
一.模板匹配
定义:让模板图像在输入图像中滑动逐像素遍历整个图像进行比较,查找出与模板图像最匹配的部分。
单目标匹配
定义:输入图像中只存在一个可能匹配结果
基本格式如下:
result = cv2.matchTemplate(image,templ,method)
- image为输入图像
- templ为模板图像,要小于image
- method为匹配方法,如下: - cv2.TM_SQDIFF:以方差结果为依据进行匹配。完全匹配时结果为零,否则为很大的值- cv2.TM_SQDIFF_NORMED:标准(归一化)方差匹配- cv2.TM_CCORR:相关匹配,将输入图像与模板图像相乘,乘积越大匹配程度越高,乘积为0匹配程度最低- cv2.TM_CCORR_NORMED:标准(归一化)相关匹配- cv2.TM_CCOEFF:相关系数匹配,将输入图像于其均值的相关性和模板图像与其均值的相关值进行匹配。1为完美匹配,-1并表示糟糕匹配,0表示没有任何相关性。- cv2.TM_CCOEFF_NORMED:标准(归一化)相关系数匹配
- result为返回结果。当匹配方法为前两个时,匹配结果值越小匹配度越高,越大匹配度越低。当为后四个时值越小说明匹配度越低,反之则说明匹配度越高。
opencv中的cv2.minMaxLoc()函数用于处理匹配结果
minVal,maxVal,minLocmmaxLoc=cv2.minMaxLoc(src)
- src是上面的matchTemplate()函数的返回结果
- minVal(maxVal)为src中的最小值(最大值),不存在时可以为NULL(空值)
- minLoc(MaxLoc)为src中最小值(最大值)的位置,不存在时可以为NULL
实例代码如下
import cv2
import numpy as np
import matplotlib. pyplot as plt
img1=cv2. imread( 'img/a.jpg')
cv2. imshow( ' original', img1)
temp=cv2. imread( 'img/b.jpg' )
cv2. imshow('template',temp)
img1gray=cv2. cvtColor(img1, cv2.COLOR_BGR2GRAY,dstCn=1)
tempgray=cv2. cvtColor(temp, cv2.COLOR_BGR2GRAY,dstCn=1)
h, w=tempgray.shape
res=cv2. matchTemplate(img1gray, tempgray,cv2.TM_SQDIFF)
plt.imshow(res,cmap = 'gray')
plt.title( 'Matching Result')
plt.axis('off')
plt. show()
min_val,max_val,min_loc,max_loc=cv2 .minMaxLoc(res)
top_left = min_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img1,top_left, bottom_right,(255,0,0),2)
cv2. imshow(' Detected Range ',img1)
cv2. waitKey(0)
原图像:
模板图像:
匹配结果:
本次用了cv2.TM_SQDIFF作为匹配方法,所以值越小匹配度就越高。用灰度图像格式显示匹配结果,所以图中颜色越深的位置匹配度越高
模板图像在原图当中的位置:
多目标匹配
定义:输入图像中存在多个可能的匹配
以查找象棋为例,查找“卒象棋”: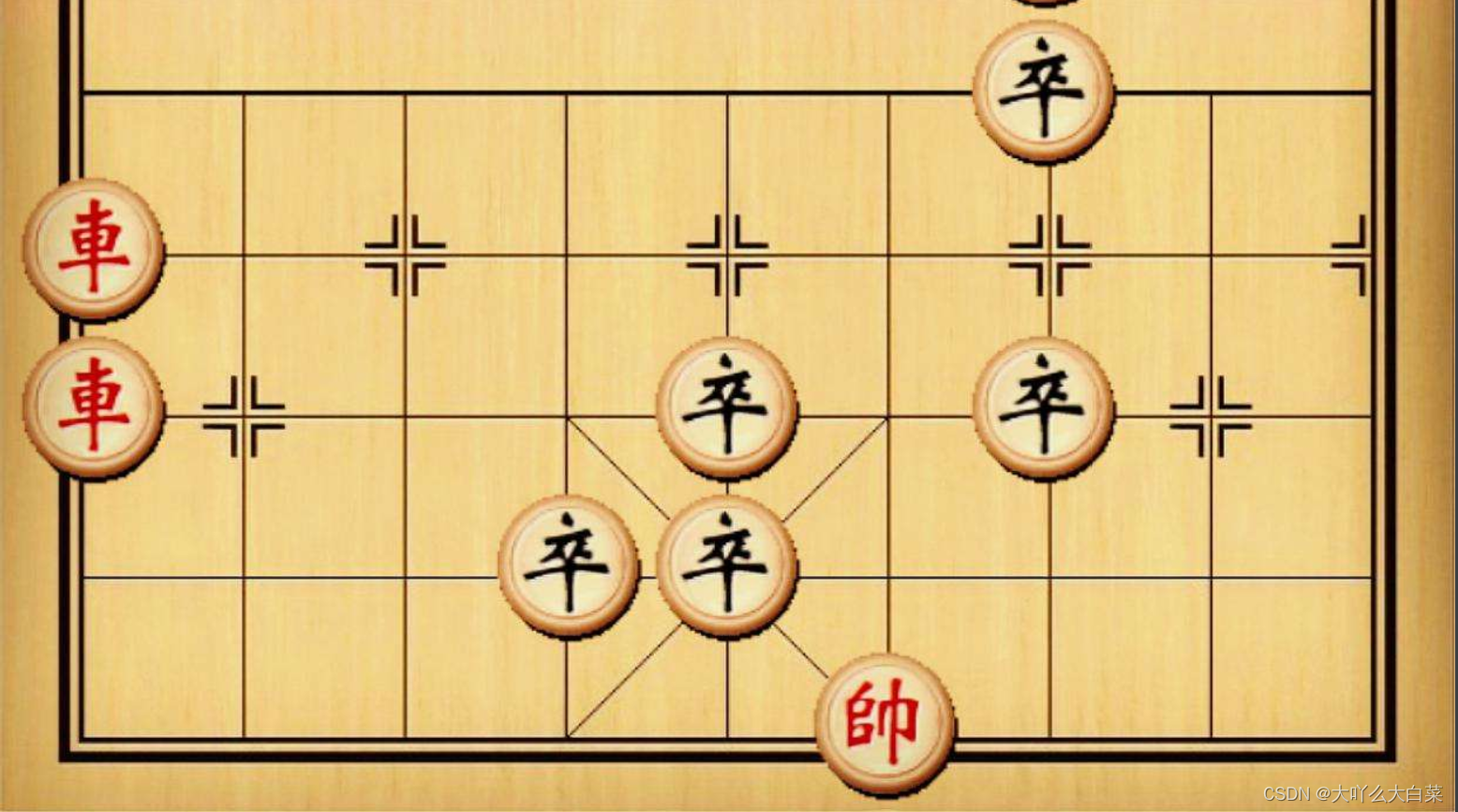
模板图像:
代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img1=cv2. imread('img/d.jpg') #打开输入图像,默认为BGR格式
temp=cv2. imread('img/e.jpg') #打开模板图像
img1gray=cv2. cvtColor(img1, cv2. COLOR_BGR2GRAY, dstCn=1) #转换为单通道灰度图像
tempgray=cv2. cvtColor(temp,cv2. COLOR_BGR2GRAY , dstCn=1) #转换为单通道灰度图像
th, tw=tempgray.shape #获得模板图像的高度和宽度
img1h, img1w= img1gray. shape
res = cv2.matchTemplate(img1gray, tempgray, cv2.TM_SQDIFF_NORMED) #执行匹配操作
mloc=[] #用于保存符合条件的匹配位置
threshold = 0.02 #设置匹配度阈值
for i in range(img1h-th): #查找符合条件的匹配结果位置
for j in range(img1w-tw):
if res[i][j]<=threshold: #保存小于阈值的匹配位置
mloc.append((j,i))
for pt in mloc:
cv2.rectangle(img1,pt, (pt[0]+tw,pt[1]+th),(255,0,0),2) #标注匹配位置,蓝色
cv2. imshow( ' result' ,img1) #显示结果
cv2.waitKey(0)
这种多目标匹配相较于上面的单目标的区别主要在于通过threshold,设置匹配度的阈值来筛选匹配位置。因为上面代码采用的模板匹配方法是cv2.TM_SQDIFF_NORMED,匹配结果越小匹配度越高。所以小于匹配度阈值的会被筛选出来。结果如下: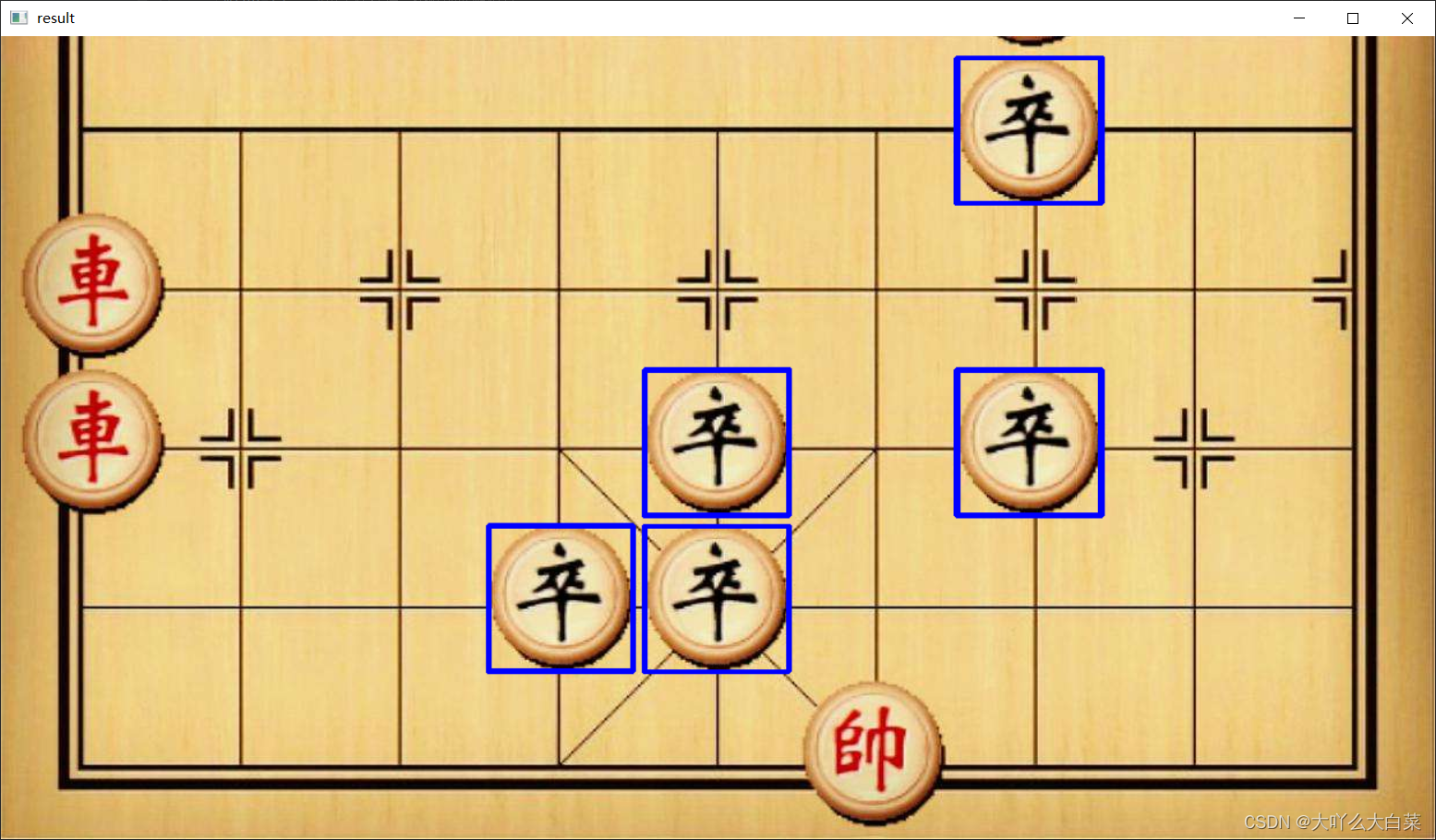
二.图像分割
本节采用分水岭算法和图像金字塔对图像进行分割的方法
使用分水岭算法分割图像
基本原理:将任意的灰度图像视为地形图表面,其中灰度值高的部分表示山峰和丘陵,灰度值低的部分表示山谷。用不同的颜色的水(标签)填充每个独立的山谷(局部最小值);随着水平面的上升,来自不同山谷(具有不同颜色)的水将开始合并。为了避免出现这种现象,需要在水的汇合位置建造水坝;持续填充水和建造水坝,直至所有的山峰和丘陵都在水下。整个过程中建造的水坝将作为图像分割的依据。
分水岭算法分割图像步骤:
- 将源图像转换为灰度图像
- 运用开运算(先腐蚀后膨胀,去除图像中的细小白色噪点)和膨胀操作(膨胀运算使得一部分背景成为了物体的边界,因为先进行了二值化处理得到的图像中的黑色区域肯定是真实背景)
- 进行距离转换(用下面函数,其中每个像素的值为其到最近的背景像素(灰度值为0)的距离,而中心像素值最大(中心离背景像素最远)。对其进行二值处理就得到了分离的前景图),再进行阈值处理,确定图像前景
- 确定图像的未知区域(用图像的背景减去前景的剩余部分,可能是边界的部分)
- 标记背景图像
- 执行分水岭算法分割图像
此处有算法详细的解释
我们需要给不同区域贴上不同的标签。用大于1的整数表示我们确定为前景或对象的区域,用1表示我们确定为背景或非对象的区域,最后用0表示我们无法确定的区域。然后应用分水岭算法,我们的标记图像将被更新,更新后的标记图像的边界像素值为-1。
cv2.distanceTransform()函数用来计算非0值像素点到0值(背景)像素点的距离
dst=cv2.distanceTransform(src,distanceType,maskSize[,dstType])
- dst为返回的距离转换结果图像
- src为原图像
- distanceType为距离类型
- maskSize为掩模的大小,可设置为0、3、5.
- dstType为返回的图像类型,默认为CV_32F(32位浮点数)
import cv2
import numpy as np
img=cv2. imread( 'img/aa.jpg' )
cv2. imshow('original',img) #显示原图
gray=cv2. cvtColor( img, cv2. COLOR_BGR2GRAY) #转换为灰度图
ret, imgthresh=cv2. threshold(gray,0,255,cv2. THRESH_BINARY_INV+cv2.THRESH_OTSU) #Otsu算法阈值处理
kernel=np.ones((3,3),np.uint8) #定义形态变换卷积核
imgopen=cv2 . morphologyEx(imgthresh,cv2.MORPH_OPEN,kernel, iterations=2) #形态变换:开运算
imgdist=cv2. distanceTransform( imgopen,cv2.DIST_L2,3) #距离转换
cv2. imshow('distance',imgdist) #显示距离转换结果
cv2. waitKey(0)
原图:注意最上面的圆中的十字星中的里面也是十字星
距离转换结果图:十字星变成了椭圆形,因为星星的角上进行距离转换后的图形颜色会比较浅,在进行阈值处理就会被处理成白色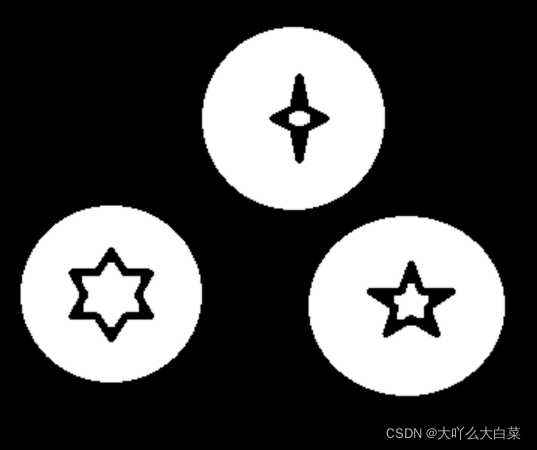
cv2.connectedComponents()函数用于将图像中的背景标记为0,将其他图像标记为1开始的整数
格式如下:
ret,labels=cv2.connectedComponents(image[,connectivity[,ltype]])
参数说明如下:
- labels为返回的标记结果图像,和image大小相同
- image为要标记的8位单通道图像
- connectivity为4或8(默认值)
- ltype为返回的标记结果图像的类型
ret, imgfg=cv2.threshold(imgdist,0.7*imgdist.max(),255,2) #对距离转换结果进行阈值处理
imgfg=np.uint8(imgfg) #转换为整数
ret,markers=cv2.connectedComponents(imgfg) #标记阈值处理结果
cv2.watershed()函数用于执行分水岭算法分割图像,基本格式如下
ret=cv2.watershed(image,markers)
- ret为返回的8位或32位单通道图像
- image为输入的8位3通道图像
- markers为输入的32位单通道图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2. imread('img/ccc.jpg')
gray=cv2. cvtColor(img, cv2.COLOR_BGR2GRAY) #转换为灰度图
ret, imgthresh=cv2. threshold(gray, 0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) #Otsu算法阈值处理
kernel=np . ones((5,5), np.uint8) #定义形态变换卷积核
imgopen=cv2. morphologyEx(imgthresh, cv2.MORPH_OPEN,kernel, iterations=2) #形态变换:开运算
imgbg=cv2. dilate( imgopen, kernel, iterations=3) #膨胀操作,确定背景
imgdist=cv2. distanceTransform( imgopen, cv2.DIST_L2,0) #距离转换
ret, imgfg=cv2. threshold(imgdist,0.7*imgdist .max(),255,2) #对距离转换结果进行阈值处理
imgfg=np.uint8( imgfg) #转换为整数,获得前景图像
ret,markers=cv2. connectedComponents(imgfg) #标记阈值处理结果
unknown= cv2. subtract(imgbg, imgfg) #确定位置未知区域
markers=markers+1 #加1使背景不为0
markers[unknown==255]=0 #将未知区域设置为0
imgwater=cv2. watershed(img, markers) #执行分水岭算法分割图像
plt. imshow( imgwater) #以灰度图像格式显示匹配结果
plt. title( 'watershed')
plt.axis('off')
plt. show()
img[ imgwater==-1]=[0,255,0] #将原图中的被标记点设置为绿色
cv2. imshow('watershed',img) #显示分割结果
cv2.waitKey(0)
分水岭算法返回的结果图像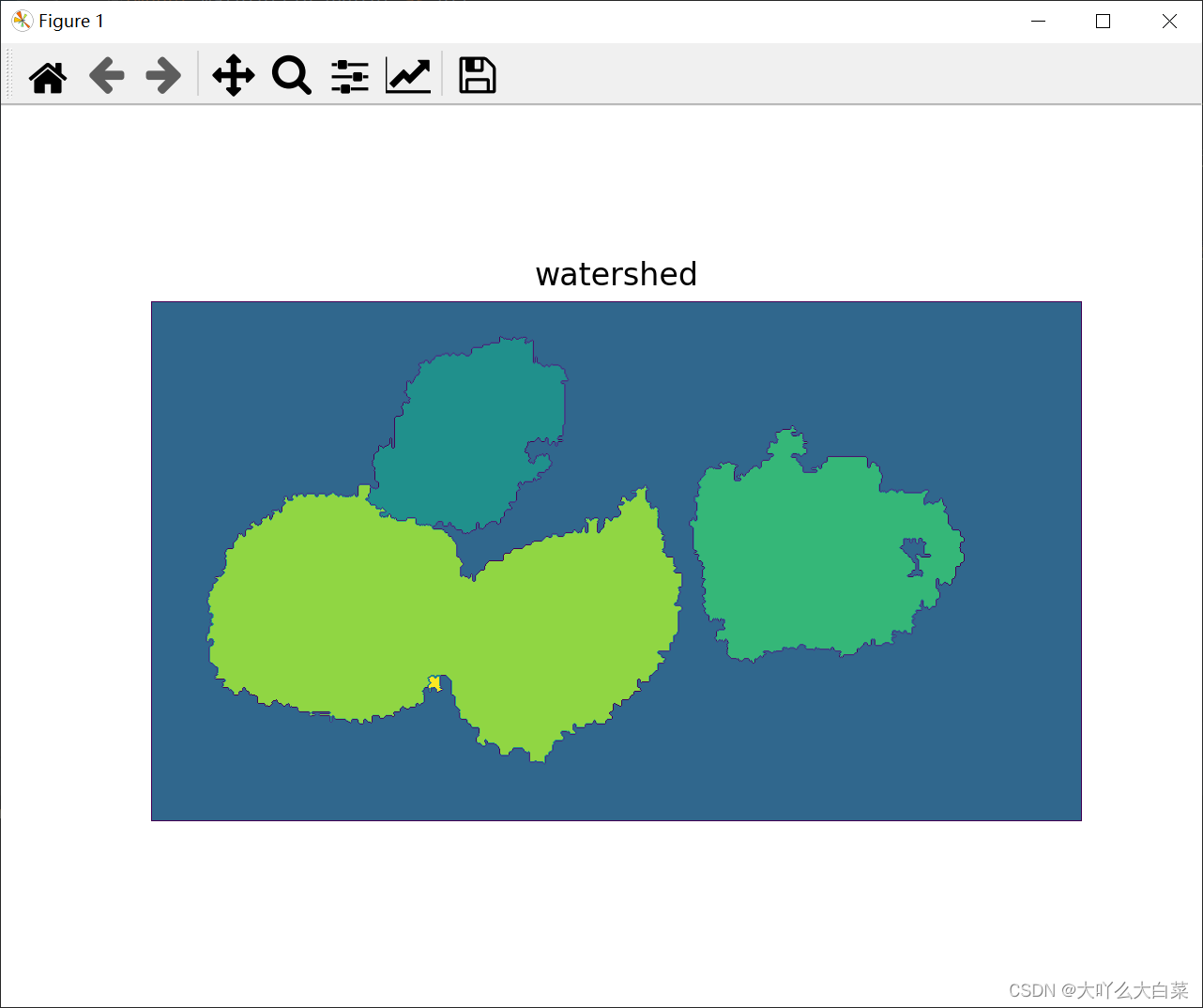
原图中标记的分割结果(绿色为分割线):
图像金字塔
图像金字塔从分辨率的角度分析处理图像。图像金字塔的底部为原始图像,对原始图像进行梯次向下采样,得到金字塔的其他各层图像。层次越高,分辨率越低,图像越小。通常,每向上一层,图像的宽度和高度就为下一层的一半。常见的图像金字塔可分为高斯金字塔和拉普拉斯金字塔。
高斯金字塔有向下和向上两种采样方式。向下采样时,原始图像为第0层,第1次向下采样的结果为第1层,第2次向下采样的结果为第2层,依此类推。 每次采样图像的高度和宽度都减小为原来的一 半,所有的图层构成高斯金字塔。 向上采样的过程和向下采样相反 ,每次采样图像的高度和宽度 都扩大为原来的二倍。
高斯金字塔向下采样
cv2.pyrDown() 函数基本格式如下:
ret=cv2.pyrDown(image[,dstsize[,borderType]])
- ret为返回的结果图像,类型和输入图像相同
- image为输入图像
- dstsize为结果图像大小
- borderType为边界值类型
import cv2
img0=cv2. imread('img/dd.jpg')
img1=cv2. pyrDown( img0) #第1次采样
img2=cv2. pyrDown(img1) #第2次采样
cv2. imshow( ' img0', img0) #显示第0层
cv2. imshow( ' img1',img1) #显示第1层
cv2. imshow( ' img2',img2) #显示第2层
print('0层形状: ', img0.shape) #输出图像形状
print('1层形状: ',img1.shape) #输出图像形状
print('2层形状:', img2. shape) #输出图像形状
cv2. waitKey(0)
结果: 可见高和宽依次减为原来一半
0层形状: (447, 706, 3)
1层形状: (224, 353, 3)
2层形状: (112, 177, 3)
三个图片分别为原图,第一次采样,第二次采样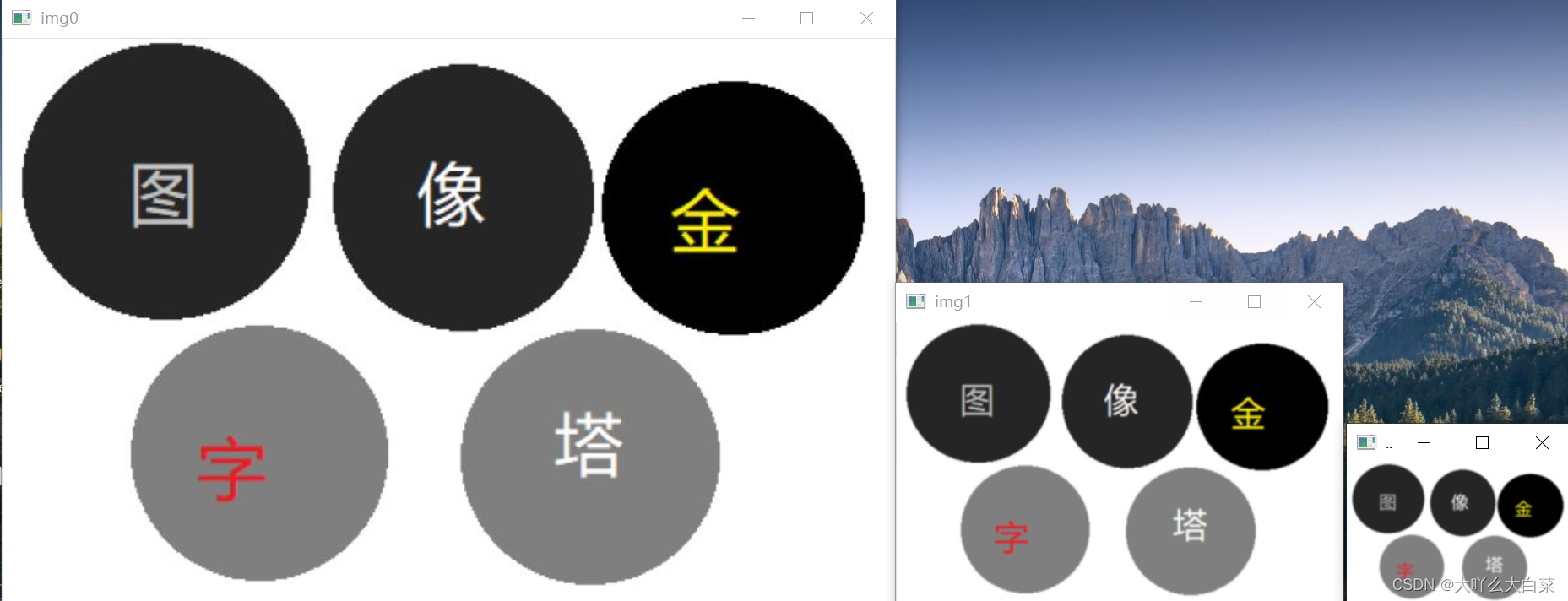
高斯金字塔向上采样
cv2.pyrUp() 函数基本格式如下
ret=cv2.pyrUp(image[,dstsize[,borderType]])
- ret 为返回的结果图像,类型和输入图像相同
- image为输入图像
- dstsize为结果图像大小
- borderType为边界值类型
import cv2
img0=cv2. imread('img/ee.jpg')
img1=cv2. pyrUp( img0) #第1次采样
img2=cv2. pyrUp(img1) #第2次采样
cv2. imshow( ' img0', img0) #显示第0层
cv2. imshow( ' img1',img1) #显示第1层
cv2. imshow( ' img2',img2) #显示第2层
cv2. waitKey(0)
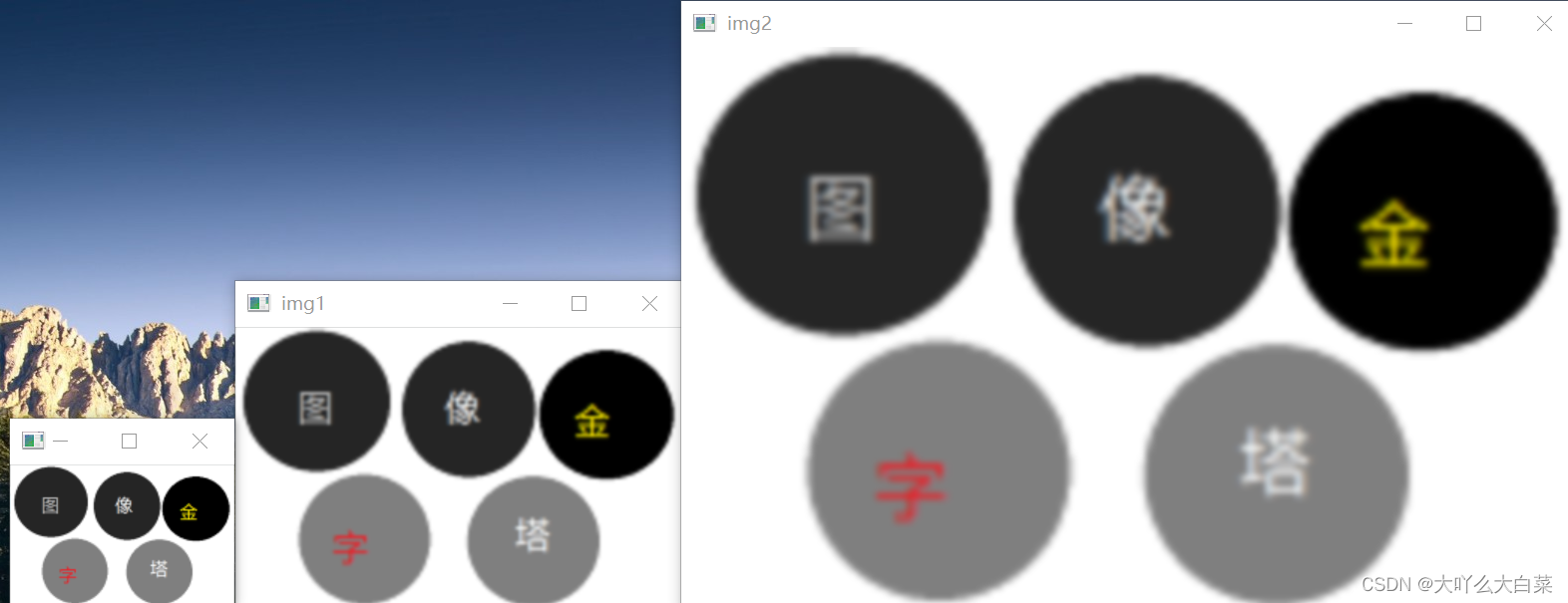
拉普拉斯金字塔
拉普拉斯金字塔的第n层是该层高斯金字塔图像减去第n+1层向上采样结果获得的图像
注意:N层的拉普拉斯金字塔,图像的宽度和高度就应该是2的N次方的整倍数
示例代码:
import cv2
img0=cv2. imread('img/ff.jpg' )
img1=cv2. pyrDown(img0) #第1次采样
img2=cv2. pyrDown(img1) #第2次采样
img3=cv2. pyrDown(img2) #第3次采样
imgL0= cv2. subtract(img0,cv2.pyrUp(img1)) #拉普拉斯金字塔第0层
imgL1= cv2. subtract(img1,cv2.pyrUp(img2)) #拉普拉斯金字塔第1层
imgL2= cv2. subtract(img2,cv2.pyrUp(img3)) #拉普拉斯金字塔第2层
cv2. imshow( ' imgL0',img0) #显示第0层
cv2. imshow( ' imgL1',img1) #显示第1层
cv2. imshow( ' imgL2',img2) #显示第2层
cv2. waitKey(0)
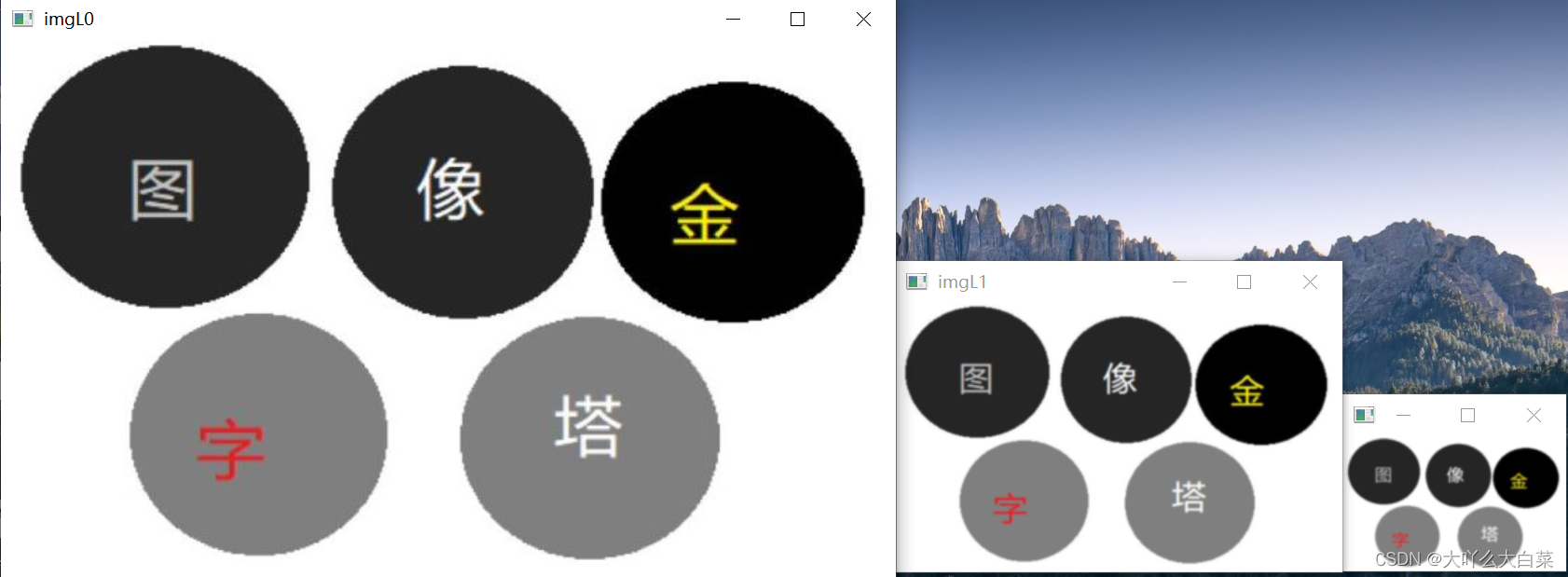
交互式前景提取
交互式前景提取的基本原理如下。
首先,用一个矩形指定要提取的前景所在的大致范围,然后执行前景提取算法,得到初步结果。初步结果中包含的前景可能并不理想,存在前景未提取完整或者背景被处理为前景等问题。此时需要人工干预(体现交互),甩户需要复制原图像作为掩模图像,在其中用白色标注要提取的前景区域,用黑色标注背景区域,标注并不需要很精确。然后,使用掩模图像执行前景提取算法从而获得理想的提取结果。
cv2.grabCut() 函数用于实现前景提取,基本格式如下:
mask2,bgdModel,fgdModel = cv2.frabCut(img,mask1,reck,bgdModel,fgdModel,iterCount[,mode])
参数说明如下
- mask1为输入的8位单通道掩模图像,用于指定图像的哪些区域可能是背景或前景。
- mask2为输出的掩模图像,其中的0表示确定的背景,1 表示确定的前景,2表示可能的背景,3表示可能的前景。
- bgdModel和fgdModel为用于内部计算的临时数组, 需定义为大小是1 x 65的np.float64类型的数组,数组元素值均为0。
- img为输入的8位3通道图像。
- rect为矩形坐标,格式为“(左上角的横坐标x,左上角的纵坐标y,宽度,高度)”。要提取的前景图像在矩形内部,将矩形的外部视为背景。mode参数设置为使用矩形模板时,rect 参数才有效。
- iterCount为迭代次数。
- mode为前景提取模式,可设置为下列值。 - cv2.GC_ INIT_ WITH_ RECT:使用矩形模板。- cv2.GC_ INIT_ WITH_ MASK: 使用自定义模板。- cv2.GC_ EVAL:使用修复模式。- cv2.GC_ EVAL_ FREEZE_ _MODEL:使用固定模式。
import cv2
import numpy as np
img = cv2. imread( 'img/qwe.jpg' )
cv2. imshow( ' original',img)
mask = np. zeros(img. shape[:2],np.uint8)
#定义与原图大小相同的掩模图像
bg = np.zeros((1, 65) ,np. float64)
fg = np.zeros((1,65),np. float64)
rect = (150,0,360,330)
#根据原图设置包含前景的矩形大小
cv2. grabCut(img,mask, rect, bg, fg,5,cv2.GC_INIT_WITH_RECT) #提取前景
#将返回的掩模图像中像素值为0或2的像素设置为0 (确认为背景)
#将所有像素值为1或3的像素设置为1 (确认为前景)
mask2 = np.where((mask==2)|(mask==0),0,1).astype( 'uint8')
img=img*mask2[:, :, np. newaxis] #将掩模图像与原图像相乘,获得分割出来的前景图像
cv2. imshow( ' grabCut ',img) #显示获得的前景
cv2.waitKey(0)
原图:
提取前景图片:
此时图片提取的前景并不完整,用黑色和白色的线标注背景和前景,代码为:
import cv2
import numpy as np
img = cv2.imread('img/qwe.jpg')
mask = np.zeros(img. shape[:2],np.uint8) #定义原始掩模图像
bg = np.zeros((1,65),np. float64)
fg = np.zeros((1,65),np. float64)
rect = (130,0,360,330)
cv2. grabCut(img,mask,rect, bg,fg,5,cv2.GC_INIT_WITH_RECT) #第1次提取前景,矩形模式
imgmask = cv2. imread('img/qwee.jpg') #读取已标注的掩模图像
cv2. imshow( ' mask image ',imgmask)
mask2 = cv2. cvtColor( imgmask, cv2. COLOR_BGR2GRAY, dstCn=1) #转换为单通道灰度图像
mask[mask2==0]=0 #将掩模图像中黑色像素对应的原始掩模像素设置为0
mask[mask2==255]=1 #将掩模图像中白色像素对应的原始掩模像素设置为1
cv2. grabCut( img , mask, None,bg,fg,5,cv2.GC_INIT_WITH_MASK) #第2次提取前景,掩模模式
#将返回的掩模图像中像素值为0或2的像素设置为0 (确认为背景)
#将所有像素值为1或3的像素设置为1 (确认为前景)
mask2 =np.where( (mask==2)|(mask==0),0,1).astype('uint8')
img =img*mask2[:,:,np.newaxis] #将掩模图像与原图像相乘获得分割出来的前景图像
cv2. imshow( 'grabCut',img) #显示获得的前景
cv2. waitKey(0)
标注了背景和前景的掩膜图像:
干预后提取的前景图片:·
版权归原作者 大吖么大白菜 所有, 如有侵权,请联系我们删除。