
本文将详细介绍FPGA芯片。
微信搜索关注《Java学研大本营》
CPU为一般计算提供了一套通用的计算指令,要修改或优化应用程序,我们更改代码,但硬件是固定的。然而,这种通用化是以硬件的复杂性为代价的。如果没有复杂的硬件优化,如投机执行,它就会损害性能。但是,这些优化会增加芯片面积和功耗。

通用性以复杂性为代价提供了灵活性,为了增加深度学习(DL)中的并发性,一些芯片设计者将芯片功能限制在一套垂直的指令中,并使用ASIC(特定应用集成电路)设计实现。这是Google TPU使用的方法。但是,如果设计要求不断变化,则开发ASIC是昂贵且不可能的。
FPGA在通用处理器(如CPU)和ASIC之间提供了一种中间方法,设计人员可以为自己的硬件设计编程FPGA芯片,可以通过FPGA重新编程轻松地进行更改或增强。对于那些不熟悉FPGA的人来说,让我们先来了解一下技术概况。

1 什么是FPGA?
对于半导体行业来说,几十年来有一个中间解决方案,允许可配置的硬件设计(通用组件与定制ASIC设计)。这就是FPGA(现场可编程门阵列)。它被称为 "现场可编程的",因为我们可以轻松地为不同的硬件设计重新编程芯片。我们可以视为FPGA包含像乐高一样的积木。通过以不同的方式将乐高积木组合起来(编程),我们创造出不同的玩具(硬件设计)。让我们看一个DL的例子来解释人工智能中的高级应用。
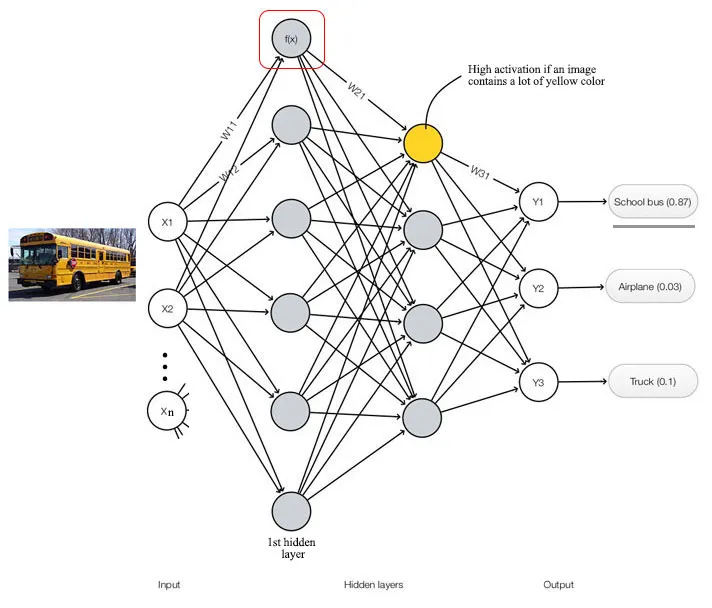
许多DL模型,如上面的全连接深度神经网络(DNN),可以视为计算图。节点表示计算,边表示数据流。为了对这个图进行建模,我们的ASIC设计应该由模拟这些节点中的计算的计算节点(块)组成,然后我们将数据流从一个节点链接到另一个节点。
FPGA是基于可配置逻辑块(CLB)矩阵通过可编程互连连接的半导体器件。CLB是高度可配置的,可以创建不同的逻辑。通过可编程互连,我们可以为这些CLB创建复杂的数据路径。
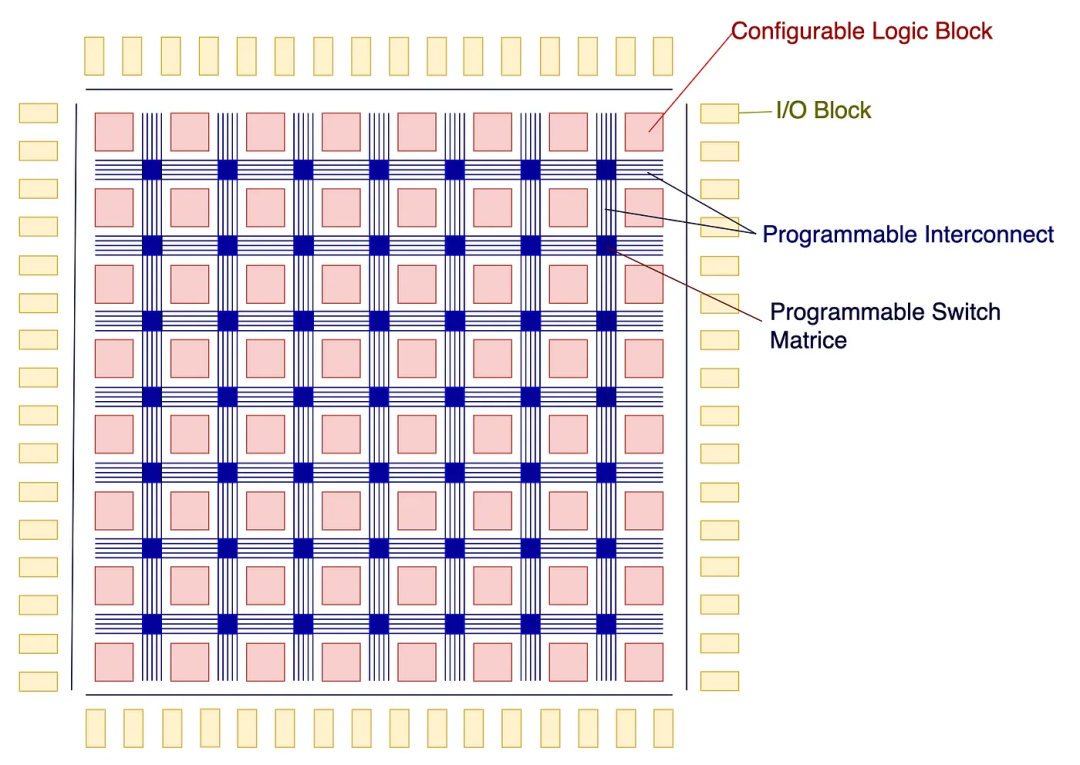
2 CLB
下面的图是Intel Stratix 10中逻辑阵列块(LAB)中自适应逻辑模块(ALM)的高级块图(LAB - 即可配置逻辑块CLB):
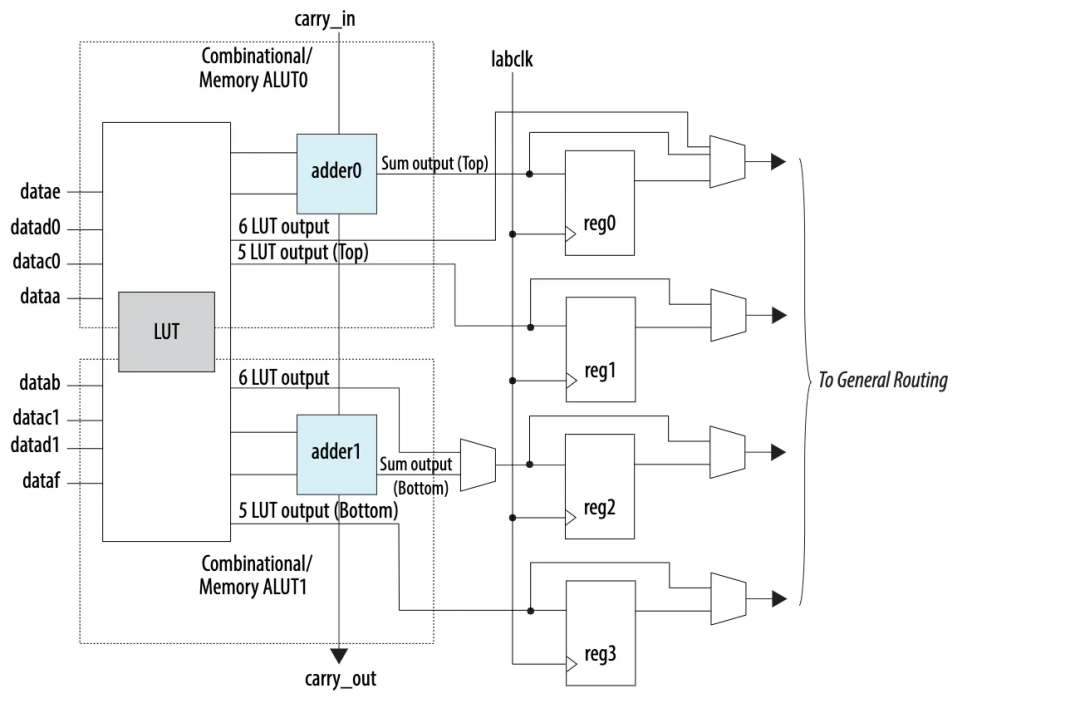
CLB使用可配置的查找表(LUT)(在上面的左边)来实现逻辑函数f(a, b, c, ...),我们可以配置LUT来模仿任何逻辑函数。

在CLB内部,LUT通常后面跟着带有输出寄存器的加法器(输出存储其先前值,直到应用新时钟)。
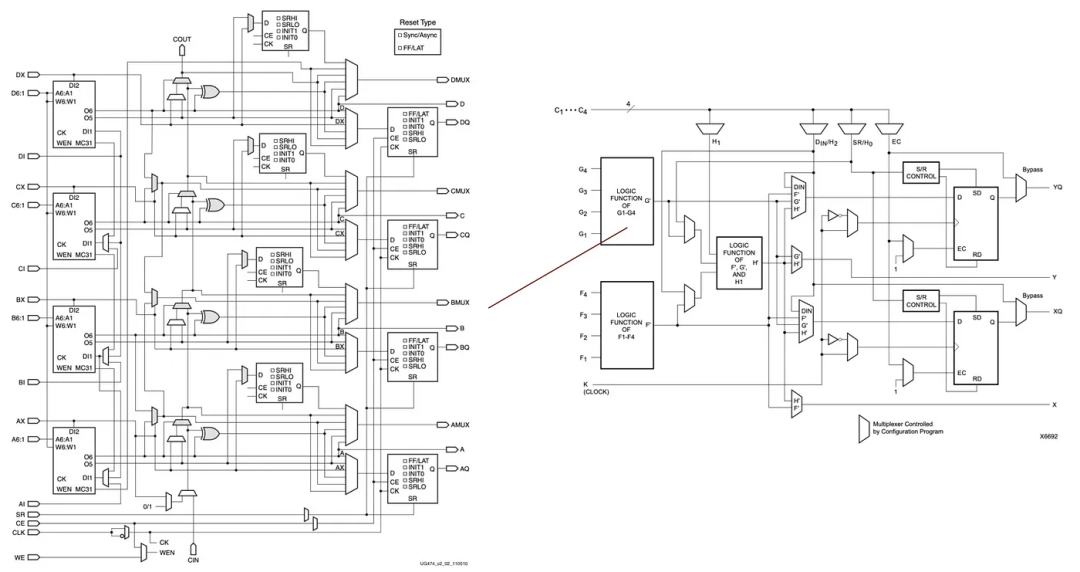
为了说明,这是来自Xilinx 7系列FPGA的另一个CLB示例。在右侧图中,输入端有两个模块,每个模块都有四个输入和一个逻辑值输出。然后,进一步的组合逻辑被应用于创建支持多于四个输入和多个输出的逻辑函数。
3 DL中的FPGA
为了进一步增强功能,可以将其他块(如存储器块、乘法器、嵌入式处理器和DSP块)添加到FPGA中。这些块可以通过下面的垂直和水平线进行分段和连接。
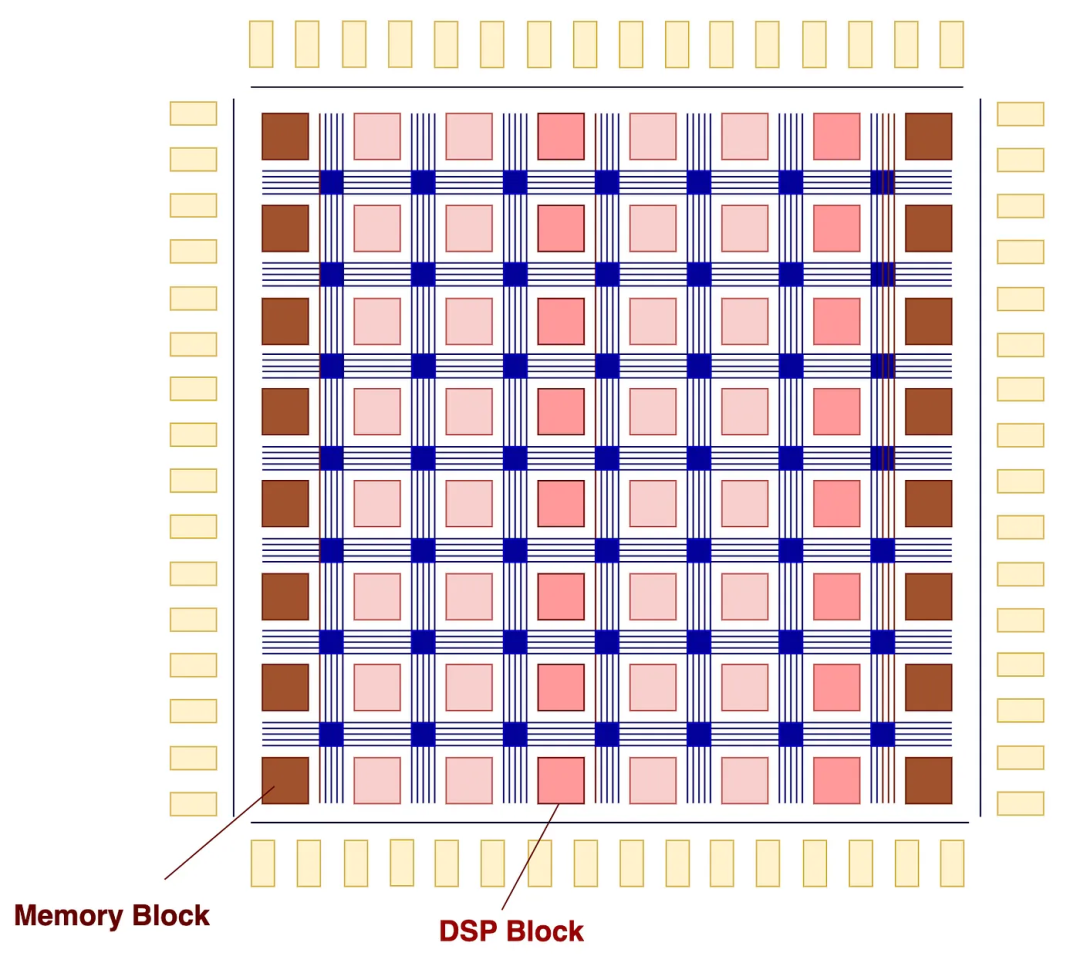
这里是英特尔Stratix 10可变精度DSP块。对于DNN,它将使用这些DSP块优化其许多算术函数。
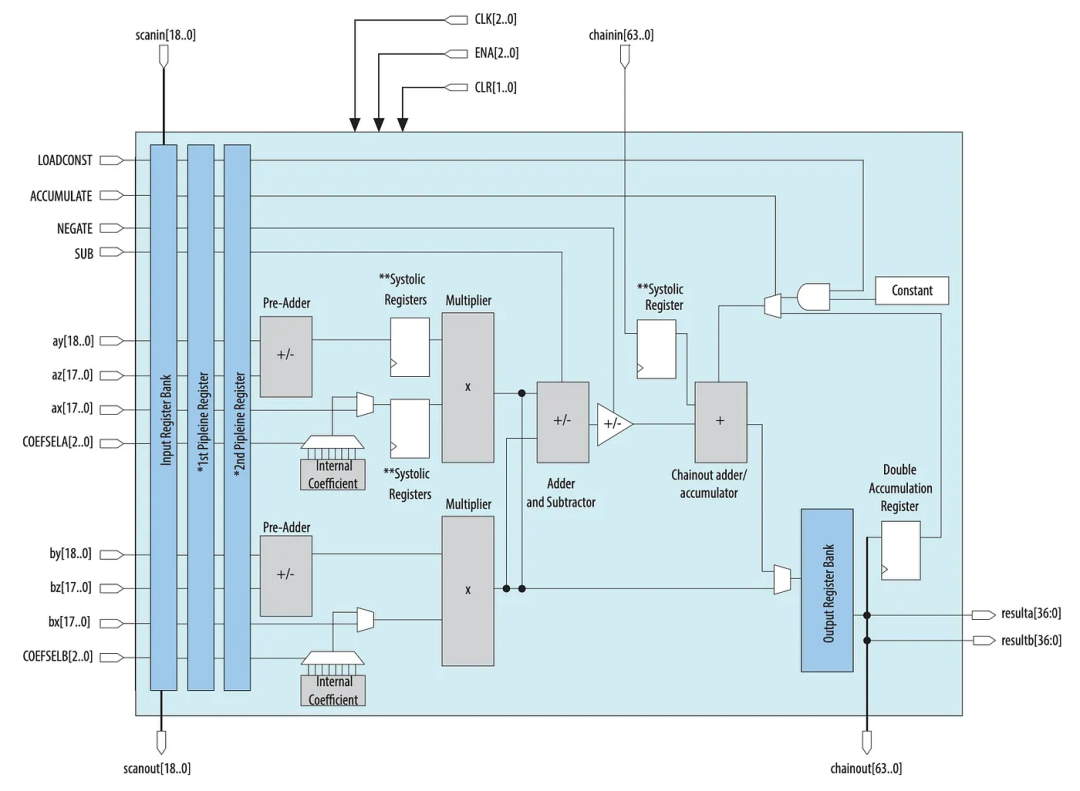
DSP块也可以配置来支持多个功能。
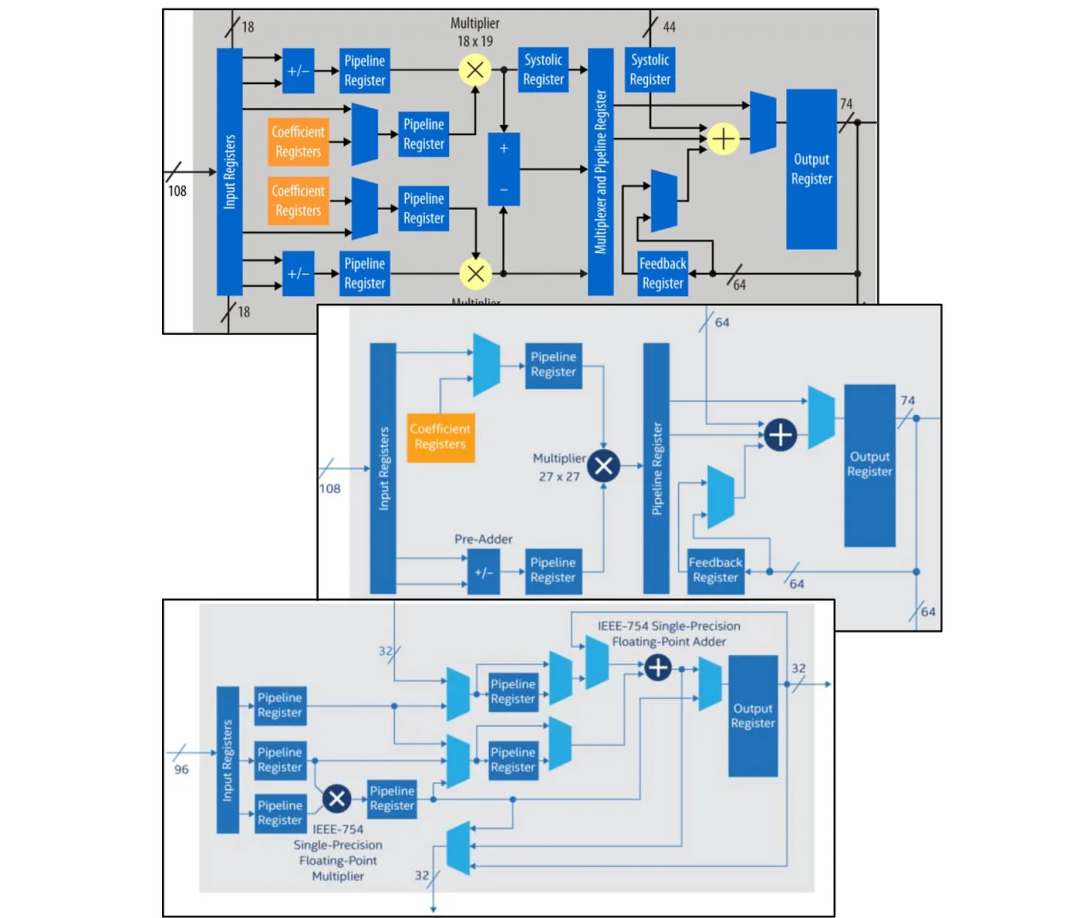
4 FPGA的卖点
根据不同的供应商和产品线,FPGA还可以提供许多其他模块。

FPGA可能包含数百万个逻辑元素、数千个存储块和数千个DSP块。这些存储块可以提供大于50TB/s的片上SRAM带宽。
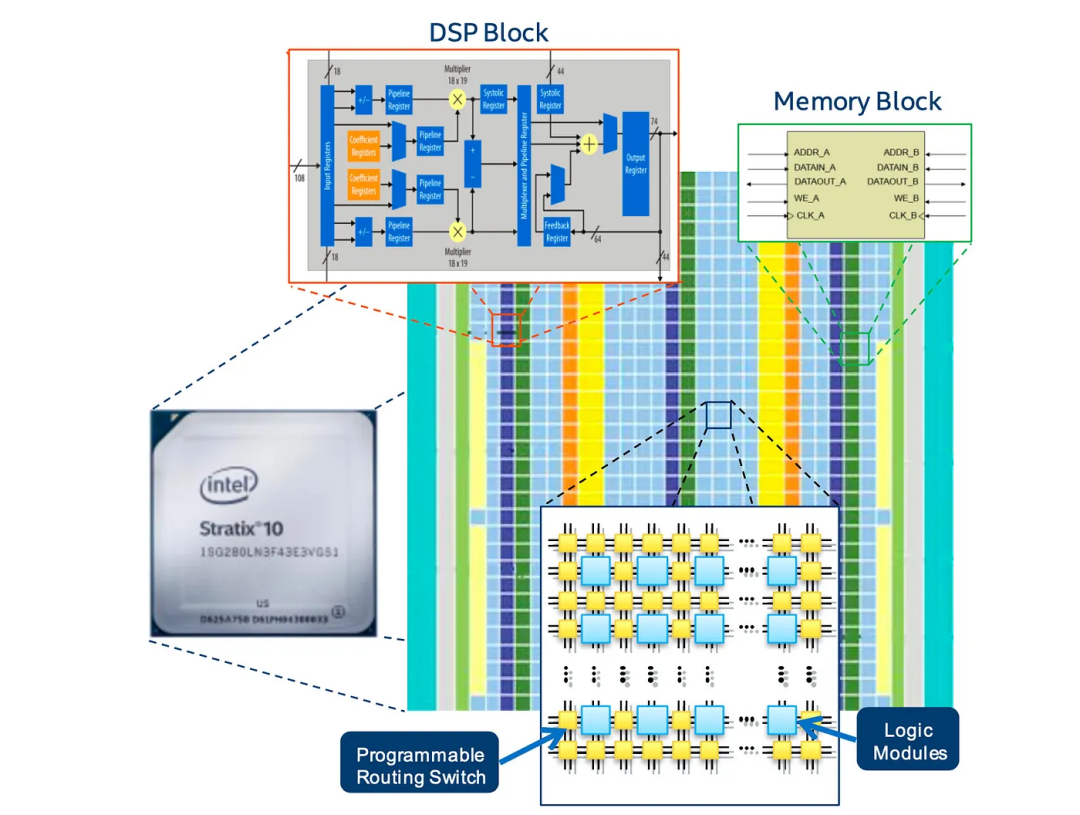
这些块可以分组、分段,并通过可编程的连接进行连接。这些块和互连是高度可配置的,以创建高度定制化设计的并行性和计算能力。高速存储块也可以分组成不同的大小,并为特定节点和特性集提供特定大小/缓存需求。
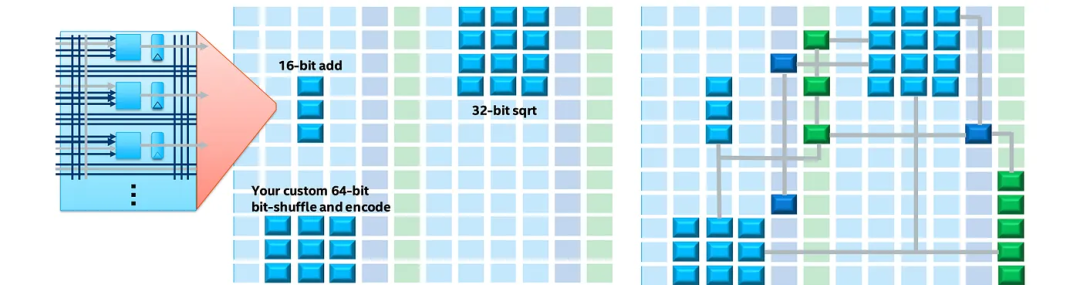
此外,FPGA被设计为能够快速接收和传输信号。高速收发器(带有许多I/O块)的重点是处理视觉和音频流数据的另一个卖点。使用新的FPGA位流文件,PGA可以在20毫秒范围内重新编程(取决于FPGA型号)。产品升级不再局限于软件升级。硬件设计升级可以通过新的位流文件完成。这种定制设计通常消耗更少的功率,在英特尔视觉加速器设计中,使用Arria 10 FPGA的功耗通常为38~42W,而Nvidia V100 GPU的功耗范围为250W(这仅用于说明,,因为两者的设备非常不同)。使用定制硬件还可以缩短系统延迟,这可能就是为什么英特尔将他们的FPGA用于AI推理的原因。
5 可编程互连
这些FPGA块可以通过垂直和水平线连接在一起。

但是,这是通过我们可以预编程的高度可配置的可编程交换矩阵(PSM)完成的。
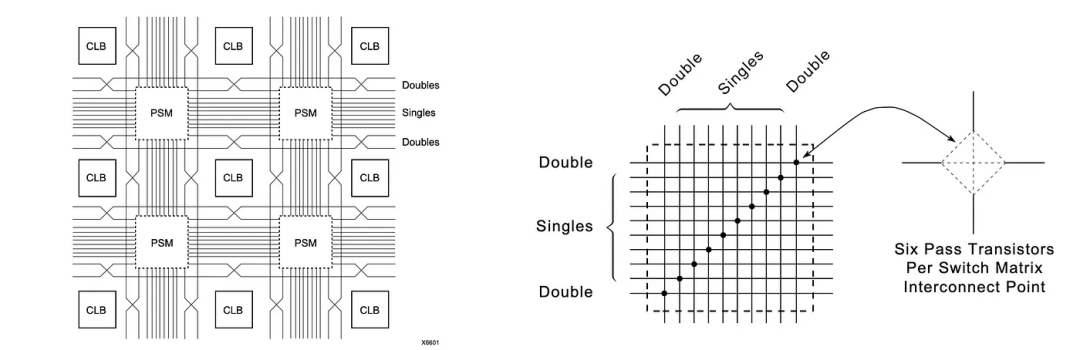
这是FPGA芯片一小段可能互连的放大视图:
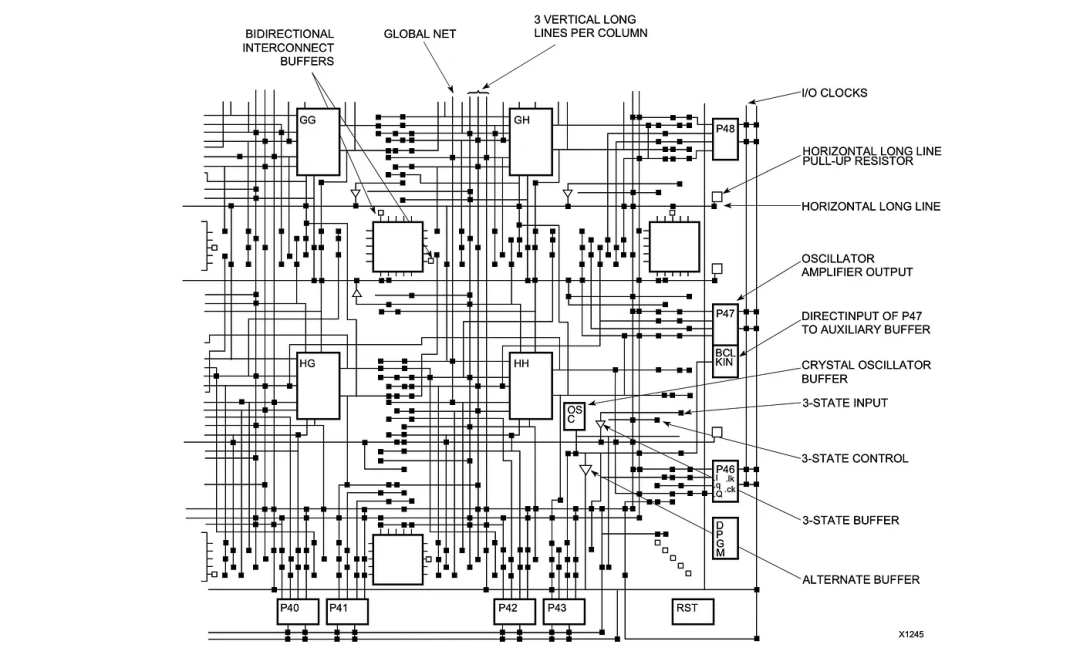
这是另一个演示块如何连接的例子:
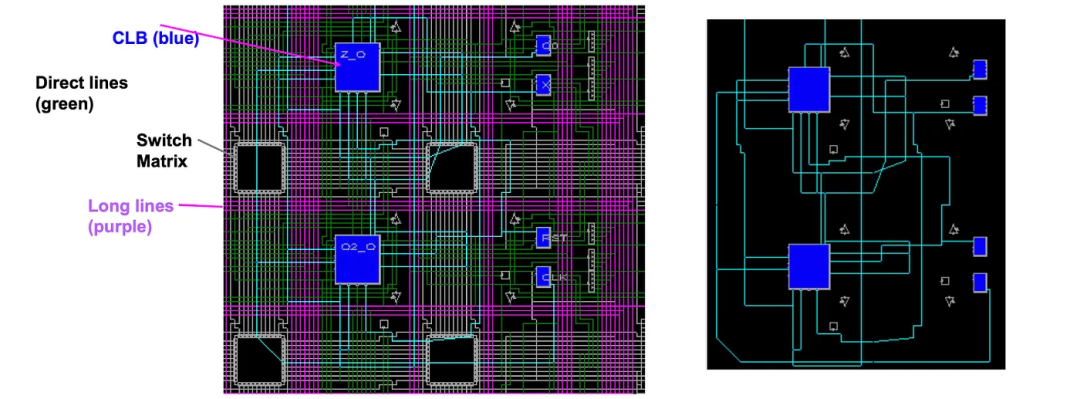
6 带有Arria 10 FPGA的英特尔视觉加速器设计(用于AI推理)

带有Arria 10 FPGA的英特尔视觉加速器可以连接到视频服务器或NVR(网络视频录像机),支持超过20个通道的视频输入,用于分析、处理或其他AI应用,包括面部识别和检测。

例如,我们可以使用加速器来分析原始视频流,以便能从许多视频源中进行人员检测和跟踪(在Amazon Go等商店中有潜在用途)。
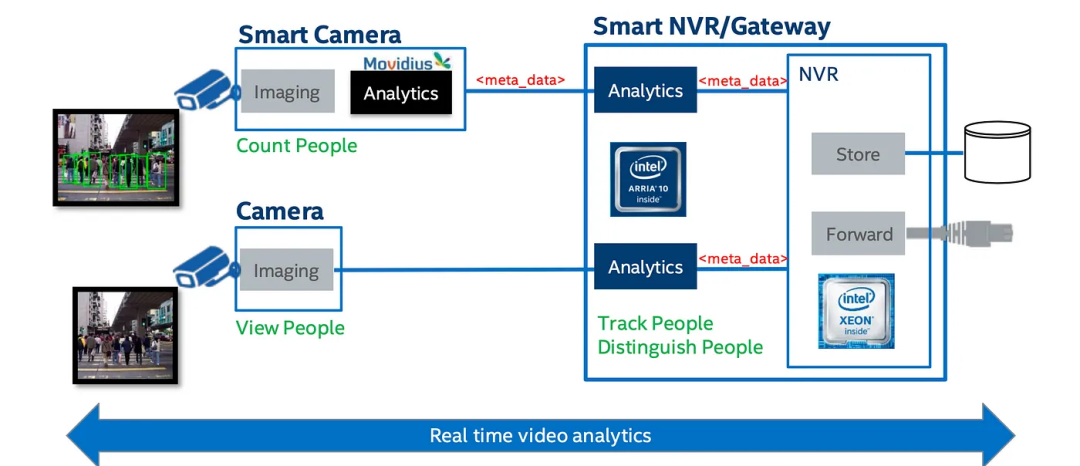
这里是另一个使用Arria 10 FPGA的FPGA加速卡(可编程加速卡)的设计:
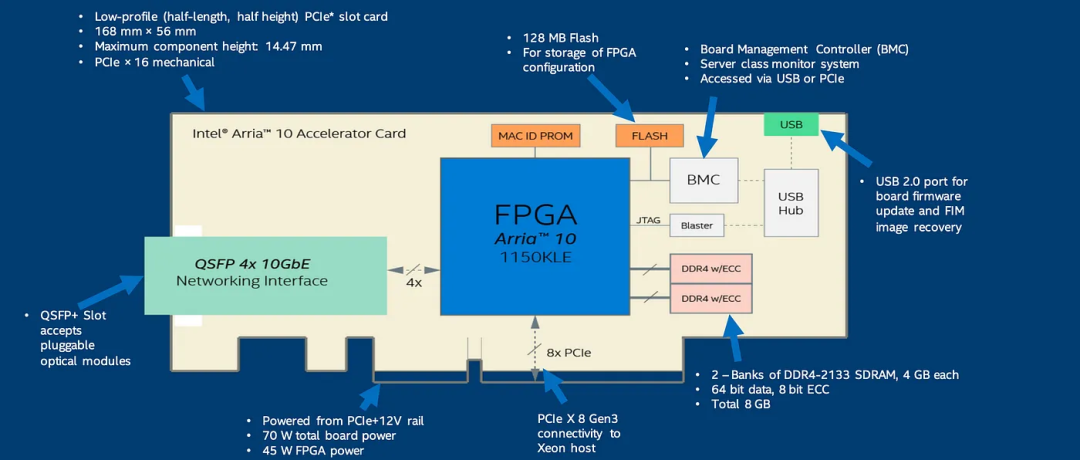
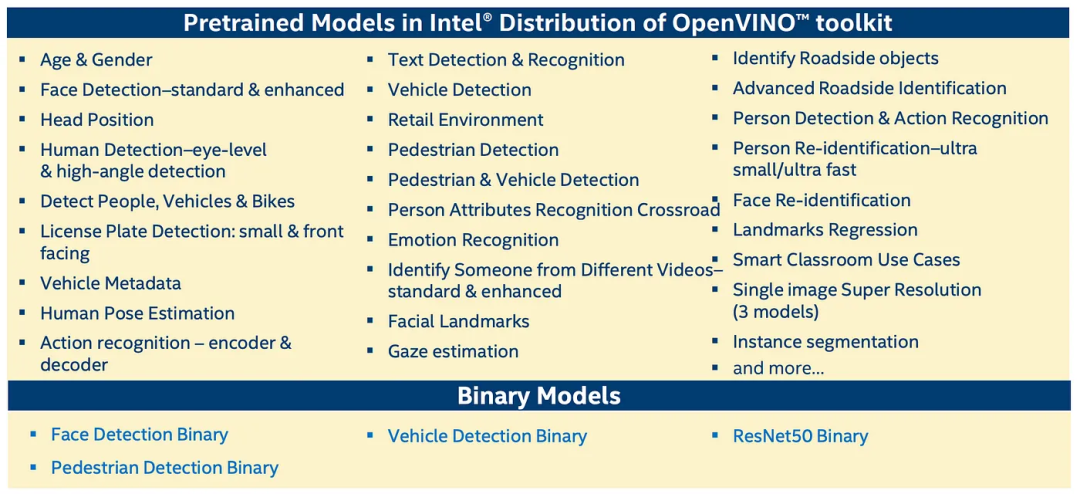
这些加速卡可以执行许多AI功能。OpenVINO(稍后讨论)发布了许多AI模型,执行以下功能:
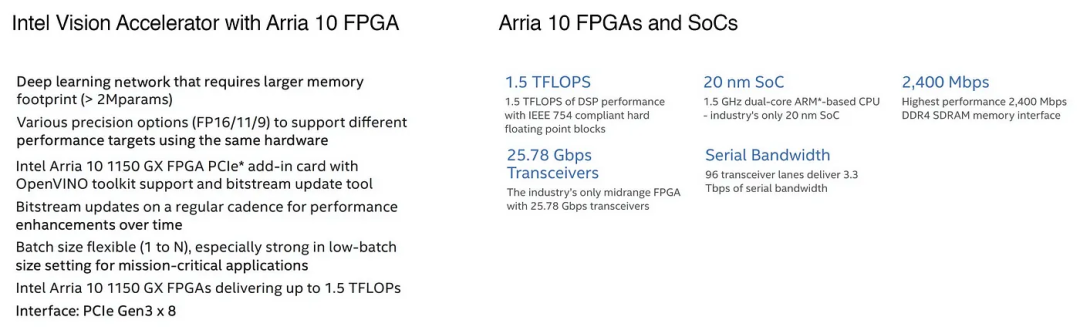
如果您感兴趣,这是加速卡和Arria 10的高级规格说明:
几十年来,FPGA都是用高级设计语言(HDL)编程的。它讲的是寄存器、时钟等的语言......
通过供应商提供的工具,HDL的源代码被转化为电路。然后应用放置和路由算法将它们映射到块中,通过最小化延迟的互连进行映射。这个编译过程需要几个小时或几天才能完成。完成后,将创建一个位流文件。该文件将用于编程(配置)FPGA。
但是,这不是我们在Intel FPGA上设计或部署DNN模型的方式。使用工具包执行软件部署,而不是重新编程FPGA。FPGA应该已经被编程了。
7 OpenVINO
OpenVINO(Open Visual Inference and Neural network Optimization)为Intel设备(CPU、集成GPU、FPGA等)提供工具包和库,涵盖以下领域:

它可以用来部署一个DL模型,使用FPGA分析视频流。
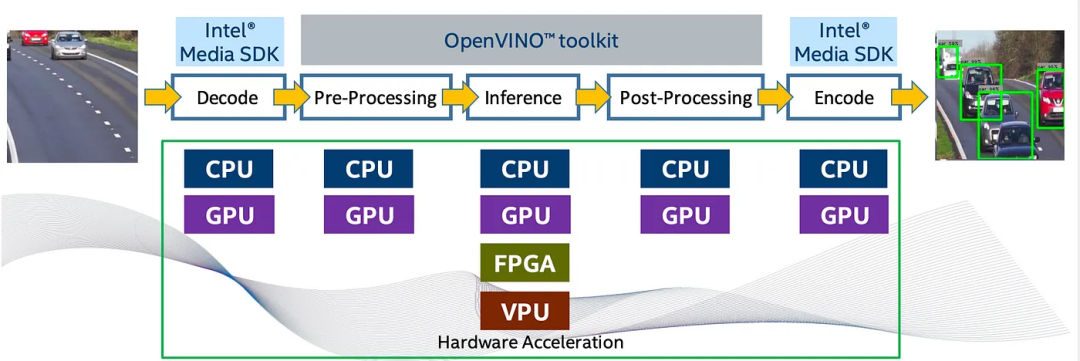
OpenVINO发行版包含:
- 优化和部署ML模型的深度学习开发工具箱(DLDT)
- 用于DL的FPGA深度学习加速器(DLA)和比特流
- 用于OpenCV、OpenVX、OpenCL和Intel Media SDK的工具、库和加速器
- 适用于Intel设备的插件
- 为DLDT提供预训练模型的模型库

DL工程师在诸如TensorFlow、PyTorch等软件平台上设计和训练模型。最终,我们将训练好的模型保存在文件中(TensorFlow中的.pb文件)。
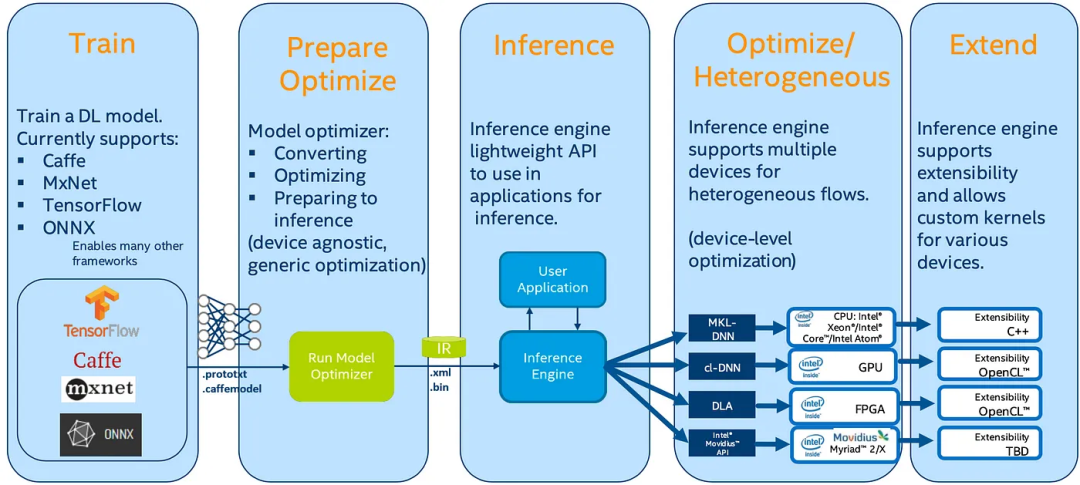
然后,我们使用OpenVINO中的深度学习部署工具包(DLDT)来部署DL模型。DLDT包含两个主要组件:
- 模型优化器
- 推理引擎
具体而言,DLDT读取模型文件,执行优化,并将其部署在Intel设备上。为了拥有所有Intel设备的单一平台解决方案,它从流行的DL平台(如TensorFlow)读取训练好的模型文件,应用与设备无关的优化,并将模型转换为与设备无关的中间表示(IR)。
以下两个部分是可选的,用于演示一些计算图优化。
8 线性操作融合(高级主题-可选)
许多CNN模型,包括ResNet和Inception,都包含批量归一化和比例偏移层(比例然后偏移输入),可以看作是加法和乘法的序列。这些序列可以合并为单个乘法和加法操作,即×、+、×、+、×、+→×、+。然后,如果存在下一个卷积层或完全连接层,则可以将其与之融合。
推荐书单
《微机原理与接口技术——基本原理、实用技术和基于FPGA的SOC技术》
《微机原理与接口技术--基本原理实用技术和基于FPGA的SOC技术(高等院校电子信息科学与工程规划教材)》系统地讲解了微型计算机系统的结构、工作原理、接口技术及其应用,特别是将这些内容与现代EDA技术、FPGA开发技术和SOC片上系统技术有机地融合起来,全方位强化和拓展了这一传统教学领域中的知识与技能传授的深度与广度。本书的基本内容包括80x86微处理器结构、指令系统、汇编语言程序设计、存储器系统、总线技术、中断技术、定时/计数接口技术和DMA技术、并行接口技术、串行接口技术、模拟接口技术和其他实用的接口技术,以及与这些内容相对应的基于超大规模F=PGA的SOC技术。 本书可作为高等院校电子工程、通信、工业自动化、计算机等专业的本科生或研究生教材,也可用作相关专业技术人员的参考书。
《微机原理与接口技术——基本原理、实用技术和基于FPGA的SOC技术》【摘要 书评 试读】- 京东图书京东JD.COM图书频道为您提供《微机原理与接口技术——基本原理、实用技术和基于FPGA的SOC技术》在线选购,本书作者:,出版社:清华大学出版社。买图书,到京东。网购图书,享受最低优惠折扣!https://item.jd.com/10067827338575.html

精彩回顾
9个步骤,手把手教你在Windows上安装Hadoop
一文讲清RabbitMQ、Apache Kafka、ActiveMQ
一文讲清数据集市、数据湖、数据网格、数据编织
分布式计算哪家强:Spark、Dask、Ray大比拼
使用FPGA制作低延时高性能的深度学习处理器
微信搜索关注《Java学研大本营》
访问【IT今日热榜】,发现每日技术热点
版权归原作者 Java学研大本营 所有, 如有侵权,请联系我们删除。