
DeepSort目标跟踪算法是在Sort算法基础上改进的。
首先介绍一下Sort算法
Sort算法的核心便是卡尔曼滤波与匈牙利匹配算法
卡尔曼滤波是一种通过运动特征来预测目标运动轨迹的算法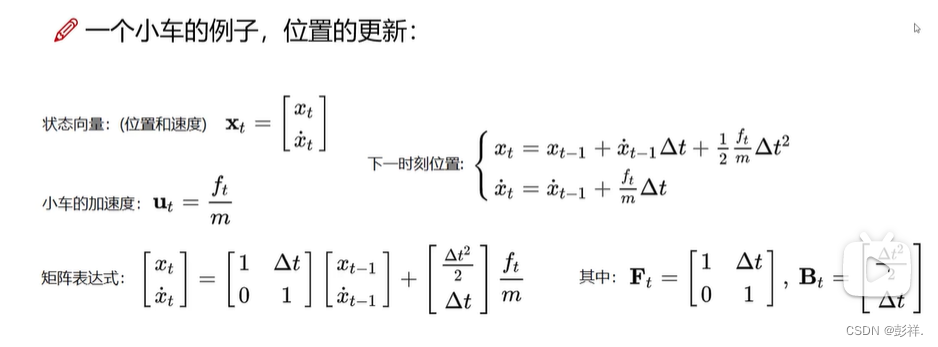
其核心为五个公式,包含两个过程:
其分为先验估计(预测)
其中Xt-表示预测的位置状态,包含位置速度等信息,F为状态转移矩阵,描述前一帧如何影响该帧,ut-1为控制量,可认为是加速度B为控制矩阵,表示如何控制ut-1作用于当前状态。
P-为当前帧的预测协方差矩阵,是描述变化关系的,要知道,变量之间是有联系而非独立的,比如身高与体重存在关联,其维度取决于X变量有几个,比如在sort算法中,有(x,y,t,h,vx,vy,vr,vh)八个变量,那么其协方差阵即为8*8,该公式也是在变化的,Q代表噪声,其服从正态分布,表示随机进行抑制或增强,但总体全局来看是无影响的。
后验估计即更新(使用观测值来进行修正),我们知道,在目标检测跟踪中,无论是根据数学公式去推导得到的验证框,还是通过YOLO等检测器所得到的检测框(观测值)其都是有误差的,而更新过程便是要融合两个所得结果来确定一个更接近真实值的过程。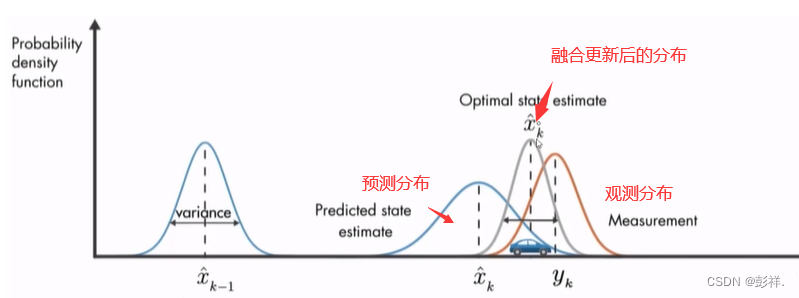
首先要计算Kk,其表示卡尔曼增益,实际上是一种权重,由科学家推导所得,我们也就不要去纠结了,其中R代表检测误差。
接下来便是当前帧的Xt,其表示我们的修正值,也是我们这一帧的一个预测的最终值,该公式表示根据上一帧的运行特征的预测与观测值的一个融合,权重值Kk表示我们应该更相信谁多一点,值得注意的是,当检测误差R=0时,可认为预测值等于观测值。
随后完成Xt的更新后便是更新Pt,这是我们要送入下一帧中使用的协方差阵。
其在Matlab中的实现:可以看到我们直接使用公式即可。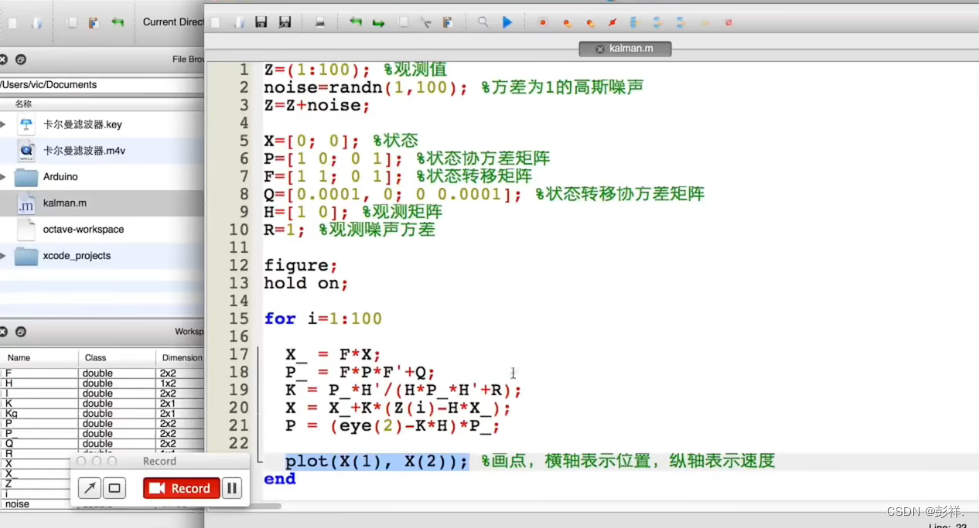
接下来便是ID匹配,使用的是匈牙利算法,其最早是用于二分图匹配中
二分图: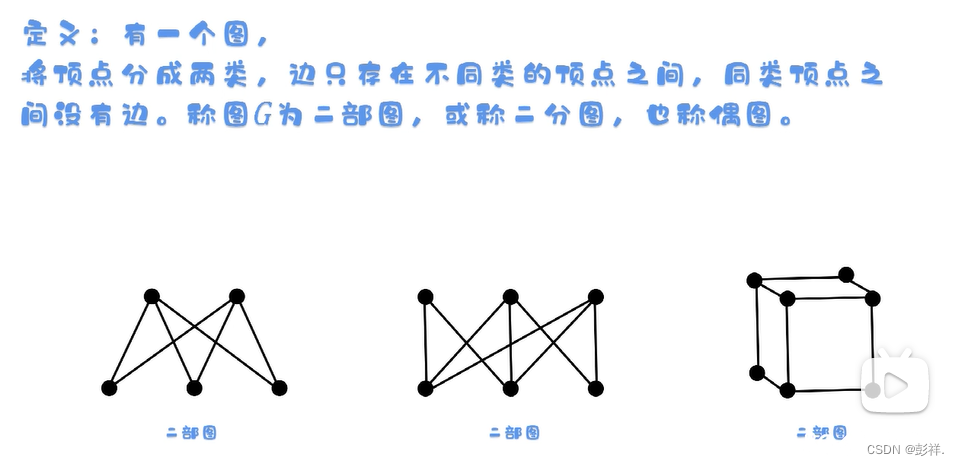
匈牙利算法是一个处理指派问题的算法,在这里可认为ID匹配
指派问题:n个人,n个任务,如何才能是任务完成时间最少,代价最小。
其完成的就是一个指派问题,具体实现过程我们不需要深究,在SK-learn库的linear_assignment_和scipy库的linear_sum_assignment都实现了这一算法,只需要输入cost_matrix即代价矩阵就能得到最优匹配。
Sort算法流程图: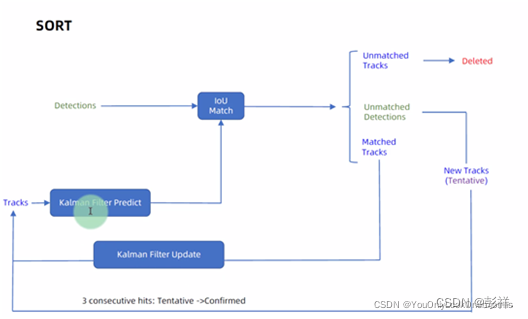
Sort算法总结
SORT是一个粗略的框架,核心就是两个算法:卡尔曼滤波和匈牙利匹配。
卡尔曼滤波:在图中被分为两个过程:预测和更新。预测过程:当一个小车经过移动后,且其初始定位和移动过程都是高斯分布时,则最终估计位置分布会更分散,即更不准确;更新过程:当一个小车经过传感器(也就是我们的Detections)观测定位,且其初始定位和观测都是高斯分布时,则观测后的位置分布会更集中,即更准确。但是由于我们得到的是一堆Track和一堆Detection,因此只有在用匈牙利算法进行分配后,才能把Track按照对应的Detection结果更新。
匈牙利算法:解决的是一个二分图分配问题(Assignment Problem),即如何分配使成本最小。在上图中是IOU Match那里,即基于IOU距离构造的成本矩阵对Detection和Track作匹配。
即每个检测框与预测框的IOU距离最小构成代价矩阵。
SK-learn库的linear_assignment_和scipy库的linear_sum_assignment都实现了这一算法,只需要输入cost_matrix即代价矩阵就能得到最优匹配。不过要注意的是这两个库函数虽然算法一样,但给的输出格式不同。具体算法步骤也很简单,是一个复杂度 的算法。
SORT的问题:ID-switch很高,即同一个人的ID会变化。这主要是由于该算法中的一帧不匹配删除机制及IOU 成本矩阵的问题。
DeepSort算法
Sort算法采用IOU加 权的匈牙利算法进行数据关联,用最小IOU作为代价矩阵。
目前主流的目标跟踪算法都是基于Tracking-by-Detecton策略,即基于目标检测的结果来进行目标跟踪。DeepSORT运用的就是这个策略,DeepSORT对人群进行跟踪的结果即:每个bbox左上角的数字是用来标识某个人的唯一ID号。
从名字中就可以看出,DeepSort算法中应用了深度学习,其在原有sort算法的基础上使用了CNN网络来实现检测框表观特征的提取,通过将提取的表观特征与预测框(跟踪框)的表观特征技术余弦相似度来衡量两者之间的匹配度。
运动特征匹配

表观特征衡量
马氏距离虽然可以通过检测框和跟踪框的偏差以计算状态估计的不确定性,但仍存 在不足,由于实际跟踪环境复杂,目标运动不受控制,存在因遮挡而丢失目标或身份切 换的问题。因此,DeepSort算法中引入了针对表观特征匹配的余弦距离度量方式。
将表观特征与运动特征融合构造匈牙利算法的代价矩阵。
在DeepSORT中,匈牙利算法用来将前一帧中的跟踪框tracks与当前帧中的检测框detections进行关联,通过外观信息(appearance information)和马氏距离(Mahalanobis distance),或者IOU来计算代价矩阵。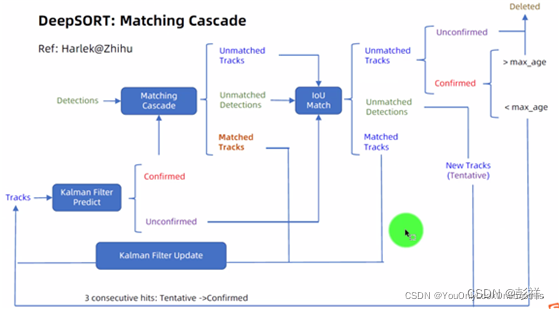
将上述的表观匹配与运动特征匹配运用到匈牙利算法,并引入了级联匹配的概念:
级联匹配
目的:长时间遮挡中。卡尔曼滤波的prediction会发散,不确定性增加,而这样不确定性强的track的马氏距离反而更容易竞争到detection匹配。因此,需要按照遮挡时间n从小到大给track分配匹配的优先级。基于匈牙利算法。
输入为:
1、基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有confirmed状态的track;
2、当前第k帧的所有detection
输出为:
1、match上的detection、track;
2、没有match上的track;
3、没有match上的detection。
具体过程:
#input:基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有confirmed状态的track索引T={1,...,N},当前第k帧所有detections D={1,...,M},最大未匹配帧数Amax=30
1.用外观最小余弦距离和马氏距离计算成本矩阵C(实操中lambda=0,只会用到外观最小余弦距离)
2.用外观最小余弦距离和马氏距离计算阈值矩阵B,用来滤掉不可能的匹配
3.用空集初始化match上的集合M
4.用D来初始化unmatch集合U
5. for n 属于 {1,...,Amax} : #n是每个track未匹配帧数
6. 从T中挑出一个子集Tn,即那些未匹配帧数=n的track的索引
7. 用匈牙利算法 对上一步选出的子集Tn和D进行匹配
8. 向M中添加匹配的序列号对(i,j),确保这个匹配满足阈值矩阵B(即bij=1)
9. 从未匹配索引集合U中删去匹配的序列号对(i,j)的j,确保这个匹配满足阈值矩阵B(即bij=1)
10. end
11. return M,U
级联匹配流程图里上半部分就是特征提取和相似度估计,也就是算这个分配问题的代价函数。主要由两部分组成:代表运动模型的马氏距离和代表外观模型的Re-ID特征。
级联匹配流程图里下半部分匈牙利算法数据关联作为流程的主体。为什么叫级联匹配,主要是它的匹配过程是一个循环。从missing age=0的轨迹(即每一帧都匹配上,没有丢失过的)到missing age=30的轨迹(即丢失轨迹的最大时间30帧)挨个的和检测结果进行匹配。也就是说,对于没有丢失过的轨迹赋予优先匹配的权利,而丢失的最久的轨迹最后匹配。
IOU匹配
IOU匹配是在级联匹配之后做的东西,从SORT中继承而来,用来解决突然的外观变换导致级联匹配难以match的情况,如部分遮挡等。也是基于匈牙利算法做的。
输入:
1、candidate track,包括:
1.1 级联匹配中剩下的unmatched,n=1的track;
1.2 基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有unconfirmed状态(即tenative)的track;
2、级联匹配中剩下的unmatched detection
输出:
1、match上的detection、track;
2、没有match上的track;
3、没有match上的detection。
然后进行更新处理,包括:
1、卡尔曼滤波 update track在第k帧状态的均值和方差
2、是否有track需要转为confirmed(到本帧match上且已连续命中3帧)
3、是否有要删除的track,即n>Amax
4、对unmatched detections分配新的track ID,为unconfirmed态即tenative态。
三者关系: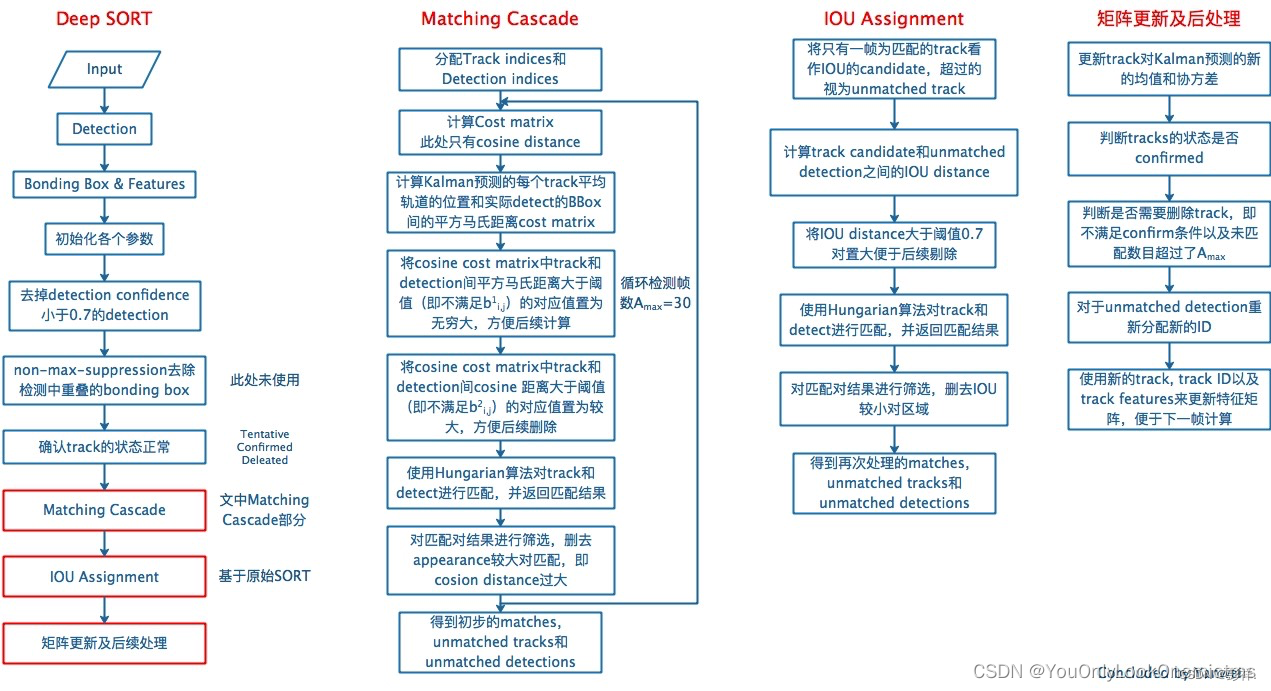
DeepSort改进
特征提取网络OSNet,其为一种新颖的深度CNN,称为全方位网络( Omni-Scale Network,OSNet),用于ReID中的全方位特征学习。这是通过设计由多个卷积特征流组成的残差块来实现的,每个残差块都以一定比例检测特征。 重要的是,引入了一种新颖的统一汇聚门,以动态融合多尺度特征和与输入有关的通道权重。为了有效地学习空间通道相关性并避免过度拟合,构件块同时使用了点向和深度卷积。
OSNet,每个流关注的特征比例由指数决定,指数是一个新的尺寸因数,在整个流中线性增加,以确保在每个块中捕获各种比例。至关重要的是,通过统一汇聚门(AG)生成的通道权重将生成的多尺度特征图动态融合。AG是一个子网,可在所有流之间共享参数,并具有许多有效的模型训练所需属性。使用可训练的AG,生成的通道权重将取决于输入,因此实现了动态标度融合。
OSNet是一个轻量级的网络,它可带来以下好处:
(1)轻量级网络具有更少的模型参数,不容易过拟合
(2)在大型监视应用程序中(例如,使用数千个摄像头的城市范围的监视),ReID的唯一实用方法是在摄像头端执行特征提取。
对于设备上的处理,小型ReID网络显然是首选。
OSBlock (bottleneck)
主要由多个轻量的3x3卷积,和AG组成,AG就是一个通道注意力,然后他们4个分支共享这个注意力网络
bottleneck只用来调整输入输出通道,图像大小没变。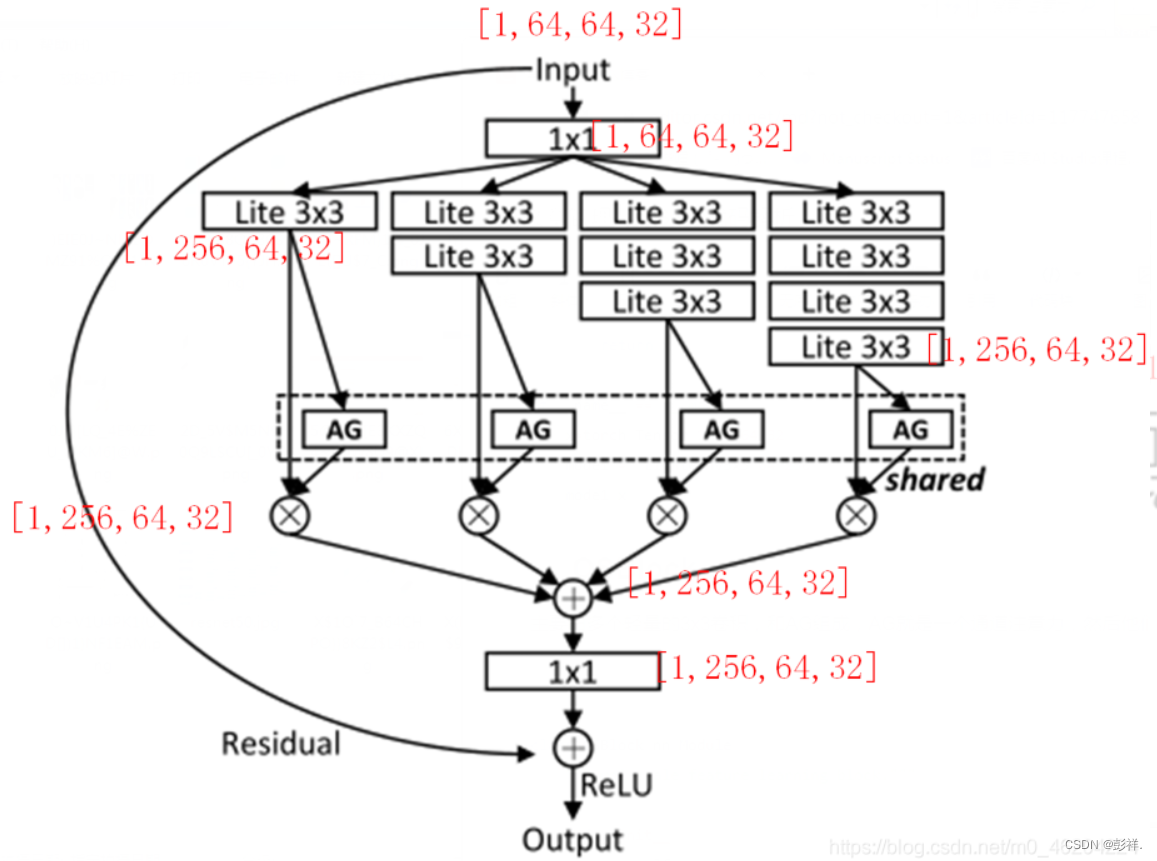
classOSBlock(nn.Module):"""Omni-scale feature learning block."""def__init__(
self,
in_channels,
out_channels,
IN=False,
bottleneck_reduction=4,**kwargs
):super(OSBlock, self).__init__()
mid_channels = out_channels // bottleneck_reduction
self.conv1 = Conv1x1(in_channels, mid_channels)
self.conv2a = LightConv3x3(mid_channels, mid_channels)
self.conv2b = nn.Sequential(
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),)
self.conv2c = nn.Sequential(
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),)
self.conv2d = nn.Sequential(
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),
LightConv3x3(mid_channels, mid_channels),)
self.gate = ChannelGate(mid_channels)
self.conv3 = Conv1x1Linear(mid_channels, out_channels)
self.downsample =Noneif in_channels != out_channels:
self.downsample = Conv1x1Linear(in_channels, out_channels)
self.IN =Noneif IN:
self.IN = nn.InstanceNorm2d(out_channels, affine=True)defforward(self, x):#torch.Size([1, 64, 64, 32])
identity = x
x1 = self.conv1(x)#torch.Size([1, 64, 64, 32])
x2a = self.conv2a(x1)#torch.Size([1, 64, 64, 32])
x2b = self.conv2b(x1)
x2c = self.conv2c(x1)
x2d = self.conv2d(x1)#torch.Size([1, 64, 64, 32])
x2 = self.gate(x2a)+ self.gate(x2b)+ self.gate(x2c)+ self.gate(x2d)
x3 = self.conv3(x2)#torch.Size([1, 256, 64, 32])if self.downsample isnotNone:
identity = self.downsample(identity)
out = x3 + identity
if self.IN isnotNone:
out = self.IN(out)return F.relu(out)
OSNet
左图就是bottleneck,注意右图中conv2,3,4,5只负责通道上的变化,transition负责图像大小的变化
OSnet一共有5层[conv1], [conv2,transition], [conv3,transition], conv4, conv5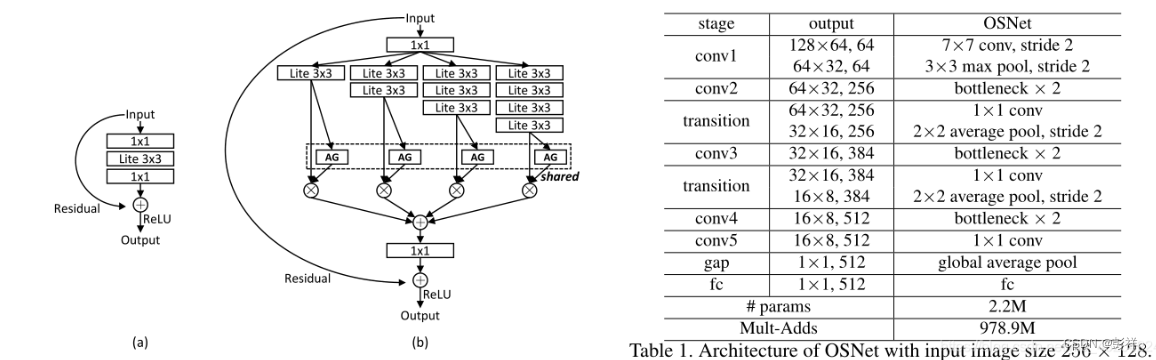
版权归原作者 彭祥. 所有, 如有侵权,请联系我们删除。