
哈喽大家好 ! 我是唐宋宋宋,很荣幸与您相见!!
代码奉上:https://github.com/bubbliiiing/deeplabv3-plus-pytorch
图像分割可以分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),其区别如图所示。
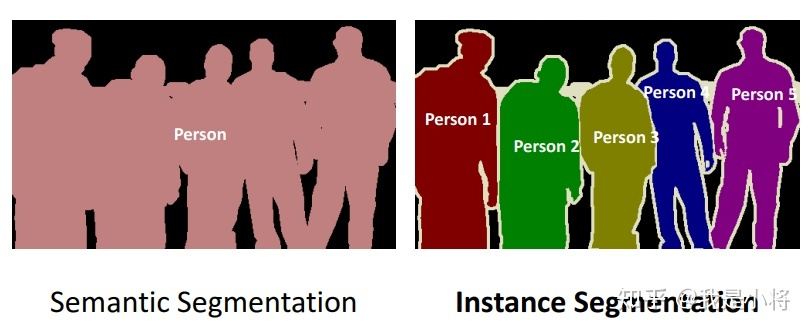
可以看到语义分割只是简单地对图像中各个像素点分类,但是实例分割更进一步,需要区分开不同物体,这更加困难,从一定意义上来说,实例分割更像是语义分割加检测。这里我们主要关注语义分割。
语义分割使用的网络模型有很多比如pspnet,unet/unet++,deeplabv1,v2,v3,v3+,我们这里使用的是Deeplabv3+进行语义分割。
Deeplabv3+整体架构:

由这幅图我们可以发现,其实deeplabV3+模型仍然是两个部分,一个部分是Encoder,一个部分是Decoder
DeepLabv3+模型的整体架构如图所示,它的Encoder的主体是带有空洞卷积的DCNN,可以采用常用的分类网络如ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),主要是为了引入多尺度信息;相比DeepLabv3,v3+引入了Decoder模块,其将底层特征与高层特征进一步融合,提升分割边界准确度。
Deeplabv3+对于Deeplabv系列的改进如下:

引入了对于膨胀卷积的膨胀系数。
改进了空洞空间金字塔池化
移除了条件随机场CFRs后处理,目的(精细化分割)
其实deeplabV3+与pspnet、segnet、unet相比,其最大的特点就是引入了空洞卷积,在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。这有利于提取多尺度信息,如下就是空洞卷积的一个示意图,所谓空洞就是特征点提取的时候会跨像素。
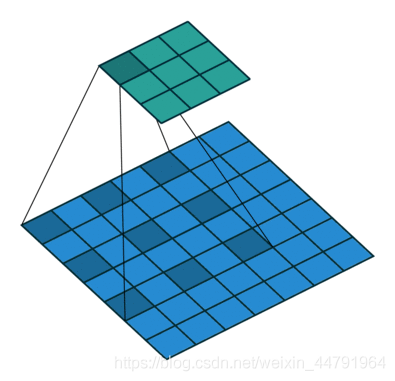
空洞卷积的目的其实也就是提取更有效的特征,所以它位于Encoder网络中用于特征提取。
接着我们先来看一下encoder。
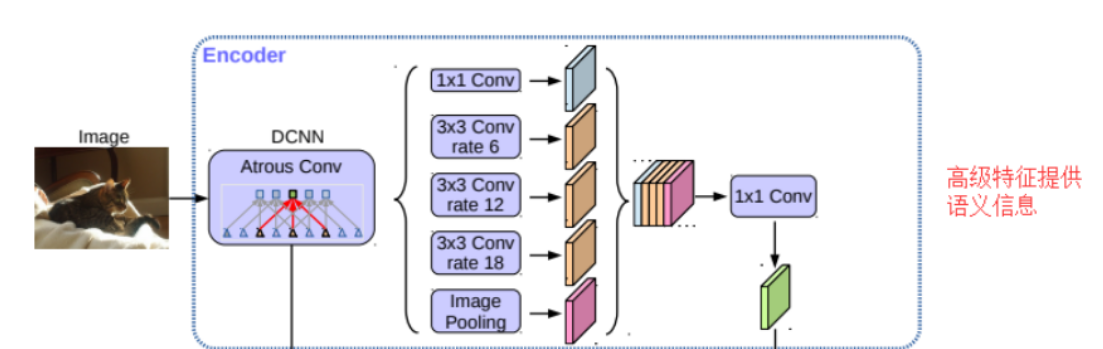
可以看出来这部分由dcnn主干网络加一个aspp组成,dcnn可以使用任意一网络模型,官方使用的是resnet模型,这里我为了更轻量化使用的是基于mobilenet的deeplabv3+,由图可有看到dcnn使用的也是串行结构,然后输出的是两部分,一部分直接输出进入到decoder部分,一部分经过了aspp结构输出进行拼接,然后经过一个1*1的卷积压缩特征。
这里我们重点说一下这个ASPP模型
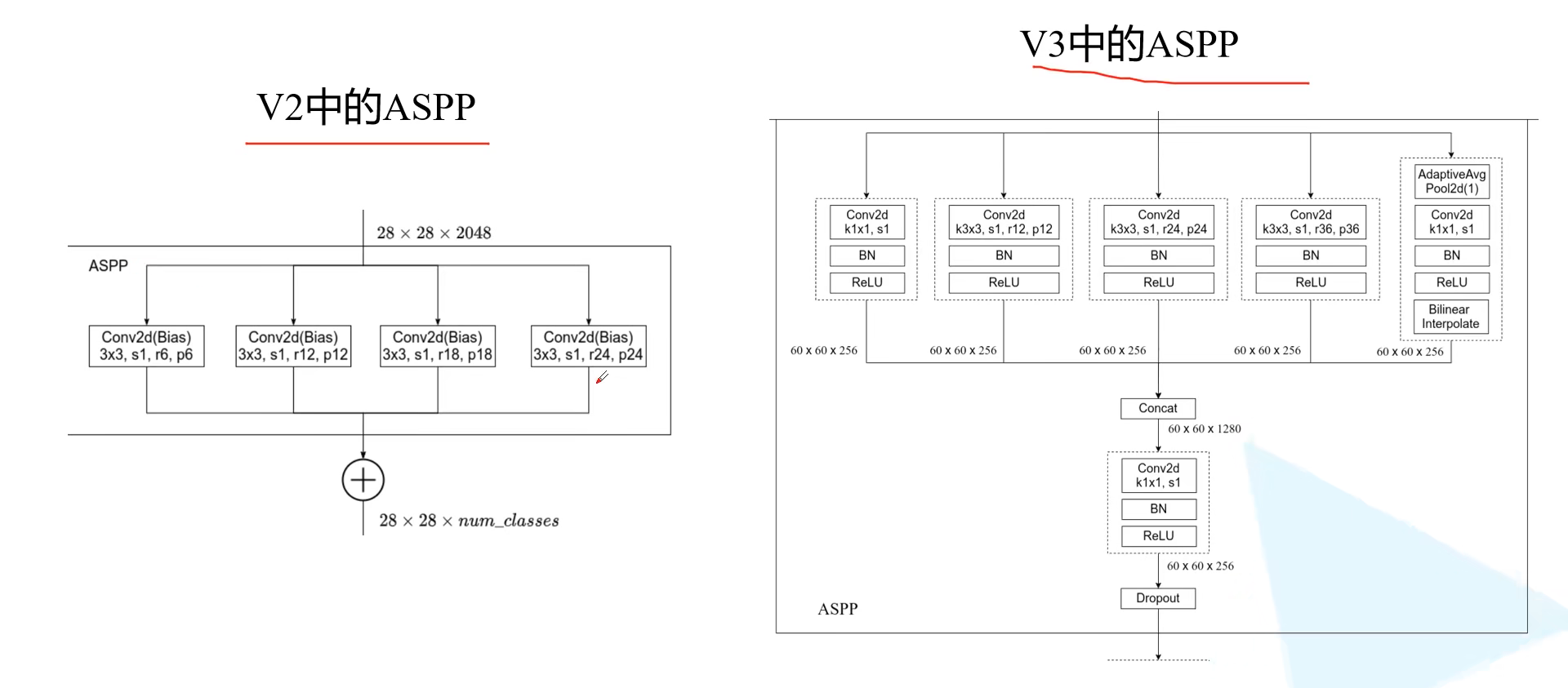
从上图我们可以看出对于Deeplabv2和Deeplabv3+ aspp的一个改进,在v2中仅仅使用了四个33的卷积,然后相加进行一个特征融合,而在v3中我们可以清晰的看到首先是使用了一个11的卷积+一个bn+一个relu 紧接着使用了3个33的卷积(所使用的膨胀系数也是不一样的 这里是12,24,36), 最后加一个全局平均池化(主要在于这里采用池化层来获取多尺度特征)+11大小的卷积+bn+relu+双线性插值来对特征进行上采样来保证特征图大小一样,(注意这里的分支特征大小都是一样规格的才可以拼接)最后对于这五个分支进行一个拼接,然后通过一个1*1的卷积 和一个随机失活进行输出。
然后我们来看一下decoder模块
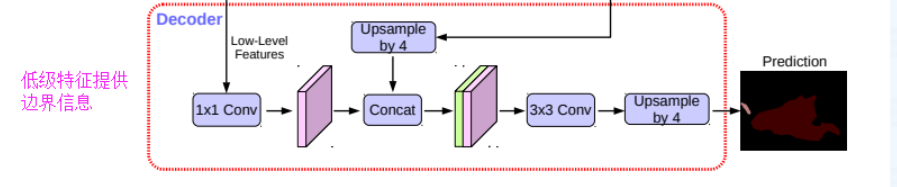
这里的第一个下箭头是我们encoder,dcnn的输出,一个是我们通过aspp的输出,最后进行一个拼接,一个3*3的卷积和一个上采样,这里的上采样是使用双线性插值的方法,最后输出,就是这么简单。
👀👀 理论总结:
deeplabv3+的缺点:
- 预测的feature map 直接双线性上采样16倍,到期望的尺寸,这样会 细节信息不够
deeplabv3+的特点:
使用了 【encoder-decoder】(高层特征提供语义,decoder逐步恢复边界信息):提升了分割效果的同时,关注了边界的信息
使用【ASPP】, 并将【深度可分离卷积(depthwise deparable conv)】应用在了ASPP 和 encoder 模块中,使网络更快。
decoder结构:采用一个简单的模块,用于恢复目标边界细节
deeplabv3+的效果:
- 在PASCAL VOC 2012 和 Cityscaps 数据集上获得 89.0% 和 82.1% 的分割效果,没有添加任何的后处理。
大家看一下我的代码。
dcnn模块使用的是MobileNetV2模型
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
from functools import partial
model = mobilenetv2(pretrained)
self.features = model.features[:-1]
self.total_idx = len(self.features)
self.down_idx = [2, 4, 7, 14]
if downsample_factor == 8:
for i in range(self.down_idx[-2], self.down_idx[-1]):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=4)
)
elif downsample_factor == 16:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
def _nostride_dilate(self, m, dilate):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if m.stride == (2, 2):
m.stride = (1, 1)
if m.kernel_size == (3, 3):
m.dilation = (dilate // 2, dilate // 2)
m.padding = (dilate // 2, dilate // 2)
else:
if m.kernel_size == (3, 3):
m.dilation = (dilate, dilate)
m.padding = (dilate, dilate)
def forward(self, x):
low_level_features = self.features[:4](x)
x = self.features[4:](low_level_features)
return low_level_features, x
ASPP特征提取模块 ,利用不同膨胀率的膨胀卷积进行特征提取,如下
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6 * rate, dilation=6 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12 * rate, dilation=12 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18 * rate, dilation=18 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch5_conv = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=True)
self.branch5_bn = nn.BatchNorm2d(dim_out, momentum=bn_mom)
self.branch5_relu = nn.ReLU(inplace=True)
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out * 5, dim_out, 1, 1, padding=0, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
# 一共五个分支
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
# -----------------------------------------#
# 第五个分支,全局平均池化+卷积
# -----------------------------------------#
global_feature = torch.mean(x, 2, True)
global_feature = torch.mean(global_feature, 3, True)
global_feature = self.branch5_conv(global_feature)
global_feature = self.branch5_bn(global_feature)
global_feature = self.branch5_relu(global_feature)
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
# -----------------------------------------#
# 将五个分支的内容堆叠起来
# 然后1x1卷积整合特征。
# -----------------------------------------#
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
接着是对于这两个模型进行一个总结,我这里做了个选择 可以选择使用原始论文的xception,可以选择我使用的mobilenet
class DeepLab(nn.Module):
def __init__(self, num_classes, backbone="mobilenet", pretrained=True, downsample_factor=16):
super(DeepLab, self).__init__()
if backbone == "xception":
# ----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,256]
# 主干部分 [30,30,2048]
# ----------------------------------#
self.backbone = xception(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 2048
low_level_channels = 256
elif backbone == "mobilenet":
# ----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,24]
# 主干部分 [30,30,320]
# ----------------------------------#
self.backbone = MobileNetV2(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 320
low_level_channels = 24
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, xception.'.format(backbone))
# -----------------------------------------#
# ASPP特征提取模块
# 利用不同膨胀率的膨胀卷积进行特征提取
# -----------------------------------------#
self.aspp = ASPP(dim_in=in_channels, dim_out=256, rate=16 // downsample_factor)
# ----------------------------------#
# 浅层特征边
# ----------------------------------#
self.shortcut_conv = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True)
)
self.cat_conv = nn.Sequential(
nn.Conv2d(48 + 256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(256, num_classes, 1, stride=1)
def forward(self, x):
H, W = x.size(2), x.size(3)
# -----------------------------------------#
# 获得两个特征层
# low_level_features: 浅层特征-进行卷积处理
# x : 主干部分-利用ASPP结构进行加强特征提取
# -----------------------------------------#
low_level_features, x = self.backbone(x)
x = self.aspp(x)
low_level_features = self.shortcut_conv(low_level_features)
# -----------------------------------------#
# 将加强特征边上采样
# 与浅层特征堆叠后利用卷积进行特征提取
# zykandqss
# -----------------------------------------#
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)), mode='bilinear',
align_corners=True)
x = self.cat_conv(torch.cat((x, low_level_features), dim=1))
x = self.cls_conv(x)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
最后我们可以看一下训练好的评价指标,运行代码部分的get_miou.py可以得到一些评价指标,这里可以看一下我的例子。
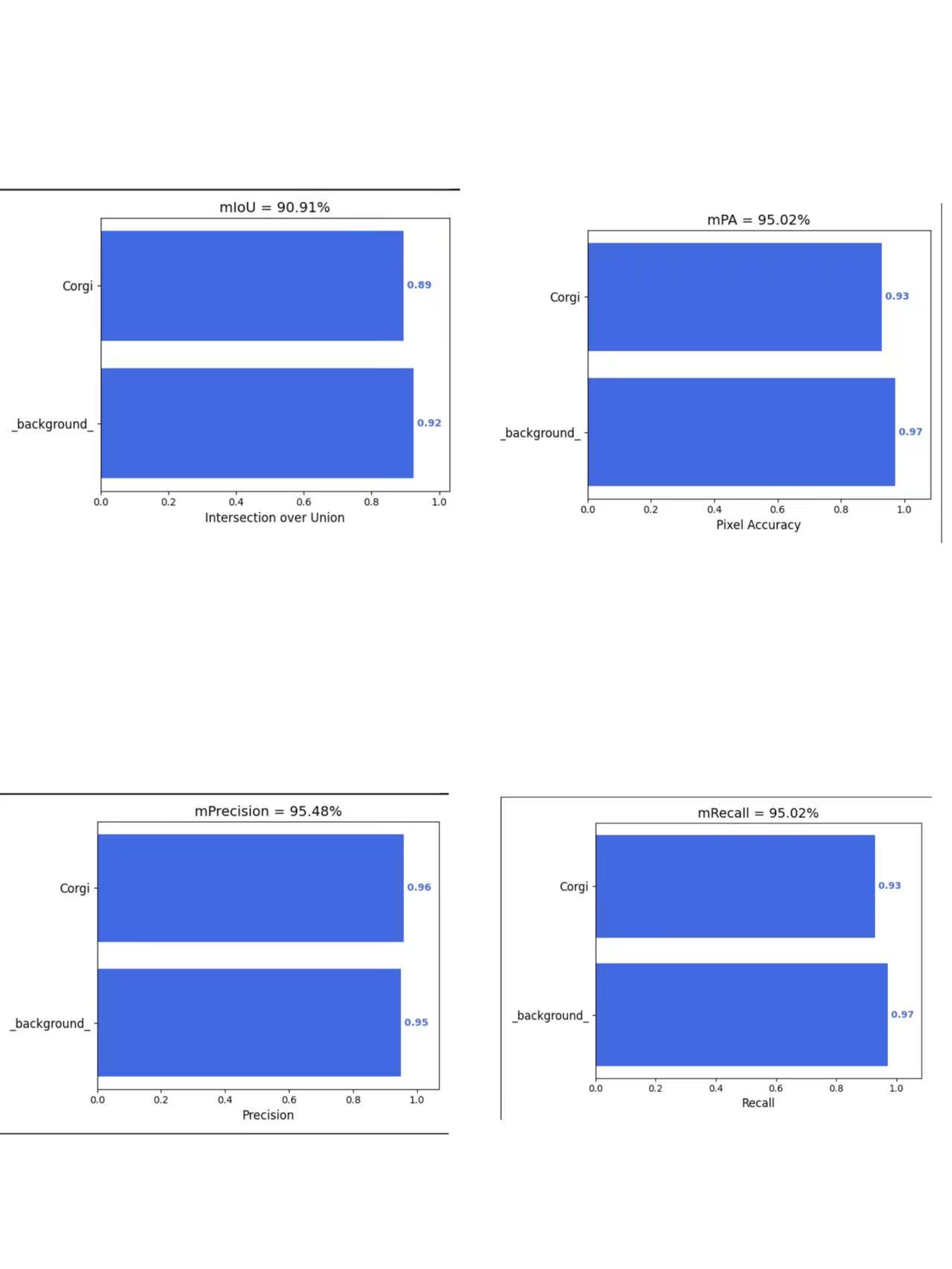
可以看到有miou,map,pre,recall各项指标。
感谢大家阅读!🙏🙏🙏
版权归原作者 唐宋宋宋 所有, 如有侵权,请联系我们删除。