
说话人识别(Speaker Recognition)任务
基于深度学习的声纹识别概述(Speaker Recognition Based on Deep Learning: An Overview) - 知乎
共计三种类型,
说话人验证(speaker verification):已知注册人时,给定一条测试音频,来判断当前音频是否由目标说话人发出,关注点是能否准确的给出是或否的判断,是最简单的一个任务;(1:1识别)
说话人辨认(speaker identification):已经注册N个人的时候,给定一个音频,判断当前音频是由哪个人发出的。(1:N识别)
- 这个任务还可以根据说话人的识别范围划分为闭集和开集下的辨认,
- 当确定说话人在注册声纹库里时,是一个N选一的有限范围选一个的闭集任务,- 当不确定当前音频是否在注册声纹库里时,是一个开集任务。
说话人分离( diarization):在一段连续的语音中准确的切分出不同说话人对应的音频,diarization需要解决的通常是无重叠的音频。
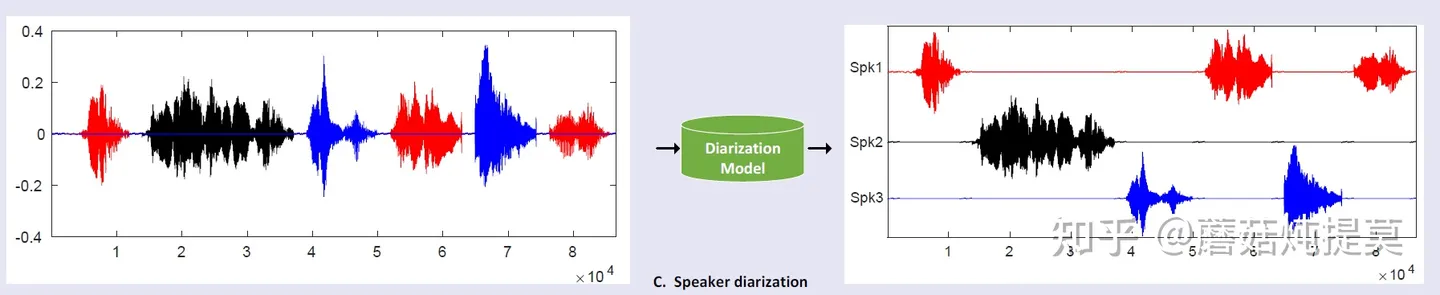 - 这里需要跟另外一个叫声源分离(Speaker separation)任务区分开来,声源分离,通常是解决鸡尾酒会的问题,就是我们的某一段音频中,不同人的说话会有重叠覆盖,这个时候我们任务是在混叠的声音中分离出不同人的声音,这个任务又是一个全新的方向,不在当前的文章里谈。
- 这里需要跟另外一个叫声源分离(Speaker separation)任务区分开来,声源分离,通常是解决鸡尾酒会的问题,就是我们的某一段音频中,不同人的说话会有重叠覆盖,这个时候我们任务是在混叠的声音中分离出不同人的声音,这个任务又是一个全新的方向,不在当前的文章里谈。
原链接Overview:Speaker Recognition Based on Deep Learning: An Overview
本文的参考文献共有311篇,从1964年到2020年的说话人识别论文都有涉及,系统的读参考文献也是了解入门的好方法,能清晰的看到几十年来人们一直在关注什么问题,用什么方法去尝试解决,又在哪些地方有突破性的进展。
新手语音入门(二): 声音检测VAD与话者分离技术简述
新手语音入门(二): 声音检测VAD与话者分离技术简述 |检测错误率 | 准确率 | 召回率 | 分离错误率DER-云社区-华为云
VAD
声音检测常用的指标是识别错率(Detection Error Rate),公式为

其中
- False Alarm, 将非语音片段识别成为语音片段的时间,简称“狼来了”;
- Missed Speech, 将语音片段识别成为非语音片段的时间,简称“脱靶”;
- Total Duration of the Time, 参考语音标注片段的总时长。
新手语音入门(二): 声音检测VAD与话者分离技术简述 |检测错误率 | 准确率 | 召回率 | 分离错误率DER-云社区-华为云
正确率(Accurancy, 预测值将输入标签识别正确的比例),召回率(Recall,预测值中的语音片段占整体语音片段的比例)和准确率(Precision, 检测出来的语音标签中真正的语音标签的比例)。
话者分离 Speaker Diarization
语音会被划分为说话人组,语音非语音的片段或说话人转变等事件会被检测出来。在实际分离过程中,不需要知道说话人是谁。

2.3. 评价标准
话者分离常用的指标是分离错误率(Diarization Error Rate, DER), 指三种错误类型的总和:
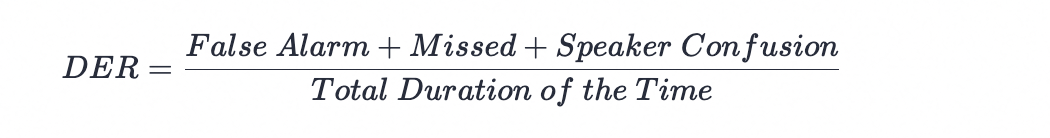
其中
- False Alarm, 将非语音片段识别成为语音片段的时间;
- Missed Speech, 将语音片段识别成为非语音片段的时间;
- Speaker Confusion, 预测语音与参考语音的时间;
- Total Duration of the Time, 参考语音标注片段的总时长。
Speaker Confusion的部分一般由匈牙利算法(Hungarian Algorithm)计算得来。并且常使用Score Collar加到音频片段的边际,以减少不连续标注引起的错误。
话者分离难点
- 事先不知道有多少个说话人;
- 不清楚说话人的ID;
- 多人同时说话;
- 不同语音的音频条件都不同。
用途
- 会议。
- 庭审。
- 广播。
- 质检。
- 语音助手。
版权归原作者 AI_Gump 所有, 如有侵权,请联系我们删除。