
每个排序算法的讲解,都包括了算法描述,图形演示,算法实现三个部分。
另外,一定要动手试着敲一敲代码哦!!!
简单排序
1、冒泡排序
算法描述:
- 首先在未排序数组的首位开始,和后面相邻的数字进行比较,如果前面一个比后面一个大则进行交换
- 接下来再将第二个位置的数字和后面相邻的数字进行比较,如果大,那么进行交换,直到将最大的数字交换到数字尾部
- 然后呢,再从排序的数组的首部开始,重复前面的2个步骤,讲最大数字交换到未排序的数组 尾部
- 以此类推,直到排序完毕
图形演示:

算法实现:
public static void main(String[] args) {
int[] arr={1,2,5,3,7,9,6,4,0,9,5};
for (int i = 0; i < arr.length-1; i++) {
for (int j = 0; j < arr.length-i-1; j++) {
if(arr[j]>arr[j+1]) {
int tmp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=tmp;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
2、选择排序
算法描述:
- 首先在未排序序列中找到最小元素,存放在排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小元素,放到已排序序列的尾部
- 以此类推,直到所有元素排序完毕
图形演示:

算法实现:
public static void main(String[] args) {
int[] arr={1,2,5,3,7,9,6,4,0,9,5};
int min=0;
for (int i = 0; i < arr.length; i++) {
min=i;
for (int j = i+1; j < arr.length; j++) {
if(arr[min]>arr[j]) {
min=j;
}
}
int tmp=arr[min];
arr[min]=arr[i];
arr[i]=tmp;
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
3、插入排序
算法描述:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一个位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插图到相应的位置
- 重复步骤2~5
图形演示:

**算法实现: **
代码1:
public static void main(String[] args) {
int[] nums={1,5,7,9,3,2,4,0,6,8,5};
int start=1;
for(start=1;start<nums.length;start++) {
int insert=nums[start];//待插入元素
while(start>0) {
if(nums[start-1]>insert) {
nums[start]=nums[start-1];
} else {
nums[start]=insert;
break;
}
start--;
}
if(start==0) {
nums[0]=start;
}
}
for (int i = 0; i < nums.length; i++) {
System.out.print(nums[i]+" ");
}
}
代码2:
public static void main(String[] args) {
Scanner scanner=new Scanner(System.in);
int[] nums={1,5,7,9,3,2,4,0,6,8,5};
int start=1;
for(start=1;start<nums.length;start++) {
int insert=nums[start];//待插入元素
int j=start-1;
for(j=start-1;j>=0;j--) {
if(insert<nums[j]) {
nums[j+1]=nums[j];//往后挪一个
} else {
break;
}
}
nums[j+1]=insert;//本行代码不可以放在break前面
}
for (int i = 0; i < nums.length; i++) {
System.out.print(nums[i]+" ");
}
}
高级排序
4、希尔排序(缩小增量排序)
是插入排序的一种更高效的排序改进版本
算法描述:
- 先根据数组的长度/n,获取增量k(第一次n=2)
- 按增量序列个数k进行分组,一般可以分为k组
- 根据已分好的组进行插入排序(每组排序,根据对应的增量k来找到当前的元素)
- 当每组都排序完毕之后,回到第一步将n*2再次分组进行插入排序,直到最终k=1时,再执行一次插入排序完成最终的排序
图形演示:




 算法实现:
算法实现:
public static void main(String[] args) {
int[] nums={1,5,7,9,3,2,4,0,6,8,5};
//控制增量序列,增量序列为1的时候为最后一趟
for (int i = nums.length/2; i > 0; i/=2) {
//根据增量序列,找到每组比较序列的最后一个数的位置
for (int j = i; j <nums.length ; j++) {
//根据该比较序列的最后一个数的位置,依次向前执行插入排序
for (int k = j-i; k >= 0 ; k-=i) {
if(nums[k]>nums[k+i]) {
int tmp=nums[k];
nums[k]=nums[k+i];
nums[k+i]=tmp;
}
}
}
}
System.out.println(Arrays.toString(nums));
}
5、归并排序
算法描述:
- 归并排序是利用归并的思想实现的排序方法,该算法采用经典的分治策略,即,将问题分成一些小的问题然后递归求解,而治的阶段将分的阶段得到的各答案“修补”在一起,即分而治之
- 归并排序是稳定排序,它是一种十分高效的排序,能利用完全二叉树特性的排序一般性能都不会太差。Java中Arrays.sort()采用了一种名为TimSort的排序算法,就是归并排序的优化版本。
- 归并排序的最好最坏,平均时间复杂度都是O(nlogn)
- 归并排序核心思想是先分再治,具体算法描述如下:
- 先将未排序数组/2进行分组,然后将分好的数组继续/2再次分组,知道无法分组,这个就是分的过程
- 然后再将之后再把两个数组大小为1合并为一个大小为2的,再把两个大小为2的合并成4的,同时在合并的过程中完成数组的排序,最终直到全部大小的数组合并起来,这个就是治的过程
我的乖乖,看起来好像是云里雾里的,是不是?不慌不慌,看下面的图,就会豁然开朗哒!!!
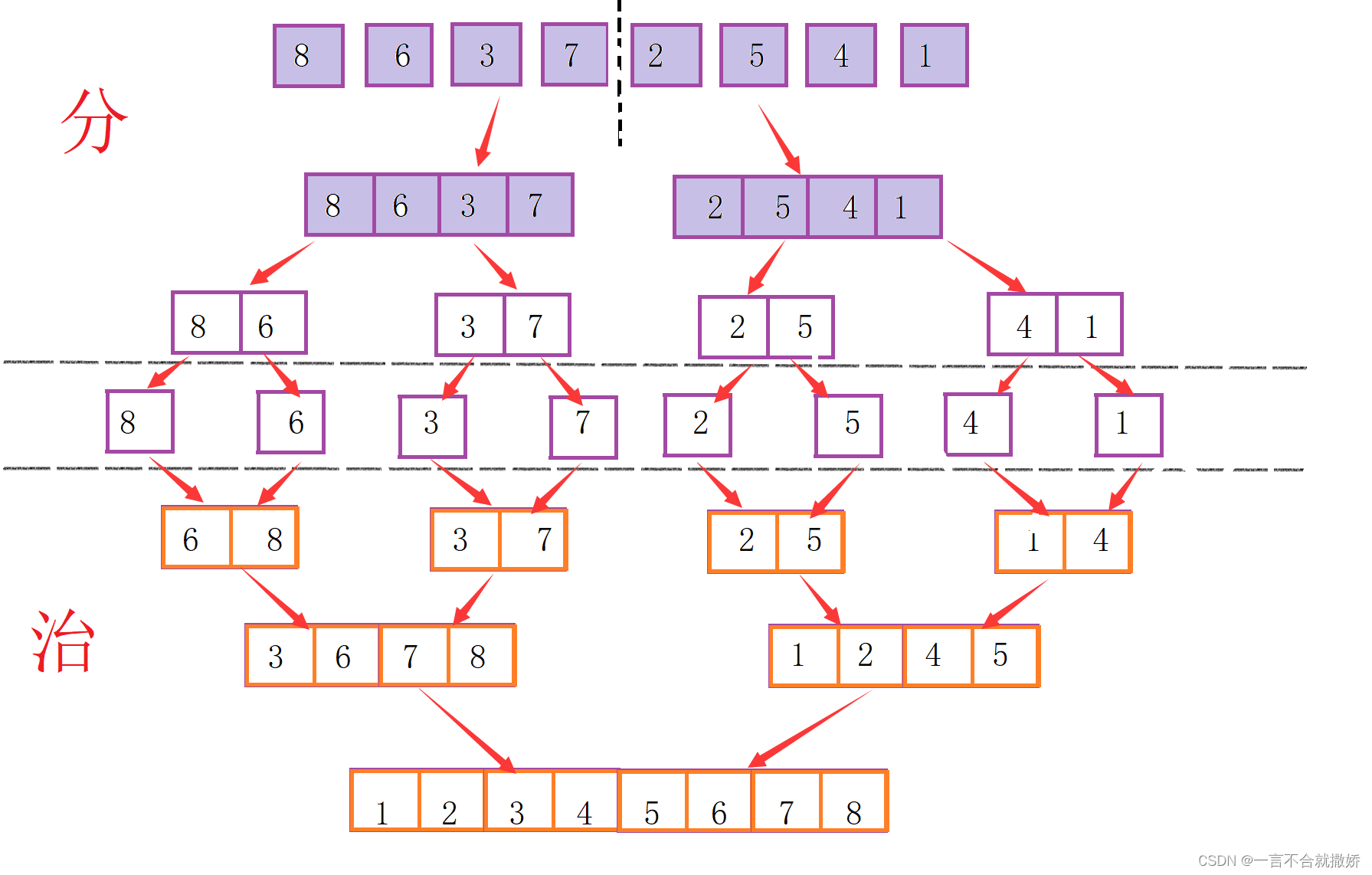
5.治的过程中会为两个数组设计两个游标,和一个新的数组
- 分别比较两个游标指对应数组的元素,将小的插入到新的数组中
- 然后向后移动较小的数组的游标,继续进行比较
- 反复前面两步,最终将两个数组中的元素排序合并到新的数组中
有点糊?看
图形演示:

算法实现:
public class Test {
public static void main(String[] args) {
int[] arr = {8, 10, -1, 6, 7, 3, 0, 40, 70};
int[] temp = new int[arr.length];//归并排序需要额外的空间
mergeSort(arr, 0, arr.length - 1, temp);
System.out.println(Arrays.toString(arr));
}
//分
public static void mergeSort(int[] arr, int left, int right, int[] temp) {
if (left < right) {
int mid = (left + right) / 2;//中间索引
mergeSort(arr, left, mid, temp);//向左递归分解
mergeSort(arr, mid + 1, right, temp);//向右递归分解
merge(arr, left, mid, right, temp);//合并
}
}
//治
public static void merge(int[] arr, int left, int mid, int right, int[] temp) {
int i = left;//i为指向左边序列第一个元素的索引
int j = mid + 1;//j为指向右边序列第一个元素的索引
int t = 0;//指向临时temp数组的当前索引
//先把左右两边有序数据按规则存入temp数组中,直到有一边的数据全部填充temp中
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) {
temp[t] = arr[i];
t++;
i++;
} else {
temp[t] = arr[j];
t++;
j++;
}
}
//将有剩余数据的一边全部存入temp中
while (i <= mid) {//左边序列有剩余元素
temp[t] = arr[i];
t++;
i++;
}
while (j <= right) {//右边序列有剩余元素
temp[t] = arr[j];
t++;
j++;
}
//将temp中的元素拷贝到arr中
t = 0;
int tempLeft = left;
while (tempLeft <= right) {
arr[tempLeft] = temp[t];
t++;
tempLeft++;
}
}
}
6、快速排序
算法描述:
- 快速排序是对冒泡排序的一种改进,,通过分而治之的思想,减少排序中交换和遍历的次数,整个过程可以通过递归的方式完成:
- 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
- 具体描述:
- 从数列中挑出一个元素,称为"基准"。
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区操作。
- 递归地把小于基准值元素的子数列和大于基准值元素的子数列排序。
图形演示:
算法实现:
public class Test {
public static void main(String[] args) {
int[] array={3,5,6,7,8,3,2,1,9,5,3};
quickSort(array);
System.out.println(Arrays.toString(array));
}
//快速排序
public static void quickSort(int[] array) {
int len;
if (array == null || (len = array.length) == 0 || len == 1) {
return;
}
sort(array, 0, len - 1);
}
//快排核心算法,递归实现
public static void sort(int[] array, int left, int right) {
//1.设置递归条件
if (left > right) {
return;
}
//2.声明左右指针以及基准值。这里的基准值设置为i与j相遇的位置为每次的基准值,初始值为第一个元素。
int i = left;
int j = right;
int base = array[left];
//3.控制while循环找到i=j的位置
while (i != j) {
//先 从右往左找到一个小于基准值的点(哪边作为初始值哪边后走),且保证i一直在j左侧。
while (array[j] >= base && i < j) {
j--;
}
//同理,从左往右找到大于基准值的点,与j交换
while (array[i] <= base && i < j) {
i++;
}
//此时的i与j已经相等,交换(这个if好像可有可无...待验证)。
if (i < j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
//此时一次交换完毕,重新设置基准值(基准值为第一个元素)。
array[left] = array[i];
array[i] = base;
//递归进行 右侧进行
sort(array, left, i - 1);
// 左侧进行
sort(array, i + 1, right);
}
}
7、计数排序
算法描述:
- 计数排序是非基于比较的排序算法
- 优势在于在对一定范围内的整数排序时,他的时间复杂度为O(n+k)【其中k是整数的范围】,快于任何比较排序算法,是一种牺牲空间换取时间的做法,而且当O(k)>O(nlog(n))的时候,其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上,下限是O(nlog(n)),如归并排序,堆排序)
- 计数排序是一种适合于最大值最小值的差值不是很大的排序,也就是说重复的数据会比较多的情况
- 具体实现过程:
- 首先遍历整个数组,找到最大值
- 然后根据最大值创建一个临时数组,用于统计每个数字出现的次数,例如:tmp[i]=m,表示元素i一共出现 m 次
- 最后再把临时数组统计的数据从小到大返回到原来的数组中,这样就是有序的
图形演示:
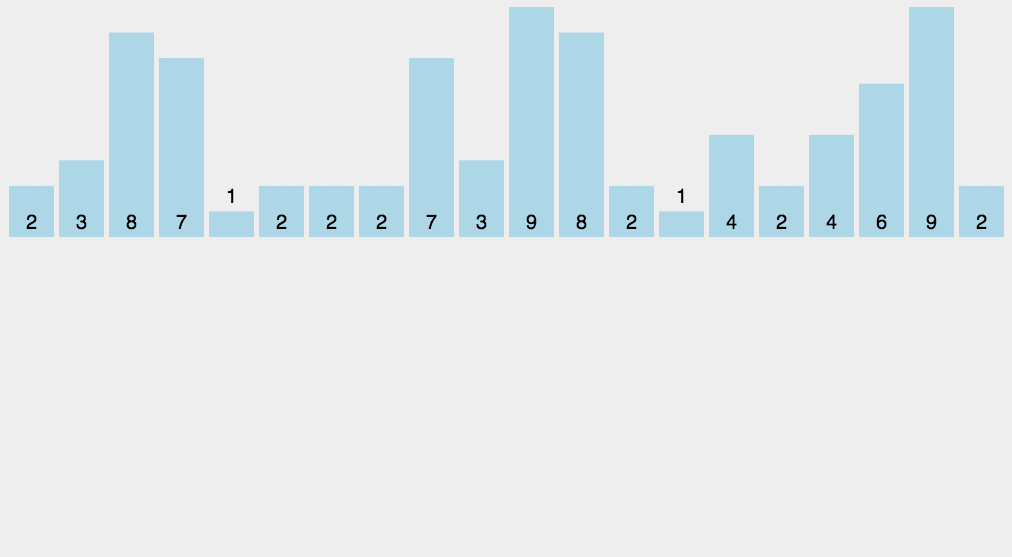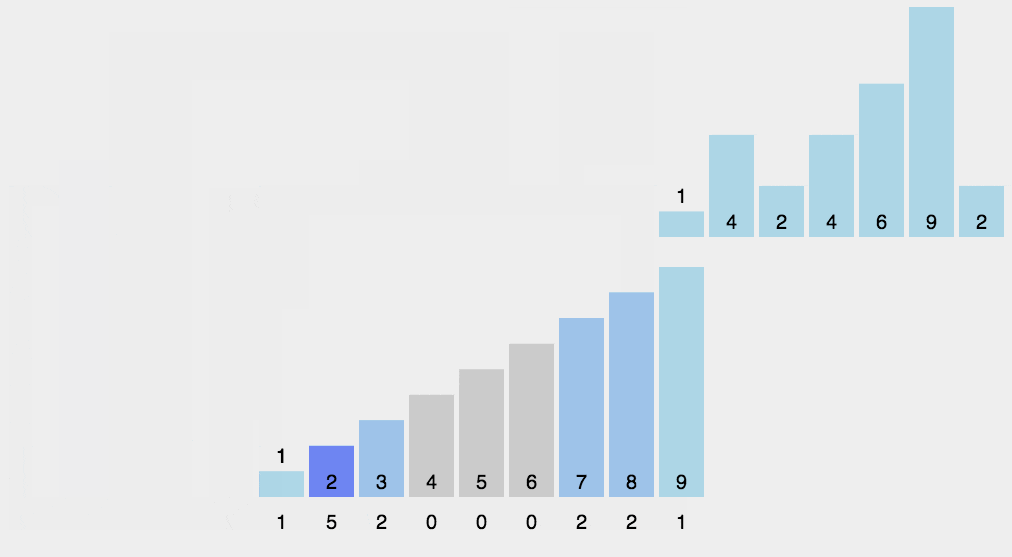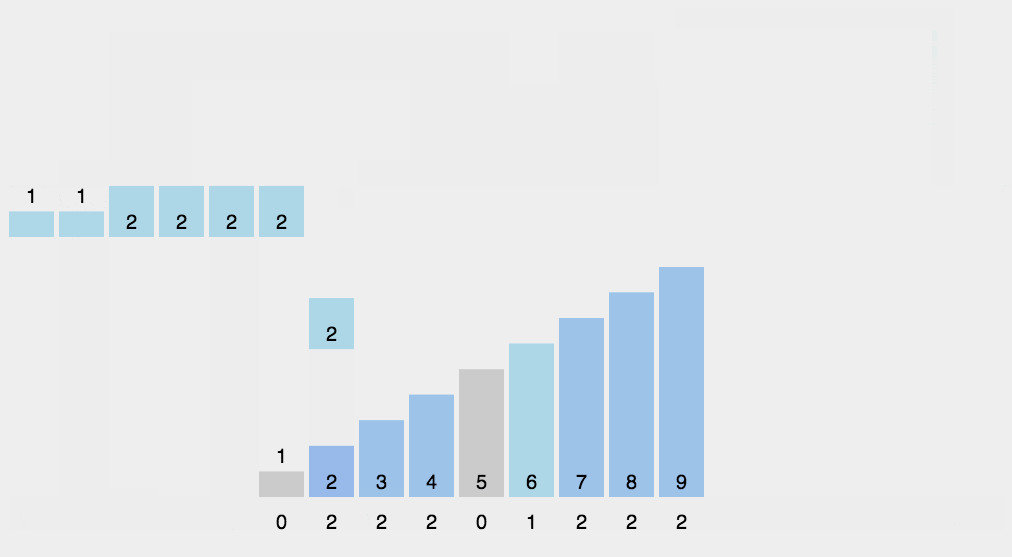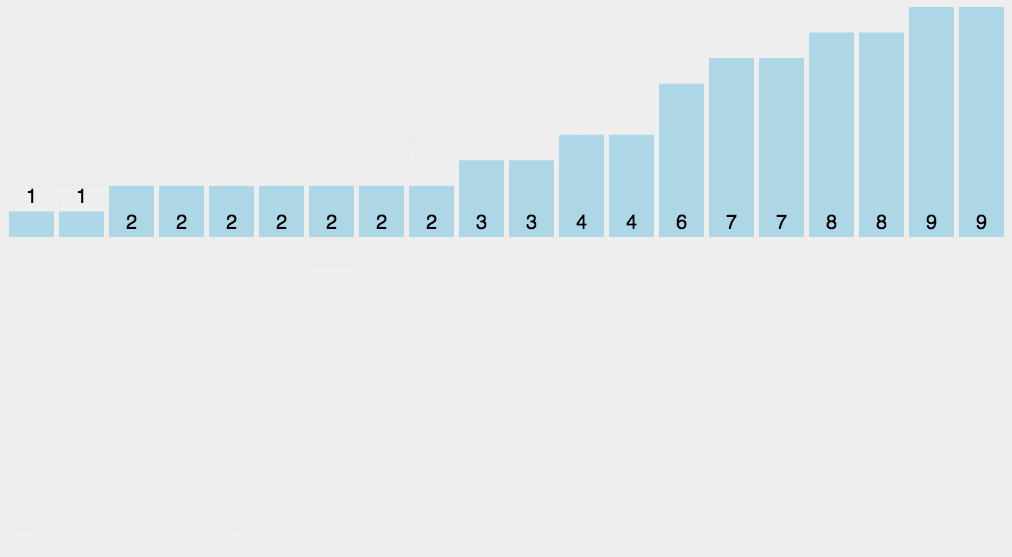
算法实现:
public static void main(String[] args) {
int[] nums={1,5,7,2,3,4,8,9,4,5};
int max=nums[0];
for (int i = 0; i < nums.length; i++) {
if(nums[i]>max) {
max=nums[i];
}
}
//临时数组——计数数组
int[] arr=new int[max+1];
for (int i = 0; i < nums.length; i++) {
arr[nums[i]]+=1;
}
int j=0;
for (int i = 0; i < arr.length; i++) {
while(arr[i]!=0) {
nums[j]=i;
arr[i]--;
j++;
}
}
System.out.println(Arrays.toString(nums));
}
8、堆排序
关于堆的知识普及:
- 堆排序是指利用堆这种数据结构所设计的一种排序算法,它是一种选择排序,他的最好最坏及平均时间复杂度均是O(nlog(n))
- 堆是一颗完全二叉树:
- 当所有的结点的值都大于或等于其左右的子结点的值称为大顶堆
- 当所有的结点的值都小于或等于其左右的子结点的值称为小顶堆

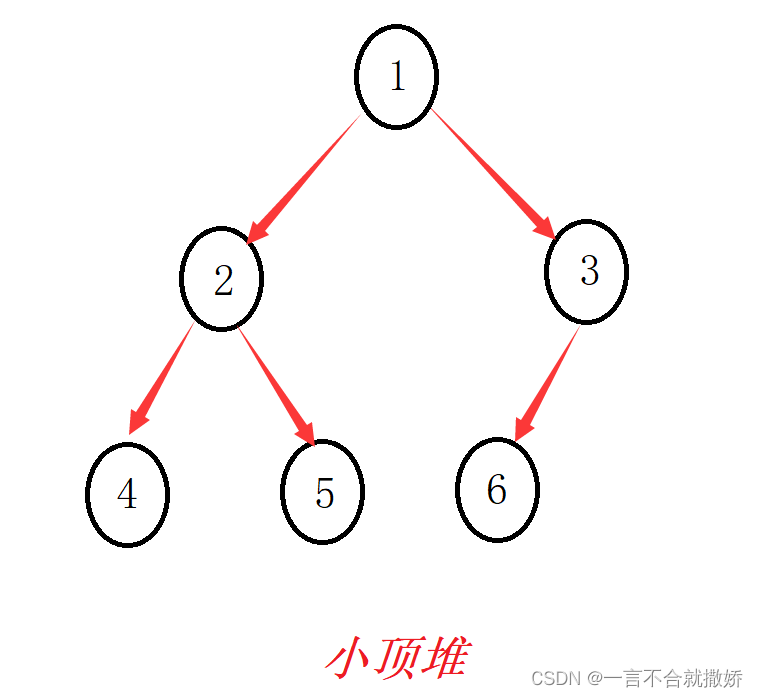 算法描述 :
算法描述 :
1、首先,将待排序的数组构造一个大顶堆
- 从最后一个非叶子结点开始,和其结点进行比较
- 如果子结点比根节点大,则选择较大的子结点和根结点进行交换
- 如果没有发生交换,则从倒数第二个非叶子结点继续比较
- 以上的做法就是将较大的元素向树的高层进行交换。注意:当树的层次较多的时候,如果在发生根节点和子结点发生交换之后,还需要继续将交换的结点与其下的子节点继续比较,直到没有子结点位置
- 最终从最后一个非叶子结点遍历到根结点,交换完之后大顶堆就构造完毕了
图形演示:

2、那么,堆的根结点,则是数组中的最大值
3、将根结点和末尾元素进行交换,之后末尾就是最大值
4、然后将剩余的n-1元素重新构造成一大顶堆,然后将跟结点和末尾(n-1)元素进行交换,这样n和n-1已经有序了
5、剩下的n-2元素继续构造大顶堆和最后n-2交换,如此反复直到排序排序完毕
完整图形演示(接着上面):
由于大小GIF大小有限制,所以分成了多个展示:



算法实现:
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int[] arr = {3, 5, 2, 7,4,5,8,2,1,9,0,5,4};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
//堆排序
public static void heapSort(int[] arr) {
//将无序序列构建成一个堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, arr.length);
}
//将堆顶元素和末尾元素交换,将最大元素放置数组末端
//重新调整至堆结构,然后继续将堆顶元素和当前末尾元素交换,以此往复
for (int i = arr.length - 1; i > 0; i--) {
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, i);
}
}
// 将二叉树调整为堆
public static void adjustHeap(int[] arr, int i, int length) {
int temp = arr[i];
//k=2i+1是i的左子结点
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if (k + 1 < length && arr[k] < arr[k + 1])//左子结点的值<右子结点的值
k++;//指向右节点
if (arr[k] > temp) {//如果子结点的值>根节点的值
arr[i] = arr[k];//将较大的值赋给当前结点
i = k;//i指向k,继续循环比较
} else
break;
}
//for循环后,已经将以i为根结点的树的最大值,放在了顶部
arr[i] = temp;//将temp值放到调整后的位置
}
}
9、桶排序
算法描述:
就是把一个数组分成几个桶(其实是几个区间,从小到大或从大到小的几个区间)装,然后让每个桶(区间)有序,然后取出来放一起就可以了,相当于把几个有序的段拿出来放一起,自然还是有序的,当然需要是按照区间的顺序拿了。
图形演示:

算法实现:
package com.keafmd.Sequence;
import java.util.ArrayList;
import java.util.Collections;
public class BucketSort {
public static void bucketSort(int[] arr){
bucketSort(arr,true);
}
public static void bucketSort(int[] arr,boolean ascending){
if(arr==null||arr.length==0){
return;
}
//计算最大值与最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i=0;i<arr.length;i++){
max = Math.max(arr[i],max);
min = Math.min(arr[i],min);
}
//计算桶的数量
int bucketNUm = (max-min)/ arr.length+1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNUm);
for(int i=0;i<bucketNUm;i++){
bucketArr.add(new ArrayList<>());
}
//将每个元素放入桶中
for(int i=0;i<arr.length;i++){
int num = (arr[i]-min)/ (arr.length);
bucketArr.get(num).add(arr[i]);
}
//对每个桶进行排序
for (int i = 0; i < bucketArr.size(); i++) {
//用系统的排序,速度肯定没话说
Collections.sort(bucketArr.get(i));
}
//将桶中元素赋值到原序列
int index;
if(ascending){
index=0;
}else{
index=arr.length-1;
}
for(int i=0;i<bucketArr.size();i++){
for(int j= 0;j<bucketArr.get(i).size();j++){
arr[index] = bucketArr.get(i).get(j);
if(ascending){
index++;
}else{
index--;
}
}
}
}
}
10、基数排序
算法描述:
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
基数排序是效率高并且稳定的排序法。(所谓稳定是什么呢?比如对一个原始数组:3,1,43,1 排序,使用基数排序后的数组为 1,1,3,43,第一个1在前面,第二个1在后面)
图形演示:

算法实现:
package DataStructures.Sort;
import java.util.Arrays;
public class RadixSort {
public static void main(String[] args) {
int[] arr = new int[]{53, 3, 542, 748, 14, 214};
radixSort(arr);
}
/**
* @param arr
* @author ZJ
* Description 基数排序
* date 2022-05-11 22:01:50 22:01
*/
public static void radixSort(int[] arr) {
//定义一个二维数组,表示10个桶,每个桶就是一个一维数组
int[][] bucket = new int[10][arr.length];//很明显,基数排序使用了空间换时间
//为了记录每个桶中实际存放了多少个数据,定义一个一维数组来记录每次放入数据的个数
//比如bucketElementCounts[0]=3,意思是bucket[0]存放了3个数据
int[] bucketElementCounts = new int[10];
int digitOfElement = 0;//每次取出的元素的位数
//找到数组中最大数的位数
int max = 0;
for (int i = 0; i < arr.length; i++) {
if (max < String.valueOf(arr[i]).length()) {
max = String.valueOf(arr[i]).length();
}
}
int index = 0;
for (int i = 0, n = 1; i < max; i++, n *= 10) {
//第i+1轮排序(针对每个元素的位进行排序处理)
for (int j = 0; j < arr.length; j++) {
digitOfElement = arr[j] / n % 10;//取出每个元素的位
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];//放入对应的桶
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标取出数据),放入原来的数组
index = 0;
//遍历每一个桶,并将桶中数据放入原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
//如果桶中有数据,我们才放到原数组
if (bucketElementCounts[k] != 0) {
//循环第k个桶,放入
for (int l = 0; l < bucketElementCounts[k]; l++) {
arr[index] = bucket[k][l];
index++;
}
}
bucketElementCounts[k] = 0;//置零!!!!!
}
System.out.println("第" + i + 1 + "轮排序后" + Arrays.toString(arr));
}
}
}
总结:
1、十大排序算法对比
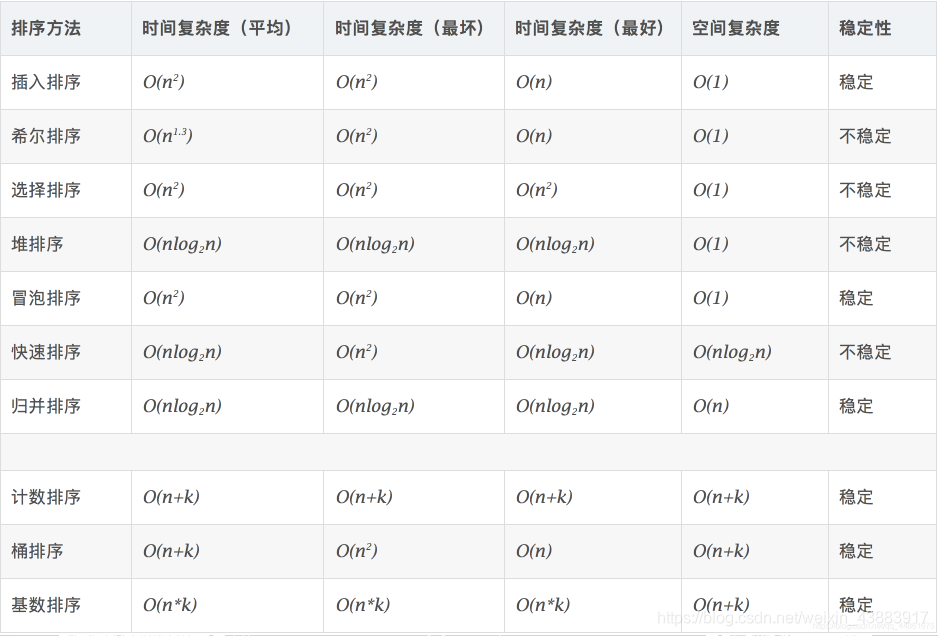
补充:什么是稳定性?
比如对一个原始数组:3,1,43,1 排序,使用基数排序后的数组为 1,1,3,43,第一个1在前面,第二个1在后面)
2、基数排序、计数排序、桶排序的区别
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;
3、从时间复杂度来说:
- 平方阶O(n²)排序:各类简单排序:直接插入、直接选择和冒泡排序
- 线性对数阶O(nlog₂n)排序:快速排序、堆排序和归并排序
- O(n1+§))排序,§是介于0和1之间的常数:希尔排序
- 线性阶O(n)排序:基数排序,此外还有桶、箱排序
4、论是否有序对排序的影响:
- 当原数据有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);
- 而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n2);
- 原数据是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
5、选择排序算法的依据
从以下四点来谈谈如何选择:
1.待排序的记录数目n的大小;
2.记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
3.关键字的结构及其分布情况;
4.对排序稳定性的要求。
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序。
2) 当n较大,内存空间允许,且要求稳定性 =》归并排序
3)当n较小,可采用直接插入或直接选择排序。
4)一般不使用或不直接使用传统的冒泡排序。
5)基数排序
它是一种稳定的排序算法,但有一定的局限性:
- 关键字可分解。
- 记录的关键字位数较少,如果密集更好
如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
6、快排、冒泡、插入排序的优缺点:
快排:
优点:极快,数据移动少;是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
缺点:不稳定;
冒泡:
优点:稳定
缺点:慢,每次只能移动两个相邻的数据;
插入:
优点:稳定,快
缺点:比较次数不一定,比较次数越少,插入点后的数据移动越多,特别是数据量庞大的时候
下期见!!!

版权归原作者 一言不合就撒娇 所有, 如有侵权,请联系我们删除。