
一、 简介
与其他的深度学习方法在人脸上的应用不同,FaceNet并没有用传统的softmax的方式去进行分类学习,然后抽取其中某一层作为特征,而是直接进行端对端学习一个从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。
FaceNet主要有两个重点:Backbone和Triplet loss。我们也将主要从这两个方面介绍。
代码:oaifaye/facenet-swim-transformer
二、Swin Transformer作为Backbone
FaceNet论文使用了两个Backbone:Zeiler&Fergus架构和Google的Inception v1。随之时代的发展,已经不会有人再使用这两个模型了,基本所有优秀的模型都可以作为FaceNet的Backbone,想大Inception+ResNet足够了,想小MobileNet很优秀。这些模型都很棒,于是我们今天使用Swin Transformer。
目前Transformer应用到图像领域主要有两大挑战:
1.目标尺寸多变。不像NLP任务中token大小基本相同,目标检测中的目标尺寸不一,用单层级的模型很难有好的效果。
2.图片的高分辨率。高分辨率会使得计算复杂度呈现输入图片大小的二次方增长,这显然是不能接受的。
顾名思义,Hierarchical(多层级)解决第一个问题;Shifted Windows(滑窗)解决第二个问题。
1.Swin Transformer整体结构
先看模型整体结构,论文中的结构图跟代码有削微的差别,我以代码为准重画了结构图。因为原版FaceNet的输入是160x160,输出是128x128,所以我将输入改为了160x160,输出层加了全连接层将768映射成128.
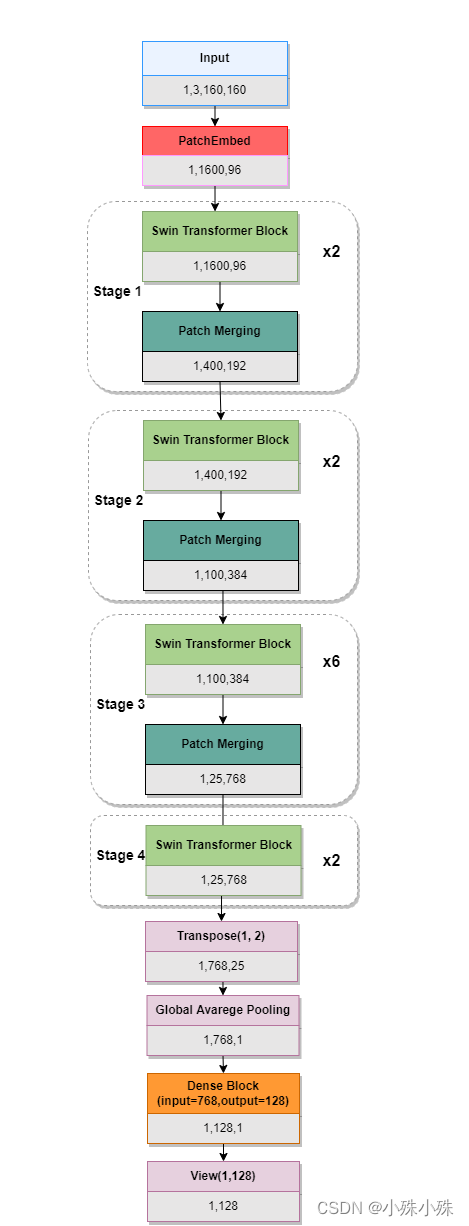
图1
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
2.PatchEmbed = Patch Partition + Linear Embedding
PatchEmbed包含了两个功能:Patch Partition 和 Linear Embedding,Patch Partition负责将图片切成Patch; Linear Embedding负责对Patch做Embedding。结构图如下:

上面的96代表Embedding的维度,我们使用默认值96,代码及中文注释如下:
class PatchEmbed(nn.Module):
r""" 将图片分割成不重叠的小patch,并做Embedding,尺寸下采样尺寸为patch_size的大小。
Args:
img_size (int): 输入图像大小. 默认: 224.我们使用160
patch_size (int): Patch token 的大小,默认为 4*4.
in_chans (int): 输入图像的通道数,默认为 3.
embed_dim (int): 线性 projection 输出的通道数,默认为 96.
norm_layer (nn.Module, optional): 归一化层, 默认为N None.
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
x = x.flatten(2)
x = x.transpose(1, 2) # 结构为 [B, num_patches=patche_h*patche_w, C]
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
3.Swin Transformer Block
重点来了,先看Swin Transformer Block结构图:
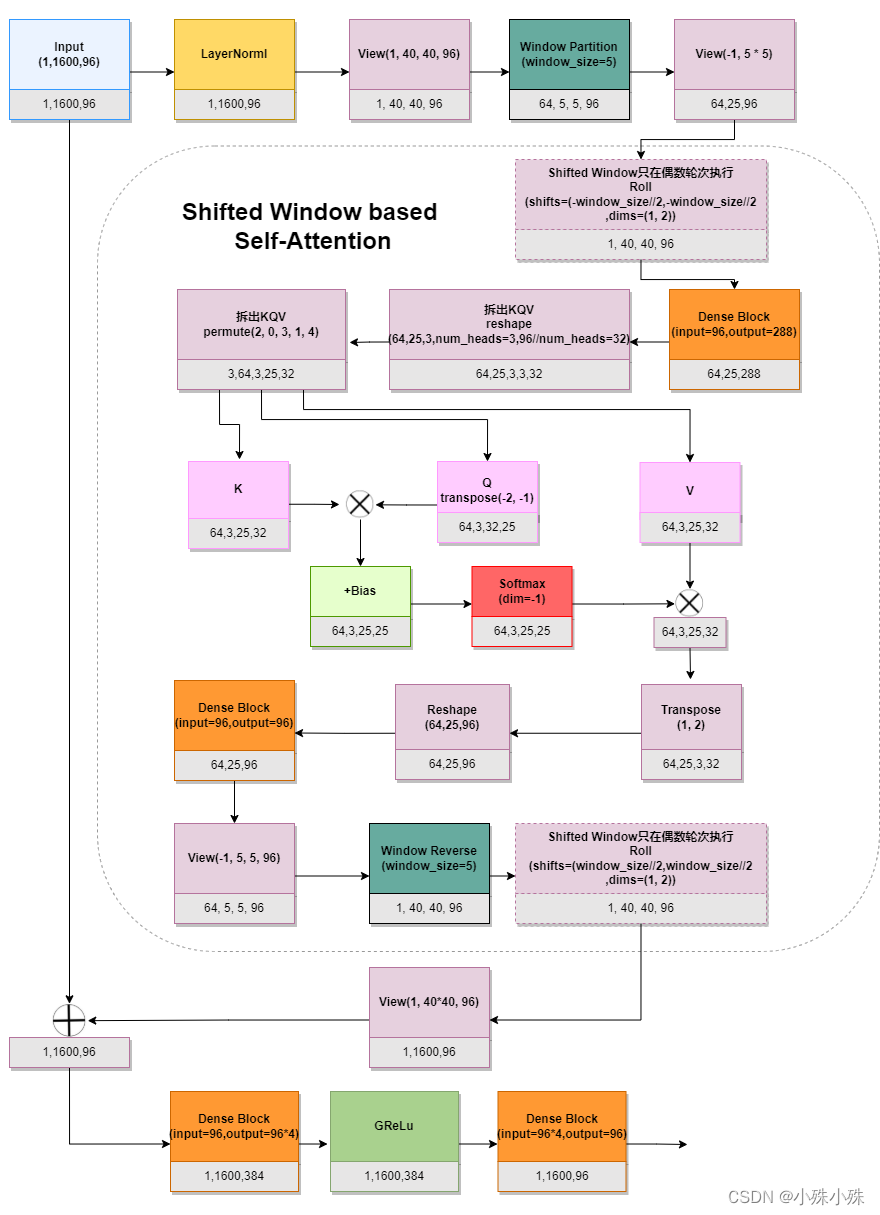
图2
图1中可以看到Stage1、2、4都有两个Swin Transformer Block,Stage3有6个Swin Transformer Block。我们以Stage1为例,输入和输出是一样的,都是1,1600,96。这块的重点两个个部分:
(1)Window Partition
根据window_size分窗,这里window_size=5,那们40x40的一个featuremap就能分成8个window,有点类似于YOLYv5中的focus结构,示意图如下:

相关代码**:**
def window_partition(x, window_size):
"""将输入分割为多个不重叠窗口
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
(2)Shifted Window based Self-Attention
图2中的Attention模块是在每个窗口下计算注意力的,大大减少了计算量,但是也带来了一个问题:每个窗口建的联系是薄弱的, 为了更好的促进window间进行信息交互,Swin Transformer引入了shifted window操作。偶数轮次执行Shifted Window,如下图:
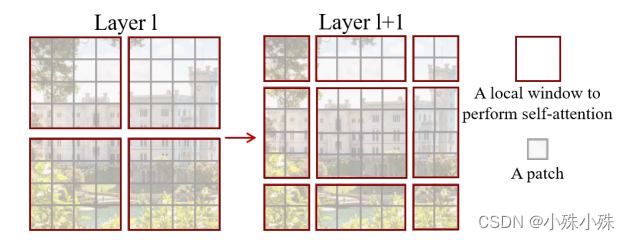
左边是没有重叠的Window Attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
为了在保持非重叠窗口的高效计算的同时引入跨窗口连接,我们提出了一种移动窗口分区方法,在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。示意图如下:
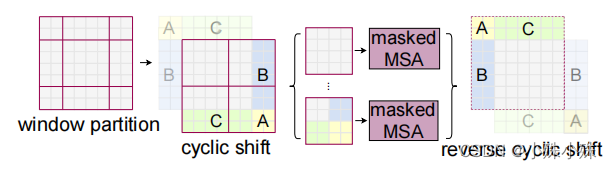
具体实现是通过
torch.roll
来实现的,
torch.roll的用法大概是
下面这样: 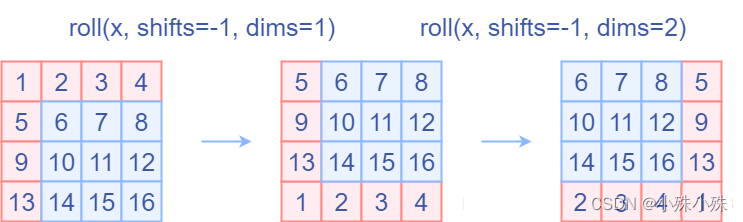 在Attention中通过设置mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=1)
在Attention中通过设置mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=1)

我们希望在计算Attention的时候,**让具有相同index QK进行计算,而忽略不同index QK计算结果**。最后正确的结果如下图所示:
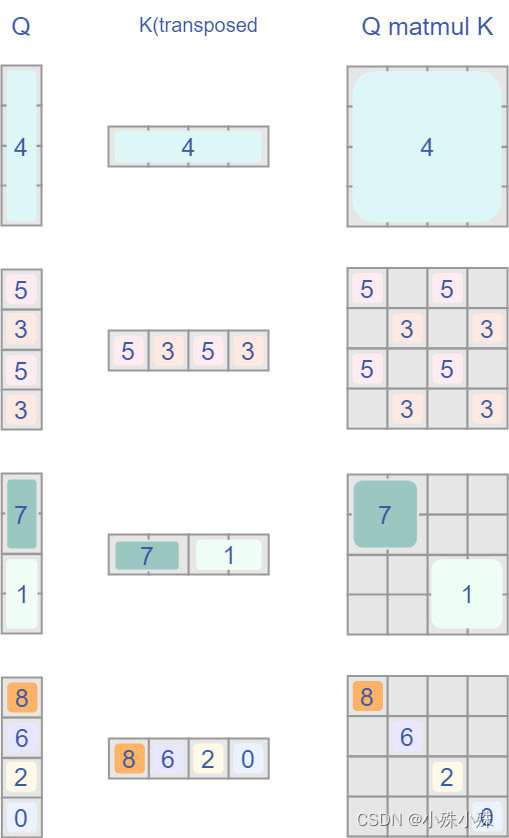
而要想在原始四个窗口下得到正确的结果,我们就必须给Attention的结果加入一个mask(如上图最右边所示)
相关代码:
class WindowAttention(nn.Module):
r""" 基于有相对位置偏差的多头自注意力窗口,支持移位的(shifted)或者不移位的(non-shifted)窗口.
输入:
dim (int): 输入特征的维度.
window_size (tuple[int]): 窗口的大小.
num_heads (int): 注意力头的个数.
qkv_bias (bool, optional): 给 query, key, value 添加可学习的偏置,默认为 True.
qk_scale (float | None, optional): 重写默认的缩放因子 scale.
attn_drop (float, optional): 注意力权重的丢弃率,默认为 0.0.
proj_drop (float, optional): 输出的丢弃率,默认为 0.0.
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim # 输入特征的维度
self.window_size = window_size # 窗口的高 Wh,宽 Ww
self.num_heads = num_heads # 注意力头的个数
head_dim = dim // num_heads # 注意力头的维度
self.scale = qk_scale or head_dim ** -0.5 # 缩放因子 scale
# 定义相对位置偏移的参数表,结构为 [2*Wh-1 * 2*Ww-1, num_heads]
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
# 获取窗口内每个 token 的成对的相对位置索引
coords_h = torch.arange(self.window_size[0]) # 高维度上的坐标 (0, 7)
coords_w = torch.arange(self.window_size[1]) # 宽维度上的坐标 (0, 7)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 坐标,结构为 [2, Wh, Ww]
coords_flatten = torch.flatten(coords, 1) # 重构张量结构为 [2, Wh*Ww]
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 相对坐标,结构为 [2, Wh*Ww, Wh*Ww]
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 交换维度,结构为 [Wh*Ww, Wh*Ww, 2]
relative_coords[:, :, 0] += self.window_size[0] - 1 # 第1个维度移位
relative_coords[:, :, 1] += self.window_size[1] - 1 # 第1个维度移位
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 # 第1个维度的值乘以 2倍的 Ww,再减 1
relative_position_index = relative_coords.sum(-1) # 相对位置索引,结构为 [Wh*Ww, Wh*Ww]
self.register_buffer("relative_position_index", relative_position_index) # 保存数据,不再更新
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 线性层,特征维度变为原来的 3倍
self.attn_drop = nn.Dropout(attn_drop) # 随机丢弃神经元,丢弃率默认为 0.0
self.proj = nn.Linear(dim, dim) # 线性层,特征维度不变
self.proj_drop = nn.Dropout(proj_drop) # 随机丢弃神经元,丢弃率默认为 0.0
trunc_normal_(self.relative_position_bias_table, std=.02) # 截断正态分布,限制标准差为 0.02
self.softmax = nn.Softmax(dim=-1) # 激活函数 softmax
# 定义前向传播
def forward(self, x, mask=None):
"""
输入:
x: 输入特征图,结构为 [num_windows*B, N, C]
mask: (0/-inf) mask, 结构为 [num_windows, Wh*Ww, Wh*Ww] 或者没有 mask
"""
B_, N, C = x.shape # 输入特征图的结构
# 将特征图的通道维度按照注意力头的个数重新划分,并再做交换维度操作
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # 方便后续写代码,重新赋值
# q 乘以缩放因子
q = q * self.scale
# @ 代表常规意义上的矩阵相乘
attn = (q @ k.transpose(-2, -1)) # q 和 k 相乘后并交换最后两个维度
# 相对位置偏移,结构为 [Wh*Ww, Wh*Ww, num_heads]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
# 相对位置偏移交换维度,结构为 [num_heads, Wh*Ww, Wh*Ww]
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0) # 带相对位置偏移的注意力图
if mask is not None: # 判断是否有 mask
nW = mask.shape[0] # mask 的宽
# 注意力图与 mask 相加
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N) # 恢复注意力图原来的结构
attn = self.softmax(attn) # 激活注意力图 [0, 1] 之间
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn) # 随机设置注意力图中的部分值为 0
# 注意力图与 v 相乘得到新的注意力图
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x) # 通过线性层
x = self.proj_drop(x) # 随机设置新注意力图中的部分值为 0
return x
三、Triplet Loss
损失函数公式:
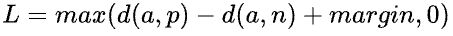
输入是一个三元组,包括锚(Anchor)示例、正(Positive)示例、负(Negative)示例,通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本之间的相似性计算。
a:anchor,锚示例;
p:positive,与a是同一类别的样本;
n:negative,与a是不同类别的样本;
margin是一个大于0的常数。最终的优化目标是拉近a和p的距离,拉远a和n的距离。设定一个margin常量,可以迫使模型努力学习,能让锚点a和负例n的distance值更大,同时让锚点a和正例p的distance值更小。
由于margin的存在,使得triplets loss多了一个参数,margin的大小需要调参。如果margin太大,则模型的损失会很大,而且学习到最后,loss也很难趋近于0,甚至导致网络不收敛,但是可以较有把握的区分较为相似的样本,即a和p更好区分;如果margin太小,loss很容易趋近于0,模型很好训练,但是较难区分a和p。
Triplet Loss代码实现:
def triplet_loss(alpha = 0.2):
def _triplet_loss(y_pred,Batch_size):
anchor, positive, negative = y_pred[:int(Batch_size)], y_pred[int(Batch_size):int(2*Batch_size)], y_pred[int(2*Batch_size):]
pos_dist = torch.sqrt(torch.sum(torch.pow(anchor - positive,2), axis=-1))
neg_dist = torch.sqrt(torch.sum(torch.pow(anchor - negative,2), axis=-1))
keep_all = (neg_dist - pos_dist < alpha).cpu().numpy().flatten()
hard_triplets = np.where(keep_all == 1)
pos_dist = pos_dist[hard_triplets].cuda()
neg_dist = neg_dist[hard_triplets].cuda()
basic_loss = pos_dist - neg_dist + alpha
loss = torch.sum(basic_loss)/torch.max(torch.tensor(1), torch.tensor(len(hard_triplets[0])))
return loss
return _triplet_loss
本文转载自: https://blog.csdn.net/xian0710830114/article/details/124569210
版权归原作者 小殊小殊 所有, 如有侵权,请联系我们删除。
版权归原作者 小殊小殊 所有, 如有侵权,请联系我们删除。