
AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
文章目录
一、迁移学习
迁移学习本质上是将已有的知识用于学习新的知识。由于直接从头开始学习新任务的代价可能很高,因此迁移学习利用已有的相关知识来辅助尽快地学习新知识。
迁移学习主要用于解决数据集大小的问题。由于标注数据的获取成本高且标注数据稀缺,迁移学习被用来从相关的辅助领域中迁移知识以提高目标领域的学习效果。
迁移学习对人类来说也很常见。例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域学习过的模型应用在新领域上。
在实践中,可以利用迁移学习的思想,将已有的一些训练好的模型,迁移到我们的任务中,针对具体的任务进行微调来降低学习和训练的成本。
**例如卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。得到这样的特征后,可以使用线性分类器(Liner SVM、Softmax等)来分类图像。 Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune的全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,故fine-tune时常常只需要采用较小的学习率来Fine-tuning后面的层。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/wxplol/article/details/104225269**
二、迁移学习与时序预测任务
时序预测任务,以温度的预测为例。
假设我们手中具备丰富的A地温度数据集和少量的B地温度数据集,那么我们可以利用A地数据训练出base_model并冻结其参数,将其作为对B地数据训练的一部分加以利用。
在训练的新的模型时,拟合B地数据时,新模型的base_model部分参数并不发生改变,当作“特征提取器”在新模型中发挥作用,剩余部分进行拟合,挖掘出B地数据内含的数据特征与分布规律。
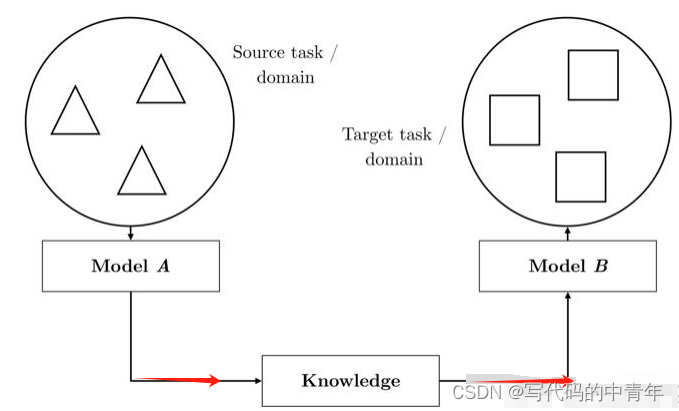
三、代码示例
base_model部分模型设计及训练
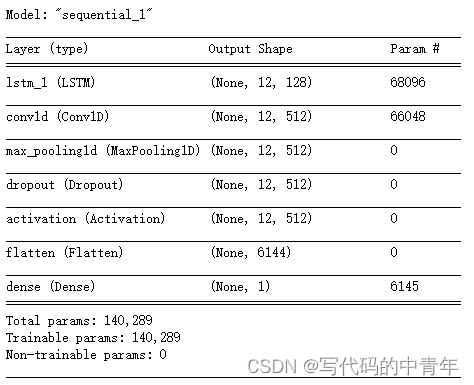
pre_model =Sequential() # 创建Sequential模型。
pre_model.add(LSTM(128, input_shape=(trainX.shape[1], trainX.shape[2]), return_sequences=True)) # 添加LSTM层,指定输入形状和输出形状。
pre_model.add(Conv1D(filters=512, kernel_size=1, activation='relu', input_shape=(trainX.shape[1], trainX.shape[2]))) # 添加一维卷积层。
pre_model.add(MaxPooling1D(pool_size=1)) # 添加最大池化层。
pre_model.add(Dropout(0.2)) # 添加Dropout层,用于正则化。
pre_model.add(Activation('relu')) # 添加激活函数层。
pre_model.add(Flatten()) # 添加扁平化层。
pre_model.add(Dense(1)) # 添加全连接层。
pre_model.compile(loss='mse', optimizer='adam') # 编译模型,指定损失函数、优化器和评估指标。
pre_model.summary()#输出参数
pre_model.fit(trainX, y_train, epochs=20, batch_size=32, verbose=1, validation_split=0.2) # 训练模型。
pre_model.save('pre_model.h5')
迁移模型部分模型设计及训练
base_model =Sequential() # 创建Sequential模型。
base_model .add(LSTM(128, input_shape=(trainX.shape[1], trainX.shape[2]), return_sequences=True)) # 添加LSTM层,指定输入形状和输出形状。
base_model .add(Conv1D(filters=512, kernel_size=1, activation='relu', input_shape=(trainX.shape[1], trainX.shape[2]))) # 添加一维卷积层。
base_model .add(MaxPooling1D(pool_size=1)) # 添加最大池化层。
base_model .add(Dropout(0.2)) # 添加Dropout层,用于正则化。
base_model .add(Activation('relu')) # 添加激活函数层。
base_model .add(Flatten()) # 添加扁平化层。
base_model .add(Dense(1)) # 添加全连接层。
base_model .compile(loss='mse', optimizer='adam') # 编译模型,指定损失函数、优化器和评估指标。
base_model .summary()#输出参数
base_model = tf.keras.models.load_model('pre_model.h5')
base_model.trainable = False
prediction_layer1 = tf.keras.layers.Dense(128,activation='relu')
prediction_layer2 = tf.keras.layers.Dense(1)
model = tf.keras.Sequential([
base_model,
prediction_layer1,
prediction_layer2
])
model.summary()

model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='mse')
model.fit(trainX, y_train, epochs=20, batch_size=32, verbose=1, validation_split=0.2) # 训练模型。
总结
完结,撒花!
版权归原作者 写代码的中青年 所有, 如有侵权,请联系我们删除。