
目标检测方法常常使用先验框提高预测性能,一张图像可能生成成千上万的先验框,但是其中只有很少一部分能匹配到目标(正样本),而没有匹配到目标的先验框占大多数。这种情况造成了One-Stage目标检测方法的正负样本不平衡。
如下图所示,红色的先验框都没有匹配到目标,所以它们都属于负样本,只是图中间的黄色先验框匹配到目标,所以它们是正样本。显然,这里的正负样本严重失衡。

而对于two stage模型,比如Faster R-CNN这种two stage模型,第一阶段的RPN可以过滤掉很大一部分负样本,最终第二阶段的检测模块只需要处理少量的候选框,而且检测模块还采用正负样本固定比例抽样(比如1:3),所以可以在一定程度上解决正负样本不均衡的情况(其实two-stage模型也存在正负样本不均衡的情况,但是相对于one-stage模型来说,不均衡情况每那么严重)。
正因为正负样本的不均衡情况,使得One-Stage目标检测方法的检测效果比不上Two-Stage目标检测方法。
与此同时,在那些大量未匹配到目标的负样本中,大部分都是简单易分的负样本,这些简单的负样本对网络训练起不到太大的作用,但是由于数量太多,会淹没掉少量但有助于训练的样本。
比如假如一张图片上有10个正样本,每个正样本的损失值是3,那么这些正样本的总损失是10x3=30。而假如该图片上有10000个简单易分负样本,尽管每个负样本的损失值很小,假设是0.1,那么这些简单易分负样本的总损失是10000x0.1=1000,那么损失值要远远高于正样本的损失值。所以如果在训练的过程中使用全部的正负样本,那么它的训练效果会很差。而Focal Loss是一种新的用于平衡One-Stage目标检测方法正负样本的Loss方案。Focal Loss从另外的视角来解决样本不平衡问题,那就是根据置信度动态调整交叉熵loss,当预测正确的置信度增加时,loss的权重系数会逐渐衰减至0,这样模型训练的loss更关注难例,而大量容易的例子其loss贡献很低。
下面我们来逐步分析一下Focal Loss:
下面公式是二分类交叉熵损失函数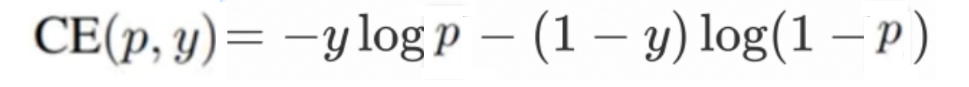
其中,y是样本的标签值,而p是模型预测某一个样本为正样本的概率,对于真实标签为正样本的样本,它的概率p越大说明模型预测的越准确,对于真实标签为负样本的样本,它的概率p越小说明模型预测的越准确,
对于上面的二分类交叉熵损失函数来说,如果将它展开,可以写成下面的公式一的形式: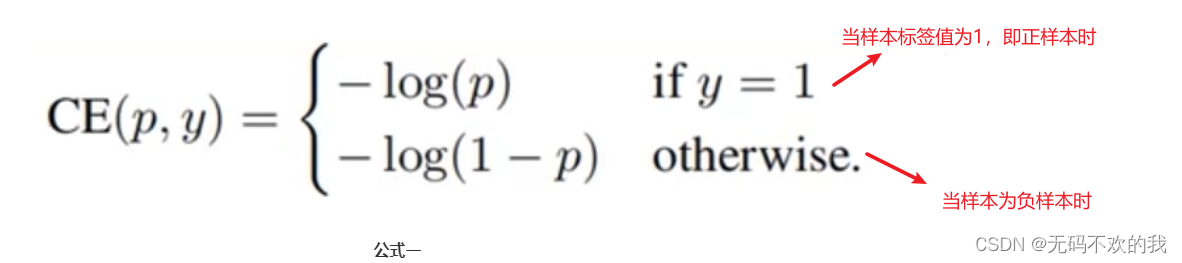
注意:这里的log(x)其实就是ln(x)
如果我们定义
p
t
p_t
pt为如下形式:
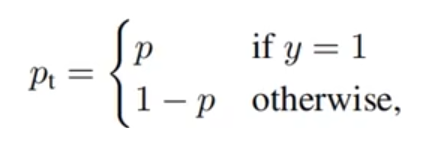
那么公式一可以表示成下面的公式二: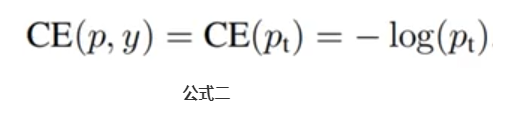

那么公式二变成了下面的公式三:
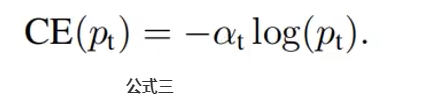
又因为样本有难易之分,所以我们必须要能区分出困难样本和简单样本,所以我们设置一个系数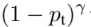
它可以降低简单样本的损失贡献,而使得训练时更重视一些困难样本。
此时公式二变成了下面的公式四:
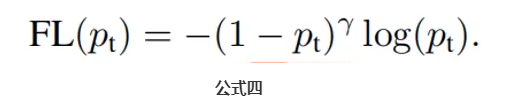
这里的
γ
\gamma
γ通常设置为2,例如预测正样本概率是0.95(即对于一个真实标签为正样本的样本,使用模型预测它也是正样本的概率是0.95),这显然是一个简单的样本,则该样本的难易权是
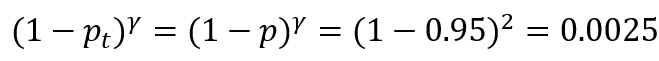
如果预测正样本概率是0.5 ,这显然是一个稍微困难一定的样本,则该样本的难易权值是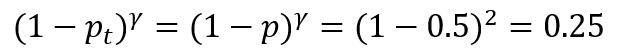
如果预测负样本的概率为0.9(即对于一个真实标签为负样本的样本,使用模型预测它是正样本的概率是0.9),这显然是一个困难的样本,则该样本的难易权重是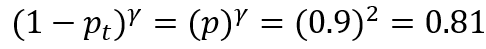
如果预测负样本的概率为0.1(即对于一个真实标签为负样本的样本,使用模型预测它是正样本的概率是0.1),这显然是一个简单的样本,则该样本的难易权重是
结合公式三和公式四,我们得到了Focal Loss损失函数,如下面公式五所示: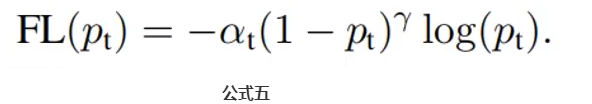
将公式五展开,Focal Loss损失函数可以写成如下公式六的形式: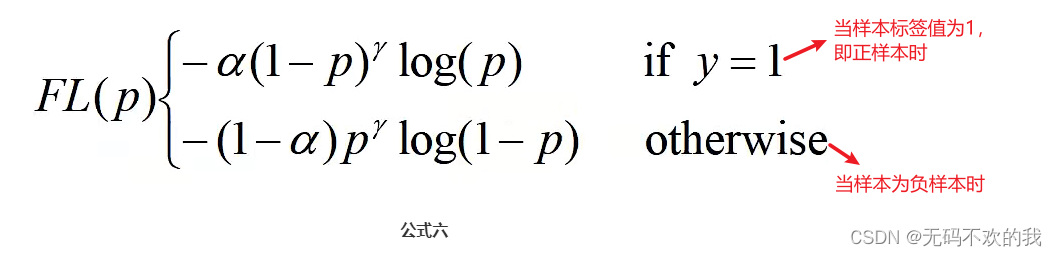
如果将公式六进一步展开,可得到最终的Focal Loss损失函数:
注意:Focal Loss损失函数容易受到噪声的干扰。也就是说训练集中标注的信息尽量不要出现错误的情况,否则Focal Loss损失函数就会针对那些标注错误的样本进行重点学习,使得模型的训练效果越来越差。因为根据Focal Loss损失函数的原理,它会重点关注困难样本,而此时如果我们将某个样本标注错误,那么该样本对于网络来说就是一个"困难样本",所以Focal Loss损失函数就会重点学习这些"困难样本",导致模型训练效果越来越差
下面我们将二分类交叉熵损失函数和Focal loss损失函数做一个对比。分别使用困难样本和简单样本来计算它们的两种损失值,由下表可知,显然Focal Loss损失函数可以明显的区分出简单样本和困难样本,对于简单样本,它所对应的Focal Loss损失值就会很小。对于困难样本,它所对应的Focal Loss损失值就会很大。并且根据二分类交叉熵损失函数和Focal loss损失函数的比值可知,对于困难样本来说,使用这两种损失函数计算的损失值相差不大,但是对于简单样本来说,使用这两种损失函数计算的损失值相差巨大,这也进一步证明了Focal loss损失函数要比二分类交叉熵损失函数更能区分出简单样本和困难样本。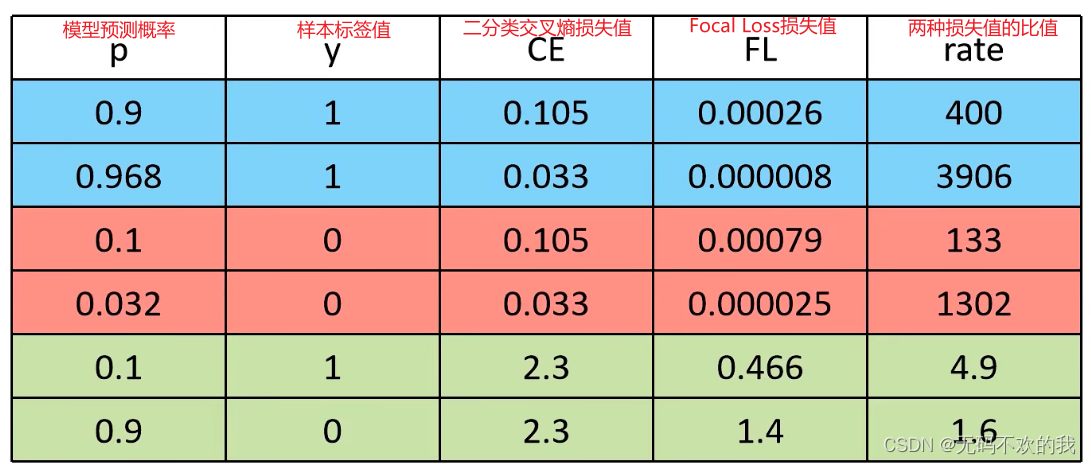
版权归原作者 无码不欢的我 所有, 如有侵权,请联系我们删除。