
👨🎓 博主介绍:大家好,我是可可卷,一个NLP领域的小小白~
📕 文章介绍:命名实体识别,即Named Entity Recognition(NER),在比如QA,text summarization,machine translation等多项任务中均有涉及。今天我们将研究顶会文章Chinese NER using Lattice LSTM中的数据集,并尝试自己手写模型,领会stoa方案的魅力!
🎉欢迎关注💗点赞👍收藏⭐️评论📝
🙏作者水平很有限,欢迎各位大佬指点,一起学习进步!
文章目录
1 数据集介绍
1.1 数据集来源
本次算法实验数据集用的是NLP顶会论文ACL 2018Chinese NER using Lattice LSTM中收集的简历数据。
1.2 数据集格式
目前,常用的序列标注方式有BIO和BIOES,其中BIO方式主要将实体X标注为B-X,I-X,O的格式,B-表示实体的起始位置,I-表示实体的中间或结尾,O-表示不属于实体;而BIOES近似于BIO的改进,主要将多元实体X标注为B-X,I-X,E-X的格式,B-表示实体的起始位置,I-表示实体的中间或结尾;一元实体则标记为S-X,;O-X表示X不属于实体。
本数据集采用BMEOS标注法,其中B-表示实体的起始位置,M-表示实体的中间,E表示实体的结尾;一元实体则标记为S-;O-表示不属于实体。
# 数据集示例如下
高 B-NAME
勇 E-NAME
: O
男 O
, O
中 B-CONT
国 M-CONT
国 M-CONT
籍 E-CONT
, O
无 O
境 O
外 O
居 O
留 O
权 O
, O
1 O
9 O
6 O
6 O
年 O
出 O
生 O
, O
汉 B-RACE
族 E-RACE
, O
中 B-TITLE
共 M-TITLE
党 M-TITLE
员 E-TITLE
, O
本 B-EDU
科 M-EDU
学 M-EDU
历 E-EDU
, O
工 B-TITLE
程 M-TITLE
师 E-TITLE
、 O
美 B-ORG
国 M-ORG
项 M-ORG
目 M-ORG
管 M-ORG
理 M-ORG
协 M-ORG
会 E-ORG
注 B-TITLE
册 M-TITLE
会 M-TITLE
员 E-TITLE
( O
P B-TITLE
M M-TITLE
I M-TITLE
M M-TITLE
e M-TITLE
m M-TITLE
b M-TITLE
e M-TITLE
r E-TITLE
) O
、 O
注 B-TITLE
册 M-TITLE
项 M-TITLE
目 M-TITLE
管 M-TITLE
理 M-TITLE
专 M-TITLE
家 E-TITLE
( O
P B-TITLE
M M-TITLE
P E-TITLE
) O
、 O
项 B-TITLE
目 M-TITLE
经 M-TITLE
理 E-TITLE
。 O
该数据集的所有类别如下:
{'B-CONT', 'E-PRO', 'M-CONT', 'S-NAME', 'E-CONT', 'B-PRO', 'M-LOC', 'E-FOOD', 'E-TITLE', 'M-ORG', 'B-ORG', 'M-TITLE', 'B-TITLE', 'B-RACE', 'B-EDU', 'B-FOOD', 'M-EDU', 'M-NAME', 'S-RACE', 'E-LOC', 'E-RACE', 'S-ORG', 'M-PRO', 'M-FOOD', 'E-NAME', 'E-EDU', 'B-LOC', 'E-ORG', 'B-NAME', 'M-RACE', 'O'}
1.3 数据集分析
1.3.1 文本长度分布
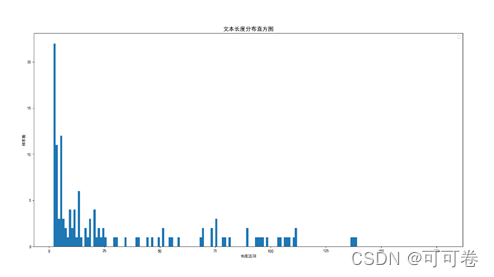
由上图可以发现,简历数据集以短句居多,有一定比例中长句,长句较少,因此在后序训练时可以更加注重短句的上下文关系。
1.3.2 数据集划分
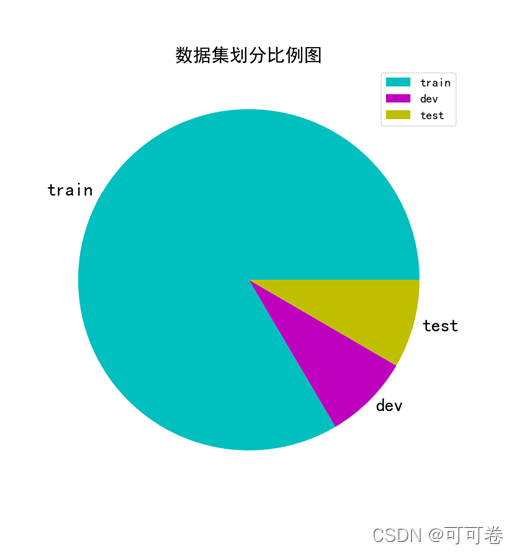
依据10:1:1的比例将数据集划分成训练集、验证集、测试集。
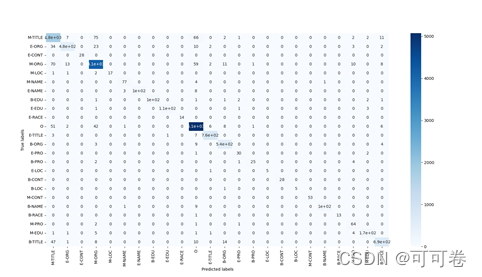
1.3.3 不同标签样本数
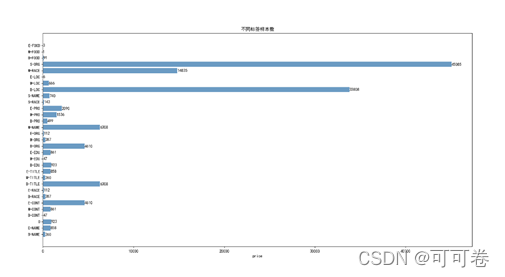
分析上图,发现标签分布不平衡,其中S-ORG,B-LOC的比例较高,而其他标签的比例较低,有一定训练难度。
1.3.4 数据集句长
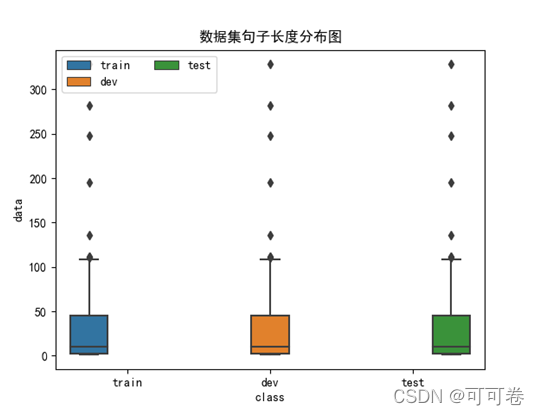
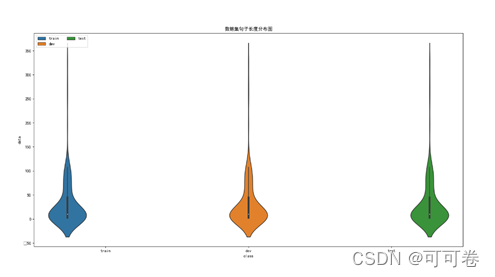
通过箱线图与小提琴图,我们可以清晰地发现,训练集、验证集、测试集的数据集句长分布保存一致。
2 统计学习算法
2.1 Hidden Markov Model
2.1.1 算法原理
隐马尔可夫模型描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐马尔可夫模型由初始状态分布,状态转移概率矩阵以及观测概率矩阵所确定。
命名实体识别本质上可以看成是一种序列标注问题,在使用HMM解决命名实体识别这种序列标注问题的时候,我们所能观测到的是字组成的序列(观测序列),观测不到的是每个字对应的标注(状态序列)。
2.1.2 程序代码
import torch
classHMM(object):def__init__(self, N, M):
self.N = N # N: 状态数,这里对应存在的标注的种类
self.M = M # M: 观测数,这里对应有多少不同的字# 状态转移概率矩阵
self.A = torch.zeros(N, N)# 观测概率矩阵
self.B = torch.zeros(N, M)# 初始状态概率
self.Pi = torch.zeros(N)deftrain(self, word_lists, tag_lists, word2id, tag2id):# word2id: 将字映射为ID; tag2id: 将标注映射为ID# 使用极大似然估计的方法来估计隐马尔可夫模型的参数# 估计转移概率矩阵for tag_list in tag_lists:
seq_len =len(tag_list)for i inrange(seq_len -1):
current_tagid = tag2id[tag_list[i]]
next_tagid = tag2id[tag_list[i+1]]
self.A[current_tagid][next_tagid]+=1
self.A[self.A ==0.]=1e-10# 将未出现元素设置一个小数
self.A = self.A / self.A.sum(dim=1, keepdim=True)# 估计观测概率矩阵for tag_list, word_list inzip(tag_lists, word_lists):assertlen(tag_list)==len(word_list)for tag, word inzip(tag_list, word_list):
tag_id = tag2id[tag]
word_id = word2id[word]
self.B[tag_id][word_id]+=1
self.B[self.B ==0.]=1e-10
self.B = self.B / self.B.sum(dim=1, keepdim=True)# 估计初始状态概率for tag_list in tag_lists:
init_tagid = tag2id[tag_list[0]]
self.Pi[init_tagid]+=1
self.Pi[self.Pi ==0.]=1e-10
self.Pi = self.Pi / self.Pi.sum()deftest(self, word_lists, word2id, tag2id):
pred_tag_lists =[]for word_list in word_lists:
pred_tag_list = self.decoding(word_list, word2id, tag2id)
pred_tag_lists.append(pred_tag_list)return pred_tag_lists
defdecoding(self, word_list, word2id, tag2id):"""
使用维特比算法,其本质是用动态规划解隐马尔可夫模型预测问题(求概率最大路径)
"""# 对数化防止下溢
A = torch.log(self.A)
B = torch.log(self.B)
Pi = torch.log(self.Pi)# 初始化维比特矩阵viterbi
seq_len =len(word_list)
viterbi = torch.zeros(self.N, seq_len)# backpointer[i,j]: 标注序列的第j个标注为i时,第j-1个标注的id
backpointer = torch.zeros(self.N, seq_len).long()
start_wordid = word2id.get(word_list[0],None)
Bt = B.t()if start_wordid isNone:
bt = torch.log(torch.ones(self.N)/ self.N)# 如果字不再字典里,则假设状态的概率分布是均匀的else:
bt = Bt[start_wordid]# 否则从观测概率矩阵中取bt
viterbi[:,0]= Pi + bt
backpointer[:,0]=-1# 递推公式:viterbi[tag_id, step] = max(viterbi[:, step-1]* self.A.t()[tag_id] * Bt[word])for step inrange(1, seq_len):
wordid = word2id.get(word_list[step],None)if wordid isNone:
bt = torch.log(torch.ones(self.N)/ self.N)else:
bt = Bt[wordid]for tag_id inrange(len(tag2id)):
max_prob, max_id = torch.max(
viterbi[:, step-1]+ A[:, tag_id],
dim=0)
viterbi[tag_id, step]= max_prob + bt[tag_id]
backpointer[tag_id, step]= max_id
# 最优路径的概率
best_path_prob, best_path_pointer = torch.max(
viterbi[:, seq_len-1], dim=0)# 求最优路径
best_path_pointer = best_path_pointer.item()
best_path =[best_path_pointer]for back_step inrange(seq_len-1,0,-1):
best_path_pointer = backpointer[best_path_pointer, back_step]
best_path_pointer = best_path_pointer.item()
best_path.append(best_path_pointer)# 将序列tag_id转化为tag
id2tag =dict((id_, tag)for tag, id_ in tag2id.items())
tag_list =[id2tag[id_]for id_ inreversed(best_path)]return tag_list
2.1.3 运行结果
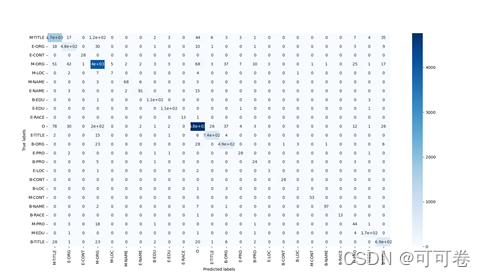
2.2 Conditional Random Field
2.2.1 算法原理
条件随机场(CRF)是NER目前的主流模型,它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。CRF为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息,有效克服了HMM模型面临的问题。
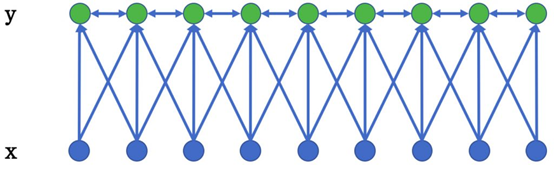
(图2.2 线性链条件随机场)
2.2.2 程序代码
from sklearn_crfsuite import CRF
# 抽取单个字的特征defword2features(sent, i):
word = sent[i]
prev_word ="<s>"if i ==0else sent[i-1]
next_word ="</s>"if i ==(len(sent)-1)else sent[i+1]
features ={'w': word,# 当前词'w-1': prev_word,# 前一个词'w+1': next_word,# 后一个词'w-1:w': prev_word+word,# 前一个词+当前词'w:w+1': word+next_word,# 当前词+后一个词'bias':1}return features
# 抽取序列特征defsent2features(sent):return[word2features(sent, i)for i inrange(len(sent))]classCRFModel(object):def__init__(self,
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False):
self.model = CRF(algorithm=algorithm,
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=all_possible_transitions)deftrain(self, sentences, tag_lists):
features =[sent2features(s)for s in sentences]
self.model.fit(features, tag_lists)deftest(self, sentences):
features =[sent2features(s)for s in sentences]
pred_tag_lists = self.model.predict(features)return pred_tag_lists
2.2.3 运行结果
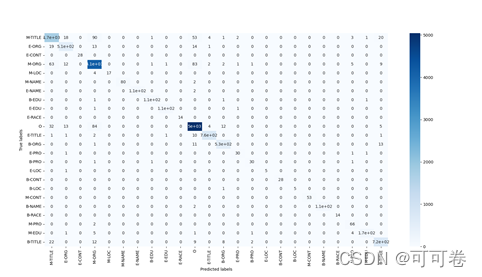
3 深度学习算法
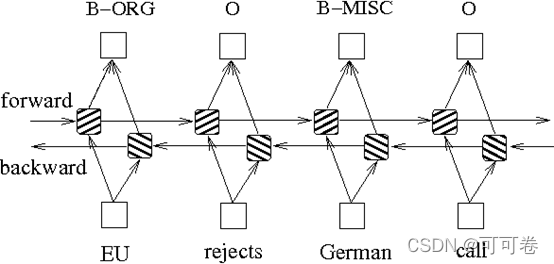
3.1 Bi-LSTM
3.1.1 算法原理
通过依靠神经网络超强的非线性拟合能力,LSTM在训练时将样本通过高维空间中的复杂非线性变换,学习到从样本到标注的函数,之后使用这个函数为指定的样本预测每个token的标注。
而双向长短期有着比普通LSTM更好的捕捉序列之间的依赖关系的能力,能更好地用于捕捉上下文关系。
3.1.2 程序代码
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
from torchinfo import summary
import pickle
classBiLSTM(nn.Module):def__init__(self, vocab_size, emb_size, hidden_size, out_size):super(BiLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.bilstm = nn.LSTM(emb_size, hidden_size,
batch_first=True,
bidirectional=True)
self.lin = nn.Linear(2*hidden_size, out_size)defforward(self, sents_tensor, lengths):
emb = self.embedding(sents_tensor)
packed = pack_padded_sequence(emb, lengths, batch_first=True)
rnn_out, _ = self.bilstm(packed)
rnn_out, _ = pad_packed_sequence(rnn_out, batch_first=True)
scores = self.lin(rnn_out)return scores
3.1.3 运行结果
3.2 Bi-LSTM+CRF
3.2.1 算法原理
Bi-LSTM:
- 优点是能够根据目标(比如识别实体)自动提取观测序列的特征
- 缺点是无法学习到状态序列(输出的标注)之间的关系(比如B类标注后面不会再接一个B类标注,而通常接M类标注或E类标注)
CRF:
- 优点就是能对隐含状态建模,学习状态序列的特点
- 缺点是需要手动提取序列特征
Bi-LSTM+CRF:在Bi-LSTM后面再加一层CRF,以获得两者的优点
3.2.2 程序代码
from itertools import zip_longest
from copy import deepcopy
import torch
import torch.nn as nn
import torch.optim as optim
classBiLSTM_CRF(nn.Module):def__init__(self, vocab_size, emb_size, hidden_size, out_size):super(BiLSTM_CRF, self).__init__()
self.bilstm = BiLSTM(vocab_size, emb_size, hidden_size, out_size)# 转移矩阵,初始化为均匀分布
self.transition = nn.Parameter(torch.ones(out_size, out_size)*1/out_size)defforward(self, sents_tensor, lengths):
emission = self.bilstm(sents_tensor, lengths)# 计算CRF scores
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(2).expand(-1,-1, out_size,-1)+ self.transition.unsqueeze(0)return crf_scores
defdecode(self, test_sents_tensor, lengths, tag2id):
start_id = tag2id['<start>']
end_id = tag2id['<end>']
pad = tag2id['<pad>']
tagset_size =len(tag2id)
crf_scores = self.forward(test_sents_tensor, lengths)
device = crf_scores.device
B, L, T, _ = crf_scores.size()# 使用维特比算法进行解码
tagids = viterbi(B, L, T, device)return tagids
3.2.3 运行结果
3.3 Bert+BiLSTM+CRF
3.3.1 算法原理
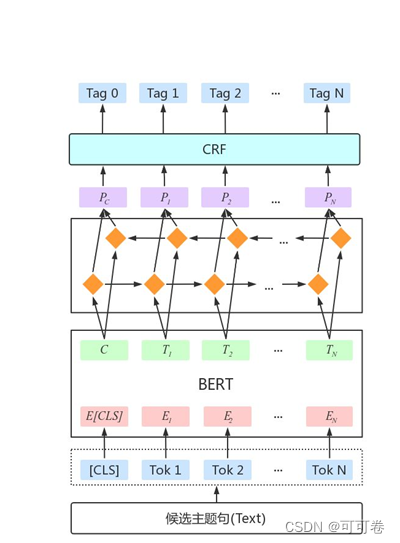
BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法。
因此,通常可以采用Bert+BiLSTM+CRF的模型结构,以期获取更高的预测精度。
3.3.2 训练模型
了解到kashgari是一个简单而强大的NLP框架,其内包括cnnmodel、blstm模型、cnnlstm模型、avcnnmodel、KMaxnn模型、RCNN模型等序列(文本)分类模型以及cnnlstm模型、blstm模型、BLSTMCRFModel等序列(文本)标签模型,同时提供GPU支持/多GPU支持,因此选择了kashgari库进行Bert模型的预训练以及微调
from kashgari.tasks.labeling import BiLSTM_CRF_Model
import kashgari
from kashgari.embeddings.bert_embedding import BertEmbedding
import warnings
warnings.filterwarnings('ignore')
bert_embed = BertEmbedding(r'\\chinese_L-12_H-768_A-12',
sequence_length=100)
model = BiLSTM_CRF_Model(bert_embed)
model.fit(train_x,
train_y,
x_validate=valid_x,
y_validate=valid_y,
epochs=5,
batch_size=512)
model.save('ner.h5')
model.evaluate(test_x, test_y)
3.3.3 训练结果
由于模型训练时间过长(一个epoch需要400s),难以有效地进行fine tune,因此模型的效果并不十分理想。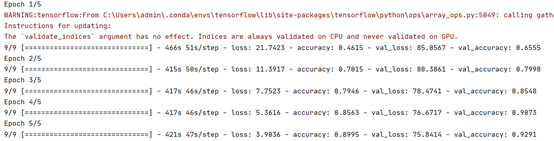
下面是模型训练5个epoch的结果,可以发现,模型的精度一直在提高,并没有达到收敛,这说明模型的潜力值得进一步挖掘。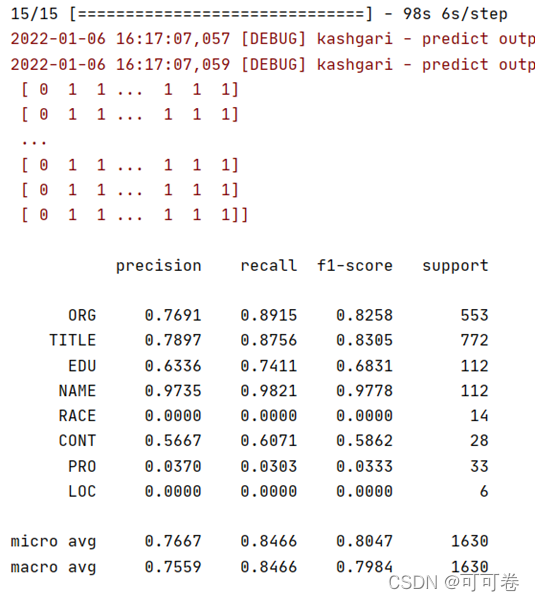
3.3.4 模型结构

4 模型融合
4.1 融合策略
考虑到Bert+BiLSTM+CRF结构由于机器的原因,远未发挥应有的效果,因此只将前4个模型进行融合。
融合策略为:voting
4.2 程序代码
defflatten_lists(lists):
flatten_list =[]for l in lists:iftype(l)==list:
flatten_list += l
else:
flatten_list.append(l)return flatten_list
# 模型融合defensemble_evaluate(results, targets):for i inrange(len(results)):
results[i]= flatten_lists(results[i])# voting
pred_tags =[]for result inzip(*results):
ensemble_tag = Counter(result).most_common(1)[0][0]
pred_tags.append(ensemble_tag)
targets = flatten_lists(targets)return targets
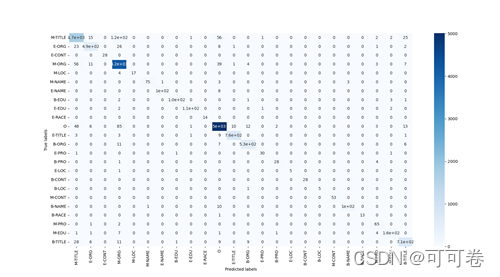
##4.3 融合结果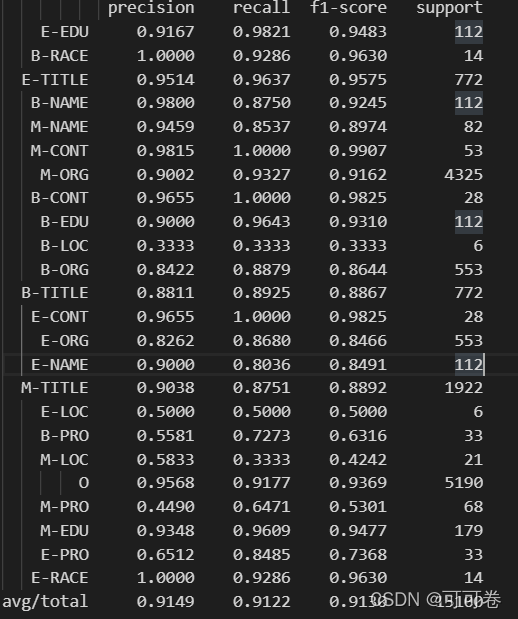
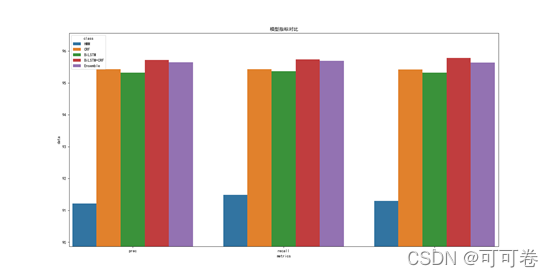
由模型精度比较图可以发现,HMM的预测精度最低,BiLSTM次低,CRF表现中等,Essemble表现次好,BiLSTM表现最好。
5 总结
- HMM认为每个字是独立的,并且标注 t a g i tag_i tagi只与上一个标注 t a g i − 1 tag_{i-1} tagi−1有关,这个假设是非常局限的,因此也导致了HMM 的预测精度不够理想。
- CRF克服了HMM的上述缺点,通过手动提取特征的方式,关注了每个字的上下文关系,因此预测精度有了一定的上升。
- 通过软投票的方式,我们在Essemble过程中对前4个模型进行了融合,我们发现Essemble的预测精度略低于BiLSTM+CRF,这可以认为是其他模型拖累了整体的精度
版权归原作者 可可卷 所有, 如有侵权,请联系我们删除。