
GPU软件抽象与硬件映射的理解
1 从程序到软件抽象:
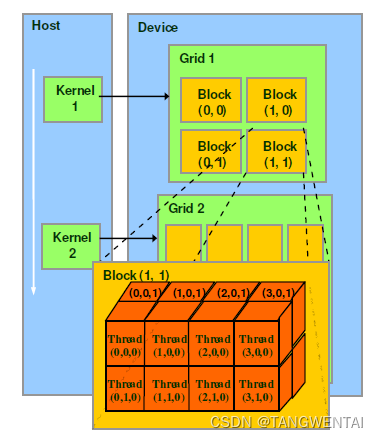
组成关系:
GPU上运行函数kernel对应一个Grid,每个Grid内有多个Block,每个Block由多个Thread组成。
运行方式:
Block中的Thread是并行执行的
Grid中的Block是独立执行的,多个Block可以采用任何顺序执行操作,即并行,随机或顺序执行。这种方式扩展了我们(程序猿)的操作空间。
2 从软件抽象到硬件结构
2.1 软件抽象: Grid(线程网格)、Block、Thread
软件抽象是CUDA编程上的概念,以方便程序员软件设计,组织线程。
Thread:一个CUDA的并行程序会被以许多个threads来执行。
Block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
Grid:多个blocks则会再构成grid。
2.2 硬件结构: SM(Streaming Multiprocessor)、SP(Streaming Processor)
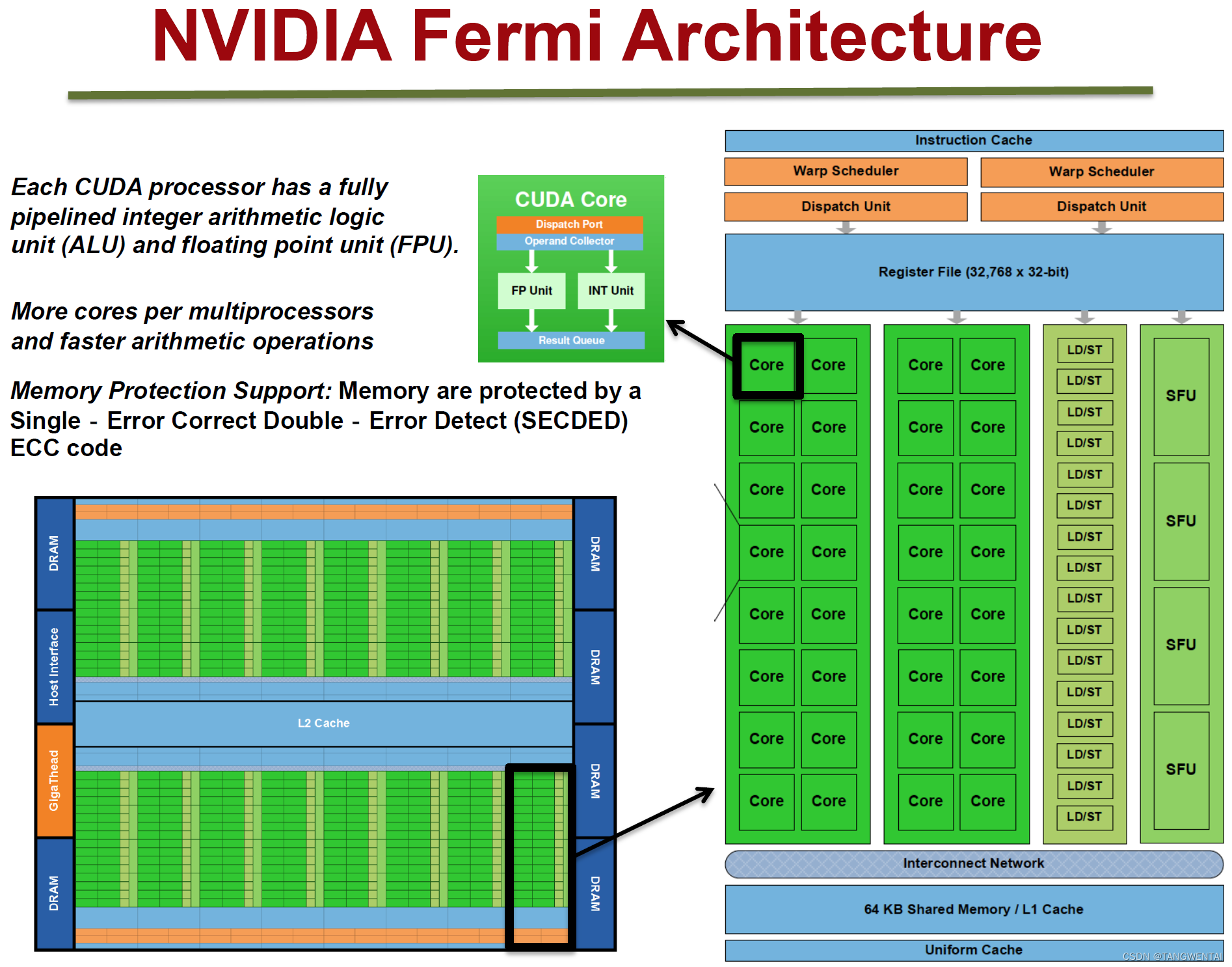
Fermi架构如上图,它的特性如下:
如上图,对于某些GPU(如Fermi部分型号)的单个SM,包含:
32个运算核心 (Core,也叫流处理器Stream Processor)
16个LD/ST(load/store)模块来加载和存储数据
4个SFU(Special function units)执行特殊数学运算(sin、cos、log等)
128KB寄存器(Register File)
64KB L1缓存
全局内存缓存(Uniform Cache)
纹理读取单元
纹理缓存(Texture Cache)
PolyMorph Engine:多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)。
2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
指令缓存(Instruction Cache)
内部链接网络(Interconnect Network)
2.3 软件抽象与硬件结构的对应关系
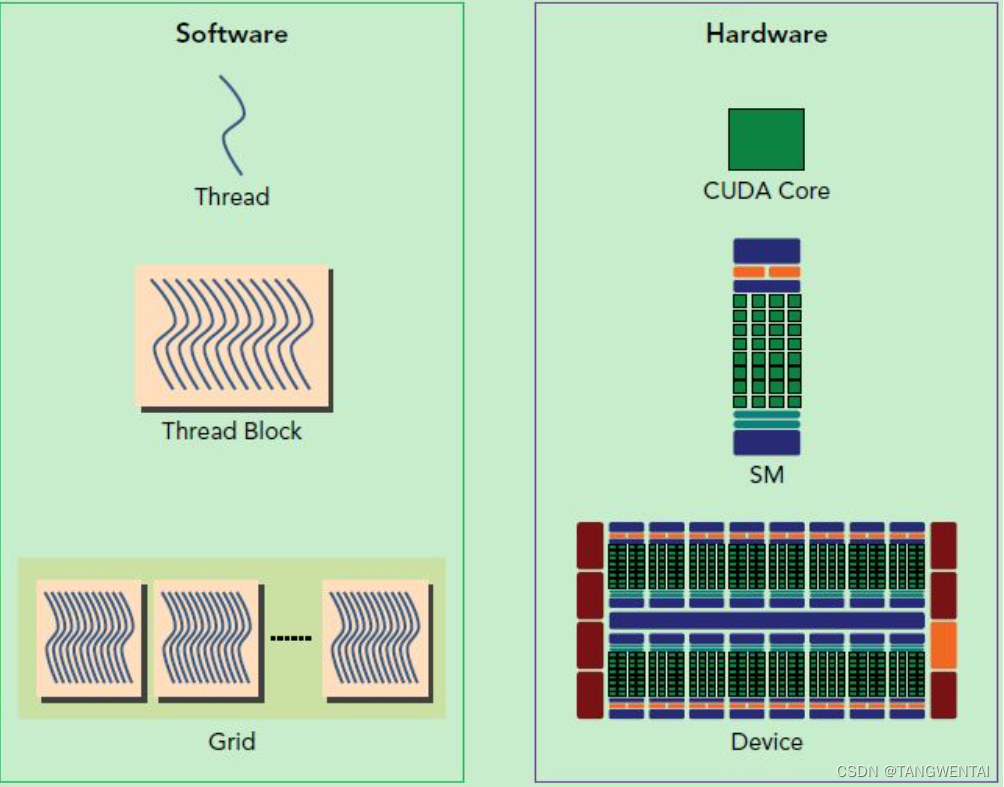
SP(CUDA Core)是Thread运行的基本单位。
SM中运行软件逻辑中的Block。(SM内每个SP可并行执行,每个Block内Thread并行)
Device中包含多个SM,Grid中包含多个Block。(Device中SM相互独立。Grid中的Block也是独立执行的,多个Block可以采用任何顺序执行操作,即并行,随机或顺序执行。)
为了更好的管理和执行Thread,采用了SIMT架构,提出了线程束Wrap:
warp是硬件层面中SM对应执行线程的单位。
线程束Wrap是GPU的基本执行单元,目前cuda的warp的大小为32。同在一个warp的线程执行同一指令。
注意: 同一线程束内Thread并发执行,同一Block不同线程束内的Thread也并发执行。
同一线程束内线程执行同一指令,但是输入的数据不同,属于SIMT(单指令多线程)架构。
线程束是GPU的基本执行单元。不同线程束之间执行不同指令,但是可以并行执行,属于GPU的调度范畴,
从硬件角度理解Wrap是如何作为调度单元执行的:
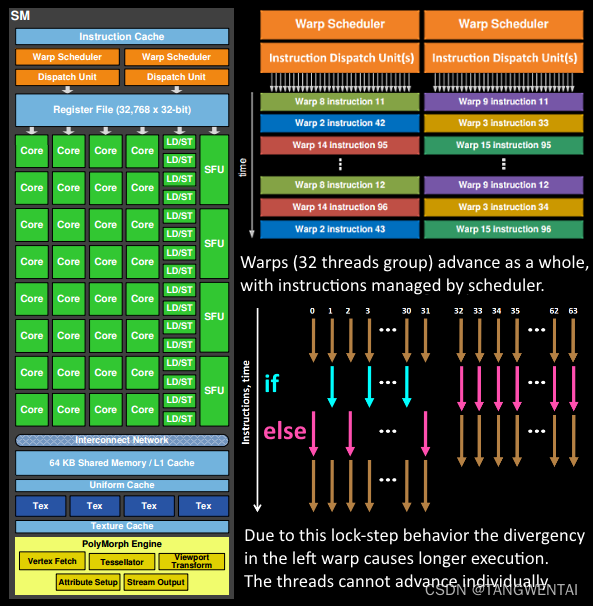
上图反应了warp作为调度单位的作用,不同Wrap执行不同指令,每次GPU调度一个warp里的32个线程执行同一条指令,其中各个线程对应的数据资源不同。
上图是一个warp排程的例子。
一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。
进行划分时,最好保证每个block里的warp比较合理,那样可以一个sm可以交替执行里面的warp,从而提高效率。
此外,在分配block时,要根据GPU的sm个数,分配出合理的block数,让GPU的sm都利用起来,提利用率。
分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。
疑问:
硬件Wrap Scheduler有两个,对应32个Croe,与软件逻辑中每个Wrap对应32Thread不符?
解惑:Fermi 采用了双发行模型
一个SM中由多个线程束(Wrap),正好对应Block中的线程束Wrap。
Fermi架构下线程束中包含16个Core,一般软件逻辑中Wrap包含32个线程。
(数量对不上,因为采用了双发行模型,Fermi 实现了接近峰值的硬件性能。)
参考:https://qa.1r1g.com/sf/ask/2592133701/
补充:
SIMD与SIMT:
SIMD(Single Instruction Multiple Data)是单指令多数据,在GPU的ALU单元内,一条指令可以处理多维向量(一般是4D)的数据。特指一个Thread在一个Croe中ALU可以进行向量计算。
比如,有以下shader指令:
float4 c = a + b; // a, b都是float4类型
对于没有SIMD的处理单元,需要4条指令将4个float数值相加,汇编伪代码如下:
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
但有了SIMD技术,只需一条指令即可处理完(利用可以进行4维向量加减的ALU处理):
SIMD_ADD c, a, b
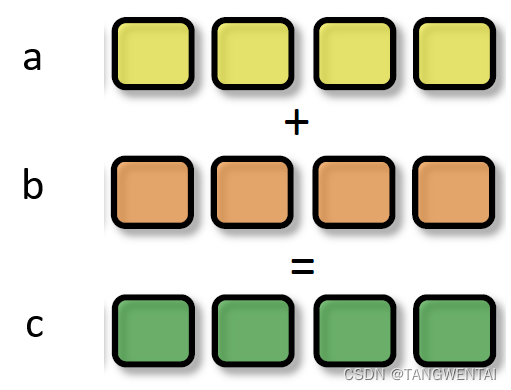
SIMT(Single Instruction Multiple Threads,单指令多线程)是SIMD的升级版,可对GPU中单个SM中的多个Core同时处理同一指令,并且每个Core存取的数据可以是不同的。特指多个Thread在一个Block中执行相同指令,执行资源不同而已。
SIMT_ADD c, a, b
上述指令会被同时送入在单个SM中被编组的所有Core中,同时执行运算,但a、b 、c的值可以不一样: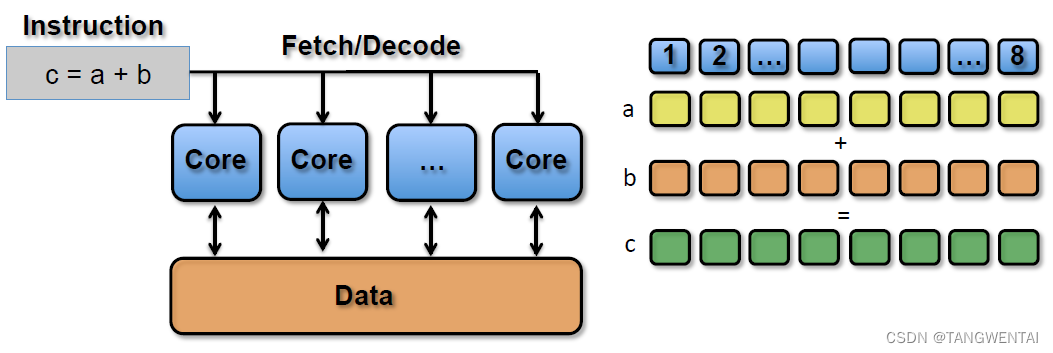
主要参考:
深入GPU硬件架构及运行机制
SIMD与SIMT区别
深入理解GPU中的并行机制
本文转载自: https://blog.csdn.net/TANGWENTAI/article/details/126818834
版权归原作者 TANGWENTAI 所有, 如有侵权,请联系我们删除。
版权归原作者 TANGWENTAI 所有, 如有侵权,请联系我们删除。