
惭愧惭愧!机器学习中的数学原理这个专栏已经很久没有更新了!前段时间一直在学习深度学习,paddlepaddle,刷题专栏跟新了,这个专栏就被打入冷宫了。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《白话机器学习中的数学——模型评估与交叉验证》!
文章目录
一、什么是模型评估
简单的讲,模型评估就是评估训练好的模型的好坏。
在进行回归和分类时,为了进行预测,我们定义了函数 fθ(x),然后根据训练数据求出了函数的参数 θ。也就是对目标函数进行微分,然后求出参数更新表达式的操作,当时我们求出参数更新表达式之后就结束了。
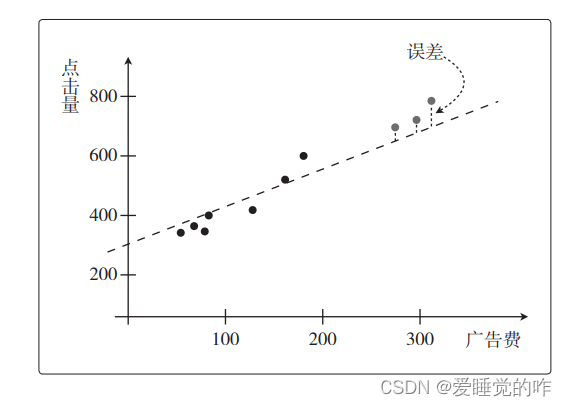
但是,其实我们真正想要的是通过预测函数得到预测值。以回归的那个例子来说,就是关于投入的广告费能带来多少点击量的预测值。所以我们希望 fθ(x)对未知数据 x 输出的预测值尽可能正确。那我们如何测量预测函数 fθ(x)的正确性,也就是精度呢?对于一个变量的问题,我可以用图直观的表示出来:
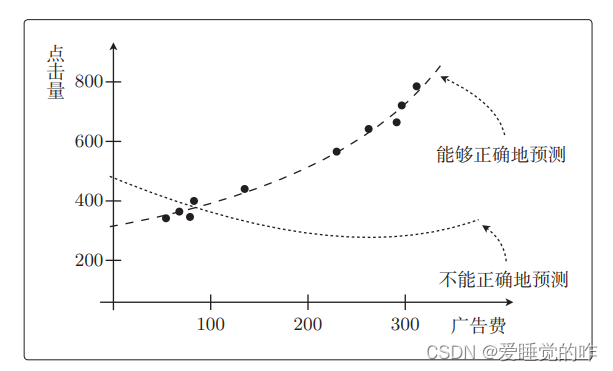 像多重回归这样的问题,变量增加后就不能在图上展示了,而且特意去画图也很麻烦。所以我们需要能够定量地表示机器学习模型的精度。
像多重回归这样的问题,变量增加后就不能在图上展示了,而且特意去画图也很麻烦。所以我们需要能够定量地表示机器学习模型的精度。
接下来我们就要考虑评估模型的方法。
二、交叉验证
验证是指的在机器学习模型训练时对模型好坏程度的衡量。交叉验证就是一种常用的模型选择方法,使用部分数据集进行验证模型的有效性。
2.1回归问题的交叉验证
把获取的全部训练数据分成两份:一份用于测试,一份用于训练。然后用前者来评估模型。也就是说假如有 10 个训练数据,那么实际上会按照 5 个测试数据、5 个训练数据来分配它们,但是比起 5 : 5,大多数情况会采用 3 : 7 或者 2 : 8 这种训练数据更多的比例。
我们接下来用3 个用于测试、7 个用于训练。也就是说,关于点击量预测的回归问题,我们现在有 10 个数据,其中测试数据和训练数据是这样分配的:
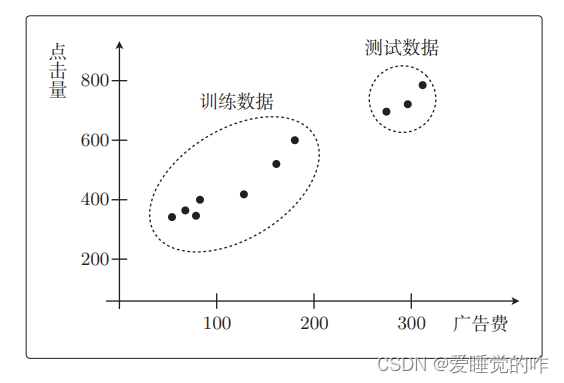 右侧的 3 个是测试数据、左侧的 7 个是训练数据。首先,我们来考虑使用左侧这 7 个数据来训练参数的情况。用一次函数
右侧的 3 个是测试数据、左侧的 7 个是训练数据。首先,我们来考虑使用左侧这 7 个数据来训练参数的情况。用一次函数
f
θ
(
x
)
=
θ
0
+
θ
1
x
∗
f_{\boldsymbol{\theta}}(\boldsymbol{x})=\theta_0+\theta_1 x^*
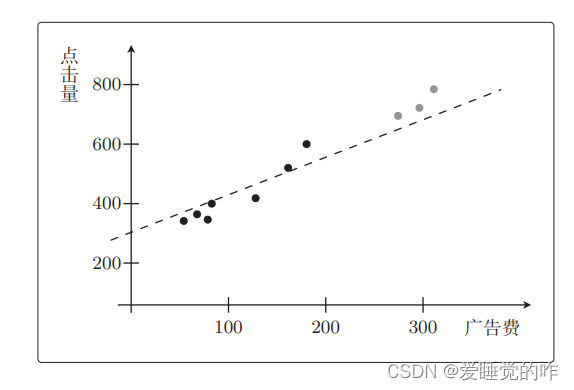
fθ(x)=θ0+θ1x∗表示即可。先从一次函数开始考虑比较好。先不去管测试数据,只看那7个训练数据。一次拟合函数大概如下:
再考虑二次函数:
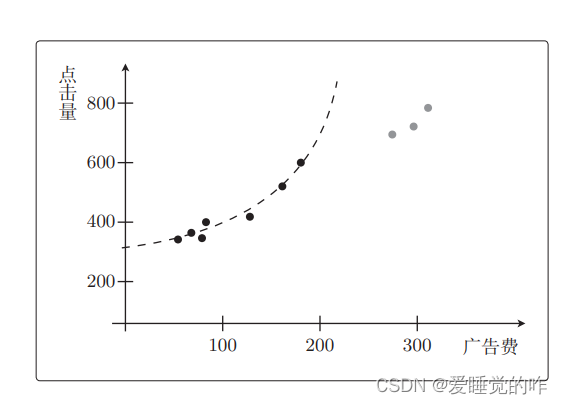
如果 fθ(x)是二次函数,那它基本上就是这个形状。但是这个函数“只有对训练数据才是正确的”,对于测试集的预测效果很差。也就是说如果只看训练数据,那么二次函数比一次函数拟合得更好。
但是,如果将测试数据也考虑进来,那么二次函数就完全不行了。要把测试数据当作未知数据来考虑。即使模型相同,如果训练数据过少,这种现象也会发生。那么在训练结束之后,我们还得像这样检查一下测试数据是否也拟合,但是如果变量增加,就不能画图了。就算能画图,也会很麻烦。
对于回归的情况,只要在训练好的模型上计算测试数据的误差的平方,再取其平均值就可以了。假设测试数据有 n 个,那么可以这样计算。
1
n
∑
i
=
1
n
(
y
(
i
)
−
f
θ
(
x
(
i
)
)
)
2
\frac{1}{n} \sum_{i=1}^n\left(y^{(i)}-f_{\boldsymbol{\theta}}\left(\boldsymbol{x}^{(i)}\right)\right)^2
n1∑i=1n(y(i)−fθ(x(i)))2
对于预测点击量的回归问题来说,y(i) 就是点击量,而 x(i) 是广告费或广告版面的大小,这个值被称为均方误差或者 MSE,全称 Mean Square Error。这个误差越小,精度就越高,模型也就越好。
回归的目标函数也是误差函数,这与为了让误差函数的值变小而更新参数时所做的事情是一样的!
2.2分类问题的验证
与回归的时候一样,我们先考虑数据的分配。
数据的分配方法不要太极端其实会更好”这一点与回归的时候也是一样的。假设在逻辑回归的情况下,θTx 是简单的一次函数,那么只根据训练数据进行训练后,决策边界应该是这样的: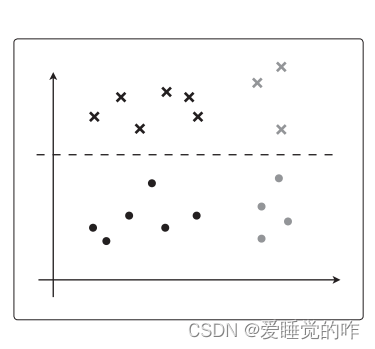
但是假如θTx 更加复杂,可能就会像这样紧贴着训练数据进行分类: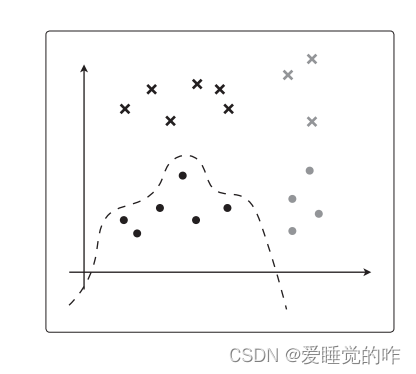
可以看到可以对训练数据完美地进行分类,却完全忽视了测试数据。对于分类有别的指标。由于回归是连续值,所以可以从误差入手,但是在分类中我们必须要考虑分类的类别是否正确。在回归中要考虑的是答案不完全一致时的误差,而分类中要考虑的是答案是否正确。
我们对图像是横向的还是纵向的进行了分类,我们是根据图像为横向的概率来分类的。关于分类是否成功就会有下面 4 种情况:
- 图像是横向的,被正确分类了
- 图像被分类为横向,但实际上不是横向的
- 图像不是横向的,被正确分类了
- 图像被分类为非横向,但实际上是横向的
把它整理到这样的表里: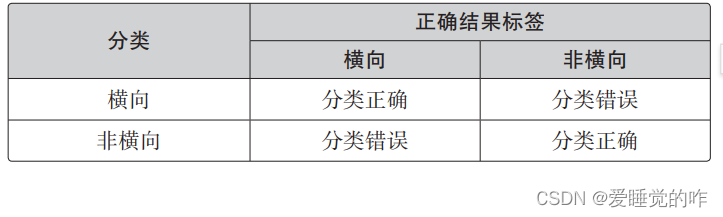
设横向的情况为正、非横向的情况为负,那么一般来说,二分类的结果可以用这张表来表示: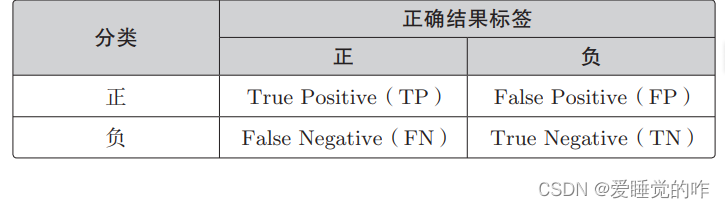
分类结果为正的情况是 Positive、为负的情况是 Negative。分类成功为 True、分类失败为 False。我们可以使用表里的 4 个记号来计算分类的精度。精度的英文是 Accuracy,它的计算表达式是这样的: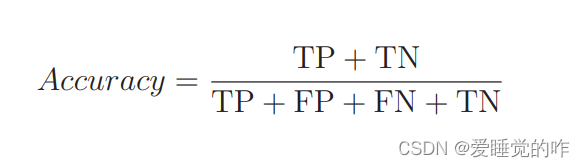
它表示的是在整个数据集中,被正确分类的数据 TP 和 TN 所占的比例。假如 100 个数据中 80 个被正确地分类了,那么精度就是这样的: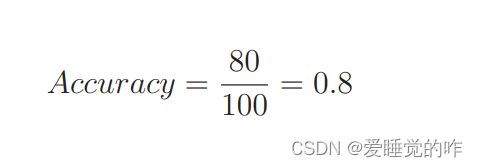
用测试数据来计算这个值,值越高精度越高,也就意味着模型越好!
版权归原作者 爱睡觉的咋 所有, 如有侵权,请联系我们删除。