

每个时间序列(TS)数据都装载有信息;时间序列分析(TSA)是解开所有这些的过程。然而,要释放这种潜力,需要在将数据放入分析管道之前对其进行适当的准备和格式化。

TS可能看起来像一个简单的数据对象,易于处理,但事实是,对于新手来说,在真正有趣的事情开始之前,仅仅准备数据集就可能是一项艰巨的任务。
因此,在本文中,我们将讨论一些简单的技巧和技巧,以获得准备好分析的数据,从而潜在地节省大量工作时间。
找到数据
如果您正在使用自己的数据集进行分析,那么您已经拥有了它。但是对于那些刚刚学习TSA的人来说,找到正确的数据集可能是一项繁重的任务。
实际上有相当多的数据源。一些随机器学习库而来的数据集——它们被称为玩具数据——已经存在很长时间了。这些“玩具”数据非常适合玩,尤其是初学者。但这是一种瘾,每个人都需要尽快摆脱它,投入到现实世界中去。
下面是一些在不同领域的主题范围内查找数据的来源——有些是经过策划的,有些需要清理。你一定要从这个列表中找到你最喜欢的。
我建议您从现成可用数据集开始,这样您就不必绞尽脑汁去解决数据问题,也不会对真正有趣的东西失去兴趣。但一旦你掌握了基本原理,发现数据越乱越好,它就会迫使你完成整个分析过程。
好了,这里有一些玩具数据集-清洁,策划和分析-准备好-在机器学习教程中经常使用:
- air passengers :1949年至1960年,每月报告的航空旅客人数
- electric energy consumption :美国某些州客户的小时电能消耗
- Stock market data :股票市场的数据随着开盘价、最高价、最低价和收盘价以及不同公司的交易量而变化
- shampoo sales:一个关于洗发水销售的超级小数据集
- Daily minimum temperature:1981年至1990年的每日最低气温数据(我不知道代表哪个国家/城市,但这无关紧要)
- air quality data :每天记录印度不同城市的空气质量数据(CO, SO2, O3等)
对于真实世界的数据集,有一些非常棒的数据。但是你不需要超越这些库去学习高级的TS分析和建模。
- 美国人口普查局拥有大量关于美国商业活动的时间序列数据 Census Bureau
- 美联储经济数据(FRED)是美国经济指标的重要数据来源 Federal Reserve Economic Data (FRED)
- 《世界发展指标》是世界银行关于世界各国社会、经济和环境问题的大型数据库。World Development Indicators (WDI)
数据准备
对于初学者来说,总是有把时间序列当作其他数据集的诱惑。然后操之过急。但是TS观测结果与我们熟悉的横断面观测结果不同。
时间序列数据已经存在很长一段时间了,许多人将他们的生命奉献给了其他人的生活变得更简单。
有相当多的库是专门为处理TS数据而设计的。通过转换数据,可以让库将其识别为一个特殊的TS对象。
假设您已经完成了所需的预处理—例如重命名列、处理丢失的值等—以下是您如何在几个步骤中准备数据的方法。
在这个练习中,我使用了一个在机器学习中过度使用的玩具数据—航空乘客数据集—并使用Python执行代码。
# import a couple of libraries
import pandas as pd
import numpy as np# import data
df = pd.read_csv("../DataFolder/file.csv")# look at the head
df.head()
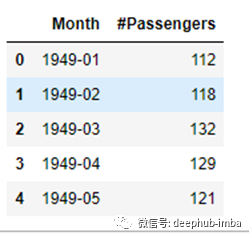
从前几行我们可以看到,数据集有两列,第一列表示“yyyy - mm”格式的日期列和具有实际观测值的值列。
记住,我们还不知道它是否是一个时间序列对象,我们只知道它是一个具有两列的dataframe。
df.info()
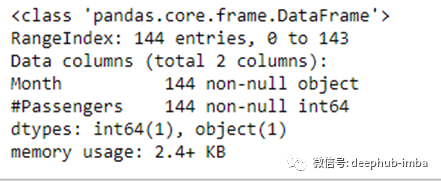
这个摘要确认了它是一个包含两列的panda dataframe。第一列是一个对象,第二列是一个整数。
它不显示任何时间维度,这是因为Month列存储为字符串。因此,我们需要将其转换为datetime格式。
df_air["Month"] = pd.to_datetime(df_air["Month"])
接下来,让它成为索引。这样做的好处是您可以以任何方式过滤/切片数据:按年、月、日、工作日、周末、特定的日/月/年范围等等。
df_air = df_air.set_index("Month")
df_air.head()
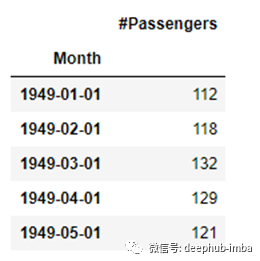
最后一个好的实践是从datetime索引中提取年份、月份和工作日,并将它们存储在单独的列中。这给了一些额外的灵活性,“分组”数据根据年/月等,如果需要。
df_air['year'] = df_air.index.year
df_air['month'] = df_air.index.month
df_air['weekday'] = df_air.index.weekday_name
这就是最终的数据集。比较一下与原始数据的差异。此外,正如下面用突出显示的,它现在确认它不是任何数据流,而是一个时间序列对象。
df.head()
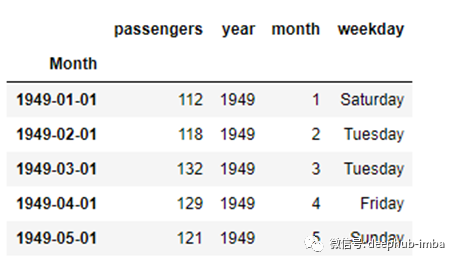
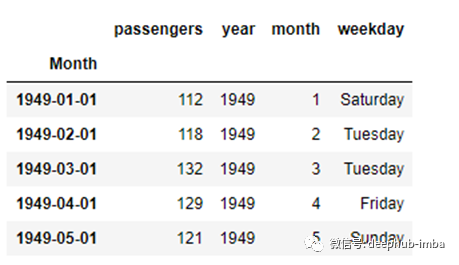
总之,我们已经做了一些事情来将我们的数据转换成一个时间序列对象:
1)将Month列从字符串转换为datetime;
2)将转换后的datetime列设置为索引;
3)从索引中提取年、月、日,并存储在新列中
现在已经有了可以分析的数据,下一步是什么?
现在,可以通过本文获得您想要的所有有趣的分析,我将在以后的文章中介绍。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********