
本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:实战 | 基于YoloV5和Mask RCNN实现汽车表面划痕检测(步骤 + 代码)
导 读
本文主要介绍基于YOLOv5和Mask RCNN实现汽车表面划痕检测。
前 言

该项目专注于**汽车划痕检测**,与不同类型产品的**自主质量检测系统**的开发同步。例如,在停车场,这种检测为客户提供了汽车安全无虞的保证;此外,如果发生什么情况,检测系统将有助于仔细处理这种情况。
此外,在这个项目中学到的技术可以在其他项目中补充或结合其他一些问题使用,例如**质量保证**和**二手车估价**。我将这个问题作为单类分类问题来解决,将凹痕、损坏和划痕视为划痕,并进一步在烧瓶的帮助下制作了一个基本的应用程序。本文将向您介绍我在完成这个项目时获得的所有想法、代码、算法和知识,我通过**Mask RCNN和Yolov5**实现了该项目。
实现步骤
【1】准备数据集。
为了收集数据,我做了一个**数据抓取器**,使用Beautiful Soup从adobe、Istock photo等在线网站抓取数据。为了收集数据,我做了一个数据抓取器,使用Beautiful Soup从adobe、Istock photo等在线网站抓取数据。
url = 'https://stock.adobe.com/in/search/images?k=car%20scratch'
# 向 url 发出请求
r = requests.get(url)
# 创建我们的soup
soup = BeautifulSoup(r.文本, 'html.parser')
print(soup.title.text)
images = soup.find_all('img')
for images[-1] 中的图像:
name = image['alt']
link = image['src']
with open(name.replace(' ', '-').将('/', '') + '.jpg', 'wb') 替换为 f:
im = requests.get(link)
f.write(im.content)
但它不起作用,因为由于网站有关抓取的隐私政策,大多数图像没有被抓取。由于隐私问题,我直接从** Istock photo、Shutter photo **和** Adobe **下载了图像。
我们从大约 80 张图像开始,增加到 350 张图像,并进一步增加到大约 900 张图像以进行最终标注。
【2】使用Mask RCNN进行实例分割。
图像分割是根据像素将图像分割成不同的区域。**Mask RCNN **是用于实例分割的模型,实例分割是图像分割的一种子类型,用于分离对象边界中的实例。它进一步建立在 Faster RCNN 的基础上。Faster RCNN 对于每个对象有两个输出,作为类标签和边界框偏移,而 Mask RCNN 是第三个输出(即对象的掩码)的相加。
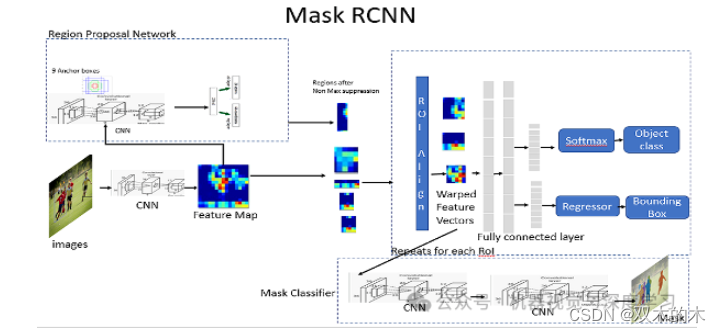
Mask RCNN 的架构由以下部分组成:
骨干网
区域提案网络
掩模表示
ROI对齐
使用 Mask RCNN 检测汽车划痕的**优点**是,我们可以使用**多边形**而不仅仅是边界框,并在目标上创建掩模,进一步使我们能够以更准确、更简洁的方式获得和可视化结果。 让我们开始使用 Mask RCNN 来实现我们的问题。 导入必要的库:
# importing libraries
import pandas as pd
import numpy as np
import cv2
import os
import re
from PIL import Image
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from matplotlib import pyplot as plt
划分数据集:
其中使用的数据采用 .csv 格式,其中包含边界框的 x、y、w 和 h 坐标,而数据是使用数据注释器make-sense进行标注的。
image_ids = train_df['image_id'].unique()
print(len(image_ids))
valid_ids = image_ids[-10:]
train_ids = image_ids[:-10]
# valid and train df
valid_df = train_df[train_df['image_id'].isin(valid_ids)]
train_df = train_df[train_df['image_id'].isin(train_ids)]
创建临时类:
创建我们的 Scratch Dataset 类来转换我们的数据集并返回所需的数据。
class ScratchDataset(Dataset):
def __init__(self, dataframe, image_dir, transforms=None):
super().__init__()
self.image_ids = dataframe['image_id'].unique()
self.df = dataframe
self.image_dir = image_dir
self.transforms = transforms
def __getitem__(self, index: int):
image_id = self.image_ids[index]
records = self.df[self.df['image_id'] == image_id]
image = cv2.imread(f'{self.image_dir}/{image_id}.jpg', cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
image /= 255.0
boxes = records[['x', 'y', 'w', 'h']].values
boxes[:, 2] = boxes[:, 0] + boxes[:, 2]
boxes[:, 3] = boxes[:, 1] + boxes[:, 3]
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2]-boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
# there is only one class
labels = torch.ones((records.shape[0],), dtype=torch.int64)
# suppose all instances are not crowd
iscrowd = torch.zeros((records.shape[0],), dtype=torch.int64)
target = {}
target['boxes']=boxes
target['labels']=labels
target['image_id']=torch.tensor([index])
target['area']=area
target['iscrowd']=iscrowd
if self.transforms:
sample = {
'image':image,
'bboxes': target['boxes'],
'labels': labels
}
sample = self.transforms(**sample)
image = sample['image']
target['boxes'] = torch.tensor(sample['bboxes'])
return image, target, image_id
def __len__(self) -> int:
return self.image_ids.shape[0]
这里的“img_dir”是保存图像的目录路径。
数据增强:
在这里,我们使用 Albumentations 进行数据增强。
# Albumenations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format':'pascal_voc', 'label_fields':['labels']})
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields':['labels']})
创建模型:
我们将使用 Resnet50 模型和 Mask RCNN。
# load a model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 2 # 1 class scratch+ background
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace th epre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
让我们继续创建 Averager 类以及训练和验证数据加载器,它们将成为训练模型时的关键组件。
class Averager:
def __init__(self):
self.current_total = 0.0
self.iterations = 0.0
def send(self, value):
self.current_total += value
self.iterations += 1
@property
def value(self):
if self.iterations == 0:
return 0
else:
return 1.0 * self.current_total/ self.iterations
def reset(self):
self.current_total = 0.0
self.iterations = 0.0
def collate_fn(batch):
return tuple(zip(*batch))
train_dataset = WheatDataset(train_df, DIR_TRAIN, get_train_transform())
valid_dataset = WheatDataset(valid_df, DIR_TRAIN, get_valid_transform())
# split the dataset in train and test set
indices = torch.randperm(len(train_dataset)).tolist()
train_data_loader = DataLoader(
train_dataset,
batch_size=16,
shuffle=False,
num_workers=4,
collate_fn=collate_fn
)
valid_data_loader = DataLoader(
valid_dataset,
batch_size=8,
shuffle=False,
num_workers=4,
collate_fn=collate_fn
)
训练模型:
我们正在激活“cuda”并访问 GPU(如果可用)。进一步我们的weight_decay=0.0005,momentum=0.9,动态学习率从0.05开始。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
images, targets, image_ids = next(iter(train_data_loader))
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9,
weight_decay=0.0005)
# lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
lr_scheduler = None
num_epochs = 2
loss_hist = Averager()
itr=1
for epoch in range(num_epochs):
loss_hist.reset()
for images, targets, image_ids, in train_data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
loss_hist.send(loss_value)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if itr % 50 == 0:
print(f'Iteration #{itr} loss: {loss_value}')
itr += 1
# update the learning rate
if lr_scheduler is not None:
lr_scheduler.step()
print(f'Epoch #{epoch} loss: {loss_hist.value}')
但我无法实现这一点,因为仅仅 80 张图像就花费了 10 个小时甚至更长的时间。
使用 Mask RCNN 进行自定义训练的时间复杂度非常大,并且需要大量的计算能力,而我却无法做到这一点。
【3】通过 Yolov5 进行物体检测
Yolo 主要用于目标检测,由 **Ultralytics[ github ]** 发布,已成为视觉数据分割等领域的基准算法。Yolov5 比 Yolov4 更快、更高效,并且可以很好地推广到新图像。
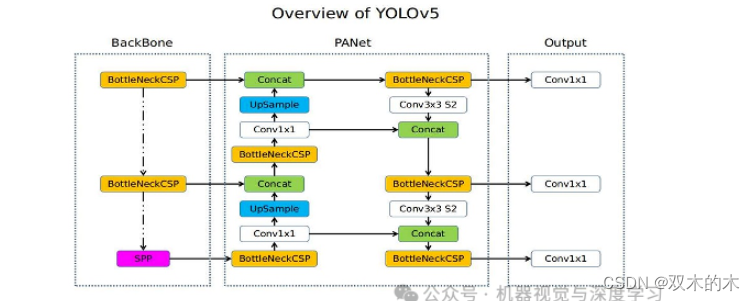
Yolov5架构
该算法的工作原理如下:
剩余块
边界框回归
并集交集(IOU)
非极大值抑制.a
Yolov5更快、更小,并且与以前的版本大致一样准确。在 coco 数据集上进行训练,它可以很好地处理边界框。
让我们从我们问题案例中 Yolov5 的实现开始;我已经使用 google collab 来运行其中的代码。
数据标注:我使用了一个有意义的数据注释器来注释数据集。
当数据被精确地注释(即小而中肯)时,Yolo 的工作效果不够好,因为它不能很好地泛化到小边界框。
因此数据标注有点棘手,区域应该统一标注。
训练:加载模型
model = torch.hub.load('ultralytics/yolov5','yolov5s')
我们添加了 Yolo 工作所需的 yaml 文件和数据(图像在一个文件夹中,而注释作为文本文件在另一个文件夹中),我们使用批量大小 16 和图像大小 320*320 训练模型。
!cd yolov5 && python train.py --img 320 --batch 16 --epochs 50 --data carScr_up.yaml --weights last.pt
虽然在 Yolo 文档中,据说需要运行 300 个 epoch 才能获得良好的结果,但我们已将其降低到 50 个 epoch,并且在超参数调整后,我们的模型甚至在 30 个 epoch 内就开始表现得很好。
对于超参数调整,我们使用 Yolo 提供的演化,其中数据训练 10 个 epoch,进行 300 次演化。
!cd yolov5 && python train.py --img 320 --batch 32 --epochs 10 --data carScr_up.yaml --weights yolov5s.pt --cache --evolve
结果:
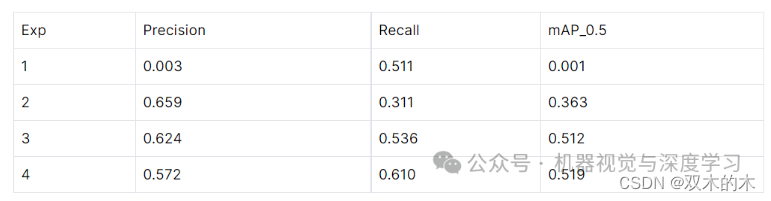
下图代表实验 4,每个实验都根据不同数量的图像和注释进行训练。对于有划痕的汽车的预测如下:

在这种情况下,精度和召回率都很小,因为在 Yolo 中,我们处理的是边界框,而这些指标取决于实际框和预测框的并集交集 (IOU)。
让我们看一下使用 Yolov5 训练数据集 50 个 epoch 后获得的指标
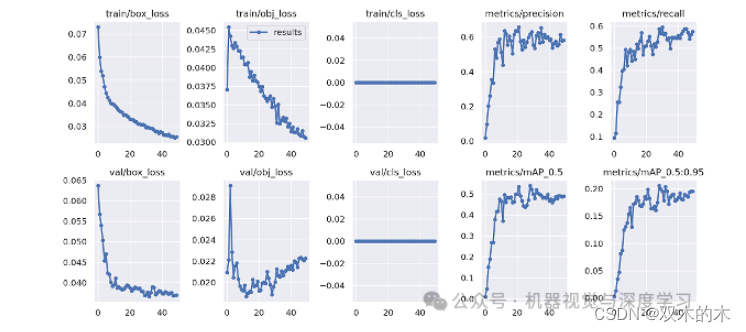
我们可以看到,在20 个 epoch 后,进度停滞不前,因此,即使我们拥有的数据低于 1000 张图像,Yolo 也能很快地学习这种关系并很好地推广到我们的问题陈述。
** 【4】结论**
我们可以看到Yolov5和 Mask RCNN 对于我们的问题陈述非常有效,尽管我无法实现后面的代码。Yolov5 可以很好地跟上我们的问题陈述。在使用 Yolov5 进行自定义训练时,除了指标之外,它能够非常好地进行预测,检测样本图像中的所有划痕和损坏。因此,我们有一个非常好的模型,在其中我们学习如何收集、注释和训练不同的模型以及训练不同模型需要什么。
在上面,我将损坏和划痕视为一个类别。
数据注释和收集是该解决方案不可或缺的详尽部分。
如果我们使用多边形并增加数据集大小,我们肯定可以做得更好。
PS:这对于没有损坏的汽车来说效果不佳。因为我们仅使用包含划痕和损坏的汽车的数据对其进行训练。我们绝对可以概括这一点以满足我们的需求。或者,我们可以点击下面提到的研究论文的链接,其中图像被分为 3*3 网格并用作我们的训练数据。这将导致划痕与图像的比率增加,从而很好地推广到数据集并改进我们的指标。
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
版权归原作者 双木的木 所有, 如有侵权,请联系我们删除。