
1、前言
精确的点云检测在很多三维场景的应用中都是十分重要的一环,比如家用机机器人、无人驾驶汽车等场景。然而高效且准确的点云检测在pointnet网络提出之前,一直没能取得很好的进展,因为传统的手工点云特征提取会造成信息不能被高效提取并且人为设计的特征无法满足点云检测场景下信息的不变性;造成了点云信息被利用的瓶颈。所以VoxelNet打破了这一限制,使得点云检测的框架从手工特征提取变成了端到端的机器自动学习所需的信息。
VoxelNet是一篇比较早的点云检测模型了,由苹果公司在2016年提出。它完成了点云的端到端的检测。直接使用PointNet网络作为点云特征提取器,完成对点云的特征提取,这也使得整个检测网络相比于之前的特征提取方式更加高效;提取的特征也具有更好的泛化性能;使得该模型在当时的KITTI点云检测中也取得了SOTA的成绩。
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection:
https://arxiv.org/abs/1711.06396https://arxiv.org/abs/1711.06396
pytorch非官方实现仓库:(本文代码没有开源)
跳转中...https://link.zhihu.com/?target=https%3A//github.com/skyhehe123/VoxelNet-pytorch
VoxelNet在使用pointnet解决了点云无序化数据结构的提取问题之后;就使用了VoxelNet中的Voxel,顾名思义就是将三维世界中每一定空间大小划分成一个格子,然后使用pointnet网络对这个小格子的数据进行特征提取;并用这个提取出来的特征来代表这个小格子,并放回到3D的空间中。这样无序的点云数据就变成了一个个的高维特征数据并且这些数据在三维空间中也变得有序了,之后就可以使用三维卷积来抽取这些三维的voxel数据了,那么图像检测的思路就可以应用在这个特征图上面了。
下图展了Voxel和点云的关系(图来自github:KITTI_VIZ_3D)
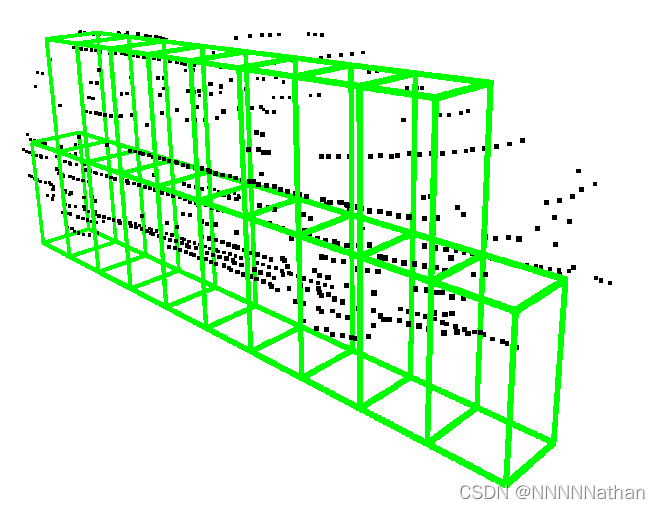
voxel和点云的关系图
其中上图中绿色的立方体可以看成是空间中的一个一个voxel,黑色的点可以看成是激光雷达的生成的点云数据,每个点云落到某个voxel内,则该点就被划分到这个voxel。
2、VoxelNet网络模块解析
VoxelNet网络整体架构(图来自原论文)
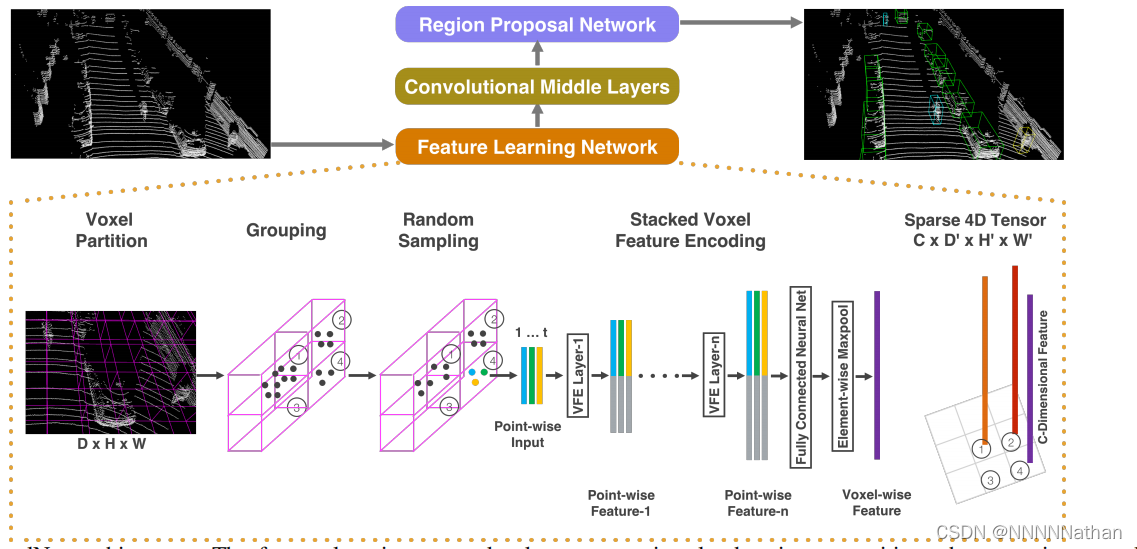
整体网络分成三个模块,分别是Feature Learning Network、Convolutional middle layers、Region proposal network。接下来分别介绍这三个模块的实现。
2.1、特征学习网络
2.1.1、Voxel 划分(分配每个voxel到3D空间中对应位置)
** ** 在一个给定的点云空间中,需要将整个三维空间变成由一个个的大小相等小方块组成,可以想象我的世界中用土块填满一处3D空间的无聊操作。假设一个三维空间的长宽高分别为X、Y、Z(此处以kitti雷达坐标系为准,X向前,Y向左,Z向上),每个voxel的大小分别为长Vx,宽Vy,高Vz;那么整个三维空间就可以划分成X上有X/Vx个voxel,Y上有Y/Vy个voxel,Z上有Z/Vz个voxel。这里假设,X、Y、Z是Vx、Vy、Vz的倍数。
参数注释:论文中X,Y,Z分别是0 — 70.4;-40 — 40;-3 — 1,Vx,Vy,Vz分别是0.4,0.2,0.2。单位均为米。超出X, Y, Z范围外的点直接裁剪掉,因为点云空间中远处的物体产生的点太过于稀疏,不能保证识别结果的可靠性
2.1.2、Grouping(将每个点分配给对应的Voxel)和Sampling(voxel中点云的采样)
** **在把3D空间voxel化后,就需要将3D空间中所有的点云分配到他们所属的voxel中了。由于激光雷达本身的特性和在捕获反射回来的光束时,会受到距离、物体遮挡、物体之间的相对姿态和不均匀采样的影响。导致产生的点云数据在整个三维空间中是十分稀疏并且不均匀的;可以看上图voxel和点云的关系图,每个voxel中点的数量都不一样,甚至大部分的voxel中都是没有点存在的。
同时,一个高精度的激光雷达点云会包含10万以上的点,如果直接对所有的这些点进行处理的话会导致:1、会产生极大的计算和内存消耗,2、还会让模型不能很好的学习,因为点的密度之间的差距太大,可能会导致检测偏差。因此在**Grouping**操作之后,需要对每个非空的voxel中随机采样T个点。(***不足补0***,超出的仅采样T个点)。
经过**Grouping **后就可以将数据表示为(N,T,C),其中N为非空的voxel了的个数,T为每个voxel中点个个数,C表示点的特征。计算出输入的tensor数据的shape是(N,35,7)。
参数注释:论文中T为35。Z'=Z/Vz,X'=X/Vx, Y'=Y/Vx分别等于10,352,400,Z', X', Y'表示每个轴上面有多少个voxel。
2.1.3、VFE堆叠(Stacked Voxel Feature Encoding)
** ** VoexelNet中最关键的部分就是将经过voxel后经过特征提取变成规则化数据的部分,因为之前就已经有许多的工作将经过voxel的数据经过编码之后拿来使用,包括将每个非空的voxel编码成6维的统计向量,这些统计量都来源于voxel内部的点;或者将统计量再融合上voxel所在的局部信息,又或者使用二值编码的方式来编码么个voxel等等操作。然而都没能达到很好的效果。
其中论文中的这幅图很好的表述了VoexelNet是如何完成对voxel的特征进行编码的
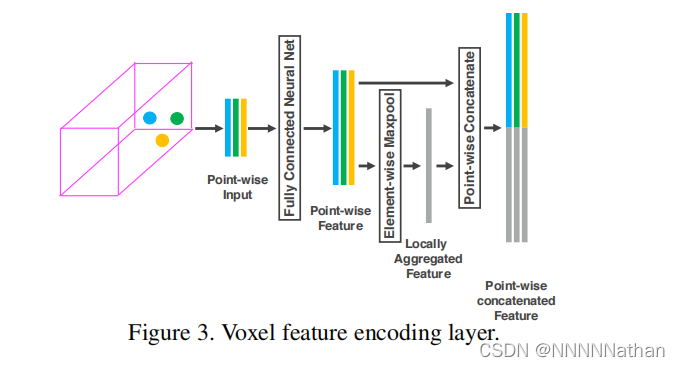
每一个非空的Voxel都是一个点集,定义为 **V **= *{***p***i *= [*x**i **, y**i **, z**i **, r**i*]*T **∈ *R^4*}**i*=1*...t ; *其中t小于等于35。**p**i 代表了点云数据中的第i个点;xi , yi , zi分别是该点在3D空间中的X,Y,Z坐标,ri表示了光线反射到雷达的强度(与距离、入射角度、物体材质等有关,数值在0-1之间)。
首先,先对voxel中的每个点进行数据增强操作,先计算出每个voxel的所有点的平均值,计为(V_Cx,V_Cy,V_Cz),然后将每个点的xi,yi,zi减去对应轴上的平均值,得到每个点到自身voxel中心的偏移量(xi_offset,yi_offset,zi_offset)。再将得到的偏移数据和原始的数据拼接在一起得到网络的输入数据**V **= *{***p***i *= [*x**i **, y**i **, z**i **, ri, *xi_offset,yi_offset,zi_offset]*T **∈ *R^7*}**i*=1*...t。*
接着就是用PointNet提出的方法,将每个voxel中的点通过全连接层转化到高维空间(每个全连接层包含了FC, RELU, BN)。维度也从(N,35,7)变成了(N,35,C1)。然后在这个特征中,取出特征值最大的点(Element-wise Maxpool)得到一个voxel的聚合特征(Locally Aggreated Feature),可以用这个聚合特征来编码这个voxel包含的表面形状信息。这也是PointNet中所提到的。获得每个voxel的聚合特征后,再用该特征来加强经过FC后的高维特征;将聚合特征拼接到每一个高维点云特征中(Point-wise Concatenate);得到(N,35,2*C1)。作者把上述的这个特征提取的模块称之为VFE(Voxel Feature Encoding),这样每个VFE模块都只仅仅包含了一个(C_in,C_out/2)的参数矩阵。每个voxel经过VFE输出的特征都包含了voxel内每个点的高维特征和经过聚合的局部特征,那么只需要堆叠VFE模块就可以实现voxel中每个点的信息和局部聚合点信息的交互,使得最终得到的特征能够描述这个voxel的形状信息。
接下来就是要堆叠这个VFE模块得到完整的Stacked Voxel Feature Encoding。
下图是完整的Stacked Voxel Feature Encoding流程
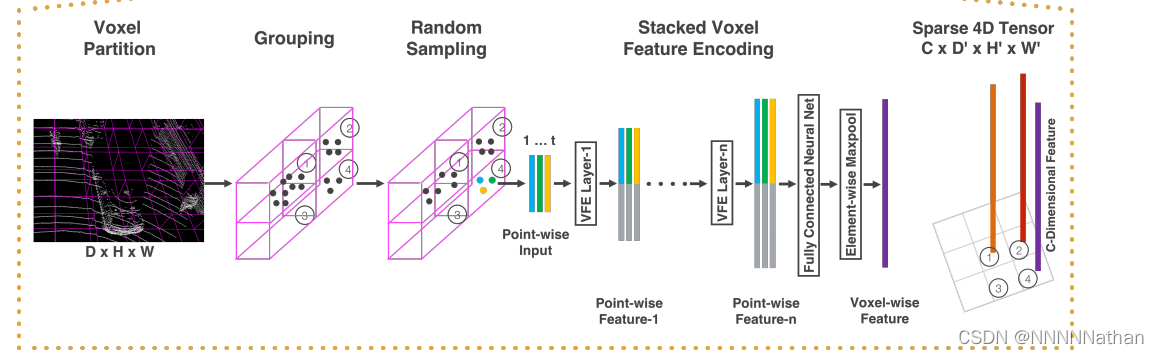
注:每个VFE模块中FC的参数共享的。原论文的实现中一共堆叠了两个VFE模块,其中第一个VFE模块将维度从输入的7维度升高到了32,第二个VFE模块将数据的维度从32升高到了128。
经过**Stacked Voxel Feature Encoding**后,可以得到一个(N,35,128)的特征,然后为了得到这个voxel的最终特征表达。需要对这个特征再进行一个FC操作来融合之前点特征和聚合特征,这个FC操作的输入输出保持不变。即得到的tensor还是(N,35,128),之后进行Element-wise Maxpool来提取每个voxel中最具体代表性的点,并用这个点来代表这个voxel,即(N,35,128)--> (N,1,128)
2.1.4、****Sparse Tensor Representation(特征提取后稀疏特征的表示)
在前面的**Stacked Voxel Feature Encoding **的处理中,都是对非空的voxel进行处理,这些voxel仅仅对应3D空间中很小的一部分空间。这里需要将得到的N个非空的voxel特征重新映射回来源的3D空间中,表示成一个稀疏的4D张量,(C,Z',Y',X')--> (128, 10, 400, 352)。这种稀疏的表示方法极大的减少了内存消耗和反向传播中的计算消耗。同时也是VoxelNet为了效率而实现的重要步骤。
2.1.5、高效实现(voxel补0)
前面我写的voxel采样中,如果一个voxel中没有T个点,就直接补0直到点的数量达到35个,如果超出35个点就随机采样35个点。但是在原论文中的具体实现如下。
原作者为Stacked Voxel Feature Encoding的处理设计了一个高效实现,如下图。
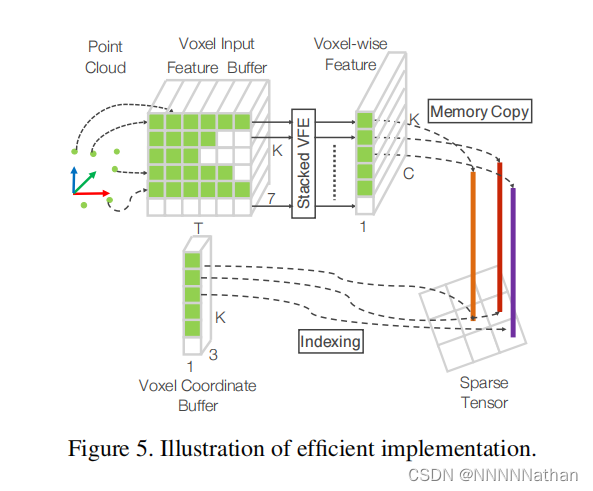
由于每个voxel中包含的点的个数都是不一样的,所以这里作者将点云数据转换成了一种密集的数据结构,使得后面的**Stacked Voxel Feature Encoding**可以在所有的点和voxel的特征上平行处理。
1、首先创建一个KT7的tensor(voxel input feature buffer)用来存储每个点或者中间的voxel特征数据,其中K是最大的非空voxel数量,T是每个voxel中最大的点数,7是每个点的编码特征。所有的点都是被随机处理的。
2、遍历整个点云数据,如果一个点对应的voxel在voxel coordinate buffer中,并且与之对应的voxel input feature buffer中点的数量少于T,直接将这个点插入Voxel Input Feature Buffer中;否则直接抛弃这个点。如果一个点对应的voxel不在voxel coordinate buffer,需要在voxel coordinate buffer中直接使用这个voxel的坐标初始化这个voxel,并存储这个点到Voxel Input Feature Buffer中。这整个操作都是用哈希表完成,因此时间复杂度都是O(1)。整个Voxel Input Feature Buffer和voxel coordinate buffer的创建只需要遍历一次点云数据就可以,时间复杂度只有O(N),同时为了进一步提高内存和计算资源,对voxel中点的数量少于m数量的voxel直接忽略改voxel的创建。
3、再创建完Voxel Input Feature Buffer和voxel coordinate buffer后Stacked Voxel Feature Encoding就可以直接在点的基础上或者voxel的基础上进行平行计算。再经过VFE模块的concat操作后,就将之前为空的点的特征置0,保证了voxel的特征和点的特征的一致性。最后,使用存储在voxel coordinate buffer的内容恢复出稀疏的4D张量数据,完成后续的中间特征提取和RPN层。
2.2、中间卷积层(Convolutional middle layers)
在经过了**Stacked Voxel Feature Encoding**层的特征提取和稀疏张量的表示之后,就可以使用3维卷积来进行整体之间的特征提取了,因为在前的每个VFE中提取反应了每个voxel的信息,这里使用3维卷积来聚合voxel之间的局部关系,扩大感受野获取更丰富的形状信息,给后续的RPN层来预测结果。
三维卷积可以用Conv*M*D(*c**in**, c**out**, ***k***, ***s***, ***p**)来表示,cin和cout是输入和输出的通道数,k表示三维卷积的kernel大小,s表示步长,p表示padding参数。每个三维卷积后都接一个BN层和一个Relu激活函数。
注:原文中在Convolutional middle layers中分别使用了三个三维卷积,卷积设置分别为
Conv3D(128, 64, 3, (2,1,1), (1,1,1)),
Conv3D(64, 64, 3, (1,1,1), (0,1,1)),
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
最终得到的tensor shape是(64,2,400,352)。其中64为通道数。
经过Convolutional middle layers后,需要将数据整理成RPN网络需要的特整体,直接将Convolutional middle layers得到的tensor 在高度上进行reshape 变成(64 * 2,400,352)。那么每个维度就变成了 C、Y、X。**这样操作的原因是因为KITTI等数据集的检测任务中,物体没有在3D空间中的高度方向进行堆叠,没有出现一个车在另一个车的上方这种情况。同时这样也大大减少了网络后期RPN层设计难度和后期anchor的数量。**
2.3、Region proposal network
2.3.1、RPN层设计
RPN层的概念在FasterRCNN中就被提出来了,主要是用于根据特征图中学习到的特征和结合anchor来生成对应的预测结果。但是VoxelNet的预测头,我觉得更像SSD和YOLO那一类的目标检测算法种的头预测。在FrCNN中RPN在每个像素和像素的中心点位置根据anchor的设置,预测了一个anchor属于类别,和针对该anchor的粗回归调整。在VoxelNet中也不例外。
下图是VoxelNet中RPN的详细结构(图来自原论文)
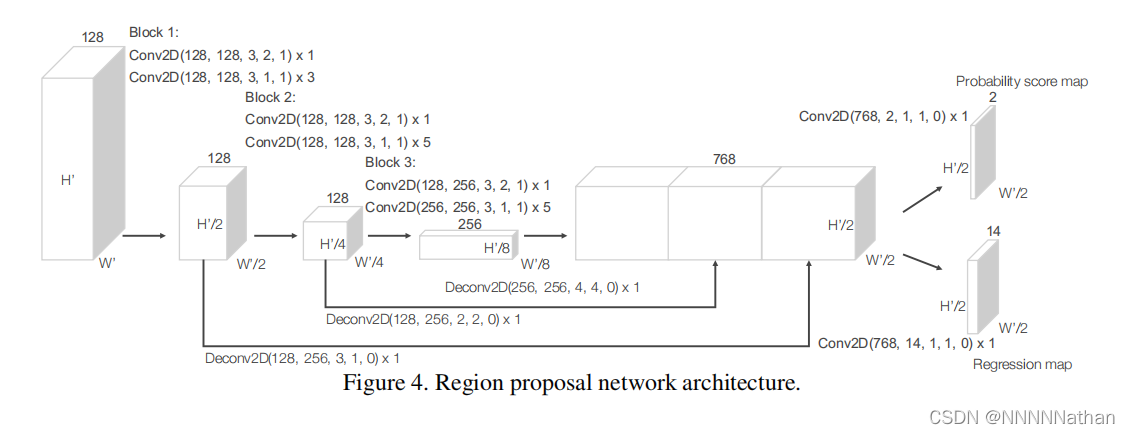
VoxelNet的RPN结构在经过前面的Convolutional middle layers和tensor重组得到的特征图后,对这个特征图分别的进行了多次下采样,然后再将不同下采样的特征进行反卷积操作,变成相同大小的特征图。再拼接这些来自不同尺度的特征图,用于最后的检测。给人的感觉有点像图像目标检测的NECK模块中PAN。只不过这里只有一张特征图。将不同尺度的信息融合在了一起。这里每一层卷积都是二维的卷积操作,每个卷积后面都接一个BN和RELU层。详细的卷积核参数设置也都在图片中了。
最终的输出结果是一个分类预测结果和anchor回归预测结果。
2.3.2、anchor的参数设计
在VoxelNet中,只使用了一个anchor的尺度,不像FrCNN中的9个anchor。其中anchor的长宽高分别是3.9m、1.6m、1.56m。同时与FrCNN中不同的是,真是的三维世界中,每个物体都是有朝向信息的。所以VoxelNet为每个anchor加入了两个朝向信息,分别是0度和90度(激光雷达坐标系)。
注:由于在原论文中作者分别为车、行人、自行车设计了不同的anchor尺度,并且行人和自行车有自己单独的网络结构(仅仅在Convolutional middle layers的设置上有区别)。为了方便解析,这里仅以车的网络设计作为参考。
3 损失函数
1、正负样本匹规则:
每个类别的先验证只有一种尺度信息;分别是车 [3.9, 1.6, 1.56],anchor的中心在-1米、人[0.8, 0.6, 1.73],anchor的中心在-0.6米、自行车[1.76, 0.6, 1.73],anchor的中心在-0.6米(单位:米)。
在anchor匹配GT的过程中,使用的是2D IOU匹配方式,直接从生成的特征图也就是BEV视角进行匹配;不需要考虑高度信息。原因有二:1、因为在kitti数据集中所有的物体都是在三维空间的同一个平面中的,没有车在车上面的一个情况。 2、所有类别物体之间的高度差别不是很大,直接使用SmoothL1回归就可以得到很好的结果。 其次是每个anchor被设置为正负样本的iou阈值是:
车匹配iou阈值大于等于0.6为正样本,小于0.45为负样本,中间的不计算损失。
人匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
自行车匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
2、损失函数详情:
在一个3D的数据的标注中,包含了7个参数(x, y ,z, l, w, h, θ),其中xyz代表了一个物体的中心点在雷达坐标系中的位置。lwh代表了这个物体的长宽高。θ代表了这个物体绕Z轴旋转角度(偏航角)。因此生成的anchor也包含对应的7个参数(xa, ya ,za, la, wa, ha, θa),其中xa, ya ,za表示这个anchor在雷达坐标系中的位置。 la, wa, ha反应了这个anchor的长宽高。θa表示这个anchor的角度。
因此编码每个anchor和GT的损失函数时,公式如下: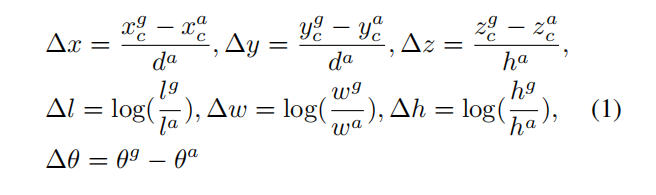
其中d^a表示一个anchor的底面对角线长度: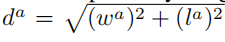
上面直接定义了每个anchor回归的7个参数;但是总的损失函数还包含了对每个anchor的分类预测,因此总的损失函数定义如下:
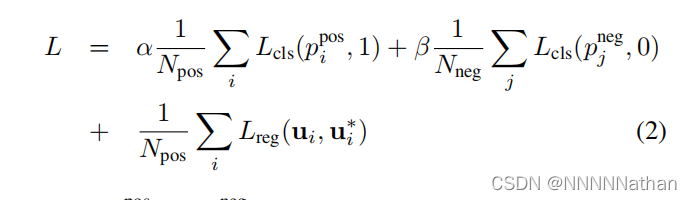
其中pi^pos表示经过softmax函数后该anchor为正样本,pj^neg表示经过softmax函数后该anchor为负样本。ui和ui*仅仅需要对正样本anchor回归计算loss。同时背景分类和类别分类都采用了BCE损失函数;1/Npos和1/Nneg用来normalize各项的分类损失。α, β为两个平衡系数,在论文中分别是1.5和1。最后的回归损失采用了SmoothL1函数。
4、点云的数据增强
1、由于点云的标注数据中,一个GTbox已经标注出来这个box中有哪些点,所以可以同时移动或者旋转这些点来创造大量的变化数据;在移动这些点后需要进行以下碰撞检测,删粗掉经过变换后这个GTbox和其它的GTbox混在一起的,不可能出现在现实中出现的情况。
2、对所有的GTbox进行放大或者缩小,放大或者缩小的尺度在 [ 0.95, 1.05]之间;引入缩放,可以使得网络在检测不同大小的物体上有更好的泛化性能,这一点在图像中很常见。
3、对所有的GTbox进行随机的进行旋转操作,角度在从[ -45, 45]均匀分布中抽取,旋转物体的偏航角可以模仿物体在现实中转了个弯的情况。
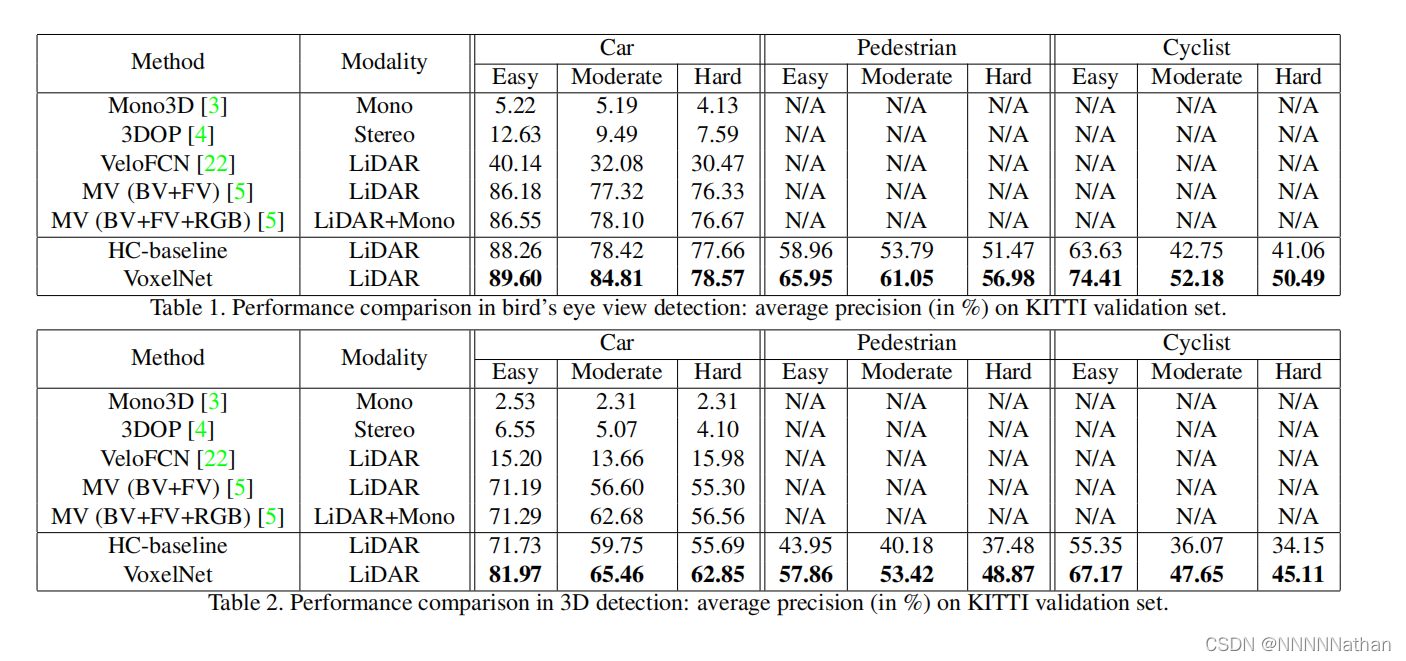
5、结果

** 详细的代码实现和网络构建与SECOND和PointPillars大同小异,可以参考我的PointPillars详解**PointPillars论文解析和OpenPCDet代码解析_NNNNNathan的博客-CSDN博客_pointpillars代码PointPillars是一个来自工业界的模型,整体思想基于图片的处理框架,直接将点云划分为一个个的Pillar,从而构成了伪图片的数据。速度和精度都达到了一个很好的平衡本文将会以OpenPCDet为代码基础,详细解析PointPillars的代码实现流程...https://blog.csdn.net/qq_41366026/article/details/123006401?spm=1001.2014.3001.5502
参考文章或文献:
1、https://www.mdpi.com/1424-8220/18/10/3337
2、【3D物体检测】VoxelNet论文和代码解析 - 知乎
3、https://arxiv.org/abs/1711.06396
4、https://arxiv.org/abs/1612.00593
5、https://arxiv.org/abs/1706.02413
6、https://github.com/skyhehe123/VoxelNet-pytorch
7、https://github.com/open-mmlab/OpenPCDet
8、https://arxiv.org/abs/1812.05784
9、【3D目标检测】PointPillars论文和代码解析 - 知乎
10、【3D视觉】PointNet和PointNet++ - 知乎
11、https://github.com/jjw-DL/OpenPCDet-Noted
12、https://arxiv.org/abs/1506.01497
13、https://arxiv.org/pdf/1803.01534.pdf
14、The KITTI Vision Benchmark Suite
版权归原作者 NNNNNathan 所有, 如有侵权,请联系我们删除。