
获取数据集
工具整合包来源
【AI翻唱/SoVITS 4.0】手把手教你老婆唱歌给你听~无需配置环境的本地训练/推理教程[懒人整合包]_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1H24y187Ko/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=bd7513aedfc5a6d9d2da276ca29e3cb5
音频来源
QQ音乐-HQ高品质下载
zutomayo的歌曲列表
- Dear Mr [F]
去和声、混响、切片按上面教程来就好了
已得到数据集
本地硬件水平有限,上云端GPU服务器训练
【so-vits-svc】手把手教你老婆唱歌_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1vM4y1S7zB/?vd_source=bd7513aedfc5a6d9d2da276ca29e3cb5
AutoDL上选一个好显卡,镜像为up的改进版(加了webui和补充了很多注释)
资源清单
显卡:A5000,cuda版本11.6
镜像:so-vits-svc-webui
按readme.ipynb步骤走,最后开始训练
开始训练
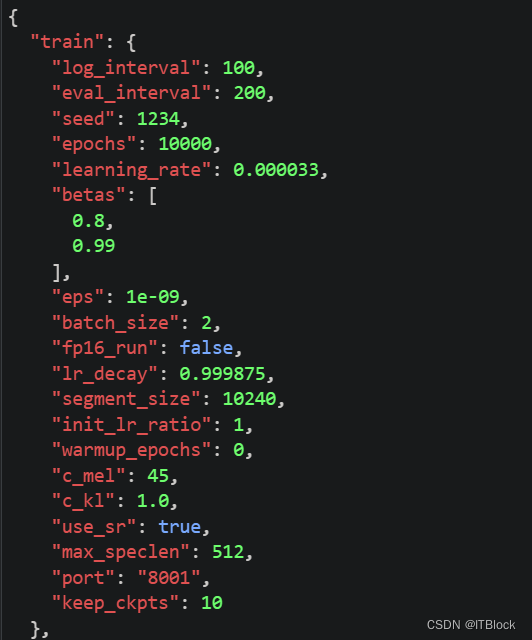
训练的相关细节(config.json)
关于训练过程几个指标的关系参考如下
(167条消息) so-vits-svc3.0 中文详细安装、训练、推理使用教程_Sucial的博客-CSDN博客https://blog.csdn.net/Sucial/article/details/129104472

上面最多语音说话人的语音数可以理解为训练集大小,也就是说训练集越大,batch_size越小,训练就越快,但训练集比较大时,batch_size调太小猜测有可能会对训练效果产生影响
一次处理数据集的数量:batch_size
如果数据集比较小,则推荐设置得小一点,比如我这次训练只是当作测试,数据集只用了一首歌,切成了12份,数据集大小就只有12,batch_size就只设置成了2,如果设置得太大会导致训练很久都训练不出一个模型,batch_size太大据说也比较吃显存,推荐设置成12以内,数据集很大再调高点
训练速度:learning_rate
按readme说两者要成正比,我batch_size调成了2,learning_rate调成了0.000033,训练速度不是看epoch的打印快慢,可以参照输出模型的快慢或者输出评估信息的快慢
隔多久输出一次评估信息:log_interval
注意不是代表打印多少次epoch,数据集越小、batch_size越大需要越多的epoch才能输出一次评估信息
下方是评估信息,各个浮点数的值越小代表损失越小,效果越好,不太熟悉可以不管

隔多久输出一次模型:eval_interval
注意不是代表打印多少次epoch,数据集越小、batch_size越大需要越多的epoch才能输出一次模型,输出模型就是log/44k目录下的那些G_开头的pth文件,D_开头的不能用
修改后的config.json如下
QA
停止后继续训练
So-VITS-SVC 4.0 训练/推理常见报错和Q&A - 哔哩哔哩 (bilibili.com)https://www.bilibili.com/read/cv22206231/
训练不出模型
个人记录VITS使用问题(先发一些,持续摸索) - 哔哩哔哩 (bilibili.com)https://www.bilibili.com/read/cv22071912/
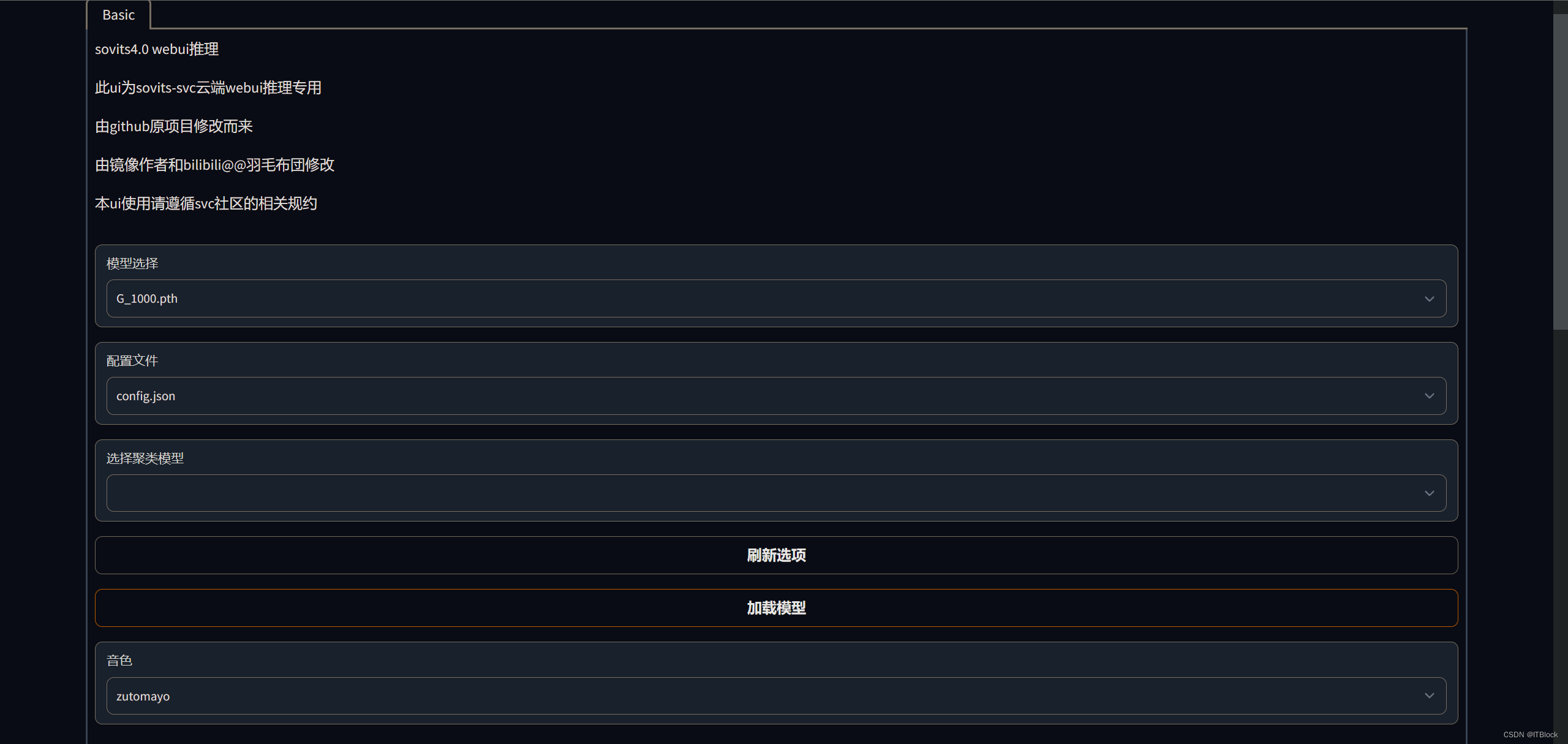
开始推理(翻唱)
按改进版镜像中的readme使用webui来推理
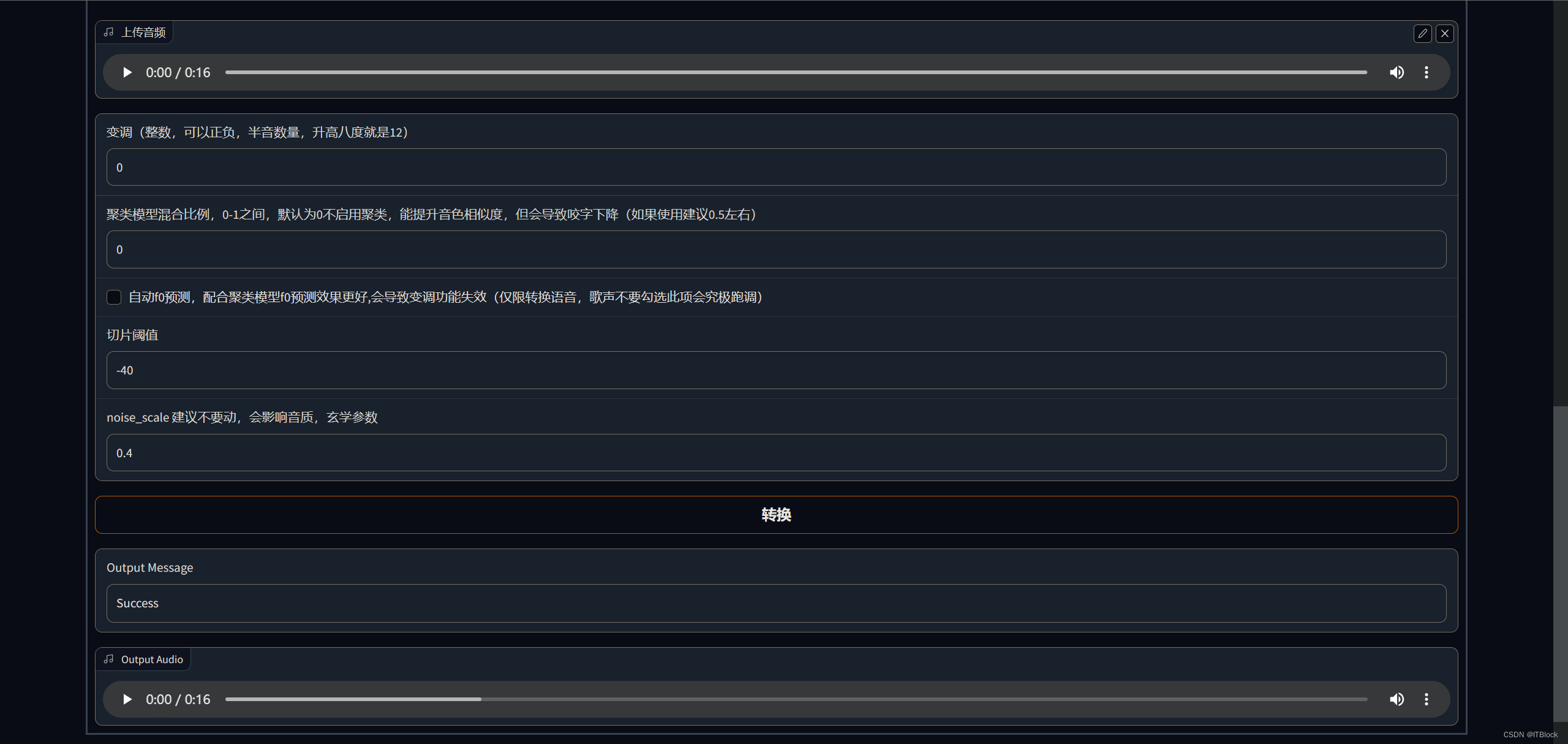
Webui中只能转换wav文件,其他格式控制台报错要求我们先装ffmpeg把其他格式转成wav,那些可调参数似乎还不能改,改了就转不成了
为了不爆现存,我本地将歌曲(米泽园的POWDER SNOW)先用UVR分成人声和bgm,将人声用AU切分成每段最长1分钟,一段段传到webui上转换后再下回本地
然后再使用AU将多段音频合成完整一段人声(复制音频粘贴到另一段音频后面),还要使用混合音轨将完整人声和前面的bgm分别拉进两段音轨里并对齐开头
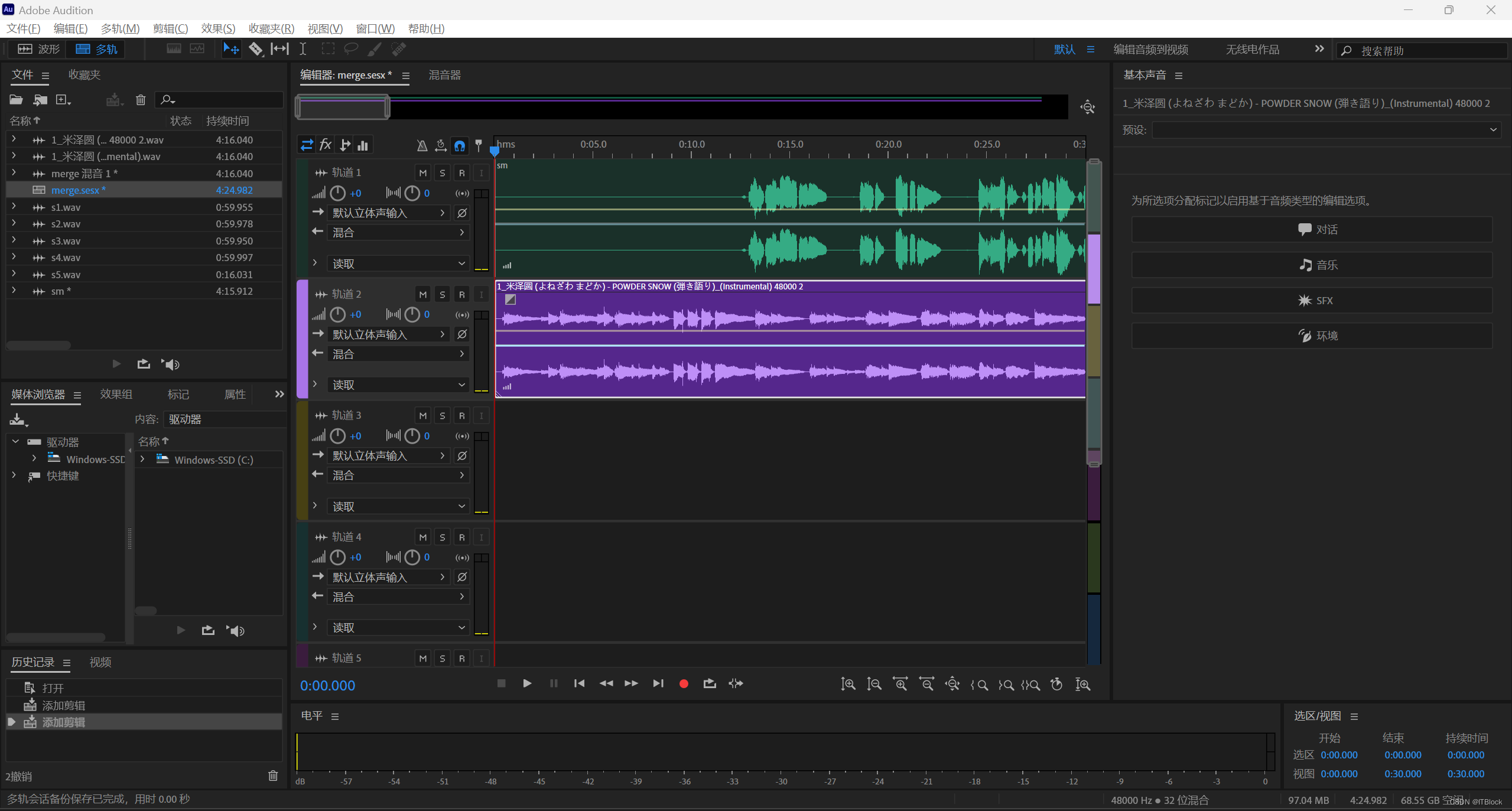
右键混音会话为新建文件,左侧工作区多了一个音频

双击后全选整段音频右键保存,即可得到最后的完整AI音频
版权归原作者 ITBlock 所有, 如有侵权,请联系我们删除。