
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
Facebook 人工智能研究 (FAIR) 团队发表的论文 Masked Autoencoders Are Scalable Vision Learners 已成为计算机视觉社区的热门话题。这也是KaiMing大神在2年后的第一篇一作论文。
采用带有掩码的语言建模系统,如谷歌的 BERT 及其自回归对应模型,如 OpenAI 的 GPT,已经在自然语言处理 (NLP) 任务中取得了惊人的性能,并能够训练包含超过 1000 亿个参数的泛化 NLP 模型。
但是在计算机视觉中自编码方法的进展和性能远远落后于它们在 NLP 能力。一个问题自然会出现:掩码自动编码在视觉和语言领域有何不同?FAIR 论文解决了这个问题,并证明了 Masked Autoencoders (MAE) 可以是用于计算机视觉的可扩展自监督学习器。

研究人员首先讨论了视觉和语言领域中带有掩码的自编码器的差异,总结为以下三点:1) 到现在为止两者架构还是不同的;2)语言和图像的信息密度不同;3)自动编码器的解码器将潜在表示映射回输入,在重建文本或图像时扮演不同的角色。
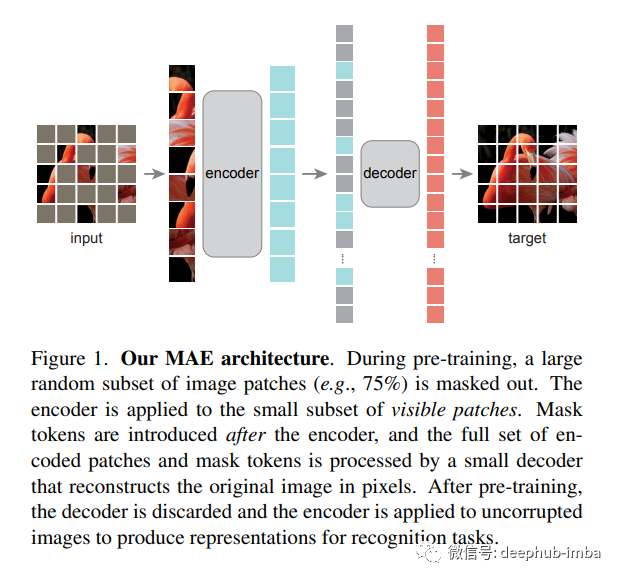
然后,该论文提出了一种简单、有效且可扩展的 用于视觉表示学习的MAE方法。所提出的 MAE 方法背后的想法很简单——将来自输入图像的随机块被屏蔽,然后在像素空间中重建丢失的块。该团队将其 MAE 的双核心设计和方法总结为:
我们开发了一个非对称编码器-解码器架构,其中一个编码器只对可见的patches子集进行操作(没有掩码标记),以及一个轻量级解码器,可以从潜在表示和掩码标记重建原始图像。
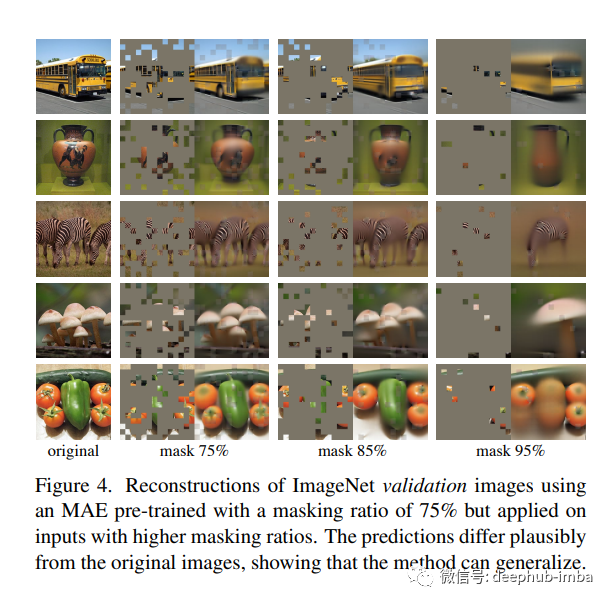
我们发现屏蔽大部分输入图像,例如 75%,会产生重要且有意义的自监督任务。将这两种设计结合起来使我们能够高效地训练大型模型,将训练速度提高 3 倍或更多,并提高准确性。
论文在 ImageNet-1K (IN1K) 训练集上进行了自监督的预训练,然后进行了监督训练,以通过端到端的微调或线性探测来评估表示。他们使用 ViT-Large (ViT-L/16) 作为他们的模型并验证Top1准确性。

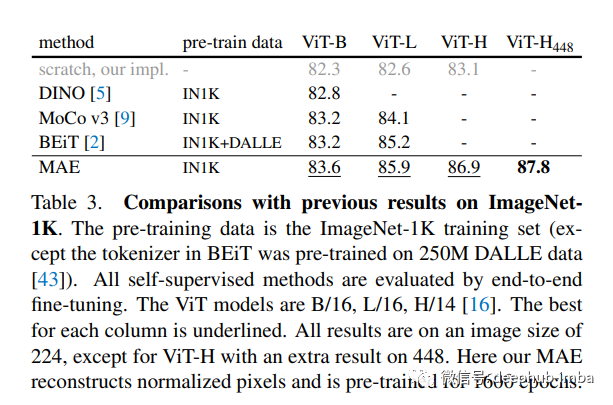
结果表明,MAE 学习了非常高容量的模型,这些模型也能很好地泛化。使用普通的 ViT-Huge 模型,MAE 在 ImageNet-1K 上进行微调时达到了 87.8% 的准确率。
论文认为,扩展性好的简单算法是深度学习的核心。在NLP中,简单的自监督学习方法可以指数级别的增益模型。在计算机视觉中,尽管在自监督学习方面取得了进展,但实际的预训练模式仍主要受到监督。在ImageNet和迁移学习中观察到,自动编码器(autoencoder)提供了非常强的优势。视觉中的自监督学习现在可能正走上与NLP类似的轨道。
论文地址:https://arxiv.org/abs/2111.06377
本文来自 syncedreview,作者:Hecate He
喜欢就关注一下吧:
点个 在看 你最好看!********** **********