
Mask RCNN作为实例分割的经典算法,对于图像分割的初学者来说,还是很有必要了解下的。
原mask rcnn的Tensorflow版本是1.13,这里提供tf2.5的mask rcnn的github源码地址:https://github.com/zouyuelin/MASK_RCNN_2.5.0
一、制作数据集
1.下载安装labelme
利用labelme制作实例分割数据集_Jiazhou_garland的博客-CSDN博客_labelme实例分割利用labelme制作实例分割数据集一、软件安装与环境配置二、利用labelme做实例分割标记三、利用labelme生成voc与coco格式数据集关于coco数据集的理解其它一些可能出现的问题一、软件安装与环境配置参考上一篇博客二、利用labelme做实例分割标记容易出现的一些问题:当一张图片里同个类别有多个物体时,均使用同一种类名称作为标签进行标注(因为后文coco数据集格式会给同种物体单独分序号)。如下图三人均属于person类。当一张图片里某个颗粒被遮挡时,利用labelme标签https://blog.csdn.net/qq_43019433/article/details/124583352
2.标注数据集
可以自己找图片,用labelme进行标注,标注工作很枯燥耗时,如果不想自己标注,可以使用本项目提供的标注好的数据集。 该数据集饮水机是自己标注的,其他几个类是从coco数据集转化成labelme标注格式的。从coco数据集提取自己想要的类和数量,转化成labelme格式是很实用的操作,不用自己手工标注,转换脚本refine_by_class.py配置如下:
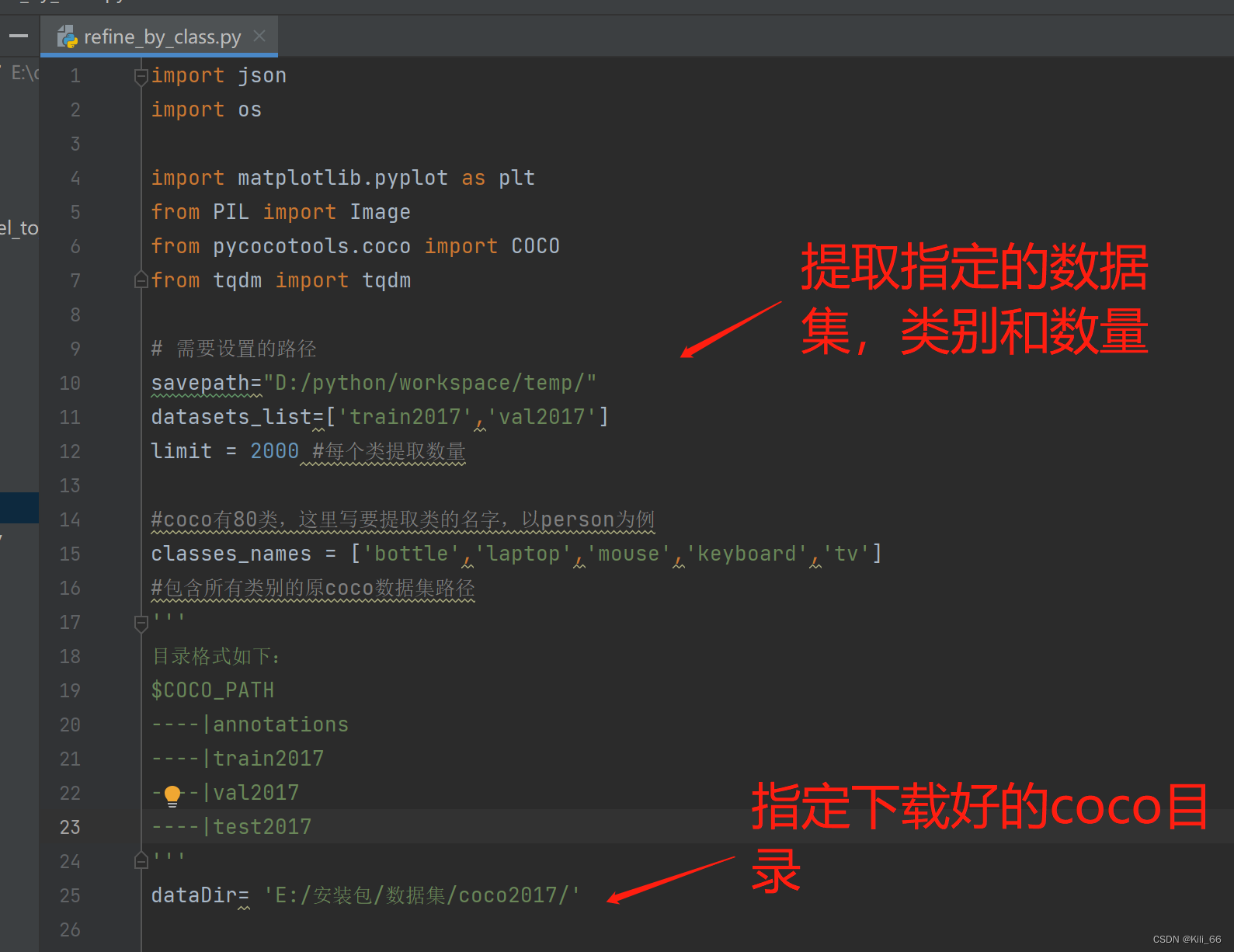
import json
import os
import matplotlib.pyplot as plt
from PIL import Image
from pycocotools.coco import COCO
from tqdm import tqdm
# 需要设置的路径
savepath="D:/python/workspace/temp/"
datasets_list=['train2017','val2017']
limit = 3000 #每个类提取数量
#coco有80类,这里写要提取类的名字,以person为例
classes_names = ['person','dog','cat']
#包含所有类别的原coco数据集路径
'''
目录格式如下:
$COCO_PATH
----|annotations
----|train2017
----|val2017
----|test2017
'''
dataDir= 'E:/datasets/coco2017/'
# 检查目录是否存在,如果存在,先删除再创建,否则,直接创建
def mkr(path):
if not os.path.exists(path):
os.makedirs(path) # 可以创建多级目录
def id2name(coco):
classes=dict()
for cls in coco.dataset['categories']:
classes[cls['id']]=cls['name']
return classes
def refine(coco,dataset,img,classes,cls_ids,show=True):
img_dir = savepath+'/'+dataset+ '/images/'
anno_dir = savepath+'/'+dataset + '/annotations/'
mkr(img_dir)
mkr(anno_dir)
global dataDir
I=Image.open('%s/%s/%s/%s'%(dataDir,dataset,dataset,img['file_name']))
#通过id,得到注释的信息
annIds = coco.getAnnIds(imgIds=img['id'], catIds=cls_ids, iscrowd=None)
# print(annIds)
anns = coco.loadAnns(annIds)
# print("### ", anns)
# coco.showAnns(anns)
#构建labelme格式json数据
labelme_json ={"version":"","flags":{},"shapes":[],"imagePath":"","imageData":"","imageHeight":"","imageWidth":""}
labelme_json["imageHeight"] = img["height"]
labelme_json["imageWidth"] = img["width"]
labelme_json["imagePath"] = "..\\images\\"+img['file_name']
objs = []
for ann in anns:
class_name=classes[ann['category_id']]
if class_name in classes_names:
#提取bbox
if 'bbox' in ann:
bbox=ann['bbox']
xmin = int(bbox[0])
ymin = int(bbox[1])
xmax = int(bbox[2] + bbox[0])
ymax = int(bbox[3] + bbox[1])
obj = [class_name, xmin, ymin, xmax, ymax]
objs.append(obj)
# draw = ImageDraw.Draw(I)
# draw.rectangle([xmin, ymin, xmax, ymax])
#提取分割标注
x = ann['segmentation'][0][::2] # 奇数个是x的坐标
y = ann['segmentation'][0][1::2] # 偶数个是y的坐标
shape = {"label": class_name, "points": [], "group_id": ann['category_id'], "shape_type": "polygon","flags": {}}
for j in range(len(x)):
shape['points'].append([x[j], y[j]])
labelme_json['shapes'].append(shape)
print("### labelme json: ",labelme_json)
#保存json和图片
with open(anno_dir+class_name+"_"+img['file_name'].replace(".jpg",".json"), 'w', encoding='utf-8') as json_file:
json.dump(labelme_json, json_file, ensure_ascii=False)
I.save(img_dir+img['file_name'])
print("write image and json file success!")
if show:
plt.figure()
plt.axis('off')
plt.imshow(I)
plt.show()
return objs
for dataset in datasets_list:
#./COCO/annotations/instances_train2017.json
annFile='{}/annotations_trainval2017/annotations/instances_{}.json'.format(dataDir,dataset)
#使用COCO API用来初始化注释数据
coco = COCO(annFile)
#获取COCO数据集中的所有类别
classes = id2name(coco)
print(classes)
#[1, 2, 3, 4, 6, 8]
classes_ids = coco.getCatIds(catNms=classes_names)
print(classes_ids)
count = {}
for cls in classes_names:
count[cls] = 0
#获取该类的id
cls_id=coco.getCatIds(catNms=[cls])
img_ids=coco.getImgIds(catIds=cls_id)
print(cls,len(img_ids))
# imgIds=img_ids[0:10]
for imgId in tqdm(img_ids):
if(count[cls] > limit):
print("### class_id:{}数量已满足{}".format(cls,limit))
break
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
# print(filename)
try:
# 第五个参数,cls_id表示只提取图片里的这一个类,classes_ids表示提取图片符合要求的多个类
objs=refine(coco, dataset, img, classes,cls_id,show=False)
count[cls] += 1
except Exception as e:
print(e)
continue
print(objs)
# save_annotations_and_imgs(coco, dataset, filename, objs)
转换成功后会生成annotation和images两个文件夹,一个是labelme标注的json,一个是原始图片。网盘下载链接:https://pan.baidu.com/s/13OPmawjn_aj_qH35H7yOtQ 提取码:6666
3.labelme数据集转化
将训练集和验证集转换成项目需要的数据格式,使用如下的labelme_json_to_dataset.py代码

# -*- coding: utf-8 -*-
import argparse
import json
import os
import os.path as osp
import traceback
import warnings
import imgviz
import PIL.Image
import yaml
from labelme.logger import logger
from labelme import utils
import base64
def main():
# warnings.warn("This script is aimed to demonstrate how to convert the\n"
# "JSON file to a single image dataset, and not to handle\n"
# "multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
filepath = json_file.replace("/\\", "/")
print("##### dir_path:",filepath)
count = os.listdir(filepath)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
try:
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = imgviz.label2rgb(label=lbl, img=imgviz.rgb2gray(img), label_names=label_names, loc='rb')
# lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
save_folder_name = out_dir # 文件夹名称
split_file_name = osp.basename(count[i]).split('.') # 分隔文件名和文件类型
save_file_name = split_file_name[0]
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(json_file + '/' + 'labelme_json'):
os.mkdir(json_file + '/' + 'labelme_json')
mask_info = json_file + 'labelme_json'
out_dir1 = mask_info + '/' + save_folder_name
if not osp.exists(out_dir1):
os.mkdir(out_dir1)
PIL.Image.fromarray(img).save(osp.join(out_dir1, 'img.png')) # save_file_name文件名
# PIL.Image.fromarray(lbl).save(osp.join(out_dir1, save_file_name+'_label.png'))
utils.lblsave(osp.join(out_dir1, 'cv2_mask.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir1, 'label_viz.png'))
if not osp.exists(json_file + '/' + 'cv2_mask'):
os.mkdir(json_file + '/' + 'cv2_mask')
mask_save2png_path = json_file + '/' + 'cv2_mask'
if not osp.exists(json_file + '/' + 'pic'):
os.mkdir(json_file + '/' + 'pic')
img_save2png_path = json_file + '/' + 'pic'
utils.lblsave(osp.join(mask_save2png_path, save_file_name + '.png'), lbl)
PIL.Image.fromarray(img).save(osp.join(img_save2png_path, save_file_name + '.png'))
with open(osp.join(out_dir1, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
# warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir1, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir1)
except Exception as e:
traceback.format_exc()
if __name__ == '__main__':
main()
转化成功后会生成三个文件,cv2_mask(图片掩码),labelme_json(标注信息)和pic(原图)
将训练集和验证集复制到项目的datasets目录
二、模型训练
1.环境搭建
用Anaconda创建一个虚拟环境,切换至虚拟环境,运行项目中的requirements.txt,会下载模型所需的库文件。注:将requirements.txt中的tensorflow改为tensorflow-gpu,版本推荐用2.5.0,比较新的高版本可能会有兼容问题。如果下载过程太慢,可能是没有切换镜像源,这里使用的清华镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple

2.模型配置
2.1 datasets.py修改
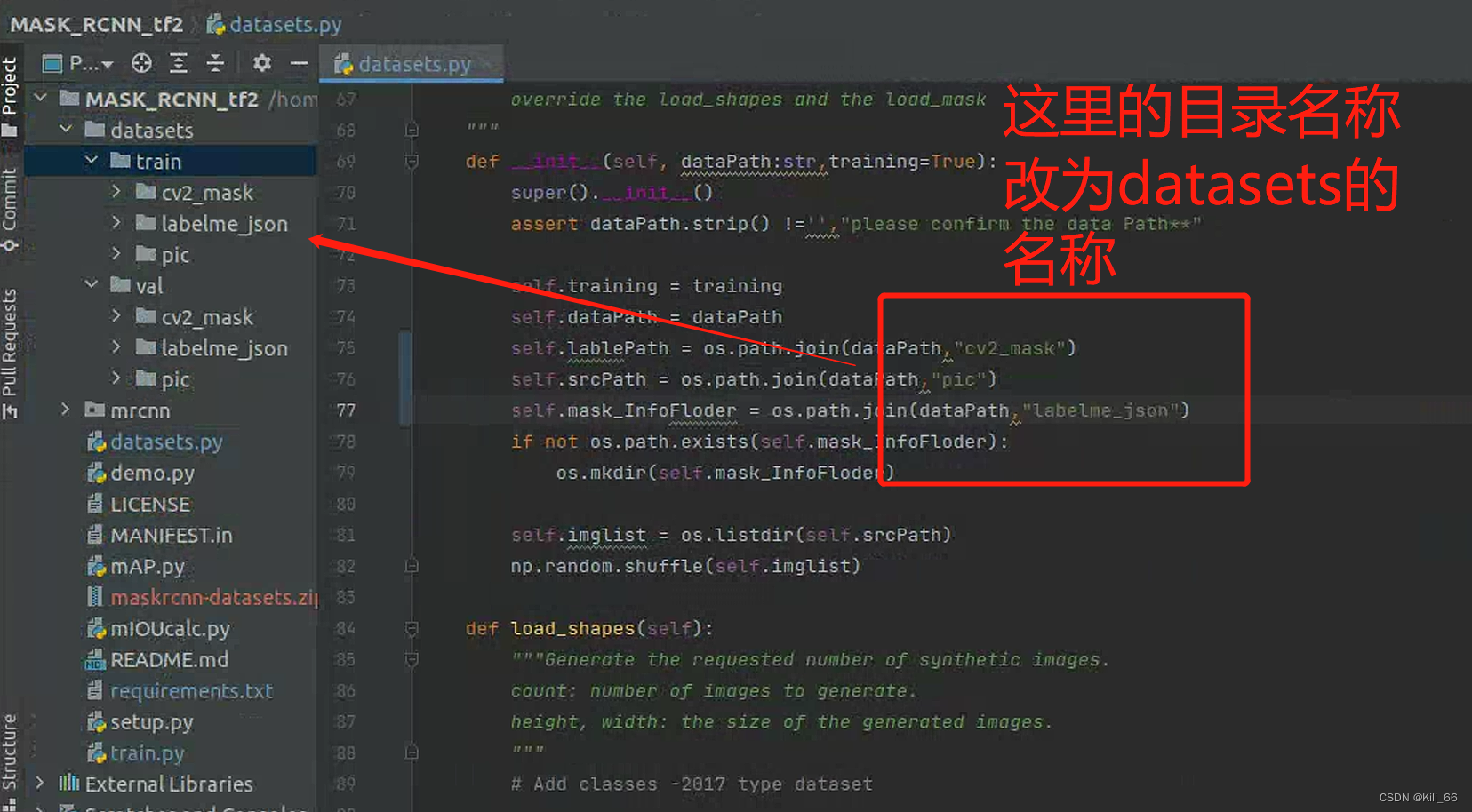
2.1.1 目录名称修改
项目的目录名称和脚本生成的目录名不一样,这里改为和datasets里一致的目录名称。
2.2.2 添加类别
数据集只训练了5个类,依次添加进list,id和名称自己取的,第一个参数都是‘shapes’。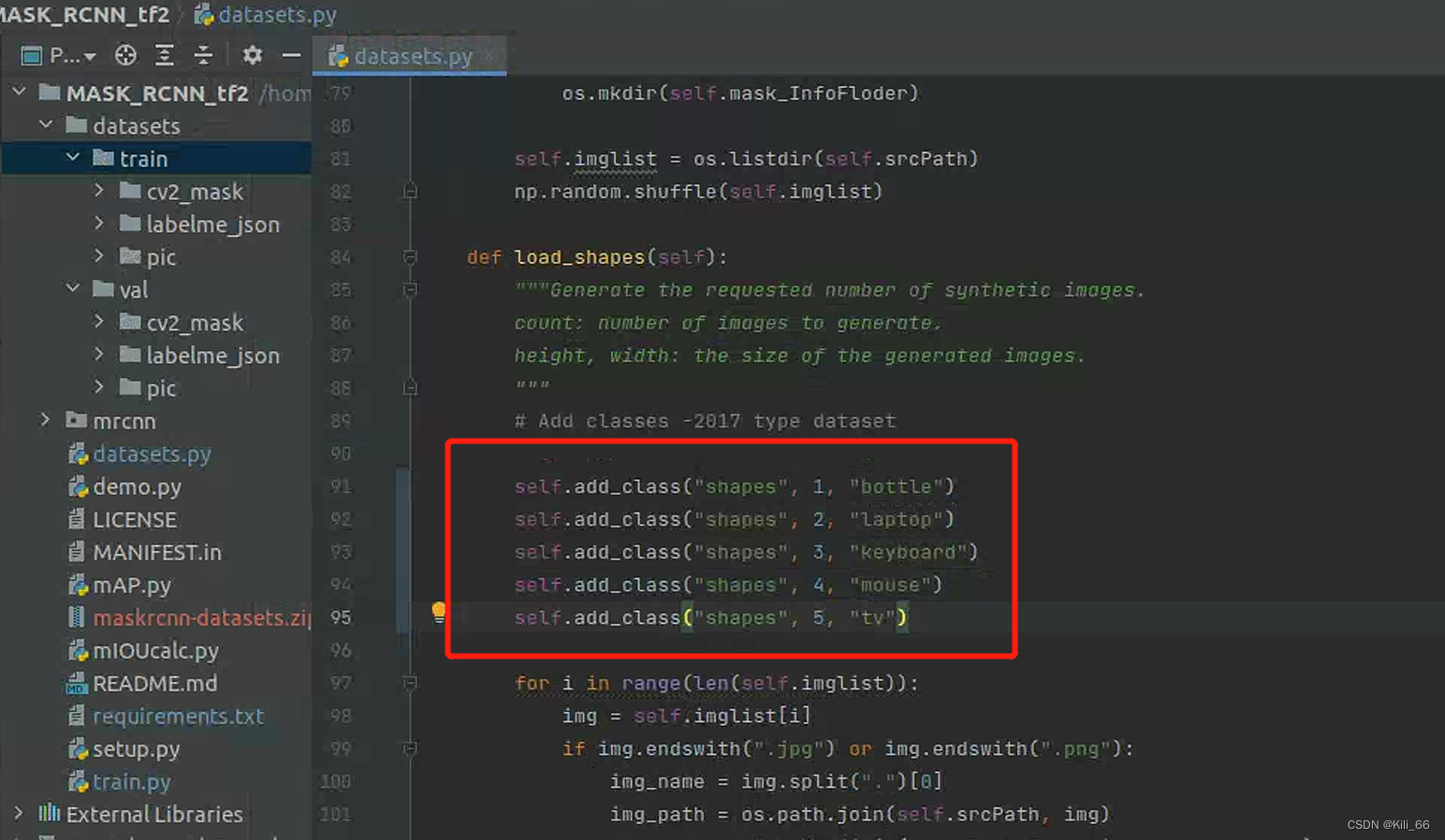
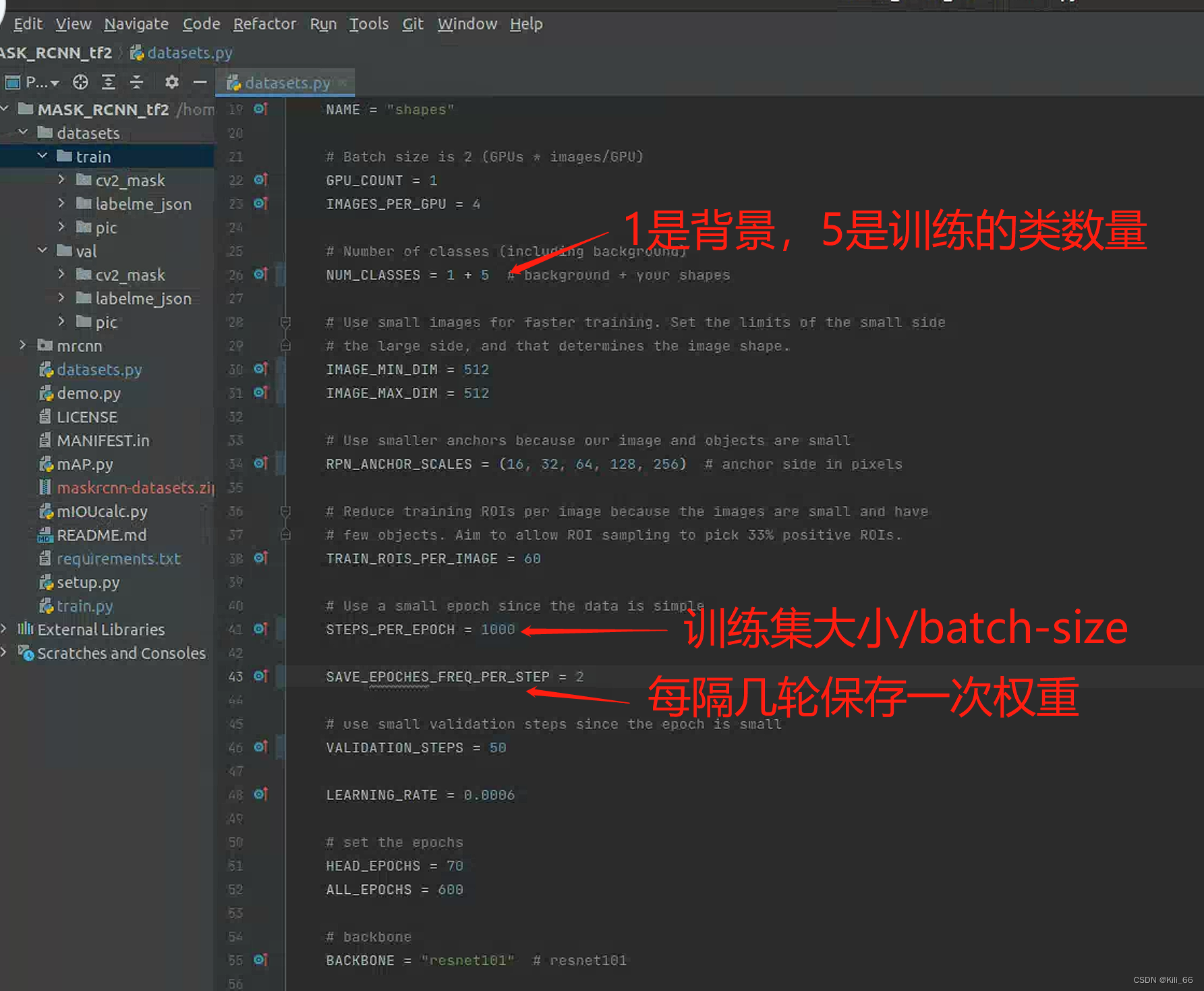
2.2.2 config配置
config比较常见的参数,已经提取到datasets.py里配置,其他的用config.py默认配置。配置详解请看这篇文章:Mask-RCNN应用 - 结合源码详细解析Config.py_天木青的博客-CSDN博客
3 开始训练
train.py设置对应的train和val路径,运行脚本开始训练。当第一次训练时,系统需要一段时间给数据集生成.npz的中间文件,以后训练会直接读这些文件,加快训练。
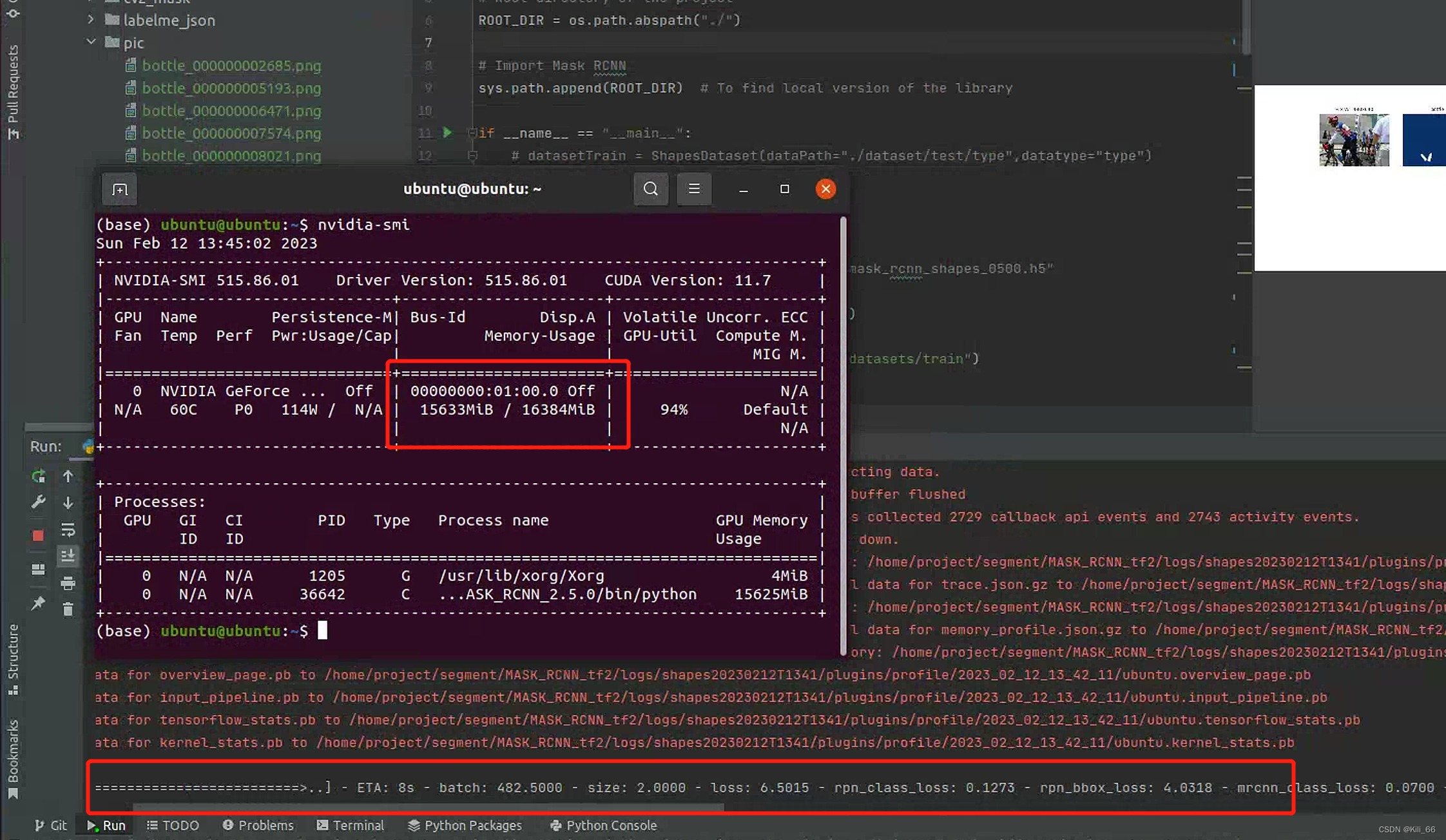
 当控制台没有报错,且出现以下进度条时说明模型可以正常训练。训练非常慢的话,有可能是使用cpu训练的,没有调到GPU,检查cuda和cudnn是否安装正确,通过nvidia-smi可查看GPU使用情况。
当控制台没有报错,且出现以下进度条时说明模型可以正常训练。训练非常慢的话,有可能是使用cpu训练的,没有调到GPU,检查cuda和cudnn是否安装正确,通过nvidia-smi可查看GPU使用情况。
4. 查看日志
训练得到的权重模型文件在logs文件夹下
在tensorbord中查看训练过程的各指标变化趋势
tensorboard --logdir logs/


三.模型测试
测试用自己写的脚本,支持图片和视频测试,NUM_CASSESL和class_names需要根据实际修改
import os
import sys
import cv2
import skimage.io
from tensorflow.python.client import device_lib
from ecnu.draw_segmention_utils import draw_segmentation
print(device_lib.list_local_devices())
import tensorflow as tf
print("GPU状态:",tf.test.is_gpu_available())
ROOT_DIR = os.path.abspath("../")
sys.path.append(ROOT_DIR)
from mrcnn.config import Config
from datetime import datetime
import mrcnn.model as modellib
from mrcnn import visualize
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/"))
MODEL_DIR = os.path.join(ROOT_DIR, "logs/")
# MODEL_DIR = os.path.join(ROOT_DIR, "logs/")
# COCO_MODEL_PATH = os.path.join(MODEL_DIR, "mask_rcnn_shapes_0004.h5")
COCO_MODEL_PATH = os.path.join(MODEL_DIR, "mask_rcnn_shapes_0368.h5")
IMAGE_DIR = os.path.join(ROOT_DIR, "testdata")
# IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class ShapesConfig(Config):
NAME = "shapes"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = 1 + 5
DETECTION_MIN_CONFIDENCE = 0.8 # 所有小于0.7的置信度都认为内部不包含物体
TRAIN_ROIS_PER_IMAGE = 512
RPN_TRAIN_ANCHORS_PER_IMAGE = 512
# Length of square anchor side in pixels
# RPN_ANCHOR_SCALES = (32, 64, 128, 256,512)
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
class_names = ['BG','bottle','chair','laptop','mouse','keyboard','person']
if __name__ == "__main__":
i = 1
# video_path = ''
video_path= 'video/test.mp4'
config = InferenceConfig()
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
model.load_weights(COCO_MODEL_PATH, by_name=True)
i = i + 1
file_names = next(os.walk(IMAGE_DIR))[2]
# image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
image = skimage.io.imread(os.path.join(IMAGE_DIR, "000004.jpg"))
a = datetime.now()
results = model.detect([image], verbose=5)
b = datetime.now()
print("time:", (b - a).seconds)
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])
if video_path:
# 1、获取视频的读取
vcapture = cv2.VideoCapture(video_path)
width = int(vcapture.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vcapture.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = vcapture.get(cv2.CAP_PROP_FPS)
# 2、定义video writer后续写入
file_name = "./segmentation_{}".format(video_path.split("/")[-1])
vwriter = cv2.VideoWriter(file_name,
cv2.VideoWriter_fourcc(*'mp4v'),
fps, (width, height))
# 3、循环获取每帧数据进行处理,完成之后写入本地文件
count = 0
success = True
while success:
print("帧数: ", count)
# 读取图片
success, image = vcapture.read()
if success:
# OpenCV 返回的BGR格式转换成RGB
image = image[..., ::-1]
# 模型检测mask
r = model.detect([image], verbose=0)[0]
# 画出区域
# 画出区域
segmentation = visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])
# RGB -> BGR
segmentation = segmentation[..., ::-1]
# 添加这张图到video writer
vwriter.write(segmentation)
count += 1
vwriter.release()
测试效果图,作为当时sota的经典算法效果还行,想要更好的分割效果,下篇文章会介绍目前性能sota的yolov8分割算法。



版权归原作者 Kili_66 所有, 如有侵权,请联系我们删除。