
当前主流 AI 智能体框架有一个共同的局限:智能体只能按预设逻辑执行任务,无法从运行时反馈中持续学习。模型权重是静态的,提示词需要人工迭代,整个系统缺乏自我优化的闭环。
Agent Lightning 针对这一问题提出了解决方案。它是一个框架无关的强化学习包装层,可以套在任意现有智能体外部,让智能体具备在线学习能力。无论底层用的是 LangChain、AutoGen、CrewAI 还是原生 Python 实现,都能以最小改动接入训练流程。
本文将介绍 Agent Lightning 的核心架构和使用方法,并通过一个开源的"自修复 SQL 智能体"项目演示完整的训练流程。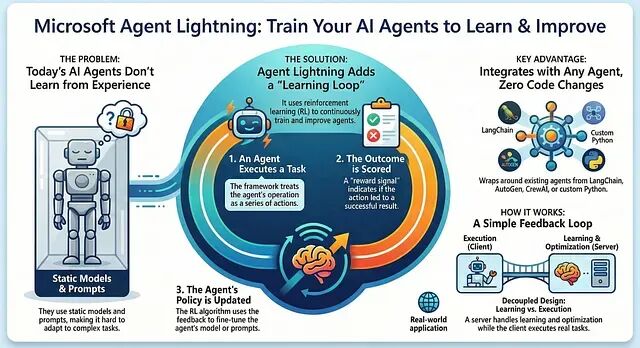
Agent Lightning 的核心特性
Agent Lightning 具备两个关键的设计优势:框架无关性和执行训练解耦。
框架无关性意味着它不绑定特定的智能体实现。无论底层是 LangChain、AutoGen、CrewAI 还是原生 Python 代码,都可以通过统一的接口接入训练流程,无需重构现有逻辑。
执行与训练解耦则是指智能体的推理执行和强化学习训练在架构上分离。智能体正常处理业务请求,训练模块在后台异步收集反馈、更新策略。这种设计保证了生产环境的稳定性,同时支持持续优化。
Agent Lightning 的工作原理
Agent Lightning 由四个核心组件构成:
Runner 负责智能体的沙箱执行。它为智能体提供隔离的运行环境,执行任务并记录完整的行为轨迹,包括输入、输出、中间状态和最终结果。Trainer 负责策略优化。它根据 Runner 收集的轨迹数据计算奖励信号,通过强化学习算法更新智能体的行为策略。LightningStore 是持久化存储层,保存所有历史轨迹、奖励记录和模型检查点,支持离线分析和增量训练。
VERL(Volcano Engine Reinforcement Learning)专门处理多步骤任务中的信用分配问题。在长序列决策中,最终奖励需要回溯分配到各个中间步骤。VERL 通过时序差分等方法,将整体奖励拆解到具体动作,解决稀疏奖励场景下的训练难题。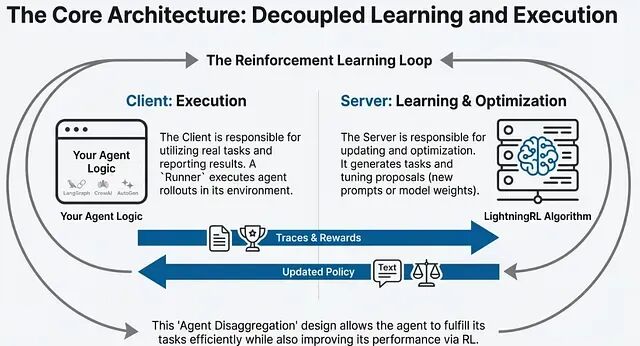
构建一个自纠正智能体
理论讲完了。下面看怎么落地。目标是构建一个学会简洁回答的智能体。
先装库,它会包在现有 LLM 调用外面。
pip install agentlightning
普通智能体就是发提示、拿回复。用 Agent Lightning 的话,要在函数外面加一个
@agl.rollout
装饰器。意思是告诉系统:盯着这个函数,给它打分,帮我改进它。
下面这个例子是一个回答首都城市的简单智能体。目标是让它输出精确答案(比如直接回"Paris")而不是废话连篇("The capital is Paris")。
import agentlightning as agl
from openai import OpenAI
# 1. Define the Reward (The Coach's Whistle)
def exact_match_reward(prediction, target):
# Reward is 1.0 if correct and concise, 0.0 otherwise
return 1.0 if prediction.strip().lower() == target.strip().lower() else 0.0
# 2. Define the Agent
@agl.rollout
def capital_city_agent(task, prompt_template):
# Use the dynamic prompt template provided by the Trainer
system_prompt = prompt_template.format(**task)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Capital of {task['input']}?"}
]
)
prediction = response.choices[0].message.content
return exact_match_reward(prediction, task['target'])
这样就不用手动改提示词了,交给 Trainer。
# Initialize the optimizer (Automatic Prompt Optimization)
optimizer = agl.APO(inference_client=client)
# Define a starting "bad" prompt
initial_prompt = agl.PromptTemplate("You are a geography helper.")
# Start the gym session
trainer = agl.Trainer(
algorithm=optimizer,
initial_resources={"prompt_template": initial_prompt}
)
trainer.fit(
agent=capital_city_agent,
train_dataset=[{"input": "France", "target": "Paris"}, ...],
)
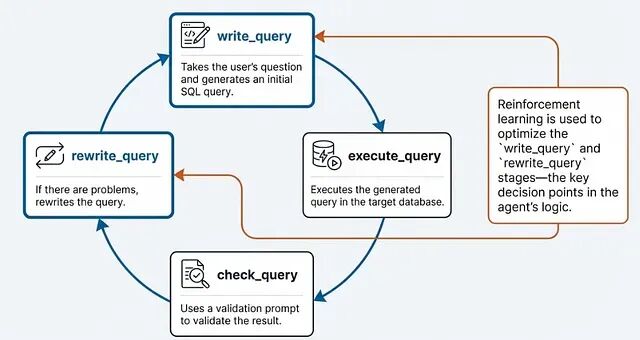
跑完之后,Agent Lightning 会自动把提示词改写成类似这样:"You are a precise geography assistant. Output ONLY the city name with no punctuation."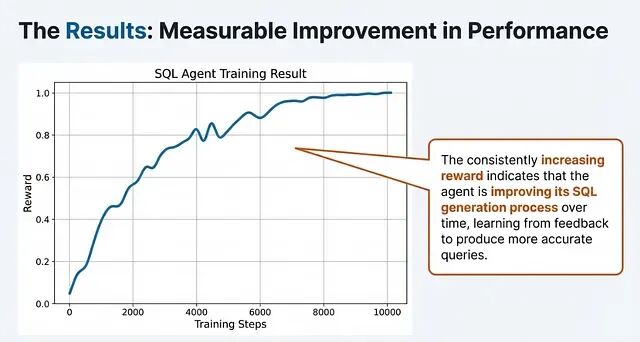
总结
Agent Lightning 为现有智能体提供了一套轻量级的在线学习方案,通过框架无关的设计和执行训练解耦架构,降低了强化学习在智能体开发中的接入门槛。
落地过程中需要注意几个问题:奖励函数设计直接影响优化方向,指标定义不当会导致智能体学到错误行为;训练过程消耗计算资源,多智能体场景需要做好监控;持续学习带来的模型漂移也需要治理机制保障,防止智能体偏离预期的安全边界。
从更大的视角看,Agent Lightning 代表了智能体开发从静态部署向动态进化的转变。随着这类工具的成熟,智能体将逐步具备自适应能力,成为真正意义上的学习型系统。
作者:Aarav Sharma