
标签:机器学习、深度学习、神经网络、图像检索、图像处理、数据驱动、行人重识别、行人检索、评价度量
定义
行人重识别(Person re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合,可广泛应用于智能视频监控、智能安保等领域。该问题于2017年在行人重识别领域首次被Wu等人提出定义。他们提出了一个跨模态行人重识别框架,并提供了一个公开的大规模 RGB-红外多模态行人 数 据 库 ,名 称 为 SYSU Multiple Modality Re- ID(SYSU-MM01),之后开始有大量相关工作涌现,然而距离跨模态行人重识别能够投入实际场景中应用依旧存在许多问题。
由于不同摄像设备之间的差异,不同的低图像分辨率,照明变化,无约束姿态,异构模式,复杂的相机环境,背景杂波,不可靠的边界框生成,同时行人兼具刚性和柔性的特性 ,外观易受穿着、尺度、遮挡、姿态和视角等影响,使得行人重识别成为计算机视觉领域中一个既具有研究价值同时又极具挑战性的热门课题。
任务难点
目前,跨模态行人重识别问题面临的困难与挑战主要在于:
1)两种模态下捕捉的图像存在较大差异。RGB图像拥有三个通道,包含了红绿蓝的可见光颜色信息,而红外图像只有一个通道,包含了近红外光的强度信息,而且从成像原理的角度出发,二者的 波长 范围也有所区别,不同的清晰度和光照条件在两类图像上所能产生效果可能会大相径庭。
2)数据集较为单一且 规模较小。虽然现在已经有许多工作致力于扩充行人重识别数据集,然而数据集中的图像大多来源于相似型号以及角度的机位,和实际中多样化的场景差距较大。
3)传统行人重识别中存在的 模态内差异。例如,低分辨率、遮挡、视角变化等问题在跨模态行人重识别中也依旧存在。
4)人工难以分辨跨模态图像的行人身份导致标注数据缺乏。
跨膜态图像数据集
1. SYSU-MM01
链接:云盘下载 提取码: dzx8
SYSU-MM01是一个大规模的跨模态行人Re-ID数据集。它是由中山大学校园内的4台通用RGB摄像机和2台近红外摄像机采集,此数据集包含在室内和室外环境中捕获的图像,这使得该数据集极具挑战性。
SYSU-MM01包含491个人物身份(287628张可见光图像和15792张红外图像),每个身份出现在两个以上不同的模态摄像机中。具体来说,它包含395个用于训练的标识和96个用于测试的标识。训练集总共包含22,258张可见光图像和11,909张近红外图像,这些图像来自室内和室外摄像机。对于测试,它包含两种不同的评估设置,全搜索模式和室内搜索模式。查询集包含在两种设置下从IR摄像机3和6捕获的3,803张图像,图库集包含从四个RGB相机在全搜索模式下捕获的所有可见图像,而室内搜索模式只包含两个室内相机捕获的图像。
SYSU_MM01数据集共包含七个文件夹, 其中cam1,cam2,cam4,cam5均为RGB图像,cam3和cam6为IR(Infrared)图像。

下面一排图片是属于同一身份的不同图片。


2. RegDB
云盘下载 提取码: 2347
RegDB数据集是由双摄像机系统收集的小规模数据集,包括一个可见光摄像机和一个热感摄像机。该数据集总共包含412个人的身份(总共8240张图像),其中每个身份有10个可见光图像和10个近红外图像。数据库包含4,120个可见光图像和4,120个对应的热图像。 在412人中,女性占254人,男性占158人。此外,正面拍摄了156人,其余256人。训练集和测试集各有206个行人。该数据集图像小,清晰度较差,每个身份的RGB图像和热图像的姿态都是一一对应的,并且同一个身份在姿态上变化很小,这些因素都降低了该数据集RegDB上的跨模态行人重识别任务的难度。下图,显示了数据库中的一些示例图像对。

热图像所带来的好处
① 热图像中身体与背景的区别性大于可见光图像,这可以更容易检测行人区域(区别性比较大);
② 热图像显示了身体形状的信息,捕捉身体姿势,提供了使用热图像检测和识别的能力(凸显身体姿势);
③ 衣服的细节纹理、颜色和灰色信息在热图像中消失,这可以使识别对衣服的变化和环境的变化保持鲁棒(着重身体轮廓)。
评估协议
由于RegDB数据集最初不是用来做跨模态行人重识别的,作者只是想使用热图像来辅助RGB图像来训练ReID任务,所以原始文章并没有说明如何使用。在跨模态行人重识别中,对RegDB数据集的使用,以下这种方法使用较多:
- 随机选择206个身份进行训练,剩下的206个身份就用作测试。
- 分别评估用RGB图查询IR图,用IR图查询RGB图的性能。
- 可见光模态的图像作为查询数据,热模态的图像作为图库数据。
- 随机划分10次,取平局值即为最终的性能。
当今主流研究方法
1. 基于行人部位的方法
1.1 基于部件匹配的方法
基于人体在三维空间中的结构(结构信息),人体图像可以进行分割,按部件来执行匹配。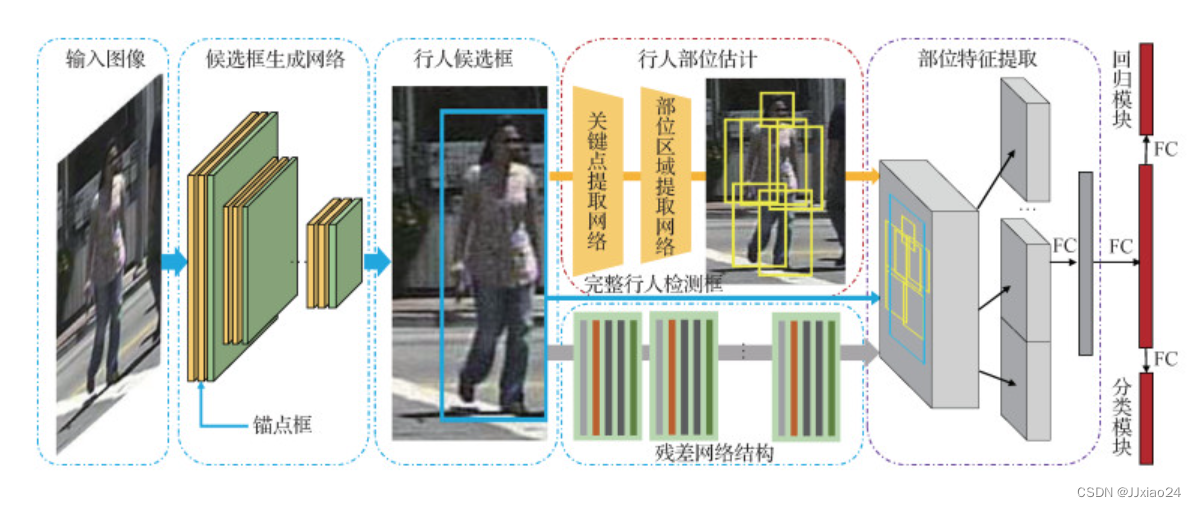
1.常见方案是水平切割,就是将图像切为几个水平的条。由于人体身材往往差不多,所以可以用简单的水平条来做比较。
2.在领域中做匹配,采用的是一个正方形的邻域。
3.另一个较新的方案是先在人体上检测部件(头部、上身、手臂、腿部等等)再进行匹配,这样的话可以减少位置的误差,但可能引入检测部件的误差。
4.类似LSTM的attention匹配,但必须成对输入,测试的时间较长,不适合快速图像检索。
5.如图,类似人脸对齐,使用STN 将行人整个图像先利用热度图对齐,再匹配。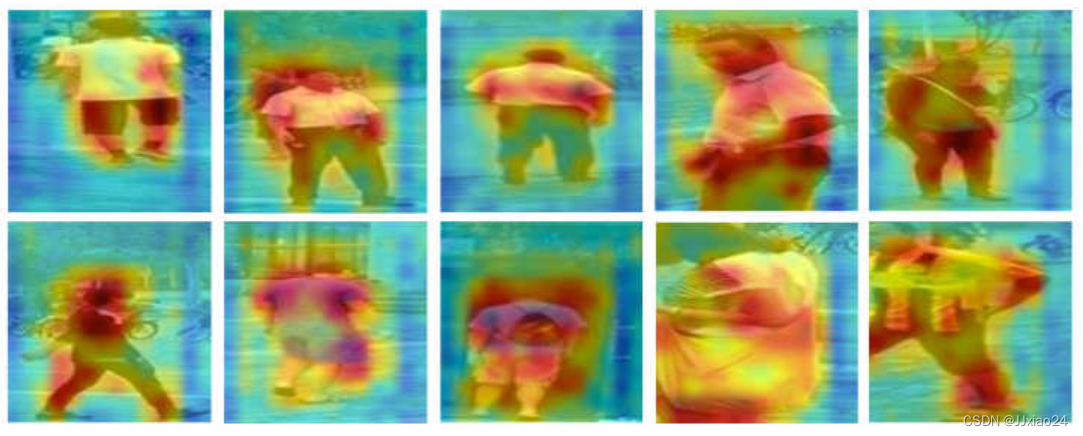
缺点如下:
一,此类方法需要额外的部位标注训练人体关键点或部位检测网络;
二,依赖数据驱动的部位检测器往往难以适配遮挡模式的多变。
1.2 基于注意力机制的方法
基于注意力机制的方法以弱监督的方式自适应地引导行人检测网络更多地关注遮挡行人的可见部位。通过建立选择注意力机制,使遮挡行人可见身体部位对应的通道获得更高的权重,以此降低遮挡噪声对行人检测器的干扰,提升遮挡行人的检测精度。 常见的方法有基于通道注意力、利用行人的可见身体部位构建逐像素的空间注意力。
如图所示。该模块通过空间掩膜引导检测器重点关注行人可见的身体区域,同时一定程度上降低行人的遮挡部分的特征权重,以此获得更加鲁棒的特征。
2. 基于损失函数的方法
- 身份损失(Identification loss),将训练过程看做成一个分类问题,直接拿身份标签做多类别分类。
- 验证损失(Verification loss),比较两个输入图像是否为同一人。
- 总损失 = 身份损失(Identification loss)+鉴定损失(Verification loss)。
- 三元组损失 (Triplet loss), 将训练视为一个检索排序问题,以3个样本为一组,同一身份的人的图像特征距离应 小于 不同身份的人。
- 加入属性任务 (attribute),比如判断是否背包,是男生还是女生等等。人们遇见陌生人也是利用这些属性来描述。
- 数据增强。混合多数据集训练 ,加入训练集上生成对抗网络(GAN)生成的数据。← 有篇文章
3. 基于表征学习的方法
基于表征学习的方法主要研究如何设计建模合理的网络架构,能够提取两种模态图像共享的具有鲁棒性和鉴别性的特征,尽量缩小模态间存在的差异性,输入到共享参数的网络,从而比较二者的相似性。
前人种树,后人乘凉:
2017 年,Wu (RGB-Infrared Cross-Modality Person Re-Identification) 文章地址 等人首次在行人重识别领域提出定义了跨模态行人重识别的问题,分析了三种网络架构,并提出了一种深度补零(deep-padding)的数据预处理方法,比较评估了这四种网络的性能。其中,三种网络架构分别为单流网络、双流网络以及非对称全连接层结构。经过研究发现,这三种网络在特殊情况下都可以使用单流网络来表示。通过将不同模态的数据通道置于不同的对应通道,而将属于其他模态的置零,从而提出深度补零的单流网络。网络中不同的节点对应不同的模态数据会选择性“失活”,同时也存在始终激活的节点,针对不同模态数据的输入,可以进行不同的特征提取操作。
网络结构如下:

有兴趣的可以查看我的另外一篇文章,点这里
1)底层视觉特征:这种方法基本上都是将图像划分成多个区域,对每个区域提取出多种不同的底层视觉特征,组合后得到鲁棒性更好的特征表示形式。最常用的就是颜色直方图,多数情况下行人的衣服颜色结构简单,因此颜色表示是有效的特征,通常用RGB、HSV直方图表示。把RGB空间的图像转化成HSL和YCbCr颜色空间,观察对数颜色空间中目标像素值的分布,颜色特征在不同光照或角度等行人识别的不适环境中具有一定的不变性。以及局部特征,如局部不变特征–尺度不变特征变换(scale-invariant feature transform,SIFT),SURF和Covariance描述子ELF(ensemble of localized features)方法中,结合RGB、YCbCr、HS颜色空间的颜色直方图,具有旋转不变性的Schmid和Gabor滤波器计算纹理直方图。还有纹理特征、Haar-like Represention、局部二值模式(LBP)、Gabor滤波器、共生矩阵(Co-occurrence Matrics)。
2)中层语义属性:可以通过语义信息来判断两张图像中是否属于同一行人,比如颜色、衣服以及携带的包等信息。相同的行人在不同视频拍摄下,语义属性很少变化。有的采用15种语义来描述行人,包括鞋子、头发颜色长短、是否携带物品等,分类器用SVM定义每幅行人图像的以上语义属性。结合语义属性重要性加权以及与底层特征融合,最终描述行人图像。对图像超像素划分,最近分割算法对图像块定义多种特征属性,颜色、位置和SIFT特征,效果有提高。
3)高级视觉特征:特征的选择技术对行人再识别的识别率的性能进行提升,如Fisher向量[编码;提取颜色或纹理直方图,预先定义块或条纹形状的图像区域;或者编码区域特征描述符来建立高级视觉特征。用某种描述符对密集轨迹、纹理、直方图进行编码,突出重要信息。受到多视角行为识别研究和Fisher向量编码的影响,一种捕获软矩阵的方法,即DynFV(dynamic fisher vector)特征和捕获步态和移动轨迹的Fisher向量编码的密集短轨迹时间金字塔特征被提出。Fisher向量编码方法是首先用来解决大尺度图像分类的方法,也能改善行为识别的性能。有的对行人的每个图像分成6个水平条带,在每个条带上计算纹理和颜色直方图。在YCbCr、HSV、白化的RGB颜色空间计算直方图建立颜色描述符,并用local fisher disrciminant analysis(LFDA)降维。学习出的矩阵把特征转换到新的空间,LFDA能在嵌入过程中使特征的局部结构适用于图像遮挡,背景变化和光照变化的情况,最后把计算变换空间中的特征向量的均值作为这个行人最终的特征向量表示。T. Matsukawa提出GOG(Gaussian Of Gaussian),把一幅图像分成水平条带和局部块,每个条带用一个高斯分布建模。每个条带看作一系列这样的高斯分布,然后用一个单一的高斯分布总体表示。GOG特征提取的方法好表现在用像素级特征的一个局部高斯分布来描述全局颜色和纹理分布,并且GOG是局部颜色和纹理结构的分层模型,可以从一个人的衣服的某些部分得到。此外,深度学习也被应用于行人重识别的特征提取中,在AlexNet-Finetune中,开始在ImageNet数据集上预训练的基于AlexNet结构的CNN,并用这个数据集对数据进行微调。在微调过程中,不修改卷积层的权重,训练后两个全连接层。McLaughlin等采用了类似的方法,对图像提取颜色和光流特征,采用卷积神经网络(CNN)处理得到高层表征,然后用循环神经网络(RNN)捕捉时间信息,然后池化得到序列特征。T对来自各个领域的数据训练出同一个卷积神经网络(CNN),有些神经元学习各个领域共享的表征,而其他的神经元对特定的某个区域有效,得到鲁棒的CNN特征表示。
4. 基于度量学习的方法
基于度量学习的方法旨在通过网络学习出两张图片的相似度,关键在于设计合理的度量方法或者损失函数,从而使得在模态一致的情况下,属于同一个体的样本图像距离尽可能小,不属于同一个体的样本图像距离尽可能大;而不属于同一模态也不属于同一个体的样本图像距离尽可能大。
5. 基于生成跨模态图像的方法
随着近年来 GAN 的快速发展,实现模态的相互转换,将跨模态行人重识别问题转化为单模态的行人重识别问题,这在很大程度上减少了模态间的差异这一难点。为了实现两者的相互转换,Wang 等人提出了一种双层差异减少 方法(Dual- level Discrepancy Reduction Learning,D2RL) 文章地址 ,分为两个部分,先使用变分自编码器消除模态之间的差异,再使用传统的行人重识别方法约束外表特征差异。Wang 等人一种用于跨模态行人重识别任务的端到端对齐生成对抗网络。像素对齐模块将 RGB 图像转化为红外图像;特征对齐模块把真实的红外图像和合成的红外图像映射到同一个特征空间,并使用基于身份标签的分类和三元组损失来监督特征;联合判别模块负责判别真假红外图像,通过身份一致性特性使得前两者互相学习从而得到鲁棒性特征。
网络结构如下:
评价标准
目前研究主要集中用于两个评估指标:
(1) CMC曲线
CMC曲线全称是Cumulative Match Characteristic (CMC) Curve,即累计匹配曲线, 是行人重识别重要的评测指标,它可以综合反映分类器的性能。具体来说,在候选行人库(gallery)中检索待查询(probe)的行人,前k个检索结果中包含正确匹配结果的比率,通常用Rank-k的形式表示。Rank-1识别率就是表示按照某种相似度匹配规则匹配后,第一次就能返回正确匹配的概率,即最匹配候选目标刚好为待查询图片目标的概率,Rank-5识别率就是指前5个匹配候选目标中存在待查询图片目标的概率,Rank-10识别率就是指前10个匹配候选目标中存在待查询图片目标的概率。随着匹配候选目标的增加,概率也会相应增加。
(2) mAP均值平均精度
目前大部分的研究都是跨多个摄像头,而CMC曲线只适用于两个摄像头之间的检索,因此Zheng等人提出了均值平均精度(mean Average Precision, mAP)对算法进行评估。mAP的具体操作是,分别求出每个类别的AP值后取平均值。AP值是求PR曲线下的面积,综合考虑了P(准确率)和R(召回率),是衡量一个模型好坏的标准。准确率表示预测为正的样本中含有真正正样本的比例,召回率表示真正正样本中正确预测的比例。通过计算precision-recall曲线的线下面积,即可得平均精度值AP,AP值越大,模型精度越高,性能越好。
未来发展方向
1. 自然语言检索
通过人为的提出一段文字,检索出图库中的符合身份信息的图像,并给出匹配概率。
2. 利用生成数据 辅助训练
总结
跨模态行人重识别是行人重识别的一个新的发展趋势,对智能化社会有着重要的研究意义和应用价值,未来的发展方向可以从以下方面考虑。
(1) 构建高质量的数据集。现有跨模态行人重识别的数据集数量少, 可供训练的图片非常有限,影响跨模态行人匹配的效果。同时目前数据集的场景不够丰富,但是现实会遇到多样的环境,不同的环境,不同的光线等因素都会影响跨模态图像之间的匹配,造成很大的差异。
(2) 关注模态转换的研究。采用模态转换的方法,识别率明显优于传统的方法,例如其中GAN、风格迁移等方法可以有效地实现两个不同模态之间的转换,有效缓解模态间的差异。
(3) 结合局部特征学习。在行人重识别中颜色是区别行人的有效信息,由于红外图像特殊性,无法在跨模态行人重识别中使用。因此,其他的信息变得异常关键,我们可以结合局部特征,学习出具有鲁棒性特征,从而提高行人识别率。
(4) 尺度处理问题。尺度变化是行人检测面临的另一个严峻挑战。由于行人距离摄像机的远近不同,在同一图像中往往呈现尺度差异较大的行人目标。一方面,小尺度目标轮廓模糊、有用信息较少,检测器难以精准检测。另一方面,大尺度目标与小尺度目标特征差异较大,难以针对不同尺度的目标设计统一的特征处理策略。
版权归原作者 JJxiao24 所有, 如有侵权,请联系我们删除。