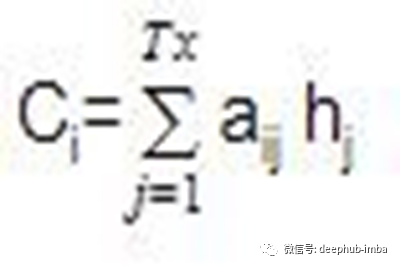
将所述解码器在时间步长i时的参与上下文向量与目标隐藏状态连接,生成参与隐藏向量Si,其中Si= concatenate([Si;Ci)然后将参与的隐藏向量Si送入稠密层产生yi, yi=dense(Si)。
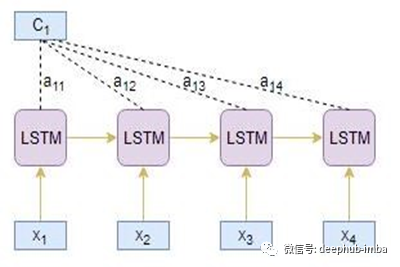
让我们通过一个示例来理解上面的注意机制步骤。假设源文本序列为[x1, x2, x3, x4],目标摘要序列为[y1, y2]。
编码器读取整个源序列并输出每个时间步长的隐藏状态,例如h1, h2, h3, h4
解码器读取由一个时间步长偏移的整个目标序列,并输出每个时间步长(例如s1、s2、s3)的隐藏状态
目标timestep i = 1
利用score函数从源隐藏状态hi和目标隐藏状态s1计算对齐得分e1j:
e11= score(s1, h1)
e12= score(s1, h2)
e13= score(s1, h3)
e14= score(s1, h4)
使用softmax对对齐分数e1j进行归一化,得到注意力权重a1j:
a11= exp(e11)/((exp(e11)+exp(e12)+exp(e13)+exp(e14))
a12= exp(e12)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
a13= exp(e13)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
a14= exp(e14)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
由编码器隐藏状态hj与对齐得分a1j的乘积的线性和得到上下文向量C1:
C1= h1 * a11 + h2 * a12 + h3 * a13 + h4 * a14
连接上下文向量C1和目标隐藏状态s1,生成隐藏向量s1
S1= concatenate([s1; C1])
然后将注意力隐藏向量S1输入到稠密层,产生y1
y1= dense(S1)
我们可以用同样的方法计算Y2。
实施
在本文中,我们将使用亚马逊食品评论数据集。让我们来看看数据:
https://www.kaggle.com/snap/amazon-fine-food-reviews

数据清洗
我们首先需要清理我们的数据,所以我们需要遵循的步骤是:
将所有内容转换为小写字母删除HTML标记收缩映射删除(的)删除括号()内的任何文本消除标点和特殊字符删除stopwords。删除短词
数据分布
然后,我们将分析评语和总结的长度,从而对文章的长度分布有一个总体的认识。这将帮助我们确定序列的最大长度。
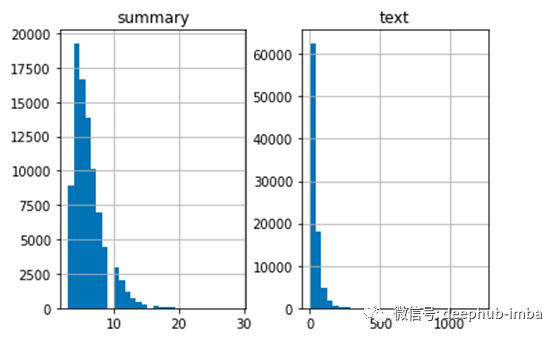
标记数据:
记号赋予器构建词汇表并将单词序列转换为整数序列。我们将使用Keras’ Tokenizer来标记句子。
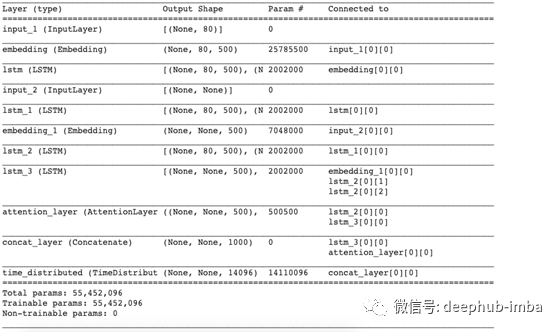
模型建立
我们终于到了模型制作部分。但在此之前,我们需要熟悉一些术语,这些术语在构建模型之前是必需的。
- Return Sequences= True:当参数设置为True时,LSTM为每个时间步长生成隐藏状态和单元格状态
- Return State = True:当Return State = True时,LSTM只生成最后一个时间步骤的隐藏状态和单元格状态
- Initial State:用于初始化第一个时间步骤的LSTM的内部状态
- Stacked LSTM:Stacked LSTM有多层的LSTM堆叠在彼此之上。这样可以更好地表示序列。我鼓励您试验堆叠在彼此之上的LSTM的多个层
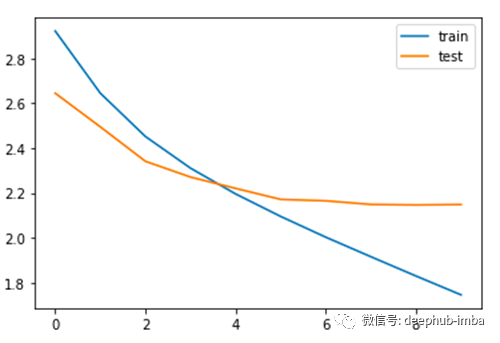
训练和Early Stopping:
这就是在训练过程中验证损失减少的原因,我们可以推断在 epoch10之后验证损失略有增加。因此,在这个 epoch之后,我们将停止训练模型。
推理
现在,我们将为编码器和解码器建立推断。在这里,编码器和解码器将一起工作,以产生摘要。所述解码器将堆叠在所述编码器之上,所述解码器的输出将再次馈入所述解码器以产生下一个字。
Review: right quantity japanese green tea able either drink one sitting save later tastes great sweet
Original summary: great japanese product
Predicted summary: great teaReview: love body wash smells nice works great feels great skin add fact subscribe save deal great value sold
Original summary: great product and value
Predicted summary: great productReview: look like picture include items pictured buy gift recipient disappointed
Original summary: very disappointed
Predicted summary: not what expected
总结
在本文中,我们了解了如何使用序列到序列模型总结文本。我们可以通过增加数据集、使用双向LSTM、 Beam Search策略等方法进一步改进该模型。
本文代码:https://gist.github.com/sayakmisra/6133be0554ce916d8cae4cdb83d475d8
作者:Sayak Misra
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********