
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本章中,您将穿越星星,尝试以XGBClassifier为向导发现系外行星。本章的原因是双重的。首先是使用 XGBoost 在自上而下的研究中获得实践非常重要,因为出于所有实际目的,这就是您通常使用 XGBoost 所做的事情。尽管您可能无法自己发现带有 XGBoost 的系外行星,但您在此处实施的策略(包括选择正确的评分指标和考虑该评分指标仔细微调超参数)适用于 XGBoost 的任何实际使用。这个特殊案例研究的第二个原因是,所有机器学习从业者都必须精通胜任处理不平衡数据集,这是这一章的关键主题。
具体来说,您将获得使用混淆矩阵和分类报告、理解精确率与召回率、重新采样数据、应用scale_pos_weight等方面的新技能。从XGBClassifier获得最佳结果需要仔细分析不平衡的数据并明确预期目标。在本章中,XGBClassifier是一项自上而下的研究,分析光数据以预测宇宙中的系外行星。
在本章中,我们涵盖以下主要主题:
- 寻找系外行星
- 分析混淆矩阵
- 重采样不平衡数据
- 调整和缩放 XGBClassifier
寻找系外行星
在本节中,我们将通过分析系外行星数据集开始搜索系外行星。我们将提供在尝试通过绘制和观察光图检测系外行星之前发现它们的历史背景。绘制时间序列是一种有价值的机器学习技能,可用于深入了解任何时间序列数据集。最后,在发现明显缺陷之前,我们将使用机器学习进行初步预测。
历史背景
自古以来,天文学家就一直在从光中收集信息。随着时代的到来望远镜,天文知识在17世纪激增。望远镜和数学模型的结合使 18世纪的天文学家能够非常精确地预测我们太阳系内的行星位置和日食。
在 20 世纪,天文学研究继续伴随着更先进的技术和更复杂的数学。围绕其他恒星旋转的行星,称为系外行星,是在宜居地带发现。宜居带的行星意味着系外行星的位置和大小与地球相当,因此它是容纳液态水和生命的候选者。
这些系外行星不是通过望远镜直接观察到的,而是通过星光的周期性变化推断出来的。一个周期性地围绕一颗大到足以阻挡可检测到的星光部分的恒星旋转的物体被定义为行星。从星光中发现系外行星需要在较长的时间间隔内测量光的波动。由于光线的变化通常非常微小,因此很难确定系外行星是否真的存在。
在本章中,我们将通过 XGBoost 预测恒星是否有系外行星。
系外行星数据集
您在第 4 章“从梯度提升到 XGBoost ”中预览了 Exoplanet 数据集,以揭示XGBoost 具有针对大型数据集的可比集成方法。在本章中,我们将深入研究 Exoplanet 数据集。
这个系外行星数据集取自NASA 开普勒太空望远镜,Campaign 3,2016年夏季。有关信息数据源可在 Kaggle 上https://www.kaggle.com/keplesmachines/kepler-labelled-time-series-data获得。在数据集中的所有恒星中,有 5,050 颗没有系外行星,而 37 颗有系外行星。
300 多列和 5,000 多行等于 150 万个以上的条目。乘以 100 个 XGBoost 树,就是 1.5 亿个数据点。为了加快处理速度,我们从数据的一个子集开始。在处理大型数据集时,从子集开始是一种常见的做法,以节省时间。
pd.read_csv包含一个nrows参数,用于限制行数。请注意,nrows=n选择数据集的前n行。根据数据结构,可能需要额外的代码来确保子集代表整体。让我们开始吧。
导入pandas ,然后使用nrows=400加载exoplanets.csv。然后查看数据:
import pandas as pd
df = pd.read_csv('exoplanets.csv', nrows=400)
df.head()
输出应如下所示:
图 7.1 – 系外行星数据帧
DataFrame 下方列出的大量列 ( 3198 ) 是有意义的。在寻找光的周期性变化时,您需要足够的数据点来找到周期性。我们太阳系内行星的公转周期从 88 天(水星)到 165 年(海王星)不等。如果要检测系外行星,则必须足够频繁地检查数据点,以免在行星在恒星前方运行时错过行星的凌日。
由于只有 37 颗系外行星恒星,因此了解子集中包含多少颗系外行星恒星非常重要。
.value_counts ()方法确定特定列中每个值的数量。自从我们对LABEL栏感兴趣,可以使用以下代码找到系外行星恒星的数量:
df['LABEL'].value_counts()
输出如下:
1 363 2 37 Name: LABEL, dtype: int64
所有系外行星恒星都包含在我们的子集中。正如**.head()**所揭示的,系外行星的恒星处于开始阶段。
绘制数据
期望是当系外行星阻挡来自恒星的光时,光通量会下降。如果通量下降周期性发生,则可能是系外行星,因为根据定义,行星是围绕恒星运行的大型物体。
让我们通过图形来可视化数据:
- 导入matplotlib、numpy和seaborn,然后将seaborn设置为暗格,如下所示:
import matplotlib.pyplot as pltimport numpy as npimport seaborn as snssns.set()绘制光波动时,LABEL列不重要。LABEL列将是我们机器学习的目标列。> 小费> > 建议使用seaborn来改进您的*matplotlib**图。sns.set **()默认提供带有白色网格的漂亮浅灰色背景。此外,许多标准图表,例如plt.hist()*,在这个 Seaborn 默认设置下看起来更美观。更多有关 Seaborn 的信息,请查看seaborn: statistical data visualization — seaborn 0.12.0 documentation。 - 现在,让我们将数据拆分为X预测列(我们将绘制图表)和y目标列。请注意,对于 Exoplanet 数据集,目标列是第一列,而不是最后一列:
X = df.iloc[:,1:]y = df.iloc[:,0] - 现在写一个名为light_plot的函数,它将数据的索引(行)作为输入,将所有数据点绘制为y坐标(光通量),并将观察数作为x坐标。为图形使用适当的标签,如下所示:
def light_plot(index): y_vals = X.iloc[index] x_vals = np.arange(len(y_vals)) plt.figure(figsize=(15,8)) plt.xlabel('Number of Observations') plt.ylabel('Light Flux') plt.title('Light Plot ' + str(index), size=15) plt.plot(x_vals, y_vals) plt.show() - 现在,调用函数来绘制第一个索引。这颗恒星已被归类为系外行星:
light_plot(0)这是我们第一个光图的预期图表: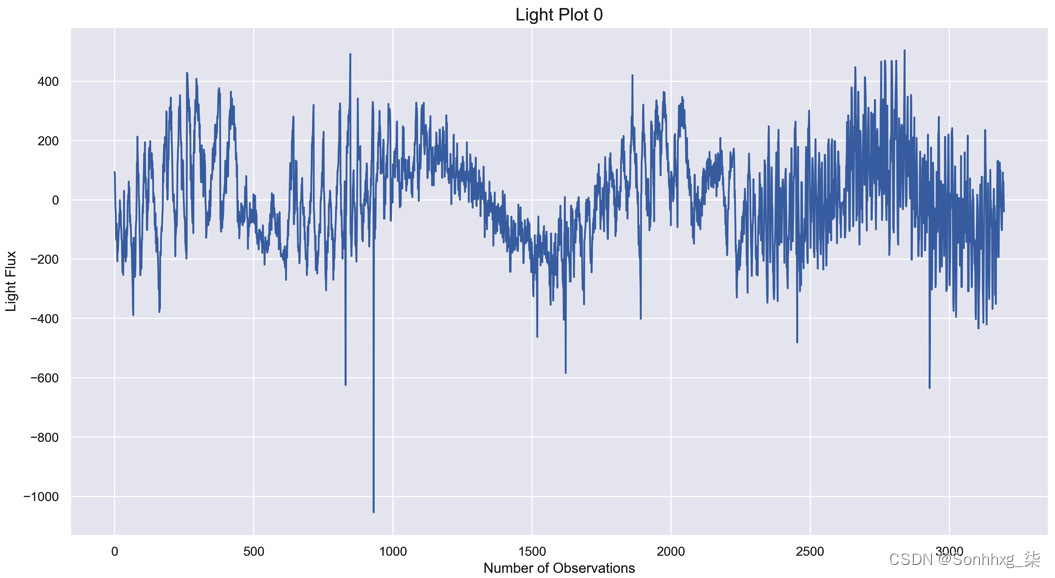 图 7.2 – 光照图 0. 存在周期性的光照下降有明确的定期发生的数据下降。然而,仅从这张图表中就不能明显得出存在系外行星的结论。
图 7.2 – 光照图 0. 存在周期性的光照下降有明确的定期发生的数据下降。然而,仅从这张图表中就不能明显得出存在系外行星的结论。 - 相比之下,将此图与第 37个索引(数据集中的第一个非系外行星恒星)进行对比:
light_plot(37)这是第 37个指数的预期图表: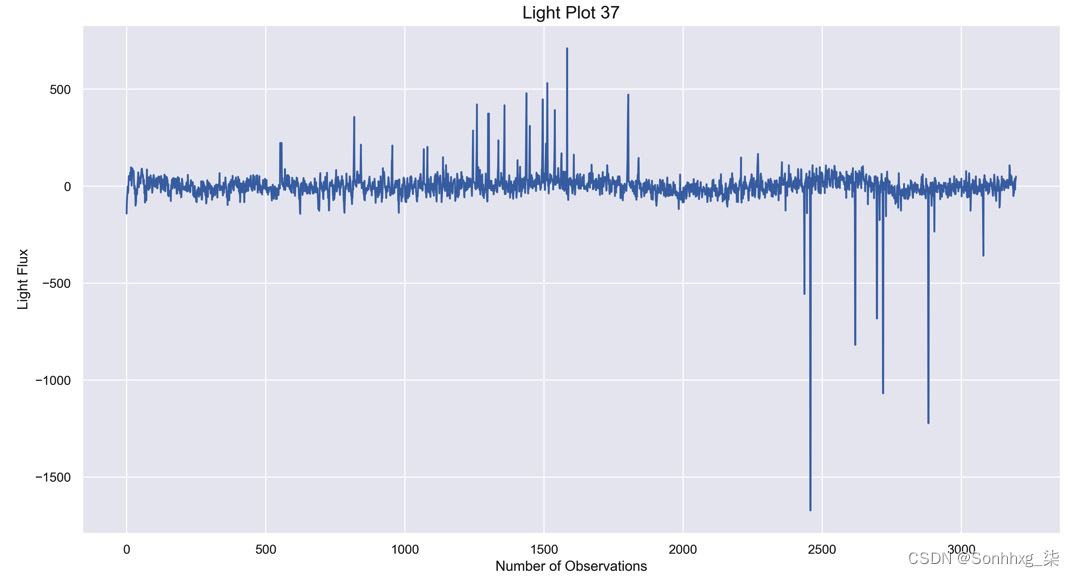 图 7.3 – 光照图 37增加和光的减少是存在的,但不是在整个范围内。数据中有明显的下降,但在整个图表中它们不是周期性的。滴的频率不会始终如一地重复。仅基于这些证据,还不足以确定系外行星的存在。
图 7.3 – 光照图 37增加和光的减少是存在的,但不是在整个范围内。数据中有明显的下降,但在整个图表中它们不是周期性的。滴的频率不会始终如一地重复。仅基于这些证据,还不足以确定系外行星的存在。 - 这是系外行星恒星的第二个光图:
light_plot(1)这是第一个索引的预期图表: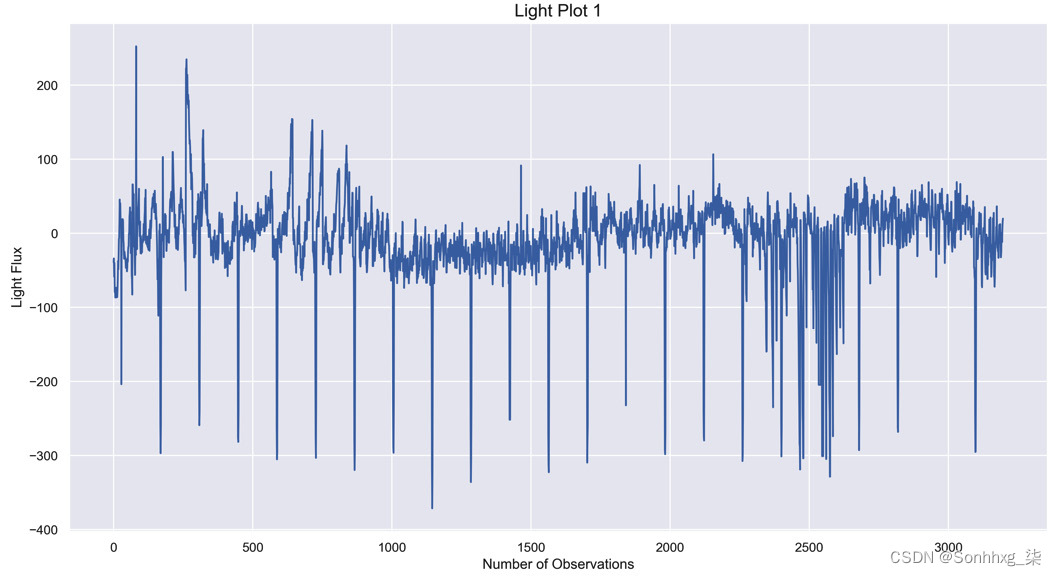
图 7.4 – 明显的周期性下降表明存在系外行星
该图显示了明显的周期性,光通量大幅下降,极有可能是系外行星!如果所有的情节如此清晰,机器学习将是不必要的。正如其他情节所揭示的那样,得出系外行星存在的结论通常并不那么清楚。
此处的目的是突出数据和仅基于视觉图对系外行星进行分类的难度。天文学家使用不同的方法对系外行星进行分类,机器学习就是这样一种方法。
虽然这个数据集是一个时间序列,但目标不是预测下一个单位时间的光通量,而是根据所有数据对恒星进行分类。在这方面,机器学习分类器可用于预测给定恒星是否拥有系外行星。这个想法是在提供的数据上训练分类器,这反过来又可以用来预测新数据上的系外行星。在本章中,我们尝试使用XGBClassifier对数据中的系外行星进行分类。在我们继续对数据进行分类之前,我们必须首先准备数据。
准备数据
我们见证了在上一节指出,并非所有图表都足够清晰,可以确定系外行星的存在。这就是机器学习可能大有裨益的地方。首先,让我们为机器学习准备数据:
- 首先,我们需要数据集是数字的,没有空值。**使用df.info()**检查数据类型和空值:
df.info()这是预期的输出:<class 'pandas.core.frame.DataFrame'>RangeIndex: 400 entries, 0 to 399Columns: 3198 entries, LABEL to FLUX.3197dtypes: float64(3197), int64(1)memory usage: 9.8 MB该子集包含 3,197 个浮点数和 1 个整数,因此所有列都是数字的。由于列数众多,未提供有关空值的信息。 - 我们可以在 .null() 上使用**.sum()**方法两次对所有空值求和,一次对每列中的空值求和,第二次对所有列求和:
df.isnull().sum().sum()预期输出如下:0
由于没有空值并且数据是数字的,我们将继续进行机器学习。
初始 XGBClassifier
开始构建一个初始 XGBClassifier,执行以下步骤:
- 导入XGBClassifier和accuracy_score:
from xgboost import XGBClassifier from sklearn.metrics import accuracy_score - 将模型拆分为训练和测试集:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2) - 使用booster='gbtree'、objective='binary:logistic'和random_state=2作为参数构建和评分模型:
model = XGBClassifier(booster='gbtree', objective='binary:logistic', random_state=2)model.fit(X_train, y_train)y_pred = model.predict(X_test)score = accuracy_score(y_pred, y_test)print('Score: ' + str(score))分数如下:Score: 0.89
正确分类 89% 的恒星似乎是一个很好的起点,但有一个明显的问题。
你能弄清楚吗?
想象一下,您将您的模型展示给您的天文学教授。假设你的教授在数据分析方面训练有素,你的教授会回答:“我看到你获得了 89% 的准确率,但系外行星代表了 10% 的数据,所以你怎么知道你的结果并不比一个模型好? 100% 的时间预测没有系外行星?”
问题就在于此。如果模型确定没有恒星包含系外行星,其准确度将约为 90%,因为 10 颗恒星中有 9 颗不包含系外行星。
对于不平衡的数据,准确性是不够的。
分析混淆矩阵
混淆矩阵是一个表格,总结了分类模型的正确和错误预测。这混淆矩阵是分析不平衡数据的理想选择,因为它提供了更多关于哪些预测是正确的,哪些预测是错误的信息。
对于 Exoplanet 子集,这是完美混淆矩阵的预期输出:
array([[88, 0],
[ 0, 12]])
当所有正条目都在左对角线上时,该模型具有 100% 的准确度。这里的完美混淆矩阵预测了 88 颗非系外行星恒星和 12 颗系外行星恒星。请注意,混淆矩阵不提供标签,但在这种情况下,可以根据大小推断标签。
在深入细节之前,让我们看看使用 scikit-learn 的实际混淆矩阵。
混淆矩阵
从sklearn.metrics导入confusion_matrix作为如下:
from sklearn.metrics import confusion_matrix
以y_test和y_pred作为输入(在上一节中获得的变量)运行混淆矩阵,确保将y_test放在首位:
confusion_matrix(y_test, y_pred)
输出如下:
array([[86, 2],
[9, 3]])
混淆矩阵对角线上的数字显示了86个正确的非系外行星恒星预测和只有3 个正确的系外行星恒星预测。
在矩阵的右上角,数字2表明两颗非系外行星恒星被错误分类为系外行星恒星。同样,在矩阵的左下角,数字9表明9颗系外行星恒星被错误分类为非系外行星恒星。
水平分析时,88 颗非系外行星中有 86 颗被正确分类,而 12 颗系外行星中只有 3 颗被正确分类。
如您所见,混淆矩阵揭示了模型预测的重要细节,而准确性分数无法获得。
classification_report
各种种类上一节混淆矩阵中显示的数字的百分比包含在分类报告中。我们来看分类报告:
- 从sklearn.metrics导入分类报告:
from sklearn.metrics import classification_report - 将y_test和y_pred放在clasification_report中,确保将y_test放在首位。然后将分类报告放在全局打印函数中,以保持输出对齐且易于阅读:
print(classification_report(y_test, y_pred))这是预期的输出:precision recall f1-score support 1 0.91 0.98 0.94 88 2 0.60 0.25 0.35 12 accuracy 0.89 100 macro avg 0.75 0.61 0.65 100weighted avg 0.87 0.89 0.87 100
理解前面分数的含义很重要,所以让我们一次复习一下。
Precision
精度给出了对实际正确的正例 (2s) 的预测。它在技术上是根据真阳性和假阳性来定义的。
真阳性
这里有一个真阳性的定义和例子:
- 定义——正确预测为正的标签数量。
- 示例 – 2s 被正确预测为 2s。
误报
这是一个定义和误报的例子:
- 定义——被错误预测为负的正标签的数量。
- 示例 – 对于系外行星恒星,2s 被错误地预测为 1s。
精度的定义最常被提及数学电子表格如下:
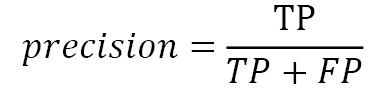
这里TP代表真阳性,FP代表假阳性。
在 Exoplanet 数据集,我们有以下两种数学形式: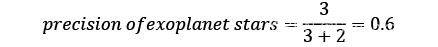
和
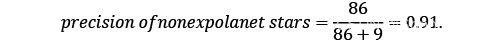
精度给出了每个目标类别的正确预测百分比。现在让我们回顾一下分类报告显示的其他关键评分指标。
Recall
召回为您提供您的预测发现的阳性病例的百分比。召回率是真阳性数除以真阳性加假阴性。
假阴性
这是一个定义和假阴性的例子:
- 定义 – 错误预测为负数的标签数量。
- 示例 – 对于系外行星恒星预测,2s 被错误地预测为 1s。
我n 数学形式,如下所示:
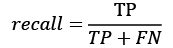
这里TP代表真阳性,FN代表假阴性。
在 the Exoplanet 数据集,我们有以下内容:
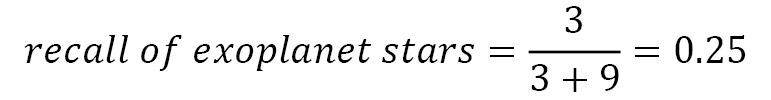
和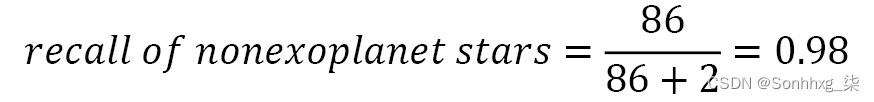
召回告诉您发现了多少阳性病例。在系外行星的案例中,只有 25% 的系外行星被发现。
F1 score
F1 分数是准确率和召回率之间的调和平均值。使用调和平均值是因为准确率和召回率基于不同的分母,调和平均值使它们变得均匀。当准确率和召回率同等重要时,F1 分数最好。请注意,F1 分数的范围是从 0 到 1,其中 1 是最高的。
替代评分方法
精度、召回率和 F1 分数是 scikit-learn 提供的替代评分方法。可以在3.3. Metrics and scoring: quantifying the quality of predictions — scikit-learn 1.1.2 documentation的官方文档中找到标准评分方法的列表。
小费
准确性通常不是分类数据集的最佳选择。另一种流行的评分方法是roc_auc_score,即接收算子特征曲线下的面积。与大多数分类评分方法一样,越接近 1,结果越好。有关更多信息,请参阅sklearn.metrics.roc_auc_score — scikit-learn 1.1.2 documentation。
在选择计分方法时,了解目标至关重要。Exoplanet 数据集中的目标是寻找系外行星。这是显而易见的。不明显的是如何选择最好的评分方法来达到预期的结果。
想象两种不同的场景:
- 场景 1:在机器学习模型预测的 4 颗系外行星恒星中,有 3 颗实际上是系外行星恒星:3/4 = 75% 精度。
- 场景 2:在 12 颗系外行星恒星中,模型正确预测了 8 颗系外行星恒星(8/12 = 66% 召回率)。
哪个更可取?
答案是视情况而定。召回是标记潜在阳性病例(系外行星)以找到所有病例的理想选择。精度是确保预测(系外行星)确实是积极的理想选择。
天文学家不太可能仅仅因为机器学习模型这么说就宣布发现了系外行星。他们更有可能在根据其他证据确认或反驳这一说法之前仔细检查潜在的系外行星恒星。
假设机器学习模型的目标是找到尽可能多的系外行星,召回是一个很好的选择。为什么?回忆告诉我们 12 颗系外行星中有多少颗已被发现(2/12、5/12、12/12)。让我们试着找到它们。
精密笔记
更高的精度百分比并不表示有更多的系外行星恒星。例如,1/1 的召回率是 100%,但它只能找到一颗系外行星。
recall_score
如前文所述部分,我们将继续使用召回作为 Exoplanet 数据集的评分方法,以找到尽可能多的系外行星。让我们开始:
- 从sklearn.metrics导入recall_score:
from sklearn.metrics import recall_score默认情况下,recall_score报告正类的召回分数,通常标记为1。正类被标记为2而负类被标记为1是不寻常的,就像 Exoplanet 数据集的情况一样。 - 要获得系外行星恒星的recall_score值,请输入y_test和y_pred作为recall_score 的参数以及pos_label =2:
recall_score(y_test, y_pred, pos_label=2)系外行星的得分如下:0.25
这与分类报告在召回分数2下给出的百分比相同,即系外行星恒星。展望未来,我们将不使用accuracy_score ,而是使用****recall_score和前面的参数作为我们的评分指标。
接下来,让我们了解重采样,这是提高不平衡数据集分数的重要策略。
重采样不平衡数据
现在我们有一个发现系外行星的合适评分方法,是时候探索重采样、欠采样和过采样等策略来纠正导致低召回分数的不平衡数据。
重采样
一种策略抵消不平衡数据是对数据进行重新采样。可以通过减少多数类的行来对数据进行欠采样,并通过重复少数类的行来对数据进行过采样。
欠采样
我们的探索首先从 5,087 行中选择 400 行。这是一个欠采样的示例,因为子集包含的行数少于原始行数。
让我们编写一个函数,允许我们对任意行数的数据进行欠采样。这个函数应该返回召回分数,以便我们可以看到欠采样如何改变结果。我们将从评分功能开始。
评分功能
以下函数将 XGBClassifier 和行数作为输入,并生成混淆矩阵、分类报告和系外行星的召回分数作为输出。
以下是步骤:
- 定义一个函数xgb_clf,它将model(机器学习模型)和nrows(行数)作为输入:
def xgb_clf(model, nrows): - 使用nrows加载 DataFrame ,然后将数据拆分为X和y以及训练和测试集:
df = pd.read_csv('exoplanets.csv', nrows=nrows) X = df.iloc[:,1:] y = df.iloc[:,0] X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2) - 初始化模型,将模型拟合到训练集,并使用y_test、y_pred和pos_label=2(recall_score)作为输入使用测试集对其进行评分:
model.fit(X_train, y_train) y_pred = xg_clf.predict(X_test) score = recall_score(y_test, y_pred, pos_label=2) - 打印混淆矩阵和分类报告,并返回分数:
print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred)) return score
现在,我们可以对行数进行欠采样,看看分数如何变化。
欠采样
开始吧通过将nrows加倍到800。这仍然是欠采样,因为原始数据集有5087行:
xgb_clf(XGBClassifier(random_state=2), nrows=800)
这是预期的输出:
[[189 1]
[ 9 1]]
precision recall f1-score support
1 0.95 0.99 0.97 190
2 0.50 0.10 0.17 10
accuracy 0.95 200
macro avg 0.73 0.55 0.57 200
weighted avg 0.93 0.95 0.93 200
0.1
尽管对非系外行星恒星进行了近乎完美的召回,但混淆矩阵显示,10 颗系外行星中只有 1 颗被召回。
接下来,将nrows从400减少到200:
xgb_clf(XGBClassifier(random_state=2), nrows=200)
这是预期的输出:
[[37 0]
[ 8 5]]
precision recall f1-score support
1 0.82 1.00 0.90 37
2 1.00 0.38 0.56 13
accuracy 0.84 50
macro avg 0.91 0.69 0.73 50
weighted avg 0.87 0.84 0.81 50
这个好一点。通过减少n_rows,召回率上升。
让我们看看什么如果我们精确地平衡类,就会发生。由于有 37 颗系外行星恒星,37 颗非系外行星恒星平衡了数据。
使用nrows=74运行xgb_clf函数:
xgb_clf(XGBClassifier(random_state=2), nrows=74)
这是预期的输出:
[[6 2]
[5 6]]
precision recall f1-score support
1 0.55 0.75 0.63 8
2 0.75 0.55 0.63 11
accuracy 0.63 19
macro avg 0.65 0.65 0.63 19
weighted avg 0.66 0.63 0.63 19
0.5454545454545454
这些结果是可观的,即使子集要小得多。
接下来,让我们看看是什么当我们应用过采样策略时会发生这种情况。
过采样
另一种重采样技术是过采样。过采样不是消除行,而是通过复制和重新分配阳性病例。
虽然原始数据集有超过 5,000 行,但我们继续使用nrows=400作为我们加快流程的起点。
当nrows=400时,正例与负例的比率为 10 比 1。我们需要 10 倍的正例才能获得平衡。
我们的策略如下:
- 创建一个复制阳性案例九次的新 DataFrame。
- 将新的 DataFrame 与原始 DataFrame 连接以获得 10-10 的比率。
在继续之前,需要发出警告。如果数据在分成训练集和测试集之前被重新采样,召回分数将被夸大。你能看出为什么吗?
重采样时,阳性病例一式九份。将此数据拆分为训练集和测试集后,副本可能包含在两个集中。因此,测试集将包含大部分与训练集相同的数据点。
适当的策略是先将数据拆分为训练和测试集,然后再对数据进行重新采样。如前所述,我们可以使用X_train、X_test、y_train和y_test。开始吧:
- 用pd.merge合并左右索引上的X_train和y_train如下:
df_train = pd.merge(y_train, X_train, left_index=True, right_index=True) - 使用np.repeat创建一个 DataFrame,new_df ,其中包括以下内容:a) 正例的值:df_train[df_train['LABEL']==2.values。b) 份数——在本例中为9c) axis=0参数指定我们正在使用列:
new_df = pd.DataFrame(np.repeat(df_train[df_train['LABEL']==2].values,9,axis=0)) - 复制列名:
new_df.columns = df_train.columns - 连接数据框:
df_train_resample = pd.concat([df_train, new_df]) - 验证value_counts是否符合预期:
df_train_resample['LABEL'].value_counts()预期输出如下:1.0 2752.0 250Name: LABEL, dtype: int64 - 使用重新采样的 DataFrame拆分X和y :
X_train_resample = df_train_resample.iloc[:,1:]y_train_resample = df_train_resample.iloc[:,0] - 在重新采样的训练集上拟合模型:
model = XGBClassifier(random_state=2)model.fit(X_train_resample, y_train_resample) - 使用X_test和y_test对模型进行评分。在结果中包含混淆矩阵和分类报告:
y_pred = model.predict(X_test)score = recall_score(y_test, y_pred, pos_label=2)print(confusion_matrix(y_test, y_pred))print(classification_report(y_test, y_pred))print(score)这分数如下:[[86 2][ 8 4]] precision recall f1-score support 1 0.91 0.98 0.95 88 2 0.67 0.33 0.44 12 accuracy 0.90 100 macro avg 0.79 0.66 0.69 100weighted avg 0.89 0.90 0.88 1000.3333333333333333
通过适当地保留一个测试集,过采样达到了 33.3% 的召回率,这个分数是之前获得的 17% 的两倍,尽管仍然太低了。
小费
SMOTE是一个流行的重采样库,可以从imblearn**导入,必须下载才能使用。我使用前面的重采样代码获得了与 SMOTE 相同的结果。
自从重采样充其量只能产生适度的收益,是时候调整 XGBoost 的超参数了。
调整和缩放 XGBClassifier
在本节中,我们将微调和缩放 XGBClassifier 以获得Exoplanets 数据集的最佳召回分数值。首先,您将使用scale_pos_weight调整权重,然后您将运行网格搜索以找到超参数的最佳组合。此外,您将在合并和分析结果之前对不同数据子集的模型进行评分。
调整权重
在第 5 章XGBoost Unveiled中,您使用了scale_pos_weight超参数来抵消希格斯玻色子数据集中的不平衡。Scale_pos_weight是一个用于缩放正权重的超参数。这里强调正值很重要,因为 XGBoost 假设目标值1是正值,目标值0是负值。
在 Exoplanet 数据集中,我们一直使用数据集提供的默认1作为负数和2作为正数。我们现在将使用**.replace()方法切换到0作为负数和1**作为正数。
代替
可以使用.replace ()方法重新分配值。以下代码将LABEL列中的1替换为0,将2替换为1 :
df['LABEL'] = df['LABEL'].replace(1, 0)
df['LABEL'] = df['LABEL'].replace(2, 1)
如果将两行代码颠倒过来,所有列的值都会以 0 结束,因为所有的 2 都会变成 1,然后所有的 1 都会变成 0。在编程中,顺序很重要!
使用value_counts方法验证计数:
df['LABEL'].value_counts()
这是预期的输出:
0 363
1 37
Name: LABEL, dtype: int64
阳性病例现在标记为1,阴性病例标记为0。
scale_pos_weight
是时候了用scale_pos_weight=10构建一个新的XGBClassifier来解决数据中的不平衡问题:
- 将新的 DataFrame 拆分为X(预测列)和y(目标列):
X = df.iloc[:,1:]y = df.iloc[:,0] - 将数据拆分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2) - 使用scale_pos_weight=10构建、拟合、预测和评分XGBClassifier。打印出混淆矩阵和分类报告,查看完整结果:
model = XGBClassifier(scale_pos_weight=10, random_state=2)model.fit(X_train, y_train)y_pred = model.predict(X_test)score = recall_score(y_test, y_pred)print(confusion_matrix(y_test, y_pred))print(classification_report(y_test, y_pred))print(score)这是预期的输出:[[86 2][ 8 4]] precision recall f1-score support 0 0.91 0.98 0.95 88 1 0.67 0.33 0.44 12 accuracy 0.90 100 macro avg 0.79 0.66 0.69 100weighted avg 0.89 0.90 0.88 1000.3333333333333333
结果与我们上一节的重采样方法相同。
这我们从头开始实现的过采样方法给出了与带有scale_pos_weight的****XGBClassifier相同的预测。
调整 XGBClassifier
是时候看看了超参数微调是否可以提高精度。
在微调超参数时使用GridSearchCV和RandomizedSearchCV是标准的。两者都需要对两个或多个折叠进行交叉验证。我们尚未实施交叉验证,因为我们的初始模型表现不佳,并且在大型数据集上测试多个折叠的计算成本很高。
一种平衡的方法是使用两折的GridSearchCV和RandomizedSearchCV以节省时间。为确保结果一致,StratifiedKFold(第 6 章,XGBoost 超参数)是推荐的。我们将从基线模型开始。
基线模型
以下是构建一个实现与网格搜索相同的 k 折交叉验证的基线模型:
- 导入GridSearchCV、RandomizedSearchCV、StratifiedKFold和cross_val_score:
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV, StratifiedKFold, cross_val_score - 使用n_splits=2和shuffle=True 将****StratifiedKFold初始化为kfold:
kfold = StratifiedKFold(n_splits=2, shuffle=True, random_state=2) - 使用scale_pos_weight=10初始化XGBClassifier ,因为负例的数量是正例的 10 倍:
model = XGBClassifier(scale_pos_weight=10, random_state=2) - 使用cv=kfold和score='recall'作为参数的****cross_val_score对模型进行评分,然后显示分数:
scores = cross_val_score(model, X, y, cv=kfold, scoring='recall')print('Recall: ', scores)print('Recall mean: ', scores.mean())分数如下:Recall: [0.10526316 0.27777778]Recall mean: 0.1915204678362573
交叉验证的分数稍差。当阳性病例很少时,它使哪些行最终在训练和测试集中的差异。StratifiedKFold和train_test_split的不同实现可能会导致不同的结果。
网格搜索
现在好了实现第 6 章XGBoost超参数中的grid_search函数的变体,以微调超参数:
- 新函数采用与输入相同的参数字典,以及使用RandomizedSearchCV的随机选项。此外,X和y作为默认参数提供给其他子集,评分方法如下:
def grid_search(params, random=False, X=X, y=y, model=XGBClassifier(random_state=2)): xgb = model if random: grid = RandomizedSearchCV(xgb, params, cv=kfold, n_jobs=-1, random_state=2, scoring='recall') else: grid = GridSearchCV(xgb, params, cv=kfold, n_jobs=-1, scoring='recall') grid.fit(X, y) best_params = grid.best_params_ print("Best params:", best_params) best_score = grid.best_score_ print("Best score: {:.5f}".format(best_score)) - 让我们运行排除默认值的网格搜索来尝试提高分数。以下是一些初始网格搜索及其结果:a) 网格搜索 1:
grid_search(params={'n_estimators':[50, 200, 400, 800]})结果:Best params: {'n_estimators': 50}Best score: 0.19152b) 网格搜索 2:grid_search(params={'learning_rate':[0.01, 0.05, 0.2, 0.3]})结果:Best params: {'learning_rate': 0.01}Best score: 0.40351c) 网格搜索 3:grid_search(params={'max_depth':[1, 2, 4, 8]})结果:Best params: {'max_depth': 2}Best score: 0.24415d) 网格搜索 4:grid_search(params={'subsample':[0.3, 0.5, 0.7, 0.9]})结果:Best params: {'subsample': 0.5}Best score: 0.21637e) 网格搜索 5:grid_search(params={'gamma':[0.05, 0.1, 0.5, 1]})结果:Best params: {'gamma': 0.05}Best score: 0.24415 - 更改learning_rate、max_depth和gamma会带来收益。让我们尝试通过缩小范围来组合它们:
grid_search(params={'learning_rate':[0.001, 0.01, 0.03], 'max_depth':[1, 2], 'gamma':[0.025, 0.05, 0.5]})分数如下:Best params: {'gamma': 0.025, 'learning_rate': 0.001, 'max_depth': 2}Best score: 0.53509 - 这也是值得的尝试max_delta_step,XGBoost 仅推荐用于不平衡数据集。默认值为 0,增加步数会产生更保守的模型:
grid_search(params={'max_delta_step':[1, 3, 5, 7]})分数如下:Best params: {'max_delta_step': 1}Best score: 0.24415 - 作为最终策略,我们在随机搜索中将子样本与所有列样本结合起来:
grid_search(params={'subsample':[0.3, 0.5, 0.7, 0.9, 1],'colsample_bylevel':[0.3, 0.5, 0.7, 0.9, 1],'colsample_bynode':[0.3, 0.5, 0.7, 0.9, 1],'colsample_bytree':[0.3, 0.5, 0.7, 0.9, 1]}, random=True)分数如下:Best params: {'subsample': 0.3, 'colsample_bytree': 0.7, 'colsample_bynode': 0.7, 'colsample_bylevel': 1}Best score: 0.35380
代替继续这个包含400行的数据子集,让我们切换到包含74行的平衡子集(欠采样)来比较结果。
平衡子集
74行的平衡子集具有最少的数据点。它也是最快的测试。
X和y必须是明确定义,因为它们最后用于函数内的平衡子集。X_short和y_short的新定义如下:
X_short = X.iloc[:74, :]
y_short = y.iloc[:74]
经过几次网格搜索,结合max_depth和colsample_bynode得出以下结果:
grid_search(params={'max_depth':[1, 2, 3],
'colsample_bynode':[0.5, 0.75, 1]},
X=X_short, y=y_short,
model=XGBClassifier(random_state=2))
分数如下:
Best params: {'colsample_bynode': 0.5, 'max_depth': 2}
Best score: 0.65058
这是一个改进。
是时候尝试对所有数据进行超参数微调了。
微调所有数据
问题与对所有数据实现grid_search函数是时间。现在我们已经结束了,是时候运行代码并在计算机出汗时休息一下:
- 将所有数据读入一个新的 DataFrame df_all:
df_all = pd.read_csv('exoplanets.csv') - 将 1 替换为 0,将 2 替换为 1:
df_all['LABEL'] = df_all['LABEL'].replace(1, 0)df_all['LABEL'] = df_all['LABEL'].replace(2, 1) - 将数据拆分为X和y:
X_all = df_all.iloc[:,1:]y_all = df_all.iloc[:,0] - 验证**'LABEL'列的value_counts :**
df_all['LABEL'].value_counts()输出如下:0 5050 1 37 Name: LABEL, dtype: int64 - 通过将负类除以正类来缩放权重:
weight = int(5050/37) - 使用XGBClassifier和scale_pos_weight=weight为所有数据评分基线模型:
model = XGBClassifier(scale_pos_weight=weight, random_state=2)scores = cross_val_score(model, X_all, y_all, cv=kfold, scoring='recall')print('Recall:', scores)print('Recall mean:', scores.mean())这个分数太惨了。据推测,尽管召回率很低,但分类器的准确率很高。 - 让我们根据迄今为止最成功的结果尝试优化超参数:
grid_search(params={'learning_rate':[0.001, 0.01]}, X=X_all, y=y_all, model=XGBClassifier(scale_pos_weight=weight, random_state=2))这分数如下:Best params: {'learning_rate': 0.001}Best score: 0.26316这比所有数据的初始分数要好得多。让我们尝试组合超参数:grid_search(params={'max_depth':[1, 2], 'learning_rate':[0.001]}, X=X_all, y=y_all, model=XGBClassifier(scale_pos_weight=weight, random_state=2))分数如下:Best params: {'learning_rate': 0.001, 'max_depth': 2}Best score: 0.53509
这更好,尽管不如之前得分的欠采样数据集强。
随着所有数据的得分开始降低并花费更多时间,自然会出现一个问题。是机器学习模型在 Exoplanet 数据集的较小子集上更好?
让我们来了解一下。
巩固成果
这很棘手将结果与不同的数据集合并。我们一直在使用以下子集:
- 5,050 行 - 大约 54% 召回
- 400 行 - 大约 54% 召回
- 74 行 – 大约 68% 召回
获得的最佳结果包括learning_rate=0.001、 max_depth=2和colsample_bynode=0.5。
让我们在所有 37 颗系外行星上训练一个模型。这意味着测试结果将来自模型已经训练过的数据点。通常,这不是一个好主意。然而,在这种情况下,阳性病例很少,看看较小的子集如何测试它以前从未见过的阳性病例可能是有益的。
以下函数将X、y和机器学习模型作为输入。该模型适用于提供的数据,然后对整个数据集进行预测。最后,recall_score、混淆矩阵、分类报告都打印出来了:
def final_model(X, y, model):
model.fit(X, y)
y_pred = model.predict(X_all)
score = recall_score(y_all, y_pred,)
print(score)
print(confusion_matrix(y_all, y_pred,))
print(classification_report(y_all, y_pred))
让我们为三个子集中的每一个运行该函数。在三个最强的超参数中,colsample_bynode和max_depth给出了最好的结果。
让我们从行数最少,系外行星恒星和非系外行星恒星的数量匹配。
74 行
让我们从 74 行开始:
final_model(X_short, y_short,
XGBClassifier(max_depth=2, colsample_by_node=0.5, random_state=2))
输出如下:
1.0
[[3588 1462]
[ 0 37]]
precision recall f1-score support
0 1.00 0.71 0.83 5050
1 0.02 1.00 0.05 37
accuracy 0.71 5087
macro avg 0.51 0.86 0.44 5087
weighted avg 0.99 0.71 0.83 5087
所有 37 颗系外行星恒星都被正确识别,但 1,462 颗非系外行星恒星被错误分类!尽管召回率为 100%,但准确率为 2%,F1 分数为 5%。仅针对召回进行调整时,低精度和低 F1 分数是一种风险。在实践中,天文学家必须对 1,462 颗潜在的系外行星恒星进行分类才能找到 37 颗。这是不可接受的。
现在让我们看看当我们训练 400 行时会发生什么。
400 行
在 400 的情况下行,我们使用scale_pos_weight=10超参数来平衡数据:
final_model(X, y,
XGBClassifier(max_depth=2, colsample_bynode=0.5, scale_pos_weight=10, random_state=2))
输出如下:
1.0
[[4901 149]
[ 0 37]]
precision recall f1-score support
0 1.00 0.97 0.99 5050
1 0.20 1.00 0.33 37
accuracy 0.97 5087
macro avg 0.60 0.99 0.66 5087
weighted avg 0.99 0.97 0.98 5087
同样,所有 37 颗系外行星恒星都被正确分类为 100% 召回,但 149 颗非系外行星恒星被错误分类,准确率为 20%。在这种情况下,天文学家需要对 186 颗恒星进行分类才能找到 37 颗系外行星恒星。
最后,让我们对所有数据进行训练。
5,050 行
在所有的情况下数据,设置scale_pos_weight等于权重变量,如前所述:
final_model(X_all, y_all,
XGBClassifier(max_depth=2, colsample_bynode=0.5, scale_pos_weight=weight, random_state=2))
输出如下:
1.0
[[5050 0]
[ 0 37]]
precision recall f1-score support
0 1.00 1.00 1.00 5050
1 1.00 1.00 1.00 37
accuracy 1.00 5087
macro avg 1.00 1.00 1.00 5087
weighted avg 1.00 1.00 1.00 5087
惊人。所有预测、召回率和准确率都是 100% 完美的。在这种非常理想的情况下,天文学家无需筛选任何不良数据即可找到所有系外行星恒星。
但是请记住,这些分数是基于训练数据,而不是基于看不见的测试数据,后者是强制建立一个强大的模型。换句话说,尽管该模型完美地拟合了训练数据,但它不太可能很好地将其推广到新数据。然而,这些数字是有价值的。
基于这个结果,由于机器学习模型在训练集上的表现令人印象深刻,而在测试集上表现得最好,方差可能太高了。此外,可能需要更多的树和更多轮的微调来了解数据中的细微差别。
分析结果
当得分在在训练集上,调整后的模型提供了完美的召回率,但精度差异很大。以下是要点:
- 使用没有召回的精度或 F1 分数可能会导致模型不理想。通过使用分类报告,可以揭示更多细节。
- 不建议过分强调小子集的高分。
- 当测试分数较低但在不平衡数据集上的训练分数较高时,建议使用具有广泛超参数微调的更深层次的模型。
Kaggle 用户在https://www.kaggle.com/keplersmachines/kepler-labelled-time-series-data/kernels上针对 Exoplanet 数据集提出的内核、公开展示的笔记本的调查显示以下内容:
- 许多用户无法理解,高精度分数很容易获得,并且对于高度不平衡的数据几乎毫无意义。
- 用户发帖准确率一般在 50% 到 70% 之间,发布召回率的用户发布 60% 到 100%(召回率为 100% 的用户有 55% 的准确率),这表明该数据集的挑战和局限性。
当你向你的天文学教授展示你的结果时,更明智地意识到不平衡数据的局限性,你得出的结论是,你的模型最多只能有 70% 的召回率,而且 37 颗系外行星不足以建立一个强大的机器学习模型来寻找生命其他行星。然而,您的 XGBClassifier 将允许天文学家和其他接受过数据分析培训的人员使用机器学习来决定在宇宙中关注哪些恒星,以发现轨道上的下一个系外行星。
概括
在本章中,您使用 Exoplanet 数据集调查了宇宙,以发现新行星和潜在的新生命。您构建了多个 XGBClassifier 来预测系外行星恒星何时是光的周期性变化的结果。只有 37 颗系外行星恒星和 5,050 颗非系外行星恒星,您通过欠采样、过采样和调整 XGBoost 超参数(包括scale_pos_weight )来纠正不平衡数据。
您使用混淆矩阵和分类报告分析了结果。您了解了各种分类评分指标之间的关键差异,以及为什么 Exoplanet 数据集的准确性几乎毫无价值,而高召回率是理想的,尤其是与高精度相结合以获得良好的 F1 分数时。最后,当数据极其多样化和不平衡时,您意识到机器学习模型的局限性。
在本案例研究之后,您将具备必要的背景和技能,可以使用 XGBoost 使用scale_pos_weight、超参数微调和替代分类评分指标来全面分析不平衡数据集。
在下一章中,您将通过在梯度提升树之外应用替代 XGBoost 基础学习器来极大地扩展您的 XGBoost 范围。虽然梯度提升树通常是最好的选择,但 XGBoost 配备了线性基础学习器、飞镖基础学习器,甚至随机森林,接下来都会出现!
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。