
目录
1、RFM模型介绍
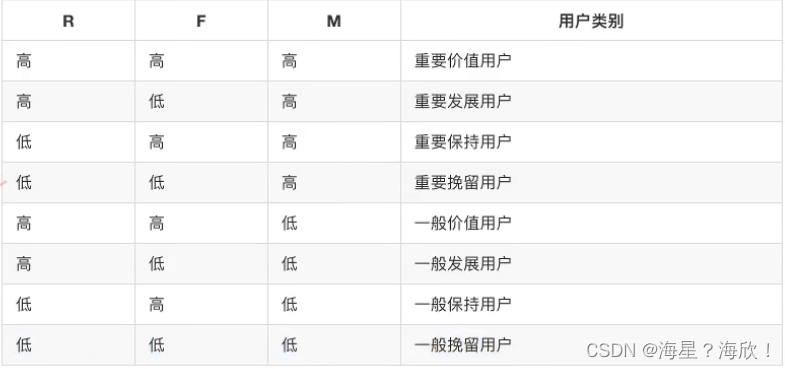
RFM客户价值模型详细介绍
- R最近一次购买时间R(recenty)
- 购买频率F(frequency)
- 购买金额M(monetary) 通过这三个维度来评估客户的订单活跃价值,用来做客户分群或价值区分
 RFM模型基于一个固定的时间点做的分析 RFM模型的实习过程:
RFM模型基于一个固定的时间点做的分析 RFM模型的实习过程: - 设置做计算的截止时间点
- 以时间点为截止时间节点,向前推固定周期
- 数据预计算,初始RFM:(最近的订单时间R,订单数量F,订单总金额M)
- R,F,M区间分组。(F,M越大越好,R越小越好),得到一个分数值
- 将三个维度值,组合或者相加得到总的RFM分 R,M,F分别为2,3,1 则拼接RFM= 231 求和RFM=6
2、Excel实际RFM划分案例


RFM划分过程:
1)提取用户最近一次的交易时间,算出距离计算时间的差值
当前时间=TODAY()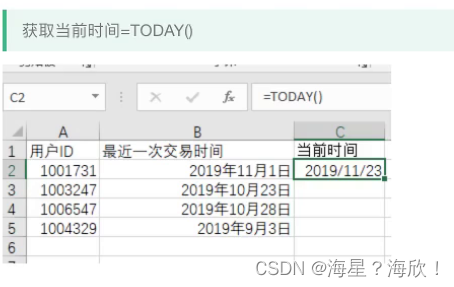
2)计算最近一次交易时间距当前时间的间隔
时间间隔 = Days(后时间,前时间)
3)根据间隔天数长度赋予对应的R值
if(条件,满足条件师输出内容,不满足时输出内容)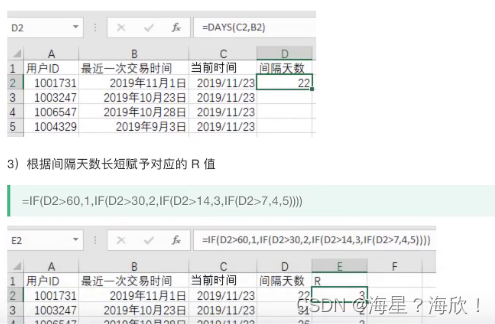
4)从历史数据中提取所有用户的购买次数,根据次数多少赋予对应的F值
5)从历史数据中汇总,求得该用户的交易总额,根据金额大小赋予对应的M值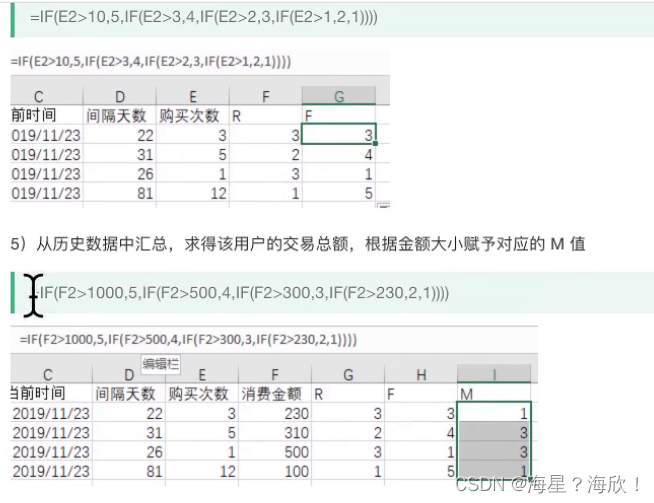
6)求出RFM的中值,例如中位数,用中值和用户的实际值进行比较,高于中值的为高,否则为低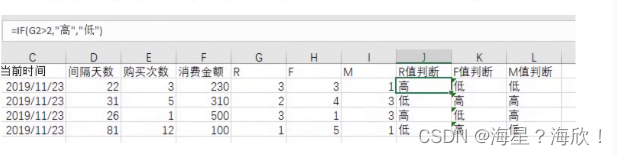
7)在得到不同会员的RFM之后,根据步骤5产生的两种结果有两种应用思路
思路1:基于3个维度值做用户群体划分和解读,对用户的价值度做分析
思路2:基于RFM的汇总得分评估价值度
基于不同群体用户做不同的策略
RFM数值可以作为一些数据挖掘的输入信息
3、RFM案例
用户价值细分是了解用户价值度的重要途经,针对交易数据分析最主要用的就是RFM模型
一般对每个维度分三个划分,最多333=27种
数据sales.xlsx。密码gi7b
数据介绍:

3.1 数据加载和基本信息查看
import pandas as pd
import numpy as np
import time
import pymysql
from pyecharts.charts import Bar3D
#忽略警告import warnings
warnings.filterwarnings('ignore')
数据是一个有五个sheet的excel表格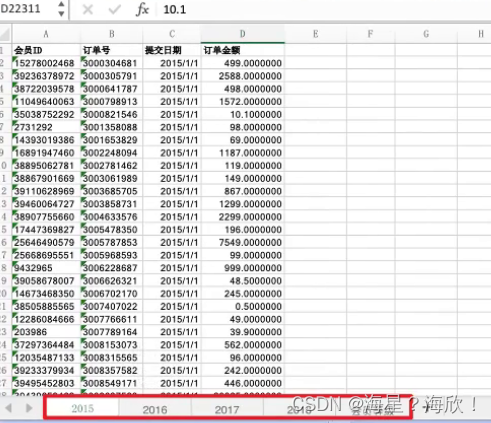
如何处理多sheet的excel表,导入python:
#加载数据#数据是一个有五个sheet的excel表格
sheet_names =['2015','2016','2017','2018','会员等级']
sheet_datas =[pd.read_excel('./data/sales.xlsx',sheet_name=i)for i in sheet_names]#每个sheet数据都读出来放在列表中#zip将两个列表的元素组合起来for each_name,each_data inzip(sheet_names,sheet_datas):print('[data summary for ========{}=======]'.format(each_name))#打印是哪个sheet,表名print('Overview:','\n',each_data.head(4))#打印前四行print('DESC:','\n',each_data.describe())#数据的描述性信息print('NA records',each_Data.isnull().any(axis=1).sum())#缺失值记录数print('Dtypes',each_data.dtypes)#数据类型
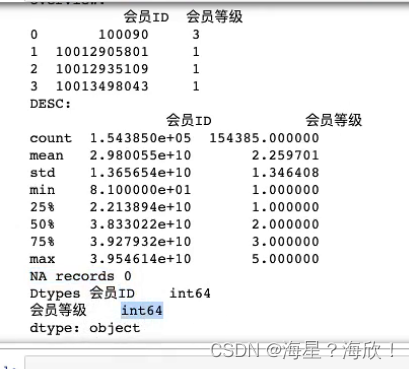
结论:日期列已经自动识别日期格式
订单金额的分布不均匀,有明显的极大值
有的表存在缺失值,但缺失量不大
等等
3.2 数据预处理和RFM的初始值计算
思路:缺失值异常值处理–添加每年的最大日期—四年数据拼接—增加间隔列和日期列—计算RFM各值
1)缺失值,异常值处理
for i,each_data inenumerate(sheet_datas[:]-1):#只要前四个表数据,会员等级那个不要#删除含有缺失值的行,这些行不多,而原数据大量--所以直接删
each_data = each_data.dropna()#删除缺失行dropna#剔除订单金额小于1的数据,这些很可能是异常的
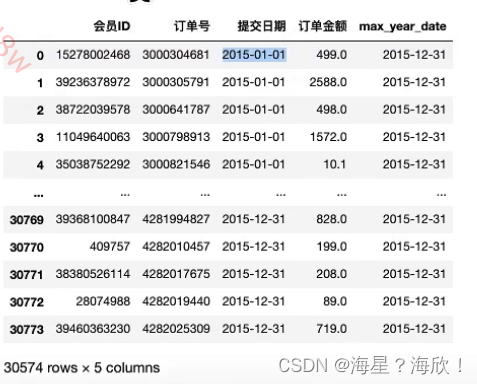
sheet_data[i]=each_data[each_data['订单金额']>1]#添加提交订单日期最大值这一列,方便后面计算时间间隔
sheet_datas[i]['max_year_data']= sheet_datas[i]['提交日期'].max()
sheet_datas[0]#先查看一下
2)数据拼接----pd.concat()
四年的数据合并一下,后面就不用再循环读取了
#将四年的数据合并一下,按行拼接
data_merge = pd.concat(sheet_datas[:-1])
data_merge
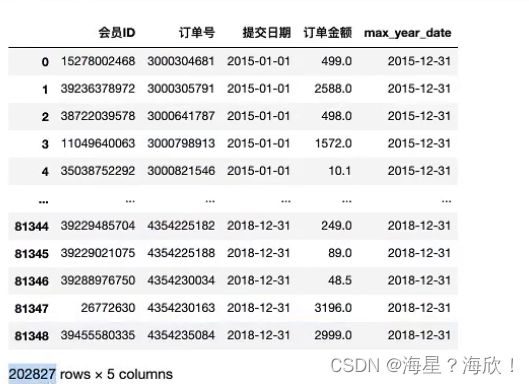
虽然把四年的数据合并在了一起,但是还是分年进行分析的
3)增加两列:
date_interval(当年中,此提交日期和最大的日期之间的差值),是当年的最后日期
year(年份)
#订单数据处理:增加两列date_interval、year
data_merge['date_interval']= data_merge['max_year_date']- date_merge['提交日期']
data_merge['year']= date_merge['提交日期'].dt.year
date_merge.head()
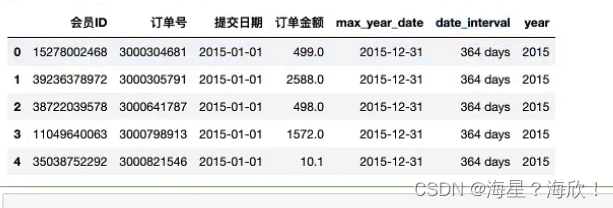
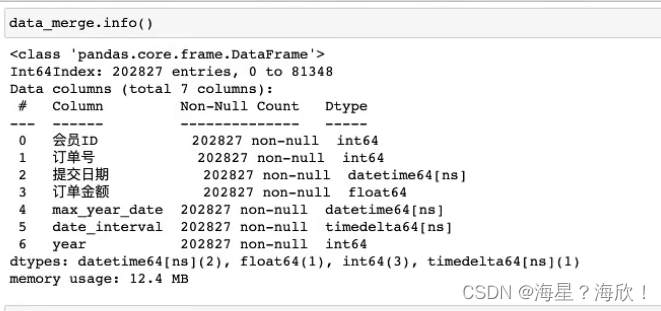
此时,date_interval类型是两日期相减后的,我们想要改成数字类型
data_merge['date_intervl']= data_merge['date_intervl'].dt.days
data_merge.info
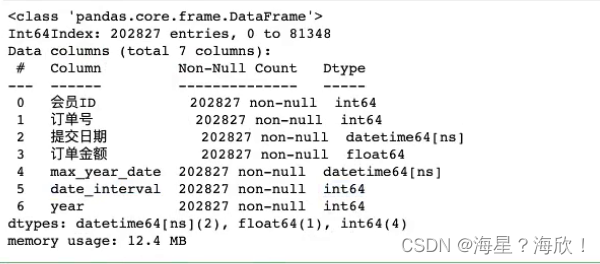
此时改好了,
4)计算RFM数据
R:date_interval列分组后计算最小值
F:频率,按照年和会员id分组后,计数
M:按照年和会员id分组后,对订单金额求和
此时的数据: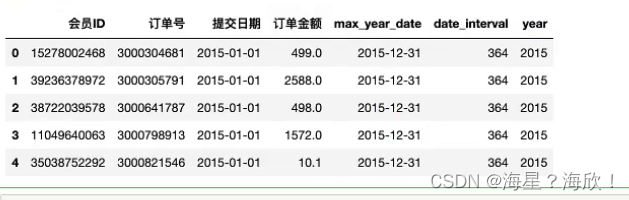
data_merge.groupby(['year','会员ID']).agg(('date_interval':'min','订单号':'count','订单金额':'sum'))
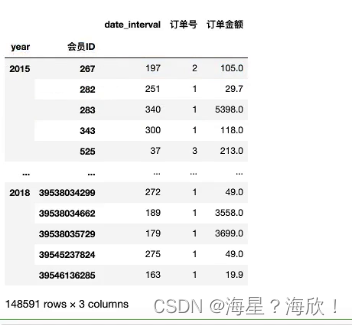
data_merge.groupby(['year','会员ID'],as_index=False).agg(('date_interval':'min','订单号':'count','订单金额':'sum'))#分组列不作为行标签:as_index=False
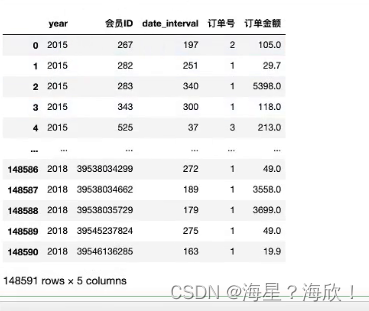
#修改列名
rfm_gb.columns =['year','会员ID','r','f','m']
rfm_gb.head()
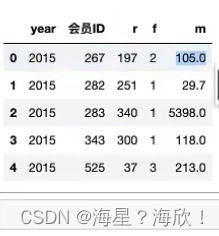
3.3 RFM区间和划分和分值计算
上面已经得到RFM具体值,但我们是需要划分区间,333个区间
如何定区间的边界值?
先看一下数值的统计值
em=fm_gb.iloc[:,2:].describe().T #T转置一下
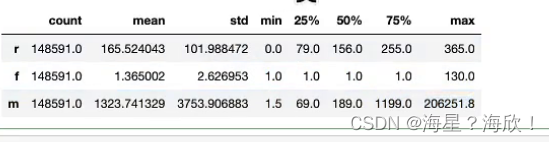
可以划定的三个区间:最小值-1/4分位数,1/4分位数-3/4分位数,3/4分位数-最大值
和业务部门沟通确定,结合业务确定
#定义区间边界
r_bins =[-1,79,255,365]#左开右闭,所以边界小于最小值
f_bins =[0,2,5,130]
m_bins =[0,69,1199,206252]
下面用pd.cut进行分割
pd.cut(rfm_gb['r'],bins=r_bins)
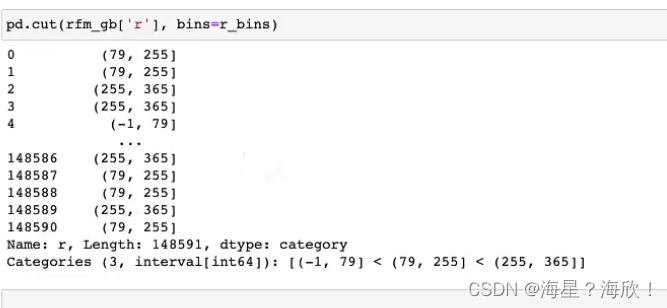
进行了区间分割,并且打了分数:
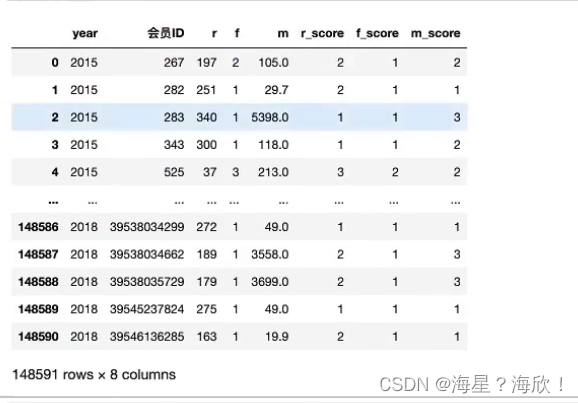
rfm_gb['r_score']= pd.cut(rfm_gb['r'],bins=r_bins,labels=[3,2,1])#给三个区间给定分数,1,2,3
rfm_gb['f_score']= pd.cut(rfm_gb['f'],bins=f_bins,labels=[1,2,3])
rfm_gb['m_score']= pd.cut(rfm_gb['m'],bins=m_bins,labels=[1,2,3])
rfm_gb
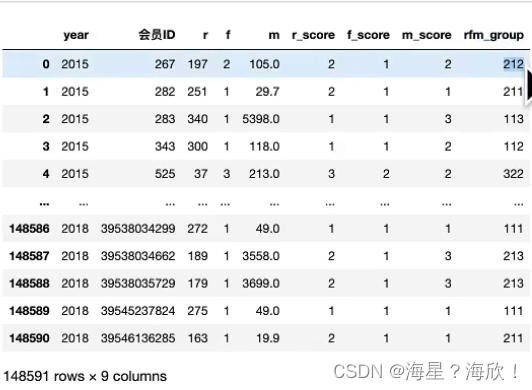
将RFM的值进行拼接
先将默认类型int,转化成str类型:
rfm_gb['r_score']= rfm_gb['r_score'].astype(np.str)
rfm_gb['f_score']= rfm_gb['f_score'].astype(np.str)
rfm_gb['m_score']= rfm_gb['m_score'].astype(np.str)
rfm_gb.info()
进行拼接:输出212这种,增加一列
str.cat()
rfm_gb['rfm_group']= rfm_gb['r_score'].str.cat(rfm_gb['f_score']).str.cat(rfm_gb['m_score'])
rfm_gb
有了上述数据,需要进行保存
3.4 RFM计算结果保存
3.4.1 保存到excel
to_excel
#保存到excel
rfm_gb.to_excel('./data/sales_rfm.xlsx')
3.4.2 保存到数据库
2.1 创建sale_rfm_score数据表
配置参数信息:
建表操作: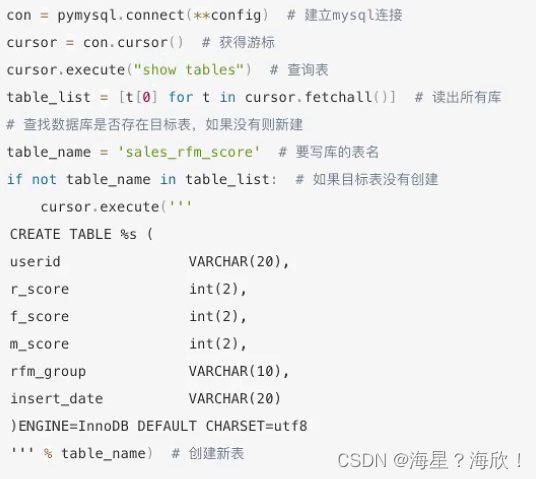
2.2 写入数据到sales_rfm_score数据表
3.5 RFM计算结果可视化
未来更好地了解各组RFM人数的变化,绘制3D柱形图
三个维度:年份、、
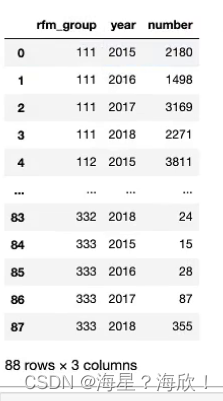
#汇总结果:统计不同不同年份的不同rfm分值的会员数量
display_data = rfm_gb.groupby(['rfm_group','year'],as_index=False)['会员ID'].count()
display_data['rfm_group']=['rfm_group','year','number']
display_data['rfm_group'].astype(np.int32)#转化类型成int32
display_data.head()
数据拿到后,准备绘图:
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
range_color =['#313695','#4575b4','#74add1','#abd9e9','#e0f3f8','#ffffbf','#fee090','#fdae61','#f46d43','#d73027','#a50026']
range_max =int(display_data['number'].max())# 绘制 3D 图形
bar = Bar3D().add(
series_name='',
data=[d.tolist()for d in display_data.values],
xaxis3d_opts=opts.Axis3DOpts(type_='category', name='分组名称'),
yaxis3d_opts=opts.Axis3DOpts(type_='category', name='年份'),
zaxis3d_opts=opts.Axis3DOpts(type_='value', name='会员数量')).set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=range_max, range_color=range_color),
title_opts=opts.TitleOpts(title="RFM分组结果"))#xaxis3d_opts是对x轴,visualmap_opts缩放条,图片也可以旋转
bar.render_notebook()
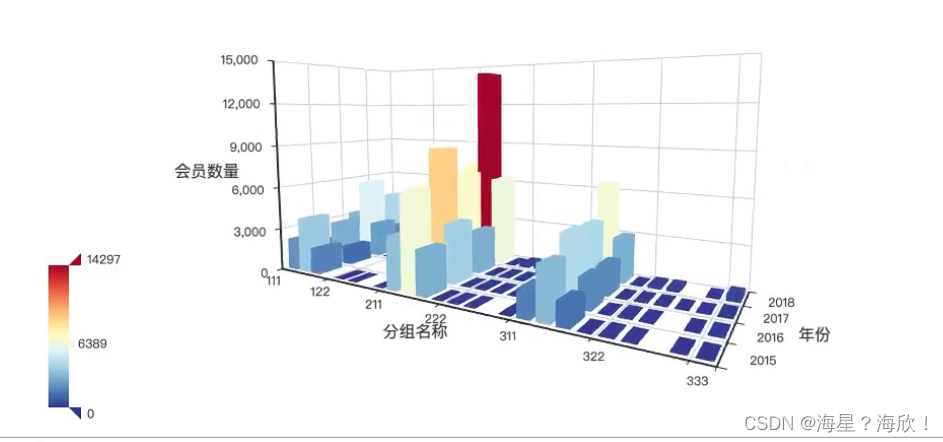
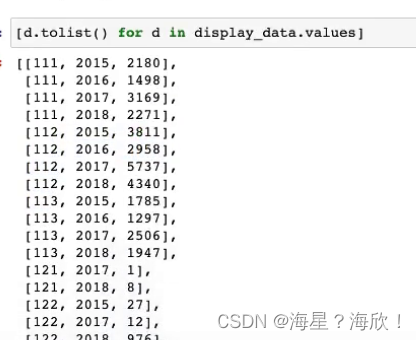
理解上面的作图代码:
[d.tolist()for d in display_data.values]#将display_data中数值遍历,后放在list列表中
3.6 结果分析(营销建议)
根据上面的图,能发现2018年212群体的数量最多。
从2016到2017年用户群体数量变化不大,但到了2018年增长了近一倍,作为重点分析人群
除212外,312,213,211及112人群都在各个年份占据很大数量
有很大分组人数很少,甚至没有
根据用户的量级可以分成两类:
第一类:用户群体占比超过10%的群体
第二类:占比在个位数的群体(1%-10%)
第三类:占比非常少,但却非常重要的群体
企业可以针对3类群体,按照公司实际运营需求,制定针对不同群体的策略
录入数据库或者保存下来的数据,可以应用到其他模型当中去,成为模型输入的关键维度特征
3.7 案例注意点
1,不同品类、行业对于RFM的依赖度是有差异的,甚至不同阶段也有影响
例如:
大型家电消费周期长的企业,R和M更重要
快消等短而快的,更看重R和F
2,RFM的区间划分,需要结合业务情况
4、总结
- RFM模型是经典的一种用户分群方法,如果数据量不大,可以直接用excel实现
- RFM并非适用所有行业,多用于复购率较高的行业
版权归原作者 海星?海欣! 所有, 如有侵权,请联系我们删除。