
近期大语言模型迅速发展,让大家看得眼花缭乱,感觉现在LLM的快速发展堪比寒武纪大爆炸,各个模型之间的关系也让人看的云里雾里。最近一些学者整理出了 ChatGPT 等语言模型的发展历程的进化树图,让大家可以对LLM之间的关系一目了然。
论文:https://arxiv.org/abs/2304.13712
Github(相关资源):https://github.com/Mooler0410/LLMsPracticalGuide
最重要的进化树图:
进化的树图
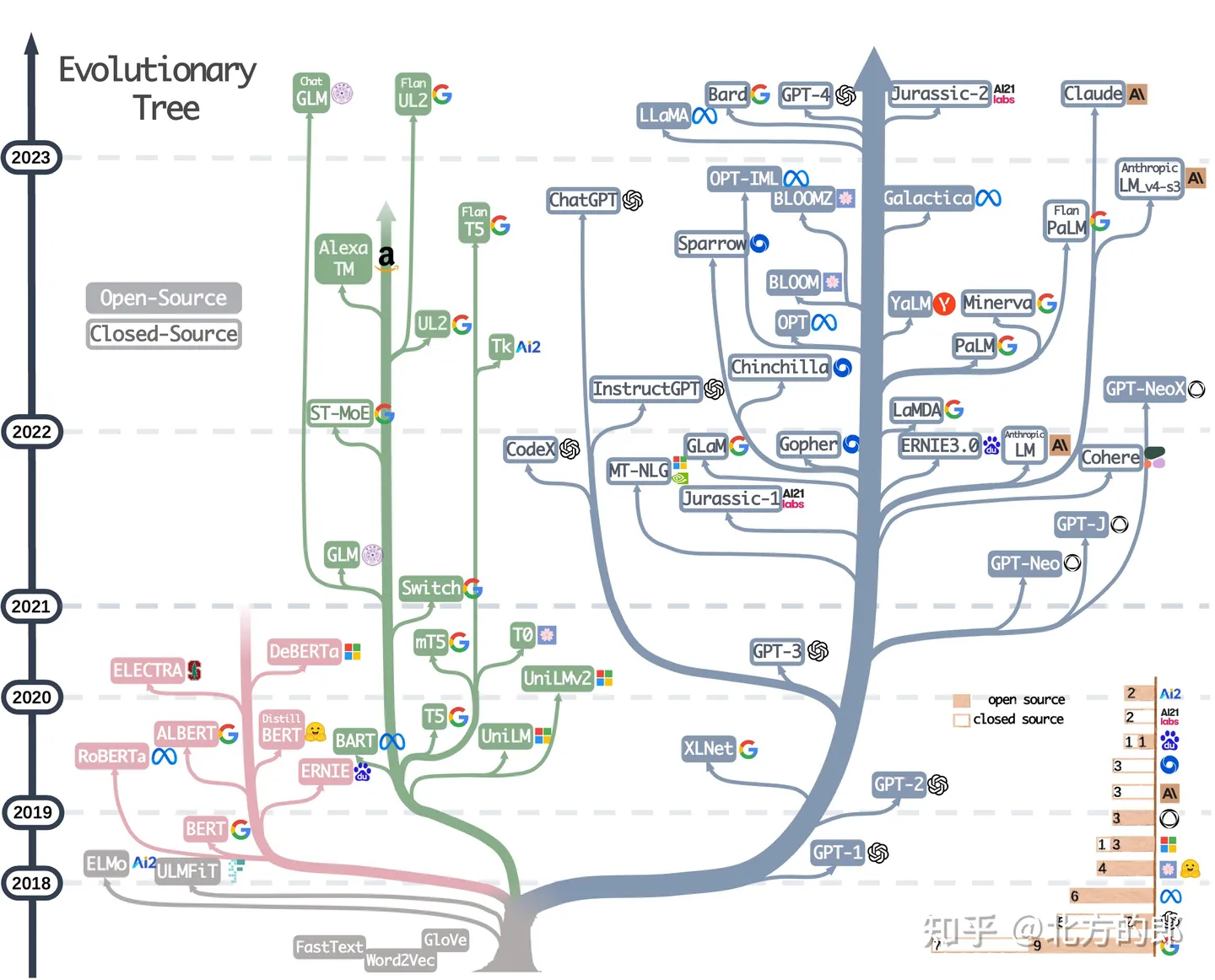
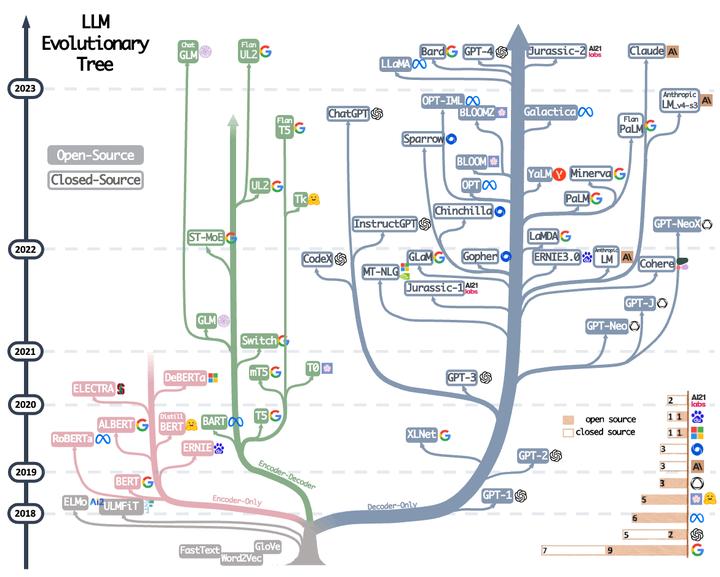
现代语言模型的进化树追溯了近年来语言模型的发展,并强调了一些最著名的模型。同一分支上的模型关系更近。基于Transformer的模型显示为非灰色颜色:仅解码器模型显示为蓝色分支,仅编码器模型显示为粉红色分支,而编码器-解码器模型显示为绿色分支。时间轴上模型的垂直位置代表其发布日期。开源模型由实心方块表示,而闭源模型由空心方块表示。右下角的堆叠条形图显示来自各公司和机构的模型数量。
然后是按年进化的动图,主要内容和上图相同。
论文内容简介(Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond)
论文地址:https://arxiv.org/abs/2304.13712

趋势

a) 仅解码器模型在语言模型的发展中逐渐占主导地位。在语言模型发展的早期阶段,仅解码器模型不如仅编码器模型和编码器-解码器模型流行。然而,在2021年之后,随着改变游戏规则的语言模型GPT-3的推出,仅解码器模型经历了显著的繁荣。与此同时,在BERT带来的初始爆炸性增长之后,仅编码器模型逐渐开始消失。
b) OpenAI在语言模型领域始终保持领先地位,无论当前还是未来。其他公司和机构正在努力追赶OpenAI开发可与GPT-3和当前的GPT-4相媲美的模型。这一领先地位可归因于OpenAI即使在最初并不广泛认可的情况下也坚定地坚持其技术路线。
c) Meta对开源语言模型做出了重大贡献,并促进了语言模型的研究。在考虑对开源社区的贡献时,特别是与语言模型相关的贡献,Meta作为最慷慨的商业公司之一脱颖而出,因为Meta开发的所有语言模型都是开源的。
d) 语言模型表现出倾向于闭源的趋势。在语言模型发展的早期阶段(2020年之前),大多数模型都是开源的。然而,随着GPT-3的推出,公司越来越倾向于闭源其模型,如PaLM、LaMDA和GPT-4。因此,学术研究人员更难进行语言模型训练的实验。因此,基于API的研究可能成为学术界的主流方法。
e) 编码器-解码器模型仍然具有前景,因为这种体系结构仍在积极探索中,并且大多数都是开源的。Google对开源编码器-解码器架构做出了重大贡献。然而,仅解码器模型的灵活性和多功能性似乎使得Google坚持这一方向的前景不太乐观。
总之,仅解码器模型和开源模型在近年来占据主导地位,而OpenAI和Meta在推动语言模型创新和开源方面做出了重大贡献。与此同时,编码器-解码器模型和闭源模型也在一定程度上推动了发展。各家公司和机构在技术发展路径上面临不同的前景。
模型实用指南(Practical Guide for Models)
LLM实用指南资源的精选(仍在积极更新)列表。它基于调查论文:在实践中利用LLM的力量:关于ChatGPT及其他的调查。这些资源旨在帮助从业者驾驭大型语言模型(LLM)及其在自然语言处理(NLP)应用程序中的应用。
BERT风格的语言模型:编码器-解码器或仅编码器(Encoder-Decoder or Encoder-only)
- BERT BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018, Paper
- RoBERTa ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, 2019, Paper
- DistilBERT DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019, Paper
- ALBERT ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, 2019, Paper
- UniLM Unified Language Model Pre-training for Natural Language Understanding and Generation, 2019 Paper
- ELECTRA ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS, 2020, Paper
- T5 "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer". Colin Raffel et al. JMLR 2019. Paper
- GLM "GLM-130B: An Open Bilingual Pre-trained Model". 2022. Paper
- AlexaTM "AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model". Saleh Soltan et al. arXiv 2022. Paper
- ST-MoE ST-MoE: Designing Stable and Transferable Sparse Expert Models. 2022 Paper
GPT 风格语言模型:仅解码器(Decoder-only)
- GPT Improving Language Understanding by Generative Pre-Training. 2018. Paper
- GPT-2 Language Models are Unsupervised Multitask Learners. 2018. Paper
- GPT-3 "Language Models are Few-Shot Learners". NeurIPS 2020. Paper
- OPT "OPT: Open Pre-trained Transformer Language Models". 2022. Paper
- PaLM "PaLM: Scaling Language Modeling with Pathways". Aakanksha Chowdhery et al. arXiv 2022. Paper
- BLOOM "BLOOM: A 176B-Parameter Open-Access Multilingual Language Model". 2022. Paper
- MT-NLG "Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model". 2021. Paper
- GLaM "GLaM: Efficient Scaling of Language Models with Mixture-of-Experts". ICML 2022. Paper
- Gopher "Scaling Language Models: Methods, Analysis & Insights from Training Gopher". 2021. Paper
- chinchilla "Training Compute-Optimal Large Language Models". 2022. Paper
- LaMDA "LaMDA: Language Models for Dialog Applications". 2021. Paper
- LLaMA "LLaMA: Open and Efficient Foundation Language Models". 2023. Paper
- GPT-4 "GPT-4 Technical Report". 2023. Paper
- BloombergGPT BloombergGPT: A Large Language Model for Finance, 2023, Paper
- GPT-NeoX-20B: "GPT-NeoX-20B: An Open-Source Autoregressive Language Model". 2022. Paper
数据实用指南
预训练数据
- RedPajama, 2023. Repo
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling, Arxiv 2020. Paper
- How does the pre-training objective affect what large language models learn about linguistic properties?, ACL 2022. Paper
- Scaling laws for neural language models, 2020. Paper
- Data-centric artificial intelligence: A survey, 2023. Paper
- How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources, 2022. Blog
微调数据
- Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach, EMNLP 2019. Paper
- Language Models are Few-Shot Learners, NIPS 2020. Paper
- Does Synthetic Data Generation of LLMs Help Clinical Text Mining? Arxiv 2023 Paper
测试数据/用户数据
- Shortcut learning of large language models in natural language understanding: A survey, Arxiv 2023. Paper
- On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective Arxiv, 2023. Paper
- SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems Arxiv 2019. Paper
NLP 任务实用指南
研究者为用户的NLP应用程序构建了一个选择LLM或微调模型的决策流程~\protect\footnotemark。决策流程可帮助用户评估其手头的下游NLP应用程序是否满足特定条件,并根据该评估确定LLM或微调模型是否最适合其应用程序。
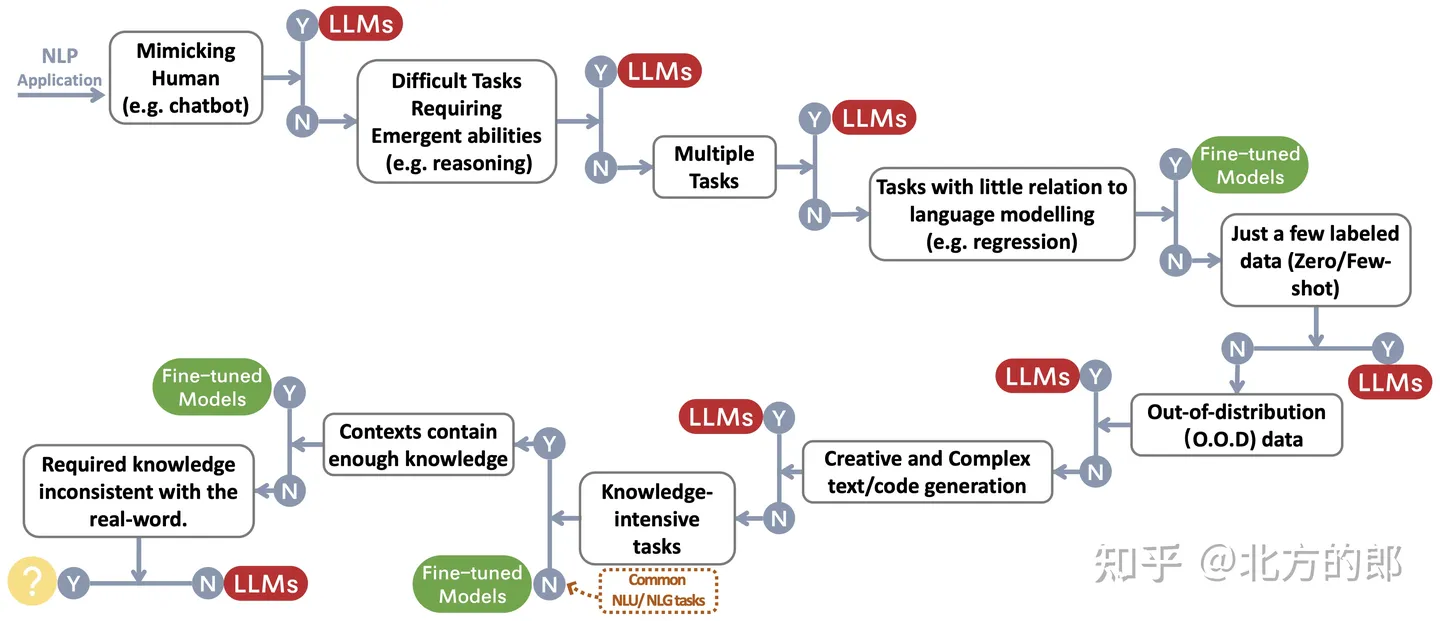
传统的非语言处理任务( NLU tasks)
- A benchmark for toxic comment classification on civil comments dataset Arxiv 2023 Paper
- Is chatgpt a general-purpose natural language processing task solver? Arxiv 2023Paper
- Benchmarking large language models for news summarization Arxiv 2022 Paper
生成任务
- News summarization and evaluation in the era of gpt-3 Arxiv 2022 Paper
- Is chatgpt a good translator? yes with gpt-4 as the engine Arxiv 2023 Paper
- Multilingual machine translation systems from Microsoft for WMT21 shared task, WMT2021 Paper
- Can ChatGPT understand too? a comparative study on chatgpt and fine-tuned bert, Arxiv 2023, Paper
知识密集型任务
- Measuring massive multitask language understanding, ICLR 2021 Paper
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, Arxiv 2022 Paper
- Inverse scaling prize, 2022 Link
- Atlas: Few-shot Learning with Retrieval Augmented Language Models, Arxiv 2022 Paper
- Large Language Models Encode Clinical Knowledge, Arxiv 2022 Paper
缩放能力
- Training Compute-Optimal Large Language Models, NeurIPS 2022 Paper
- Scaling Laws for Neural Language Models, Arxiv 2020 Paper
- Solving math word problems with process- and outcome-based feedback, Arxiv 2022 Paper
- Chain of thought prompting elicits reasoning in large language models, NeurIPS 2022 Paper
- Emergent abilities of large language models, TMLR 2022 Paper
- Inverse scaling can become U-shaped, Arxiv 2022 Paper
- Towards Reasoning in Large Language Models: A Survey, Arxiv 2022 Paper
具体任务
- Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks, Arixv 2022 Paper
- PaLI: A Jointly-Scaled Multilingual Language-Image Model, Arxiv 2022 Paper
- AugGPT: Leveraging ChatGPT for Text Data Augmentation, Arxiv 2023 Paper
- Is gpt-3 a good data annotator?, Arxiv 2022 Paper
- Want To Reduce Labeling Cost? GPT-3 Can Help, EMNLP findings 2021 Paper
- GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation, EMNLP findings 2021 Paper
- LLM for Patient-Trial Matching: Privacy-Aware Data Augmentation Towards Better Performance and Generalizability, Arxiv 2023 Paper
- ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks, Arxiv 2023 Paper
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Arxiv 2023 Paper
- GPTScore: Evaluate as You Desire, Arxiv 2023 Paper
- Large Language Models Are State-of-the-Art Evaluators of Translation Quality, Arxiv 2023 Paper
- Is ChatGPT a Good NLG Evaluator? A Preliminary Study, Arxiv 2023 Paper
现实世界的“任务”
- Sparks of Artificial General Intelligence: Early experiments with GPT-4, Arxiv 2023 Paper
效率
1.成本
- Openai’s gpt-3 language model: A technical overview, 2020. Blog Post
- Measuring the carbon intensity of ai in cloud instances, FaccT 2022. Paper
- In AI, is bigger always better?, Nature Article 2023. Article
- Language Models are Few-Shot Learners, NeurIPS 2020. Paper
- Pricing, OpenAI. Blog Post
2.延迟
- HELM: Holistic evaluation of language models, Arxiv 2022. Paper
3.参数高效微调
- LoRA: Low-Rank Adaptation of Large Language Models, Arxiv 2021. Paper
- Prefix-Tuning: Optimizing Continuous Prompts for Generation, ACL 2021. Paper
- P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks, ACL 2022. Paper
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks, Arxiv 2022. Paper
4.预训练系统
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, Arxiv 2019. Paper
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, Arxiv 2019. Paper
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, Arxiv 2021. Paper
- Reducing Activation Recomputation in Large Transformer Models, Arxiv 2021. Paper
信用
- 稳健性和校准
- Calibrate before use: Improving few-shot performance of language models, ICML 2021. Paper
- SPeC: A Soft Prompt-Based Calibration on Mitigating Performance Variability in Clinical Notes Summarization, Arxiv 2023. Paper
- 杂散偏置(Spurious biases)
- Shortcut learning of large language models in natural language understanding: A survey, 2023 Paper
- Mitigating gender bias in captioning system, WWW 2020 Paper
- Calibrate Before Use: Improving Few-Shot Performance of Language Models, ICML 2021 Paper
- Shortcut Learning in Deep Neural Networks, Nature Machine Intelligence 2020 Paper
- Do Prompt-Based Models Really Understand the Meaning of Their Prompts?, NAACL 2022 Paper
- 安全问题
- GPT-4 System Card, 2023 Paper
- The science of detecting llm-generated texts, Arxiv 2023 Paper
- How stereotypes are shared through language: a review and introduction of the aocial categories and stereotypes communication (scsc) framework, Review of Communication Research, 2019 Paper
- Gender shades: Intersectional accuracy disparities in commercial gender classification, FaccT 2018 Paper
基准指导调优(Benchmark Instruction Tuning)
- FLAN: Finetuned Language Models Are Zero-Shot Learners, Arxiv 2021 Paper
- T0: Multitask Prompted Training Enables Zero-Shot Task Generalization, Arxiv 2021 Paper
- Cross-task generalization via natural language crowdsourcing instructions, ACL 2022 Paper
- Tk-INSTRUCT: Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, EMNLP 2022 Paper
- FLAN-T5/PaLM: Scaling Instruction-Finetuned Language Models, Arxiv 2022 Paper
- The Flan Collection: Designing Data and Methods for Effective Instruction Tuning, Arxiv 2023 Paper
- OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization, Arxiv 2023 Paper
校准(Alignment)
- Deep Reinforcement Learning from Human Preferences, NIPS 2017 Paper
- Learning to summarize from human feedback, Arxiv 2020 Paper
- A General Language Assistant as a Laboratory for Alignment, Arxiv 2021 Paper
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Arxiv 2022 Paper
- Teaching language models to support answers with verified quotes, Arxiv 2022 Paper
- InstructGPT: Training language models to follow instructions with human feedback, Arxiv 2022 Paper
- Improving alignment of dialogue agents via targeted human judgements, Arxiv 2022 Paper
- Scaling Laws for Reward Model Overoptimization, Arxiv 2022 Paper
- Scalable Oversight: Measuring Progress on Scalable Oversight for Large Language Models, Arxiv 2022 Paper
安全校准(无害)
- Red Teaming Language Models with Language Models, Arxiv 2022 Paper
- Constitutional ai: Harmlessness from ai feedback, Arxiv 2022 Paper
- The Capacity for Moral Self-Correction in Large Language Models, Arxiv 2023 Paper
- OpenAI: Our approach to AI safety, 2023 Blog
真实性一致性(诚实)
- Reinforcement Learning for Language Models, 2023 Blog
提示实用指南(有用)
- OpenAI Cookbook. Blog
- Prompt Engineering. Blog
- **ChatGPT Prompt Engineering for Developers!**Course
开源社区的工作
- Self-Instruct: Aligning Language Model with Self Generated Instructions, Arxiv 2022 Paper
- Alpaca. Repo
- Vicuna. Repo
- Dolly. Blog
- DeepSpeed-Chat. Blog
- GPT4All. Repo
- OpenAssitant. Repo
- ChatGLM. Repo
- MOSS. Repo
- Lamini. Repo/Blog
感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^
版权归原作者 才能我浪费 所有, 如有侵权,请联系我们删除。