
本文通过构建一个手写数字识别的程序来解析来自机器学习与深度学习的不同算法的特点,以及如何对识别效果进行改进。
一、如何构建一个手写数字识别程序
首先可以考虑构建一个简单的页面用于用户输入,也就是前端;接下来需要准备一个后端用于调用模型进行预测。具体逻辑是:当用户在前端页面输入一个数字后,点击“识别”按钮,程序通过HTTP请求发送用户输入的数字到后端,之后由模型进行预测,返回预测值给用户,即返回识别结果。模型识别数字效果好坏决定了用户的体验是否良好,我们期望的是程序能够大概率准确识别用户输入的数字。
二、训练数据准备
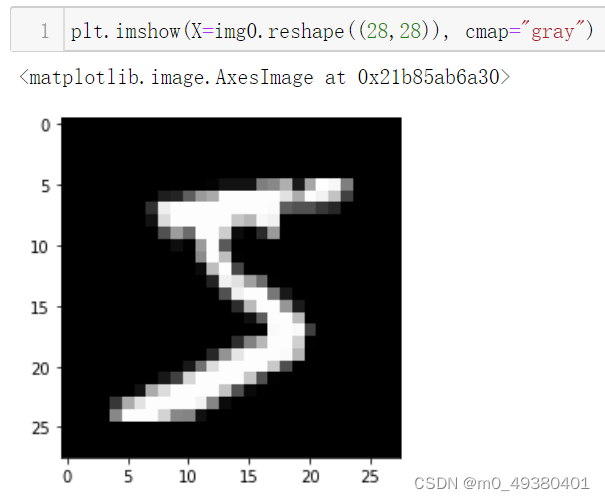
可以使用现成的手写数字数据集(下面这组图片所属的数据集包含了7万个数据),但是存在分辨率低,书写不太规范的问题,譬如下面是从数据集中提取到的数字“5”的图片:

打印第1个图片后得到的效果如下:
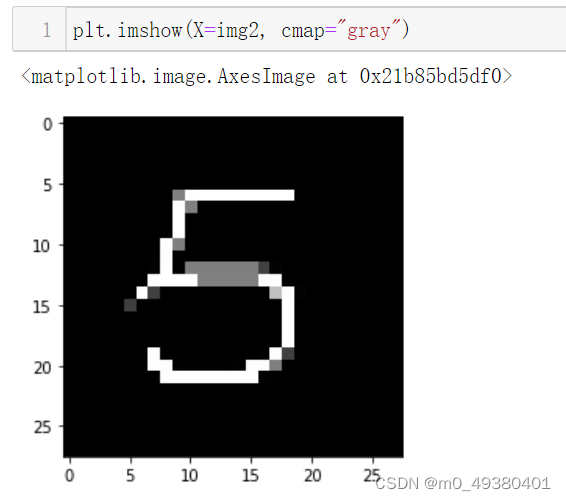
另外一种方案就是可以通过手写数字前端输入页面来生成自己的数据集,为了能提高识别准确率,在前端输入时会尽量书写规范,以下就是新建数据集中数字“5”的图片打印出来的效果(原图片的分辨率为280x280,这里缩小为与上图一致的尺寸):
按照数字0 – 9 通过前端页面手写输入的方式,合计生成了1200个左右的新图片作为训练数据集(这里只是做demo演示用,所以数量不多):

三、使用机器学习的算法构建模型
在机器学习的算法中,随机森林能够体现“集成学习”的思想,即通过一批“被打残”的决策树来做集体预测,从而达到单体模型(譬如单个决策树)所不能达到的效果。对于机器学习的模型来说,其训练过程可以看做是“一杆子捅到底”,不具有迭代的过程。
首先看下训练数据集的情况:

X_train代表训练样本,维度为28 x 28,即784
y_train代表样本所对应的标签,如数字“1”图片对应的标签值为1
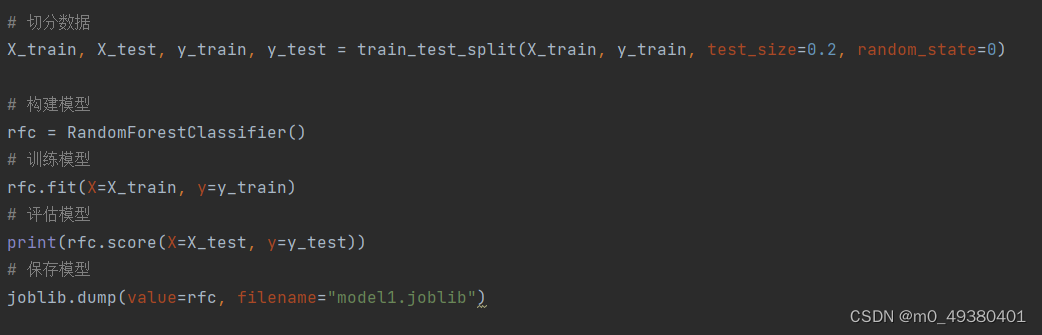
接下来是构建模型及训练的过程,这里使用了sklearn的函数train_test_split来切分训练数据集与测试数据集:
打印出来的模型基于测试集的预测准确率为0.77 左右,并不算高,但不影响用于本次手写数字程序的模型预测测试:
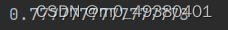
四、构建手写数字程序的前端和后端
前端使用简单html页面即可,具体效果如下,输入页面的重点是加了一个简单的方框以及提示语,引导用户尽量规范输入,从而提高识别准确率,这点在工程化实践中比较重要:

当用户拖动鼠标写入数字后,点击“识别”按钮,从而通过HTTP的方式把数据发送到后端并保存起来,在实际实践中,用户的输入应该被存储起来,一是可以作为后续训练数据集的补充,另外也可用于后续算法及模型改善的用途等等。
以下是简单保存图片的做法:

接下来就是调用模型读入上面保存的图片进行预测:

然后后端把预测值y_pred返回给用户,演示画面如下:

五、总结
在规范用户输入的情况下,使用机器学习的随机森林算法构建模型后,如果使用现成的数据集进行训练,得到的模型用于手写数字识别时,发现总体上识别准确率只有百分之三十左右,而新建数据集用于训练之后,识别准确率得到了很大改善,但是机器学习算法有其局限性,后面会使用深度学习中的CNN来做对比分析。
版权归原作者 m0_49380401 所有, 如有侵权,请联系我们删除。