

众所周知,“相关并不意味着因果关系”。我要告诉你,相关可以表示因果关系,但需要一定条件。这些条件已在计量经济学文献中被广泛讨论。在本文中,我将以一种易于理解的方式对其进行总结。我将解释如果不满足这些条件为什么标准的普通最小二乘(OLS)无法确定因果关系。然后,我将介绍可以提供有效解决方案的固定效应(FE)模型。之后,我将使用两套数据分析示例向您展示如何在python中进行操作。我希望本文能够通过良好的设计和令人信服的结果增强您对因果关系的理解。
相关可以表示因果关系 — 仅在满足某些条件时
让我们给出因果关系的正式定义。因果关系是x导致y。关联意味着x和y沿相同或相反的方向一起移动。因果关系应满足以下三个经典条件:
- x必须在y之前发生
- x必须与y相关
- x和y之间的关系不能用其他原因解释。
从相关性推断因果关系是一件很难的事

图(A):从相关性推断因果关系很可怕
在图(A)中,冰淇淋销量的增长与夏季鲨鱼的袭击密切相关。您认为这有意义吗?这是一种关联,但不是因果关系,因为并非以上三个条件中的所有条件都成立。首先,鲨鱼袭击的次数不会随着冰淇淋销售的增加而增加。
其次,冰淇淋销售量的增长与鲨鱼袭击之间的相关性可能始终存在,也可能不是始终存在。第三,也是最重要的一点,两个因素之间的关系可以用夏季来解释。实际上,炎热的夏天是冰淇淋销售量增加和鲨鱼袭击增加的驱动力。
混杂因素(Confounding Factor):冰淇淋销售量x和鲨鱼袭击次数y都受夏季热量,混杂因素z的驱动,如图(B)所示。混杂因素是一个既影响因变量y又影响自变量x的变量,从而导致了虚假关联。一项研究可能会忽略混杂因素。因为我们没有收集足够的数据,所以它是不可观察的。而补救措施是将混杂因素识别为可观察的因素。
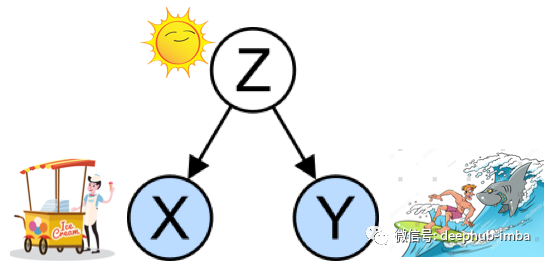
图(B):混杂因素
内生性:如果存在一个混杂因素可以解释x和y之间的关系,则x是内生的。x和y之间的相关性也无法解释或毫无意义。您能说冰淇淋销售与鲨鱼袭击之间存在正相关关系吗?我们不应试图从正号或负号得出任何结论。事实是该系数可以更高,更低,甚至不同。
如何量化X对Y的影响?
为了衡量治疗的效果,我们必须与没有治疗的事实进行比较。换句话说,我们讨论如果个人不接受治疗会产生什么结果。
随机对照试验(RCT)通常是非常好的标准
我们要怎么解决这个难题呢?随机对照试验(RCT)通常被视为非常好的标准,因为可以确定因果关系(Shadish et al,2002)。如果我们可以将个体随机分配到治疗组和对照组,那么两组的个体特征将大致相等。那么,治疗效果就是两组之间的y之差。
让我用一种统计的方式来进行以上描述。普通最小二乘(OLS)假设x与不可观察项𝜺之间没有相关性,即没有内生性。这可以用RCT中实现,因为随机分配下不可能出现内生性或混杂问题。在下式中描述了OLS,其中i是N个个体中每个个体的标识符。第二个方程是矩阵形式。关键假设是E(X𝜺)= 0,这表示x与不可观测项𝜺之间没有相关性。错误项可能是任何不可观察的项。
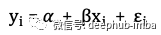
但是,在大多数情况下进行RCT会不可行。RCT可能很耗时,或很昂贵,或难以向需要合作的公众解释,并且有时是不道德的。例如,在医院中,研究人员可能会建议将患者保留为对照组。这显然不可行,因为该研究使患者处于危险之中。并非所有决策问题或临床实验都可以遵循RCT。那我们还有什么办法?研究人员越来越依赖于准实验设计并取得了令人信服的结果。“准”一词表面上看起来表示不是真的。准实验设计类似于随机对照试验,但没有对研究者进行随机分配(Cook&Campbell,1979)。
准实验接近“一样好”
RCT中无法进行大量研究。因此,我们使用了准实验设计,其中已曝光和未曝光单位之间的唯一区别是曝光本身。典型的准实验包括回归不连续性回归——Regression Discontinuity(RD),差异——Difference-in-differences(DiD)和固定效应模型——Fixed-Effects Model (FE)。
不连续性回归(RD)
RD设计将刚好高于和刚好低于阈值的对象进行比较,如图(D)中“Before”方案中的绿色框所示。预计绿色框中的主题非常相似。在“After”场景中,正确的小组受到干预,结果有所不同。结果的这种跳跃或不连续可以解释为干预的结果。
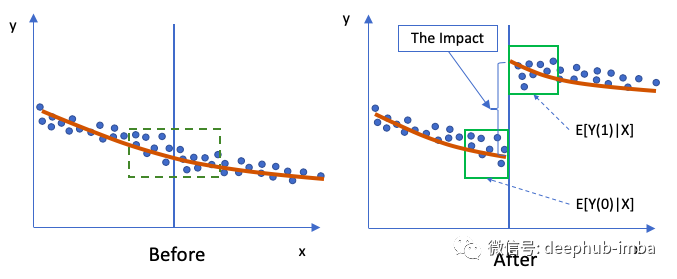
图(D):RD
在“After”期间(“ 1” =After)对Y的预期影响为E [Y(1)| X],而“Before”期间(“ 0” =Before)为E [Y(0)| X ]。在小绿色框中,所有X都非常相似,因此,“之前”和“之后”期间的X被认为是相同的。RD的结果接近RCT。
面板数据(Panel Data):也称为纵向或横向时间序列数据。在面板数据中,您拥有所有时间段内个人的数据点。基本的面板数据回归模型类似于方程式(1),其中𝜶和𝜷是系数,而i和t是个体和时间的指标。面板数据使您可以控制变量并说明各个变量的差异性。有趣的是,在Python中使用Pandas模块时,您可能会奇怪为什么开发人员将其称为“ Pandas”-非常可爱!实际上,它来自“面板数据”。
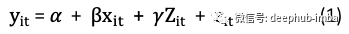
假设我们可以在OLS中详尽详尽地指定所有因素:如果我们想知道一个人的婚姻状况是否会增加一个人的收入。假设我们可以指定一个详尽的模型,明确列出影响收入水平的所有因素:
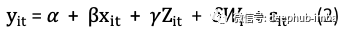
其中y_it是时间t中i的收入,x_it是婚姻状况,Z_it都是观察到的随时间变化的变量,例如年龄或工作数量。W_i都是观察到的不随时间变化变量,例如种族,𝛆_it是误差项。如果我们可以列出所有因素,则可以得到𝜷的无偏差估计。
在面板数据上运行OLS时,它也称为“池化OLS”。当每个观察值彼此独立时,这是没问题的,虽然这不太可能,因为面板数据中同一个人的观察是相关的。话虽如此,有时观察结果在面板内的相关性很小,可以忽略不计。然后,您可以这样做。
但是,我们不太可能在OLS中指定所有可能的因素:很可能我们无法详尽列出所有OLS的因素。假设我们从上面的方程式中省略了Z_it和W_i,而仅将y_it回归到x_it上。我们知道婚姻状况(x_it),年龄(Z_it)和种族(W_i)很可能相关。在没有明确指定Z_it和W_i的情况下,OLS中𝜷的估计几乎可以肯定是有偏差的。这是因为未在方程式中指定Z_it和W_i使得它们变得不可观察并合并到误差项𝛆_it中。这使得婚姻状况(x_it)是内生的(请参见上面的说明)。所以结果𝜷,无论是正数还是负数,都将毫无意义。因此,遗漏变量的问题是一个非常严重的问题。如果省略了任何已知变量,则OLS中的结果都是不可靠的。
固定效果模型
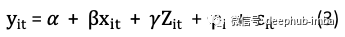
上面的𝝆_i变量称为固定效果,因为它不会随时间变化。它捕获了个人的所有不随时间变化的因素,例如性别,种族甚至个人特质。y_it和x_it是i的收入和婚姻状况,Z_it代表i的所有其他随时间变化的因素。假定误差𝛆_it与所有上述因素都不相关(如果违反了此假设,则将面临省略变量导致的偏差)。
如何估算方程式(3)?在几乎所有教科书中,您都可以看到像方程式(3)一样的基本表述形式。可以将其视为i = 0,1。当有多个个体i = 1,…N时,𝝆_i可以视为具有各自系数𝜽_i的一组(N-1)个虚拟变量D_i的简写,如图所示。等式(4)是您在回归输出中看到的。
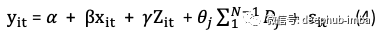
DiD是FE模型的特例
DiD是FE模型的特例。
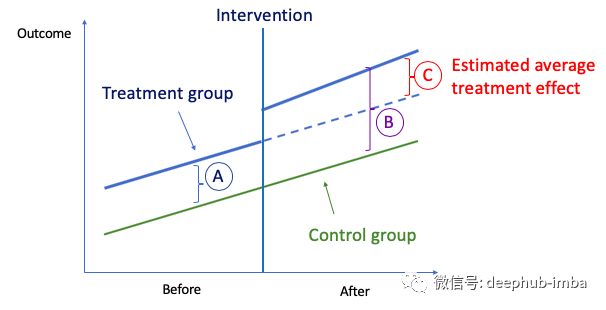
图(E):DiD
DiD背后的想法很简单。首先,我们计算在“Before”期间两组之间的结果均值之差,即图(E)中的“ A”。其次,我们在“After”期间计算相同的值,即“ B”。然后我们取“第二差异”,即“A”和“ B”之间的差异,并标记为“ C”。第二差异衡量两组结果的变化如何不同。差异归因于干预的因果效应。
以面板数据形式,可以通过“differencing out”混淆因素从有限元模型中得出DiD。因为没有混淆因素,所以影响确实是因果关系。典型设置类似于公式(5)。
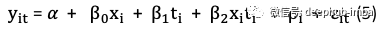
假设个体i在治疗组(x_i = 1)或对照组(x_i = 0)中,并且在治疗前(t_i = 1)或治疗后(t_i = 0)。后期的效应为𝜷_2,如图(E)所示。这是通过以下方式得出的:
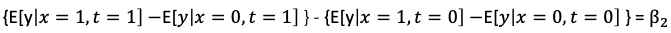
DiD模型和FE模型之间的区别在于更改是外生的。更改是在个人i的选择之外进行的。例如,某州更改了其最低饮酒年龄法律。此政策是外生的。
固定效应数据分析示例1 —投资与市场价值
公司投资的主要驱动力是什么?有大量的文献讨论了其驱动因素。Grunfeld认为,公司的市场价值是投资的主要解释和预测指标。在以下练习中,我将使用Grunfeld数据集(可在statsmodels.datasets中获得)来演示固定效果模型的使用。顺便说一句,Grunfeld数据集是计量经济学中的知名数据集,就像Machine Learning中的虹膜数据集一样。这篇学术文章“ 50岁时的Grunfeld数据”指出了它的广泛用途。
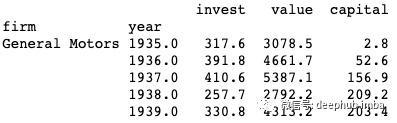
该数据包含11家公司中每家20年的数据:IBM,通用电气,美国钢铁,大西洋炼油,钻石比赛,西屋电气,通用汽车,固特异,克莱斯勒,联合石油和美国钢铁。在面板数据中,将“确定”和“年份”设置为索引。固定效果模型指定如下,其中单个公司因子为𝝆_i或在以下代码中称为
`entity_effects
。时间因子是𝝋_t或称为
time_effects
。
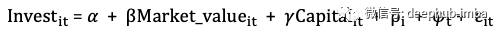
或如下所示,其中D_j是公司i的虚拟变量,而I_t是t年的虚拟变量。
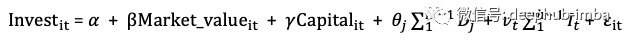
fromstatsmodels.datasetsimportgrunfeld
data = grunfeld.load_pandas().data
data = data.set_index(["firm","year"])
print(data.head())
模块
linearmodels
提供PandelOLS进行固定效果模型。
entity_effects=True
表示模拟企业特定因素。这意味着为11家公司创建10(N-1)个虚拟变量。下面我展示了两种回归方法的代码。两者产生相同的结果。
# Coding method 1
fromlinearmodels.panelimportPanelOLS
importstatsmodels.apiassm
exog = sm.add_constant(gf[['value','capital']])
grunfeld_fe = PanelOLS(gf['invest'], exog, entity_effects=True, time_effects=False)
grunfeld_fe = grunfeld_fe.fit()
print(grunfeld_fe)
# Coding method 2
grunfeld_fe = PanelOLS.from_formula("invest ~ value + capital + EntityEffects", data=gf)
print(grunfeld_fe.fit())
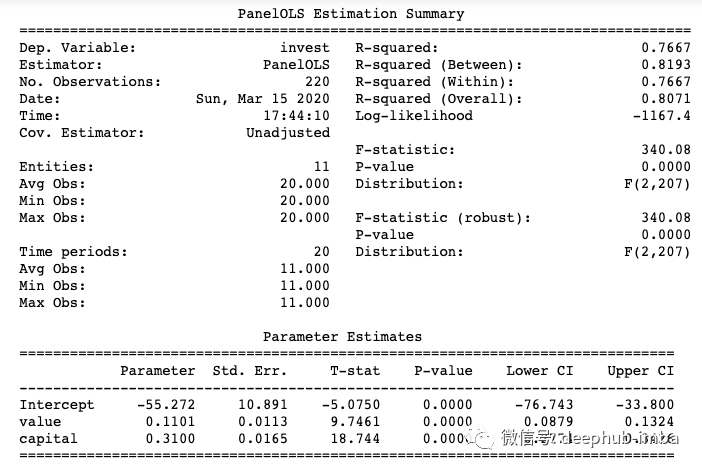
“value”的系数在95%时具有统计学意义上的0.1101。因此,Grunfeld得出了因果关系,即高投资是由高市场价值驱动的。
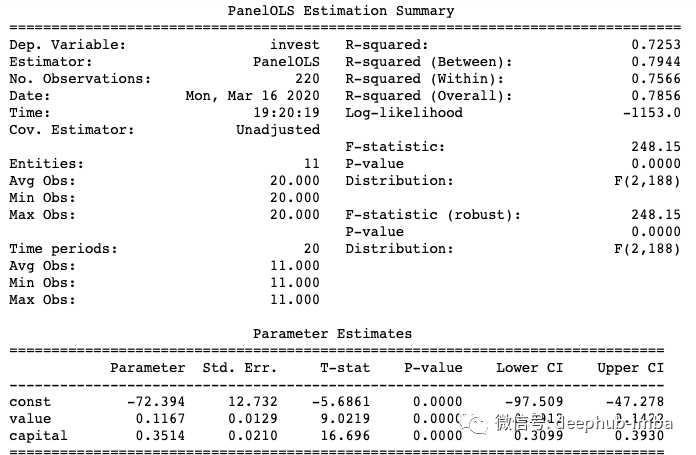
下面的代码同时指定了公司特有的效果和时间效果。结论保持不变。
# Coding method 1
fromlinearmodels.panelimportPanelOLS
importstatsmodels.apiassm
exog = sm.add_constant(gf[['value','capital']])
grunfeld_fet = PanelOLS(gf['invest'], exog, entity_effects=True, time_effects=True)
grunfeld_fet = grunfeld_fe.fit()
print(grunfeld_fet)
# Coding method 2
grunfeld_fet = PanelOLS.from_formula("invest ~ value + capital + EntityEffects + TimeEffects", data=gf)
print(grunfeld_fet.fit())
固定收益数据分析示例2 –交通死亡率与啤酒税
更高的啤酒税是否有助于减少交通致死率?许多州降低了啤酒税,交通事故死亡率更高。我们可以说降低啤酒税会导致更高的死亡率吗?这种因果关系具有深远的政策含义。我将使用Stock&Watson广为接受的书籍“计量经济学概论”中的死亡数据集。
importpandasaspd
importnumpyasnp
importseabornassns
fatalities = pd.read_csv('/fatality.csv')
fatalities.head()
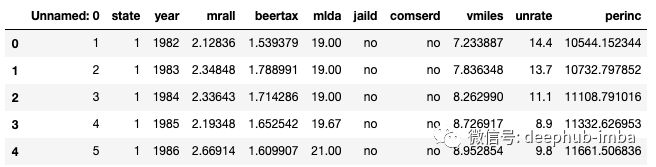
- mrall = 车辆总死亡率
- beertax = 酒精税
- mlda = 最低法定饮酒年龄
- jaild = 强制性入狱
- comserd = 强制性社区服务
- vmiles = 每位驾驶员的平均里程
- unrate = 失业率
- perinc = 人均个人收入
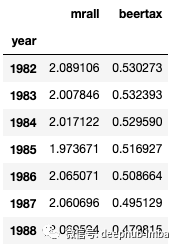
我将每年的数据生成平均值,以显示每年的平均啤酒税和死亡率。1982–1984年的平均啤酒税高于1986–1988年的啤酒税。
avg = fatalities.groupby('year')['mrall','beertax'].mean()
avg
我将使用
`seaborn
来显示相关性。
sns.set(style="darkgrid")
g = sns.jointplot("beertax", "mrall",
data=avg, kind="reg",
color="m", height=6)
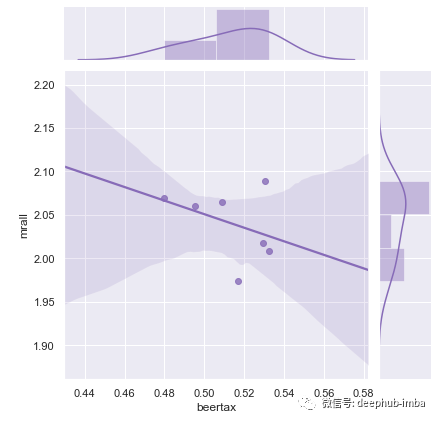
我们可以建立任何因果关系吗?我将使用固定效果模型进行测试。下面,我演示了两个固定效果模型并用于讨论和汇总OLS。
- 模型 1: 实体效果+时间效果
- 模型 2: Entity_effects
- 模型 3: 汇总OLS
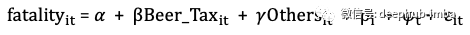
或如下所示,其中D_j是状态i的虚拟变量,而I_t是状态t的虚拟变量。
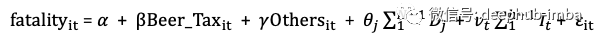
下面对州的不随时间变化的变量(例如州文化,州居民对饮酒的态度(可能是不随时间进行变化)等)进行控制。对所有州随时间变化的遗漏变量的时效控制。例如,宏观经济条件或联邦政策措施在所有州都是通用的,但会随时间而变化。
您可能会询问如何确认需要固定效果的模型规范。这是通过可合并性测试(Poolability Test)完成的。许多模块已经包含测试结果。用于
F-test for poolability
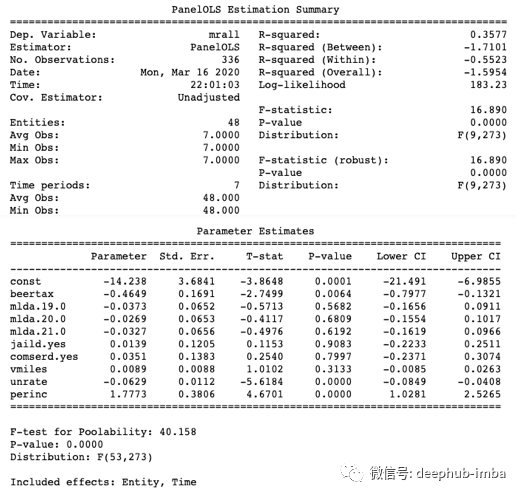
并显示输出。这是对没有固定效果的原假设的检验。模型1中的F-test是40.158,p值是0.0,因此我们可以拒绝原假设,并得出固定效果模型规格合适的结论。
模型1:实体效果+时间效果
# Coding method 1
fromlinearmodels.panelimportPanelOLS
importstatsmodels.apiassm
exog = sm.add_constant(fatalities[['beertax','mlda','jaild',
'comserd','vmiles','unrate','perinc']])
fe = PanelOLS(fatalities['mrall'], exog, entity_effects=True, time_effects=True)
fe = fe.fit()
print(fe)
# Coding method 2
fromlinearmodels.panelimportPanelOLS
fe = PanelOLS.from_formula("mrall ~ beertax + mlda + jaild
+comserd+vmiles+unrate +perinc+EntityEffects+TimeEffects",
data=fatalities)
print(fe.fit())
模型1告诉我们,啤酒税与死亡率之间存在负相关关系(啤酒税系数为-.4649)。因此,我们可以得出因果关系,即较高的啤酒税会导致较低的死亡率。
模型2:Entity_effects
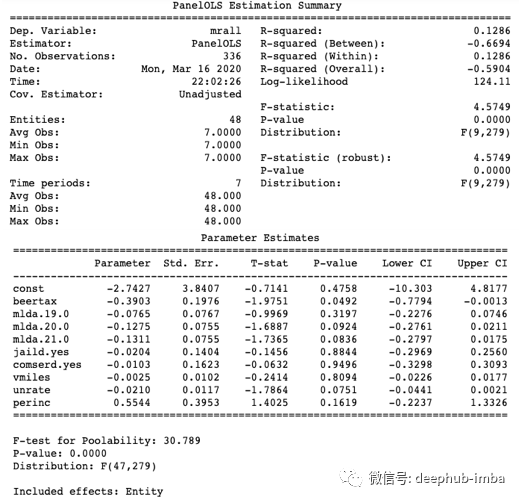
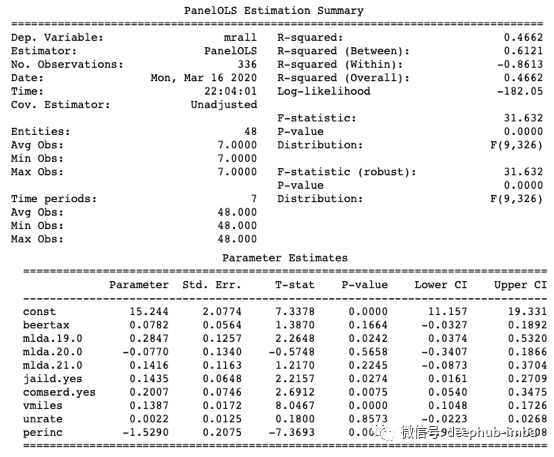
如何理解三个模型中的R-squared值?模型1中的R-squared为0.3577,高于模型2中的R-squared0.1286。这意味着模型1的拟合效果更好。模型3中的0.4662怎么样?尽管它比模型1和2的模型高得多,但是合并的OLS是一个错误指定的模型,如上面的公式(1)和(2)所述。由于模型3无法解决内生性问题,因此它无法帮助我们得出啤酒税和死亡率之间的因果关系。
# Coding method 1
fromlinearmodels.panelimportPanelOLS
importstatsmodels.apiassm
exog = sm.add_constant(fatalities[['beertax','mlda',
'jaild','comserd','vmiles','unrate','perinc']])
fe2 = PanelOLS(fatalities['mrall'], exog,
entity_effects=True, time_effects=False)
fe2 = fe2.fit()
print(fe2)
# Coding method 2
fromlinearmodels.panelimportPanelOLS
fe2 = PanelOLS.from_formula("mrall ~ beertax + mlda +
jaild+comserd+vmiles+unrate +perinc+EntityEffects",
data=fatalities)
print(fe2.fit())
模型3:汇总OLS
# Coding method 1
from linearmodels.panel import PanelOLS
import statsmodels.api as sm
exog = sm.add_constant(fatalities[['beertax','mlda',
'jaild','comserd','vmiles','unrate','perinc']])
pooledOLS = PanelOLS(fatalities['mrall'], exog,
entity_effects=False, time_effects=False)
pooledOLS = pooledOLS.fit()
print(pooledOLS)
# Coding method 2
from linearmodels.panel import PanelOLS
pooledOLS = PanelOLS.from_formula("mrall ~ beertax +
mlda + jaild + comserd + vmiles + unrate + perinc ",
data=fatalities)
print(pooledOLS.fit())
作者:Dr. Dataman
deephub翻译组:孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********