
浅析ChatGPT
ChatGPT介绍
ChatGPT 是OpenAI公司推出人工智能聊天机器人程序。ChatGPT能够以流畅的自然语言跟人聊天,还能根据聊天的上下文进行互动,其答案体现了很强的自然语言理解、信息综合和推理能力,以及其模型中蕴含的丰富的知识。ChatGPT推出以来,逐渐引起了广泛而热烈的关注,微软已计划将ChatGPT集成Office、Bing搜索等多款产品中,ChatGPT也可以与其他AIGC模型联合使用,获得更加炫酷实用的功能。例如通过对话生成客厅设计图。这极大加强了AI应用与客户对话的能力。
ChatGPT还能完成撰写邮件、编写文案、翻译、写代码,写论文等任务。ChatGPT甚至可以质疑不正确的问题。例如被询问“拿破仑2022年来到中国的情景”的问题时,机器人会说拿破仑不属于这一时代并调整输出结果。
2017 年 Transformer 结构的提出,使得深度学习模型参数突破了 1 亿大模型应运而生,ChatGPT是基于预训练大模型GPT3.5构建而成的。
2018年,OpenAI 发布了第一个 GPT-1模型,它是一个基于 Transformer 结构的预训练语言模型,能够自动生成文本。
2019年OpenAI又分别推出了GPT-2,在GPT-1的基础上做了优化,使用1600维向量进行词嵌入,修改初始化的残差权重、特征向量维度从768维扩展到1600维,词表扩大到50257;
2020年发布GPT-3版本,训练数据量和模型参数逐步大幅增加,GPT-3的单词嵌入大小从GPT-2的1600增加到12888,上下文窗口大小从GPT-2的1024增加到GPT-3的2048,GPT-3用45T数据训练,有1750亿参数,在多种自然语言任务上,体现了优异的性能。2022年发布GPT3.5,在GPT3基础上,加入人类反馈强化学习机制”(RLHF),通过人工标注对模型输出结果打分建立奖励模型,然后通过奖励模型继续循环迭代。通过这样的训练,OpenAI获得了更真实、更无害,并且更好地遵循用户意图的语言模型InstructGPT,在
2022年3月发布,并同期开始构建InstuctGPT的姊妹模型ChatGPT。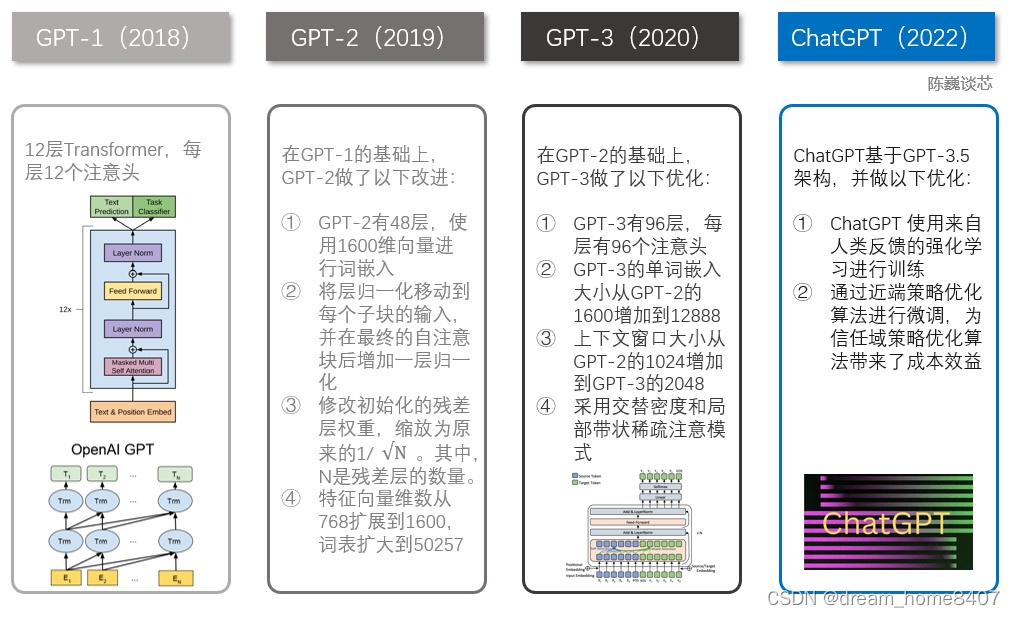
ChatGPT使用基于人类反馈的监督学习和强化学习在 GPT-3.5 之上进行了微调,获取建模对话历史的能力,以及使模型输出更符合人类期待,产生更加详实、公正的回应,拒绝不当问题和知识范围外的问题。
Bert和GPT区别
2017年Transformer结构的提出,使得深度学习模型参数突破了1亿,随着模型的迭代升级,模型参数规模越来越大,用于训练的数据量也越来越大,大模型可以称为Foundation Model(基石)模型。模型采用自监督的训练方式,从大量未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地拓展了模型的泛化能力。
Transformer出现之后,很多公司基于Transformer做NLP大模型研究,其中OpenAI与谷歌就是最重要的两家,2018年,OpenAI推出了1.17亿参数的GPT-1,谷歌推出了3亿参数的BERT,双方展开了一场NLP的较量。
BERT和GPT,底层结构都选择transformer作为特征提取器,并且都是用了大量的训练数据进行模型训练。二者的最重要的不同点在于:
BERT模型使用的是transformer的Encoder结构,属于自编码模型Encoder-AE。BERT采用双向 Transformer 结构进行预训练,能够对单句或双句文本进行建模,模型训练时,模型能够根据被预测词的上下文语义信息预测出中间词出现的概率。因此BERT更加擅长语言理解类的任务,如文本分类,实体抽取,情感判断等。
GPT模型使用的是transformer的Decoder结构,属于自回归语言模型Decoder-AR。在模型训练时,GPT模型从左到右依次生成被预测词,只能看到被预测词前面的词而无法看到被预测词后面的词。因此GPT在语言生成类任务上有着更好的表现,例如机器翻译,文本生成等。
两者具体表现如何呢?发布更早的GPT-1赢了初代Transformer,但输给了BERT,而且是完败。在当时的竞赛排行榜上,阅读理解领域已经被BERT屠榜了。此后,BERT也成为了NLP领域最常用的模型。但OpenAI没有改变策略,而是坚持走“大模型路线”后续发布的GPT-2在性能上已经超过BERT,到GPT-3又更进一步,几乎可以完成自然语言处理的绝大部分任务 ,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答,甚至还可以依据任务描述自动生成代码,后续发布的ChatGPT在自然语言处理能力更是远超BERT。
为什么ChatGPT出现前国内没有走GPT路线
在预训练模型发展的早期,预训练模型的评测主要是在各种自然语言处理NLP子任务上进行,BERT借鉴了GPT的思想于GPT之后提出,其在各项评测任务上都有着更好的表现。一个合理的解释是Decoder-AR的结构和训练方式要比Encoder-AE的难度更高,因此需要更多的训练数据才能激发模型的涌现能力和效果。所以在当时的背景下,人们更加看好BERT类的预训练模型,选择BERT+微调的形式处理各项NLP任务。
但是OpenAI还是坚持选择了GPT道路。并且在后续陆续发布的GPT2,GPT3模型,可以不使用微调,而通过prompt提示,直接用于下游NLP任务。这种灵活的生成方式,更加符合人机交互的逻辑理念,并且通过改变语言生成任务的生成形式,可以很好地处理语言理解类问题,比如可以通过生成标签处理文本分类问题,真正做到了NLP任务的统一。
Chatgpt局限性
1.无法保证答案准确性
ChatGPT在其未经大量语料训练的领域缺乏“人类常识”和引申能力,有可能给出有错误的回答,但由于其表述的自然性,反而加大了用户分辨的难度。
2.高昂的算力成本
ChatGPT的训练和推理都需要很高的算力支撑,固定成本(大量芯片购买和机房建设)和可变成本(电力和维护费用)都很高。
3.无法及时把新知识纳入其中出现一些新知识就去重新训练GPT模型是不现实的。如果对于新知识采取在线训练的模式,又很容易由于新数据的引入而导致对原有知识的灾难性遗忘的问题。
4.缺乏非常专业的领域知识。
对于来自电力、自然科学、医学等非常专业领域的问题,如果没有进行足够的语料训练,ChatGPT可能无法生成适当的回答。
随着软硬件的发展和应用层面的创新,这些问题会得到逐步的缓解或解决。
5.增量迭代成本
ChatGPT的增量迭代可以分为两部分。
一是基于强化学习的参数迭代。这部分参数较少,可以随着用户使用逐步积累数据,迭代频次成本较低,频次可以高一些。
二是预训练大语言模型部分。这部分参数较多,而且迭代需要高质量数据,迭代成本较高。但该部分训练完成后,迭代的需求频次也较低。新知识的更新,可以在应用时通过prompt的方式传递给模型,而不需要重新训练模型。
技术在公司怎么使用
1.传统搜索+ChatGPT
ChatGPT与传统搜索引擎的结合,必然会带来一场新的颠覆式的变革,Keras之父说过:生成式AI和搜索引擎是互补关系,我们需要的是结合两者优势的新一代工具,传统的搜索引擎在搜索时,根据用户的查询请求来快速定位包含关键字的网页,最后返回排名最高的搜索结果给用户,用户需要人为筛选的返回的列表。
在没有chatGPT之前,我们大多数时候是非常满足这种一次性的交互的。我们可以通过多次但chatGPT出现之后这种方式被改变了。两者的结合解决的主要问题在于:
1.ChatGPT强大的自然语言处理成立可以理解自然语言,精准识别到用户搜索意图,再用搜索引擎返回搜索的结果。解决了搜索引擎通常只能处理关键词查询能力和ChatGPT生产误导性信息的可能。
2.ChatGPT可以根据用户提供的上下文信息来理解查询,可以进行更加深度的交互和延展交互,ChatGPT生成的文本交给搜索引擎进一步搜索,两者结合解决搜索引擎通常只针对单次查询进行回答。
3.ChatGPT的知识是有限的,没有搜索引擎的知识库那么丰富,并且与传统搜索引擎相比,生成结果的速度可能更慢,因为需要计算和生成结果,两者相互弥补给用户带来更好的使用体验。
这样,无论是从知识获取的效率,还是深度交互和延展上,我们都获得了极大的满足和提升。两者结合搜索最终获取我们需要的答案。
2.代码生成
ChatGPT被称为行走的代码生成器,它具有理解人类语言意图并生成对应代码的能力,在日常工作中ChatGPT可以帮助使用者根据需求生成对应代码,然后将对应代码集成到运行系统环境中,例如:
1.生成SQL语句,去查询数据时,选择查询的表格,限定一下SQL生成的表和字段的范围,然后使用chatGPT生成SQL语句,最后使用生成的SQL语句即可查询出数据库中的数据。
2.可以根据需求生成python语言前端展示界面,运行成功后将生成代码集成到平台所运行环境中,简单快速实现展示功能。
3.修改程序BUG,ChatGPT 修改程序问题的回答非常全面,它首先确认这段代码的意图是什么,然后根据意图很快就找到了 bug 所在,并且还附上了相当细致的描述,来解释问题出在哪,会导致什么样的 bug,应该怎么改,为什么要这样改等,防止程序漏洞,提高运行系统的生产效率。
版权归原作者 dream_home8407 所有, 如有侵权,请联系我们删除。