

今天我想谈谈神经类型的转移和卷积神经网络。已有相当多的文章和教程可供使用。有时内容只是复制,有些则提供了一种新颖的实现。它们的共同之处在于对细节的快速钻研。在我看来太具体了。不仅如此,通常还有一些实现细节,这使得将重点放在整体的主要概念上变得更加困难。
这篇文章可以看作是对其他文章的概述和理解,以便在更高的层次上理解这个概念。我的意图是去掉一些实现细节,使其足够高,足以满足初学者的需要,并激发他们阅读原始研究论文和后续实现的好奇心。
基于神经网络的风格迁移
这个方法来自于论文《A Neural Algorithm of Artistic Style 》https://arxiv.org/pdf/1508.06576.pdf
在美术领域,特别是绘画领域,人们已经掌握了通过构图内容和图像风格之间复杂的相互作用来创造独特视觉体验的技能。到目前为止,这一过程的算法基础是未知的,也不存在具有类似能力的人工系统。然而,在CV的其他关键领域,如物体识别和人脸识别,最近通过一类被称为深度神经网络的启发视觉模型,证明了接近人类的表现。在此,我们介绍了一个基于深度神经网络的人工系统,它可以创建具有高感知质量的艺术图像。
该系统使用神经表示来分离和重组任意图像的内容和风格,为艺术图像的创建提供了一种神经算法。此外,考虑到性能优化的人工神经网络与生物视觉之间惊人的相似性,我们的工作为理解人类如何创造和感知艺术图像的算法提供了一条道路。
架构和流程概述
关于CNN是如何处理神经类型转换的,有很多很好的可视化方法。我想自己画,但后来我意识到已经有很好的画板了。我将展示这些别人已经画好的图示
下面这些我认为是非常棒的。
首先这一个。它完美地展示了损失是如何计算的,以及它是如何与整体结果相匹配的。
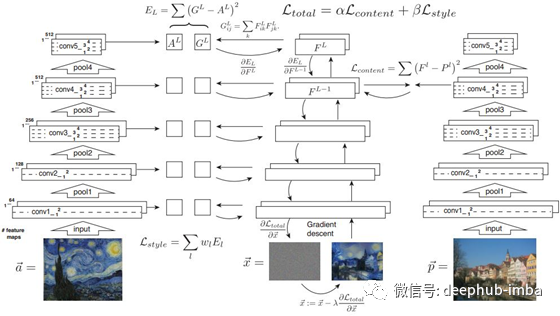
来自mike gaos blog(https://www.mikegao.net/graphics/summary/neural_style.html)
这个也不错。在不同的层上显示重建过程。
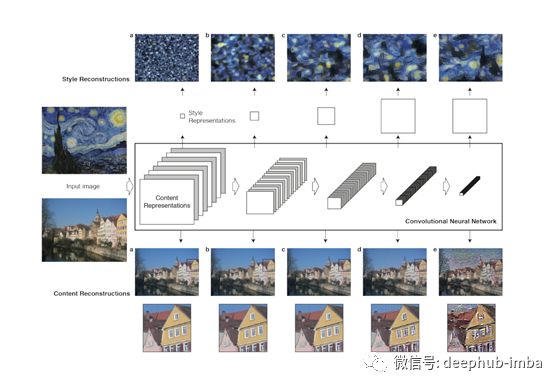
该图来自原论文
为了理解后面的计算,有必要说明CNN的不同层代表什么。
CNN的浅层倾向于检测低层次的特征,如边缘和简单的纹理。更深层次的层倾向于检测更高层次的特性,比如更复杂的纹理和对象类。
因为生成的图像应具有与输入图像相似的内容。建议在中间使用一层,以较高程度表示内容。
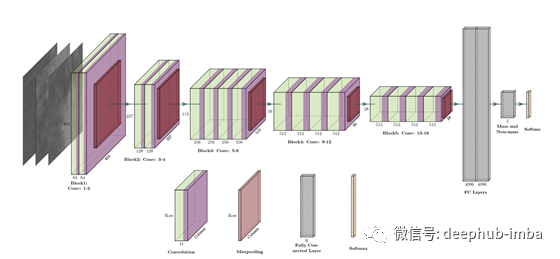
例VGG-19架构
迁移学习和风格迁移
另一个重要的概念是使用预先训练好的网络。上面所展示的VGG-19。值得注意的是,我们使用了所谓的“迁移学习”。
这里我们有两个概念来区分:
迁移学习
风格迁移
尽管两者都使用了“迁移”这个词,但从实现的角度来看,它们是完全不同的。
转移学习:通过使用已建立的模型来创建新的解决方案,概念本身是非常有趣和有效的。在一种环境中学习到的东西被利用来提高在另一种环境中的泛化能力。这在计算机视觉中尤其有用,因为这些模型的计算和训练非常耗费资源。使用一个在巨大数据集上训练过的模型,其结果现在可以免费获得,这对于个体实验来说是非常好的。
风格迁移:从概念上讲,最密切相关的是使用纹理转移实现艺术风格转移的方法。然而,这些先前的方法主要依赖于非参数技术来直接操纵图像的像素表示。相比之下,通过使用经过对象识别训练的深度神经网络,我们可以在特征空间中进行操作,以明确表示图像的高级内容。
所以这意味着深度学习方法的特点在于提取图像的风格,而不仅仅是通过对风格图像的像素观察,而是将预先训练好的模型提取的特征与风格图像的内容相结合。因此,从本质上说,要发现一个图像的风格,womenxuyao 通过分析其像素来处理风格图像并将此信息提供给预先训练过的模型层,以便将提供的输入“理解”/分类为对象
如何做到这一点,我们将在下面一节中探讨。
风格和内容
基本思想是将图像的风格转换为图像的内容。
因此,我们需要了解两件事:
- 图片的内容是什么
- 图像的风格是什么
松散地说,图像的内容是我们人类识别为图像中的对象的东西。汽车,桥梁,房屋等。风格很难定义。这在很大程度上取决于图像。它是整体纹理,颜色选择,对比度等。
这些定义需要以数学方式表达,以便在机器学习领域中实现。
损失函数的计算
首先,为什么要计算代价/损失?重要的是要理解,在这种情况下,损失只是原始图像和生成图像之间的差异。有多种计算方法(MSE,欧氏距离等)。通过最小化图像的差异,我们能够传递风格。
当我们从损失的巨大差异开始时,我们会看到风格转换不是那么好。我们可以看到风格已经转移,但是看起来很粗糙而且不直观。在每个代价最小化步骤中,我们都朝着更好地合并风格和内容并最终获得更好的图像的方向发展。
我们可以看到,此过程的核心要素是损失计算。需要计算3项损失:
内容损失
风格损失
总(变动)损失
在我看来,这些步骤是最难理解的,因此让我们一一深入研究。
请始终记住,我们正在将原始输入与生成的图像进行比较。这些差异就是代价。而我们希望将此代价降至最低。
理解这一点非常重要,因为在此过程中还将计算其他差异损失。
内容代价计算
什么是内容代价?正如我们之前发现的,我们通过图像对象定义图像的内容。作为人类的事物可以识别为事物。
了解了CNN的结构后,现在很明显,在神经网络的末端,我们可以很好地访问一个表示对象(内容)的层。通过池化层,我们丢失了图像的风格部分,但是就获取内容而言,这是理想的。
现在,在存在不同对象的情况下,可以激活CNN较高层中的特征图。因此,如果两个图像具有相同的内容,则它们在较高层中应具有相似的激活。
这是定义代价函数的前提。
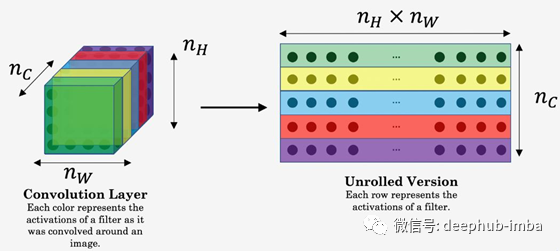
下图有助于了解如何展开该层以准备进行计算:
风格代价计算
现在,它变得越来越复杂。
确保了解图像风格和图像风格损失之间的区别。两种计算是不同的。一种是检测“风格表示”(纹理,颜色等),另一种是将原始图像的风格与生成的图像的风格进行比较。
风格总代价分为两个步骤:
- 识别风格图像的风格,从所有卷积层中获取特征向量;将这些向量与另一层中的特征向量进行比较(查找其相关性)
- 原始(原始风格图像!)和生成的图像之间的风格代价。为了找到风格,可以通过将特征图乘以其转置来捕获相关性,从而生成gram矩阵。
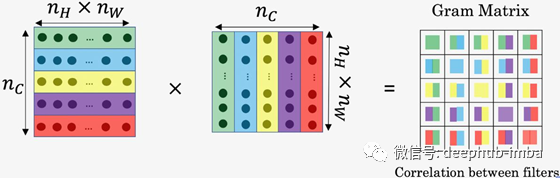
幸运的是,CNN为我们提供了多个层次,我们可以选择正确地查找其风格。比较各个图层及其相关性,我们可以确定图像的风格。
因此,我们不使用图层的原始输出,而是使用单个图层的要素图的gram矩阵来标识图像的风格。
第一个代价是这些矩阵之间的差异,即相关性的差异。第二个代价同样是原始图像和生成的图像之间的差异。这在本质上就是“风格转换”。
变化总代价计算
它就像一个正则化器,提高生成图像的平滑度。这在原始论文中没有使用,但改进了结果。本质上,我们消除了生成图像中样式和内容传输之间的差异。通过以上方法将代价最小化就可以使用优化器进行训练了。
作者:Daniel Deutsch
deephub翻译组