

R², RMSE, MAE
如果你像我一样,你可能会在你的回归问题中使用R平方(R平方)、均方根误差(RMSE)和均方根误差(MAE)评估指标,而不用考虑太多。🤔
尽管它们都是通用的度量标准,但在什么时候使用哪一个并不明显。
R方(R²)
R²代表模型所解释的方差所占的比例。
R²是一个相对度量,所以您可以使用它来与在相同数据上训练的其他模型进行比较。你可以用它来大致了解一个模型的性能。
我们看看R轴是怎么计算的。向前!➡️
这是一种表示R的方法。
1 - (SSE/SST)
SSE是误差的平方和;实际值与预测值之差的平方和。
SST为总平方和(有时用TSS表示);实际值与实际均值之差的平方之和实际值与实际均值之差的平方之和。
用更数学的符号:
1 - (∑(y - ŷ)² / ∑(y - y̅)²)
下面是代码的样子——改编自scikit-learn,主要的Python机器学习库。
numerator = ((y_true - y_pred) ** 2).sum()
denominator = ((y_true - np.average(y_true)) ** 2).sum()r2_score = 1 - (numerator / denominator)
用文字描述:
分子:
用实际的y值减去预测值求平方再求和
分母
用每个y值减去实际y值的均值求平方再求和
1 -分子/分母就是R方
R² 是scikit-learn回归问题的默认度量。如果你想显式地使用它,你可以导入它,然后像这样使用:
from sklearn.metrics
import r2_score
r2_score(y_true, y_pred)
R²分数越高越好。
然而,如果你的R²对你的测试集是1,你可能是泄漏信息或要简单的问题对于模型太简单了。👍
在一些领域,如社会科学,有许多因素影响人类的行为。假设你有一个只有几个自变量的模型结果R接近0.5。您的模型能够解释数据中一半的方差,这是非常好的。😀
R²有可能是负的。当模型拟合数据的预测低于输出值的平均值时,就会出现负分数。每次预测平均值都是一个空模型。
假设您有以下小测试数据集:
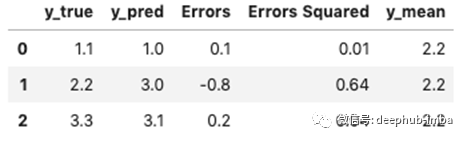
这是实际和预测的y值。
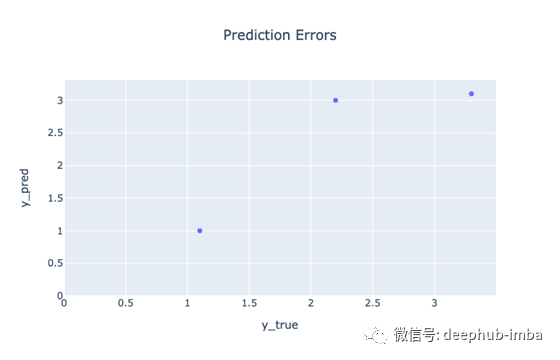
模型的R值是0。71。模型占数据方差的71%。虽然我们希望得到更多的测试数据,但这还不算太寒酸。
另一个例子,假设y的真实值是[55,2,3]均值是20。预测每个y值为20,结果R方差为0。
对上述真值进行预测[1,2,2]的模型得出的R值为-0.59。最重要的是,您可以做得比null模型糟糕得多!事实上,你可以预测更坏的情况,结果是一个无穷小的R方。
简而言之,让我们看看调整后的R²和机器学习与统计数据。调整后的R²说明增加了更多的预测变量(特征)。
当一个新的预测变量对模型性能的改善超过预期时,调整后的R²只会随着该变量的增加而增加。调整后的R²有助于您集中精力使用最节省的模型。😉
调整后的R²在统计推断中比在机器学习中更常见。scikitlearn是用于机器学习的主要Python库,甚至没有调整过的R²度量。Statsmodels是Python的主要统计库。如果您想进一步了解何时使用哪个Python库进行数据科学,我在这里编写了一个指南。
如果知道特征列的数量(p)和观察值的数量(n),就可以计算调整后的R2。代码如下:
adjusted_r2 = 1 — ((1 — r2) * (n — 1)) / ( n — p — 1)
n-1是自由度。每当你听到这个词,你就知道你在统计学领域。在机器学习中,我们通常最关心的是预测能力,因此R²比调整后的R²更受青睐。
关于统计学与机器学习的另一个注意事项:我们的重点是机器学习,所以预测而不是因果关系。R²-以及我们将要看到的其他指标,不要单独谈论因果关系。
R²告诉您模型所占的方差。它很方便,因为任何回归问题的R²将立即提供一些(有限的)对模型性能的理解。😀
R²是一个相对度量。现在让我们看看一些绝对的指标。
均方根误差(RMSE)
RMSE是一种非常常见的评价指标。它的范围可以是0到无穷大。值越低越好。要保持这一点,请记住名称中有错误,并且您希望错误率较低。☝️
RMSE的公式如下:SSE平方根我们在R²得分指标中看到了SSE。它是误差平方和;实际值和预测值的平方差之和。更多数学公式:(1/n*(∑(y-ŷ)²)的平方根Python代码:
np.sqrt(np.mean((y_true - y_pred) ** 2))
从实际y值中减去预测值,将结果平方求和,取平均值,取平方根以下是如何使用scikit learn中的函数获取RMSE:
from sklearn.model_selection
import mean_squared_error
mean_squared_error(y_true, y_pred, squared=False)
从scikit learn版本0.22.0开始,可以使用squared=False参数。在此之前,你必须自己这样取平方根:
np.sqrt(mean_squared_error(y_actual, y_predicted)
如果您想:
- 惩罚大错误
- 结果是否与结果变量的单位相同
- 使用可快速计算的损失函数进行验证
你可以使用无根的均方误差(MSE),但是单位就不那么容易理解了。取MSE的平方根,得到RMSE。
RMSE不一定随误差的方差而增加。RMSE随误差大小频率分布的变化而增大
此外,RMSE也不容易解释。这些单位可能看起来很眼熟,你不能简单地说RMSE为10意味着你平均减少了10个单位,尽管这是大多数人对结果的看法。至少,我以前是这样的。
再看看我们的示例数据集:
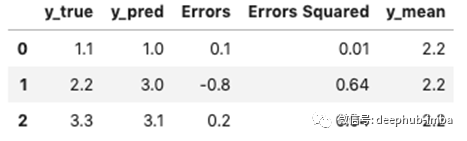
RMSE为0.48。实际y值的平均值为2.2。总之,这些信息告诉我们,这个模型可能介于伟大和可怕之间。如果没有更多的上下文,很难用这个RMSE统计数据做太多。
RMSE是一种不完善的评价统计量,但它很常见。如果你很在意惩罚大错误,这不是一个坏的选择。当超参数整定或批量训练深层神经网络时,它是一个很好的选择。
平均绝对误差(Mean Absolute Error)
平均绝对误差(MAE)是误差绝对值的平均值。
(1 / n) * (∑ |y - ŷ|)
代码
np.average(np.abs(y_true - y_pred))
用文字表述从实际y值中减去预测值,取每个误差的绝对值,求和,取平均值
以下是如何使用scikitlearn函数获取MAE:
from sklearn.model_selection
import mean_absolute_error
mean_absolute_error(y_actual, y_predicted, squared=False)
从概念上讲,MAE是回归问题最简单的评估指标。它回答了这样一个问题:“你的预测平均相差多远?”
这些单位很直观。对!🎉
例如,假设您正在预测房屋销售价格,测试集中的平均实际销售价格为500000美元。MAE为10000美元意味着该模型的预测值平均下降了1万美元。不错啊!
与RMSE评分不同,糟糕的预测不会导致过高的MAE分数,或者总是比RMSE更接近0。
注意,MAE的计算速度不如RMSE快,因为它是一个带有训练循环的模型的优化指标。
最后一次看我们的示例数据集:
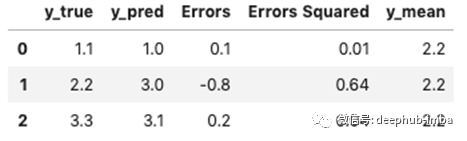
MAE是0.37。这些预测与平均值2.2的偏差平均为0.37。我很快就能理解这种说法。
顺便说下:RMSE为0.48,R²为0.71。
MAE是最简单、最容易解释的评价指标。如果你不想让一些遥远的预测压倒很多接近的预测,那么这是一个很好的度量标准。如果你想惩罚那些偏离目标很远的预测,这是一个不太好的选择。
总结
那么您应该使用哪种度量标准呢?总的来说,有以下三点!🚀
R²使评估性能的人员可以对模型的性能有一个直观的了解。
RMSE不太容易理解,但非常常见。它惩罚了非常糟糕的预测。由于计算速度快,这也为模型优化提供了一个很大的损失度量。
从这篇文章中对MAE有了新的想法。它很容易理解并按比例处理所有预测误差。我会在大多数回归问题评估中强调它。
本文代码地址:https://github.com/discdiver/r2_rmse_mae
作者:Jeff Hale
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********