

我们生活在这样一个时代:任何一个组织或公司要想扩大规模并保持相关性,就必须改变他们对技术的看法,并迅速适应不断变化的环境。我们已经知道谷歌是如何实现图书数字化的。或者Google earth是如何使用NLP来识别地址的。或者怎样才能阅读数字文档中的文本,如发票、法律文书等。

但它到底是如何工作的呢?
这篇文章是关于在自然场景图像中进行文本识别的光学字符识别(OCR)。我们将了解为什么这是一个棘手的问题,用于解决的方法,以及随之而来的代码。
But Why Really?
在这个数字化的时代,存储、编辑、索引和查找数字文档中的信息比花几个小时滚动打印/手写/打印的文档要容易得多。
此外,在一个相当大的非数字文档中查找内容不仅耗时;在手动滚动文本时,我们也可能会错过信息。对我们来说幸运的是,电脑每天都在做一些人类认为只有自己能做的事情,而且通常表现得比我们更好。
从图像中提取文本有许多应用。其中一些应用程序是护照识别、自动车牌识别、将手写文本转换为数字文本、将打印文本转换为数字文本等。
挑战
在讨论我们需要如何理解OCR面临的挑战之前,我们先来看看OCR。
在2012年深度学习热潮之前,就已经有很多OCR实现了。虽然人们普遍认为OCR是一个已解决的问题,但OCR仍然是一个具有挑战性的问题,尤其是在无约束环境下拍摄文本图像时。
我谈论的是复杂的背景、噪音、不同的字体以及图像中的几何畸变。正是在这种情况下,机器学习OCR工具才会大放异彩。
OCR问题中出现的挑战主要是由于手头的OCR任务的属性。我们通常可以把这些任务分为两类:
结构化文本——类型化文档中的文本。在一个标准的背景,适当的行,标准的字体和大多数密集的文本。

非结构化文本——自然场景中任意位置的文本。文本稀疏,没有合适的行结构,复杂的背景,在图像中的随机位置,没有标准的字体。

许多早期的技术解决了结构化文本的OCR问题。但是这些技术不适用于自然场景,因为自然场景是稀疏的,并且具有与结构化数据不同的属性。
在本文中,我们将更多地关注非结构化文本,这是一个需要解决的更复杂的问题。正如我们所知,在深度学习的世界里,没有一个解决方案可以适用于所有人。我们将看到解决手头任务的多种方法,并将通过其中一种方法进行工作。
用于非结构化OCR任务的数据集
有很多英文的数据集,但是很难找到其他语言的数据集。不同的数据集提供了不同的任务需要解决。下面是一些通常用于机器学习OCR问题的数据集示例。
SVHN数据集
街景门牌号数据集包含73257用于训练,26032用于测试,531131作为额外的训练数据。数据集包括10个标签,它们是数字0-9。数据集与MNIST不同,因为SVHN具有不同背景下的门牌号图像。数据集在每个数字周围都有包围框,而不是像MNIST中那样有几个数字图像。
场景文本数据集
该数据集包含3000张不同设置(室内和室外)和光照条件(阴影、光线和夜晚)的图像,文本为韩文和英文。有些图像还包含数字。
Devanagri字符数据集
这个数据集为我们提供了来自25个不同的本地作者在Devanagari脚本中获得的36个字符类的1800个样本。还有很多类似的例子,例如汉字,验证码,手写单词。
阅读文本
任何典型的机器学习OCR管道都遵循以下步骤:

预处理
- 从图像中去除噪声
- 从图像中删除复杂的背景
- 处理图像中不同的亮度情况

这些是在计算机视觉任务中预处理图像的标准方法。在本博客中,我们不会关注预处理步骤。
文本检测

文本检测技术需要检测图像中的文本,并在具有文本的图像部分周围创建和包围框。标准的目标检测技术也可以使用。
滑动窗口技术
可以通过滑动窗口技术在文本周围创建边界框。然而,这是一个计算开销很大的任务。在这种技术中,滑动窗口通过图像来检测窗口中的文本,就像卷积神经网络一样。我们尝试使用不同的窗口大小,以避免错过具有不同大小的文本部分。有一个卷积实现的滑动窗口,这可以减少计算时间。
单步和基于区域的探测器
有单步头检测技术,如YOLO(只看一次)和基于区域的文本检测技术,用于图像中的文本检测。
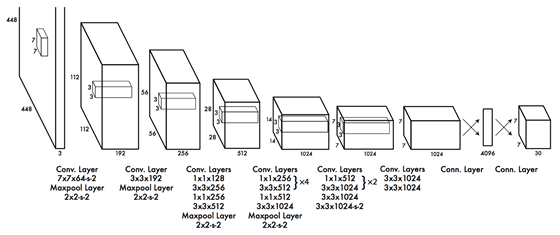
滑动窗口不同的是,YOLO是一种单步技术,只通过一次图像来检测该区域的文本。
基于区域的方法分一般都会分为两个步骤。
首先,网络提出可能有测试的区域,然后对有文本的区域进行分类。
EAST(高效精准场景文本检测)
是一种基于本文的非常鲁棒的文本检测深度学习方法。值得一提的是,它只是一种文本检测方法。它可以找到水平和旋转的边界框。它可以与任何文本识别方法结合使用。
本文的文本检测管道排除了冗余和中间步骤,只有两个阶段。
一种是利用全卷积网络直接生成单词或文本行级别的预测。生成的预测可以是旋转的矩形或四边形,通过非最大抑制步骤进一步处理,得到最终的输出。
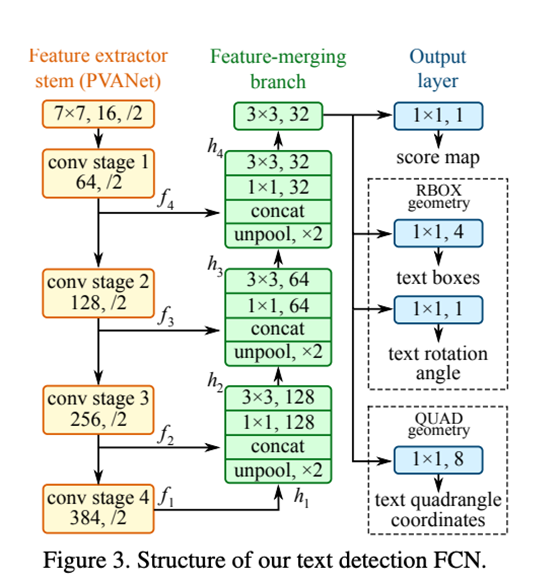
EAST可以检测图像和视频中的文本。该算法在720p图像上以13FPS的速度实时运行,具有较高的文本检测精度。这种技术的另一个好处是,它的实现可以在OpenCV 3.4.2和OpenCV 4中使用。我们将看到这个EAST模型的应用,以及文本识别。
文字识别
一旦我们检测到有文本的包围框,下一步就是识别文本。有几种识别文本的技术。我们将在下一节讨论一些最好的方法。
CRNN
卷积递归神经网络(Convolutional Neural Network, CRNN)是将CNN、RNN和CTC(Connectionist Temporal Classification, Connectionist Temporal Classification)三种方法结合起来,用于基于图像的序列识别任务,例如场景文本识别和OCR。网络架构取自于2015年发表的论文。
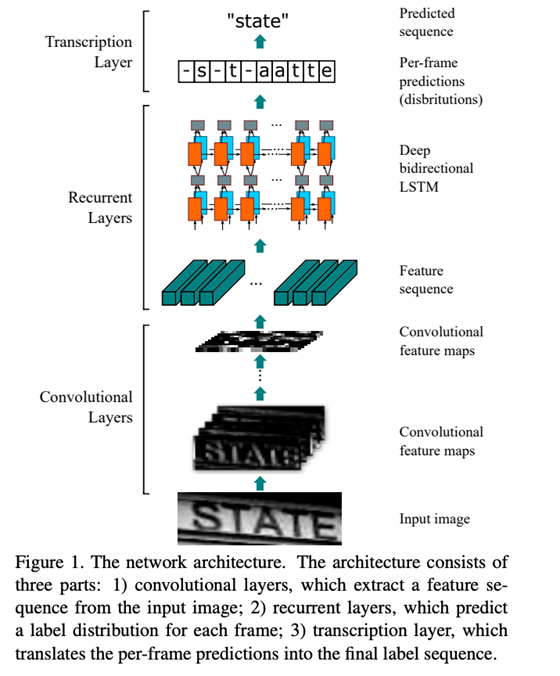
这种神经网络结构将特征提取、序列建模和转录集成到一个统一的框架中。该模型不需要字符分割。卷积神经网络从输入图像(文本检测区域)中提取特征。利用深层双向递归神经网络对标签序列进行预测,预测结果具有一定的相关性。转录层将RNN生成的每一帧转换成标签序列。转录有两种模式,即无词典转录和基于词典的转录。在基于字典的方法中,最高可能的标签序列将被预测。
机器学习OCR与Tesseract
Tesseract最初是在1985年至1994年在惠普实验室开发的。2005年,它由惠普公司开源。根据维基百科,
在2006年,Tesseract被认为是当时最精确的开源OCR引擎之一。
Tesseract的功能主要限于结构化文本数据。在非结构化的文本中,它的性能会很差,并且有很大的噪声。自2006年以来,谷歌赞助了Tesseract的进一步开发。
基于深度学习的方法对非结构化数据有更好的处理效果。Tesseract 4通过基于LSTM网络(一种递归神经网络)的OCR引擎增加了基于深度学习的能力,该引擎专注于线条识别,但也支持Tesseract 3的遗留Tesseract OCR引擎,该引擎通过识别字符模式工作。最新稳定版4.1.0于2019年7月7日发布。这个版本在非结构化文本上也更加精确。
我们将使用一些图像来展示EAST方法的文本检测和Tesseract 4的文本识别。让我们看看下面代码中的文本检测和识别。
##Loading the necessary packages
import numpy as np
import cv2
from imutils.object_detection import non_max_suppression
import pytesseract
from matplotlib import pyplot as plt#Creating argument dictionary for the default arguments needed in the code.
args = {"image":"../input/text-detection/example-images/Example-images/ex24.jpg", "east":"../input/text-detection/east_text_detection.pb", "min_confidence":0.5, "width":320, "height":320}
在这里,我首先处理必要的包。OpenCV包使用EAST模型进行文本检测。tesseract包用于识别检测到的文本框中的文本。
确保tesseract版本>= 4。Tesseract的安装请大家自行百度。
以下是一些参数的含义:
image:用于文本检测和识别的输入图像的位置。
east:具有预先训练的east检测器模型的文件的位置。
min_confidence:最小置信值预测的几何形状在该位置的置信值的最小概率得分
width:图像宽度应该是32的倍数,这样EAST模型才能正常工作
height:图像高度应该是32的倍数,这样EAST模型才能正常工作
图像处理
#Give location of the image to be read.
#"Example-images/ex24.jpg" image is being loaded here. args['image']="../input/text-detection/example-images/Example-images/ex24.jpg"
image = cv2.imread(args['image'])#Saving a original image and shape
orig = image.copy()
(origH, origW) = image.shape[:2]# set the new height and width to default 320 by using args #dictionary.
(newW, newH) = (args["width"], args["height"])#Calculate the ratio between original and new image for both height and weight.
#This ratio will be used to translate bounding box location on the original image.
rW = origW / float(newW)
rH = origH / float(newH)# resize the original image to new dimensions
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]# construct a blob from the image to forward pass it to EAST model
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
加载预先训练的EAST模型并定义输出层
# load the pre-trained EAST model for text detection
net = cv2.dnn.readNet(args["east"])# We would like to get two outputs from the EAST model.
#1. Probabilty scores for the region whether that contains text or not.
#2. Geometry of the text -- Coordinates of the bounding box detecting a text
# The following two layer need to pulled from EAST model for achieving this.
layerNames = [
"feature_fusion/Conv_7/Sigmoid",
"feature_fusion/concat_3"]
EAST模型前向传播
#Forward pass the blob from the image to get the desired output layers
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
从EAST模型预测中解码边框函数
## Returns a bounding box and probability score if it is more than minimum confidence
def predictions(prob_score, geo):
(numR, numC) = prob_score.shape[2:4]
boxes = []
confidence_val = []# loop over rows
for y in range(0, numR):
scoresData = prob_score[0, 0, y]
x0 = geo[0, 0, y]
x1 = geo[0, 1, y]
x2 = geo[0, 2, y]
x3 = geo[0, 3, y]
anglesData = geo[0, 4, y]# loop over the number of columns
for i in range(0, numC):
if scoresData[i] < args["min_confidence"]:
continue(offX, offY) = (i * 4.0, y * 4.0)# extracting the rotation angle for the prediction and computing the sine and cosine
angle = anglesData[i]
cos = np.cos(angle)
sin = np.sin(angle)# using the geo volume to get the dimensions of the bounding box
h = x0[i] + x2[i]
w = x1[i] + x3[i]# compute start and end for the text pred bbox
endX = int(offX + (cos * x1[i]) + (sin * x2[i]))
endY = int(offY - (sin * x1[i]) + (cos * x2[i]))
startX = int(endX - w)
startY = int(endY - h)boxes.append((startX, startY, endX, endY))
confidence_val.append(scoresData[i])# return bounding boxes and associated confidence_val
return (boxes, confidence_val)
我们只解码水平边界框。
通过非最大抑制得到最终的边界框
# Find predictions and apply non-maxima suppression
(boxes, confidence_val) = predictions(scores, geometry)
boxes = non_max_suppression(np.array(boxes), probs=confidence_val)
现在我们已经得到了边界框。我们如何从检测到的边界框中提取文本?Tesseract可以实现。
生成带有边界框坐标和框中可识别文本的列表
# initialize the list of results
results = []# loop over the bounding boxes to find the coordinate of bounding boxes
for (startX, startY, endX, endY) in boxes:
# scale the coordinates based on the respective ratios in order to reflect bounding box on the original image
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)#extract the region of interest
r = orig[startY:endY, startX:endX]#configuration setting to convert image to string.
configuration = ("-l eng --oem 1 --psm 8")
##This will recognize the text from the image of bounding box
text = pytesseract.image_to_string(r, config=configuration)# append bbox coordinate and associated text to the list of results
results.append(((startX, startY, endX, endY), text))
上面的代码部分已经将边界框坐标和相关文本存储在一个列表中。我们会看到它在图像上的样子。
在我们的示例中,我们使用了Tesseract的特定配置。tesseract配置有多个选项。
l: language, chosen English in the above code.
oem(OCR Engine modes):
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
psm(Page segmentation modes):
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
我们可以根据我们的图像数据选择特定的Tesseract配置。
显示带有边框和可识别文本的图像
#Display the image with bounding box and recognized text
orig_image = orig.copy()# Moving over the results and display on the image
for ((start_X, start_Y, end_X, end_Y), text) in results:
# display the text detected by Tesseract
print("{}\n".format(text))# Displaying text
text = "".join([x if ord(x) < 128 else "" for x in text]).strip()
cv2.rectangle(orig_image, (start_X, start_Y), (end_X, end_Y),
(0, 0, 255), 2)
cv2.putText(orig_image, text, (start_X, start_Y - 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0,0, 255), 2)plt.imshow(orig_image)
plt.title('Output')
plt.show()
结果
上面的代码使用OpenCV EAST模型进行文本检测,使用Tesseract进行文本识别。Tesseract的PSM已相应地设置。需要注意的是,Tesseract的检测需要清晰的图像。
在我们当前的实现中,由于其实现的复杂性,我们没有考虑旋转边界框。但是在文本旋转的实际场景中,上面的代码不能很好地工作。此外,当图像不是很清晰时,Tesseract将很难正确识别文本。
通过上述代码生成的部分输出如下:



该代码可以为以上三个图像提供良好的结果。文字清晰,文字背后的背景在这些图像中也是统一的。

这个模型在这里表现得很好。但是有些字母识别不正确。可以看到,边框基本上是正确的。但是我们当前的实现不提供旋转边界框。这是由于Tesseract不能完全识别它。

这个模型在这里表现得相当不错。但是有些文本在边界框中不能正确识别。数字1根本无法检测到。这里有一个不一致的背景,也许生成一个统一的背景会有助于这个案例。同样,24没有被正确识别。在这种情况下,填充边界框可能会有所帮助。

在上面的例子中,背景中有阴影的样式化字体似乎影响了结果。
我们不能指望OCR模型是100%准确的。尽管如此,我们已经通过EAST模型和Tesseract取得了良好的结果。添加更多的过滤器来处理图像可能有助于提高模型的性能。
作者:Rahul Agarwal
本文代码完整:https://www.kaggle.com/mlwhiz/text-detection-v1
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********