
参考:
https://github.com/vllm-project/vllm
https://zhuanlan.zhihu.com/p/645732302
https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html ##文档
1、vLLM
这里使用的cuda版本是11.4,tesla T4卡
加速原理:
PagedAttention,主要是利用kv缓存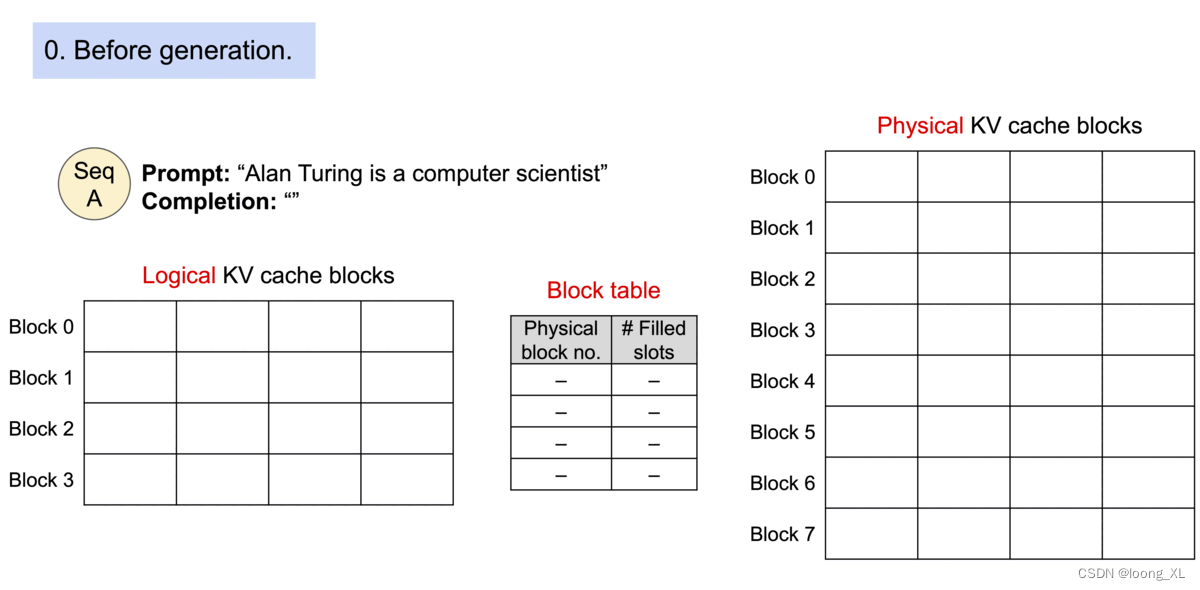
2、qwen测试使用:
注意:用最新的qwen 7B v1.1版本的话,vllm要升级到最新0.2.0才可以(https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary)
注意更改:–dtype=half
python -m vllm.entrypoints
本文转载自: https://blog.csdn.net/weixin_42357472/article/details/132664224
版权归原作者 loong_XL 所有, 如有侵权,请联系我们删除。
版权归原作者 loong_XL 所有, 如有侵权,请联系我们删除。