

机器学习是一个使用统计学和计算机科学原理来创建统计模型的研究领域,用于执行诸如预测和推理之类的主要任务。这些模型是给定系统的输入和输出之间的数学关系集。学习过程是估计模型参数的过程,以便模型可以执行指定的任务。学习过程会尝试使机器具有学习能力,而无需进行显式编程。这是ANN的作用。
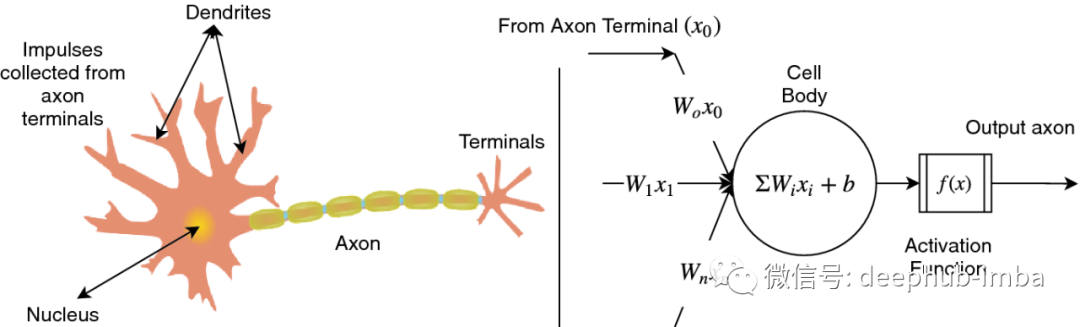
什么是人工神经网络?
典型的人工神经网络(ANN)是受人脑工作启发而设计的受生物启发的计算机程序。这些ANN称为网络,因为它们由不同的功能组成,这些功能通过使用过去称为训练示例的经验来检测数据中的关系和模式来收集知识。数据中的学习模式通过适当的激活函数进行修改,并作为神经元的输出呈现,如下图所示:
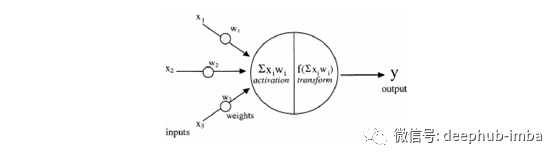
典型的受生物启发的神经元
什么是激活函数?在神经网络模型中怎么使用?
激活函数是神经网络中用于计算输入和偏差的加权和的函数,用于确定神经元是否可以释放。它通常通过梯度下降法的某种梯度处理来操纵数据,然后产生神经网络的输出,该输出包含数据中的参数。有时这些激活函数通常称为传递函数。
激活函数具有改善数据学习模式的能力,从而实现了特征检测过程的自动化,并证明它们在神经网络的隐藏层中的使用合理性,并且对于跨领域进行分类很有用。
激活函数可以是线性的,也可以是非线性的,具体取决于它所代表的功能,并用于控制我们的神经网络的输出,其范围从对象识别和分类到语音识别,分段等更多领域。
激活函数如何修改线性模型使用的学习模式?
对于线性模型,在大多数情况下,通过隐式变换可以给出输入函数到输出的线性映射,如在每个标签的最终评分最终预测之前在隐藏层中执行的那样。输入向量x转换由下式给出:
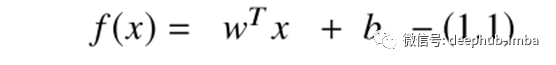
其中x =输入,w =权重,b =偏差。
此外,神经网络从等式1.1的映射生成线性结果,因此需要激活函数,首先将这些线性输出转换为非线性输出以进行进一步计算,尤其是学习模式。这些模型的输出如下:
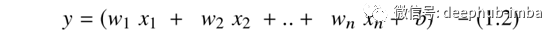
每层的这些输出都将导入多层网络(如深度神经网络)的下一个后续层,直到获得最终输出为止,但默认情况下它们是线性的。预期的输出确定要在给定网络中部署的激活功能的类型。但是,由于输出本质上是线性的,因此需要非线性激活函数才能将这些线性输入转换为非线性输出。这些激活函数是传递函数,可应用于线性模型的输出以生成转换后的非线性输出,以备进一步处理。应用AF后的非线性输出如下:
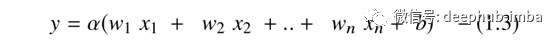
其中α是激活函数
那么激活函数有什么需求?
对这些激活函数的需求包括将线性输入转换为非线性输出,这有助于更深层网络学习高阶多项式。非线性激活函数的一个特殊属性是它们是可微的,否则它们在深度神经网络的反向传播期间将无法工作。深度神经网络是具有多个隐藏层和一个输出层的神经网络。了解多个隐藏层和输出层的构成是我们的目标。下方显示了深度学习模型的框图,该框图显示了构成基于DL的系统的三层,其中有些标出了激活函数的位置,这些函数由各个模块中的深色阴影区域表示。

基于DL的系统模型的框图,显示了激活功能
输入层接受用于训练神经网络的数据,该数据有来自图像,视频,文本,语音,声音或数字数据的各种格式,而隐藏层则主要由卷积和池化层组成,其中卷积层从图像中以阵列状形式处理前一层数据中的模式和特征,而池化层将相似特征合并为一个。输出层显示网络结果,这些结果通常由激活函数控制,尤其是分类或预测的相关的概率。
激活函数在网络结构中发挥的功能取决于其在网络中的位置,因此,将激活函数放置在隐藏层之后时,它将学习到的线性映射转换为非线性形式以便传播,而在输出层中则执行预测功能。
只是永远记住要做:
“输入乘以权重,添加偏差并激活”
激活函数的类型及其分析
本节重点介绍了激活函数的不同类型及其分析:
- Sigmoid函数
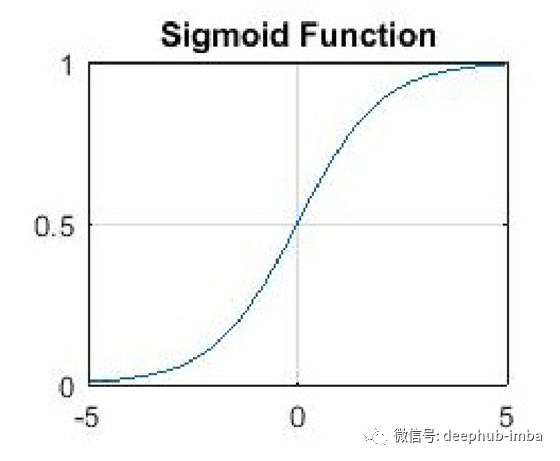
Sigmoid有时被称为逻辑函数。Sigmoid是非线性激活函数,主要用于前馈神经网络。它是一个有界的可微分实函数,为实数输入值定义,到处都有正导数,并具有一定程度的平滑度。
Sigmoid函数由以下关系给出:
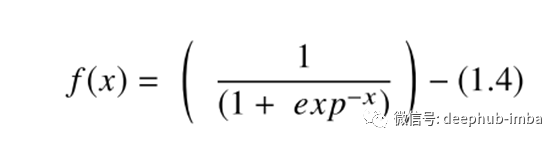
Sigmoid出现在深度学习架构的输出层中,它们可用于预测基于概率的输出,并已成功应用于二分类问题,建模逻辑回归任务以及其他神经网络领域。
Sigmoid激活函数的主要缺点包括反向传播期间从较深的隐藏层到输入层的尖锐阻尼梯度,梯度饱和,收敛缓慢和非零的中心输出,从而导致梯度更新沿不同方向传播。
- 双曲正切函数(Tanh)
双曲正切函数是深度学习中使用的另一种激活函数,并且在深度学习应用程序中具有某些变体。被称为tanh函数的双曲正切函数是一个更平滑的零中心函数,范围在-1到1之间,因此tanh函数的输出由下式给出:
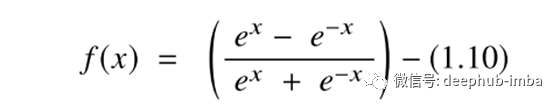
与sigmoid函数相比,tanh函数更好,因为它为多层神经网络提供了更好的训练性能。但是,tanh函数也无法解决S形函数所遭受的消失梯度问题。该函数提供的主要优点是,它可以产生零中心输出,从而有助于反向传播过程。tanh函数的一个特性是,仅当输入值为0时,即x为零时,它才能达到1的梯度。这使得tanh函数在计算过程中产生一些死亡的神经元。死神经元是激活权重很少被归因于零梯度的结果的情况。
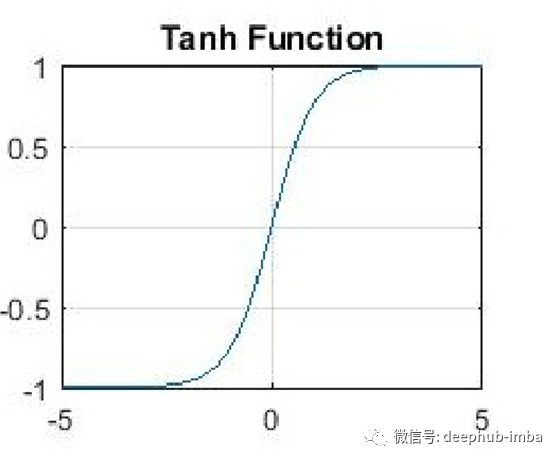
tanh函数的这种局限性促使人们进一步研究激活函数从而解决这个问题,最终诞生了整流线性单元(ReLU)激活函数。tanh函数主要用于自然语言处理和语音识别任务的递归神经网络中。
- 整流线性单元(ReLU)功能
整流线性单元(ReLU)激活函数由Nair和Hinton在2010提出,从那时起,它一直是深度学习应用程序中使用最广泛的激活函数,具有迄今为止最先进的结果。ReLU是一种快速学习的激活函数,已被证明是最成功且使用最广泛的函数。与Sigmoid和tanh激活函数相比,它在深度学习中具有更好的性能和通用性。ReLU表示几乎是线性的函数,因此保留了线性模型的属性,这些属性使它们易于使用梯度下降法进行优化。ReLU激活功能对每个输入元素执行阈值操作,其中小于零的值设置为零,因此ReLU的计算公式为:
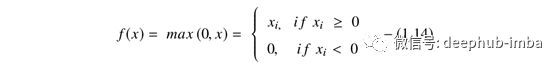
此函数可对输入值进行校正,使其小于零,从而将其强制为零,并消除了在早期激活函数类型中观察到的梯度消失问题。
ReLU函数已在深层神经网络的隐藏单元中与另一个激活函数一起使用,在网络的输出层中是对象分类和语音识别应用程序中的典型示例。在计算中使用Relu的主要优点在于,由于它们不计算指数和除法,因此它们保证了更快的计算速度,从而提高了总体计算速度。ReLU的另一个特性是,当它压缩介于0到最大值之间的值时,会在隐藏的单位中引入稀疏性。
然而,尽管已经采用了dropout技术来减少ReLU的过拟合效应,并且网络改善了深层神经网络的性能,但ReLU的局限性仍然在于与S型函数相比它容易过拟合。
ReLu的另一个问题是,某些梯度在训练过程中可能会很脆弱,甚至会消失。它可能导致权重停止更新,从而使其永远不会再在任何数据点上激活。简而言之,ReLu可能导致神经元死亡。
为了解决这个问题,引入了另一种名为Leaky ReLu的修改来解决死亡的神经元问题。它引入了一个小偏置以使更新保持活动状态。
- Softmax函数
Softmax函数是计算中使用的另一种激活函数。它用于根据实数向量计算概率分布。Softmax函数产生的输出范围是0到1之间的值,且概率之和等于1。
Softmax函数的计算公式如下:
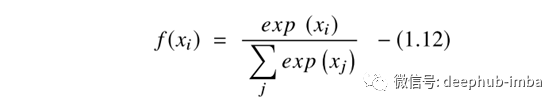
Softmax函数用于多分类模型中,在该模型中,它返回每个类的概率,而目标类的概率最高。Softmax函数主要出现在使用它们的深度学习架构的几乎所有输出层中。Sigmoid和Softmax激活函数之间的主要区别在于,Sigmoid用于二分类,而Softmax用于多分类任务。
理论上足够了对吗?我认为现在是时候检查不同的激活函数并比较它们的性能,然后选择对我们更合适的函数。因此,让我们从选择一个数据集开始。
作为该领域的新手,您可能遇到过MNIST这个词。它是一个Digit Recognizer数据集,非常适合入门。
https://www.kaggle.com/c/digit-recognizer/data
数据文件train.csv和test.csv包含从零到九的手绘数字的灰度图像。
每个图像的高度为28像素,宽度为28像素,总计784像素。每个像素都有一个与之关联的像素值,表示该像素的亮度或暗度,数字越高表示像素越暗。此像素值是0到255之间的整数(含)。
训练数据集(train.csv)有785列。第一列称为“标签”,是用户绘制的数字。其余列包含关联图像的像素值。
训练集中的每个像素列都有一个类似pixelx的名称,其中x是0到783之间(包括0和783)的整数。
测试数据集(test.csv)与训练集相同,除了它不包含“标签”列。
在开始编写代码之前,我建议您使用Google Collaboratory,因为它既快速又易于使用。
imports
# This Python 3 environment comes with many helpful analytics libraries installed, here's several helpful packages to load in
importpandasaspd
importnumpyasnp
importkeras
importmatplotlib.pyplotasplt
fromkeras.utilsimportto_categorical
fromkeras.modelsimportSequential, load_model
fromkeras.layersimportDense, Dropout, Flatten
fromkeras.layersimportConv2D, MaxPooling2D
fromkeras.layers.normalizationimportBatchNormalization
fromkeras.layers.advanced_activationsimportLeakyReLU
fromsklearn.model_selectionimporttrain_test_split
加载数据集和数据预处理
df = pd.read_csv("train.csv")X_train = np.array(df.iloc[:,1:])
y_train = np.array(df.iloc[:,0])
X_train = np.reshape(X_train,(-1,28,28,1))defcreate_dev_set(X_train, Y_train):
## split 42000 into 35000 and 7000(0.16)
returntrain_test_split(X_train, Y_train, test_size = 0.166, random_state = 0)X_train, X_dev, y_train, y_dev = create_dev_set(X_train, y_train)
print('Training data shape : ', X_train.shape, y_train.shape)
print('Dev data shape : ', X_dev.shape, y_dev.shape)

classes = np.unique(y_train)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)

X_train = X_train.astype('float32')
X_dev = X_dev.astype('float32')
X_train = X_train/255.
X_dev = X_dev/255.y_train_one_hot = np.array(to_categorical(y_train))
y_dev_one_hot = np.array(to_categorical(y_dev))
构建模型
batch_size = 64
epochs = 30
num_classes = 10dr = Sequential()dr.add(Conv2D(32, kernel_size=(3,3),activation='relu',input_shape=(28,28,1),padding='same'))dr.add(BatchNormalization(axis=-1))
dr.add(LeakyReLU(alpha=0.1))
dr.add(MaxPooling2D((2,2),padding='same'))
dr.add(Dropout(0.3))
dr.add(Conv2D(64, (3,3), activation='relu',padding='same'))
dr.add(BatchNormalization(axis=-1))
dr.add(LeakyReLU(alpha=0.1))
dr.add(MaxPooling2D(pool_size=(2,2),padding='same'))
dr.add(Dropout(0.3))
dr.add(Conv2D(128, (3,3), activation='relu',padding='same'))
dr.add(BatchNormalization(axis=-1))
dr.add(LeakyReLU(alpha=0.1))
dr.add(MaxPooling2D(pool_size=(2,2),padding='same'))
dr.add(Dropout(0.4))
dr.add(Flatten())
dr.add(Dense(120, activation='relu'))
dr.add(BatchNormalization(axis=-1))
dr.add(LeakyReLU(alpha=0.1))
dr.add(Dropout(0.3))
dr.add(Dense(40, activation='relu'))
dr.add(BatchNormalization(axis=-1))
dr.add(LeakyReLU(alpha=0.1))
dr.add(Dropout(0.2))
dr.add(Dense(num_classes, activation='softmax'))dr.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])dr.summary()
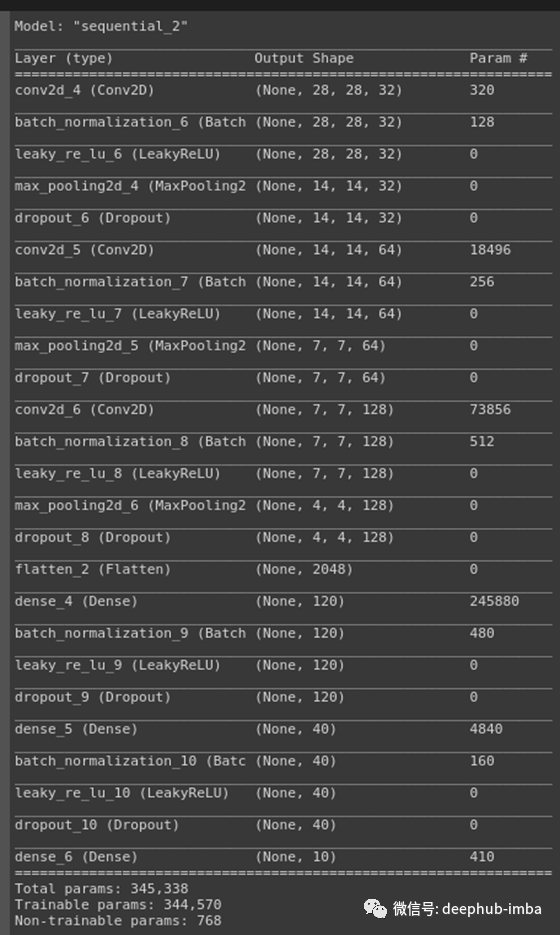
在这里,我们对所有隐藏层使用relu激活函数,对输出层使用softmax激活函数。ReLu只应应用于隐藏图层。而且,如果您的模型在训练过程中出现神经元死亡的情况,则应使用leaky ReLu或Maxout函数。
训练和可视化
training = dr.fit(X_train, y_train_one_hot, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(X_dev, y_dev_one_hot))dr.save("Conv2D_DR_dropout.h5py")test_eval = dr.evaluate(X_dev, y_dev_one_hot, verbose=0)
print(test_eval)accuracy = training.history['acc']
val_accuracy = training.history['val_acc']
loss = training.history['loss']
val_loss = training.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
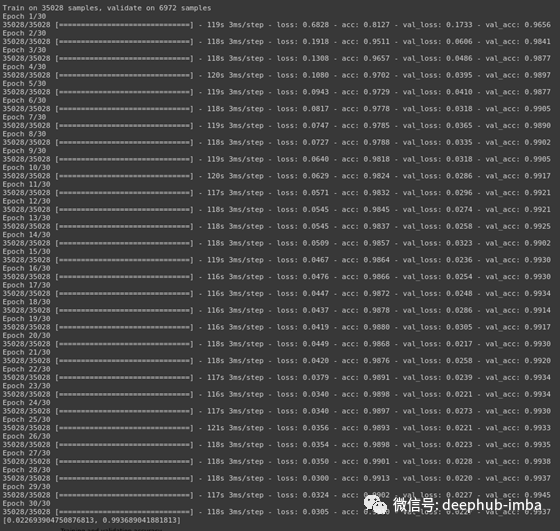
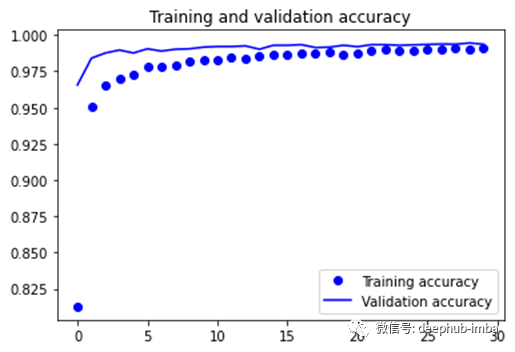
结果评估
print("Training dataset evaluation")
test_eval = dr.evaluate(X_train, y_train_one_hot, verbose=0)
print(test_eval)
print("Dev dataset evaluation")
test_eval = dr.evaluate(X_dev, y_dev_one_hot, verbose=0)
print(test_eval)
输出
Trainingdatasetevaluation
[0.003591470370079107, 0.9918690614700317]
Devdatasetevaluation
[0.022693904750876813, 0.993689041881813]
结论
本文提供了深度学习中使用的激活函数的全面摘要,最重要的是,重点介绍了在实践中使用这些功能的特点。
问题是哪个更好用?
正如我们在深度学习应用程序中使用激活函数所观察到的那样,较新的激活函数似乎要优于诸如ReLU之类的较早的激活功能,但即使是最新的深度学习架构也都依赖ReLU功能。这在SeNet中很明显,其中隐藏层具有ReLU激活函数和Sigmoid输出。
由于梯度消失的问题,如今不应该使用Sigmoid和Tanh,它会导致很多问题,从而降低了深度神经网络模型的准确性和性能。
本文作者:MRINAL WALIA https://github.com/abhiwalia15
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********