
介绍:
生成式人工智能的出现开启了创造性可能性的新领域。DALL-E 2 和 Stable Diffusion 等模型在通过简单的文本提示生成高质量图像方面表现出了前所未有的能力。然而,一个关键的限制仍然存在——缺乏实时交互性。
当涉及 Metaverse、视频游戏图形、直播和广播等应用程序所需的连续输入流时,现有的扩散模型往往会出现问题。事实证明,顺序处理管道不足以处理此类实时交互场景的高吞吐量需求。
StreamDiffusion 是一种开创性的管道解决方案,专为实现实时扩散功能和流畅的用户交互而设计。在本文中,我们将深入探讨推动这一突破的创新,这一突破有望彻底改变生成式人工智能。
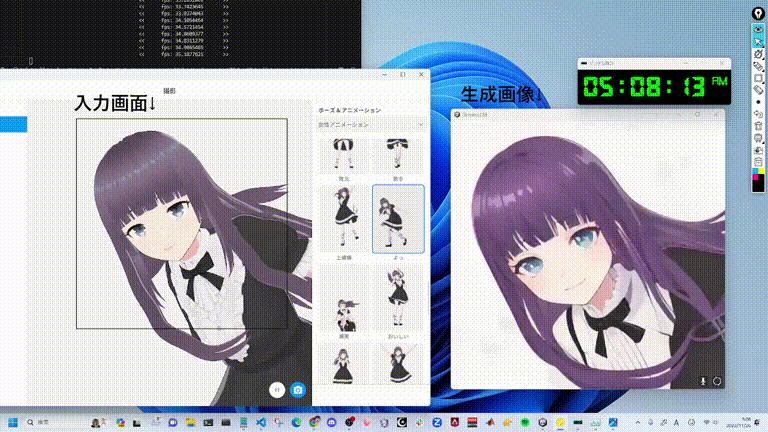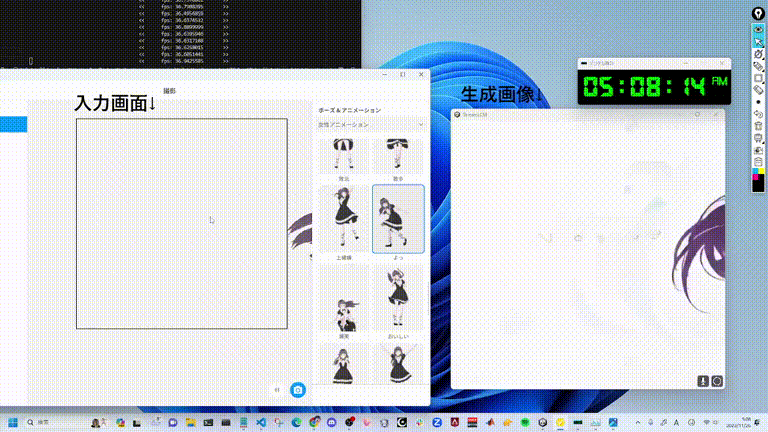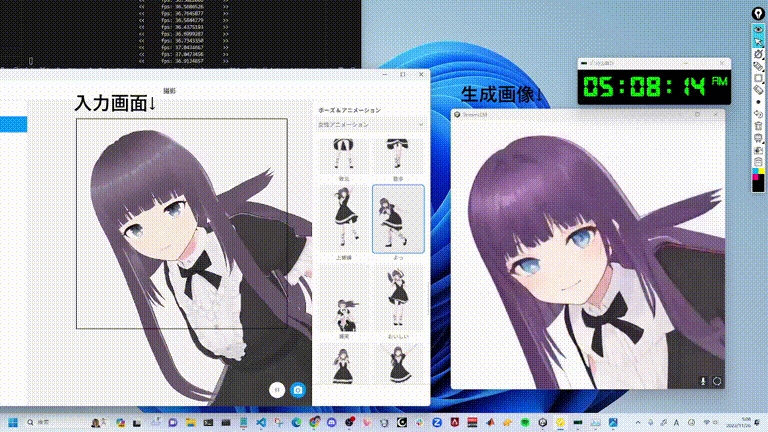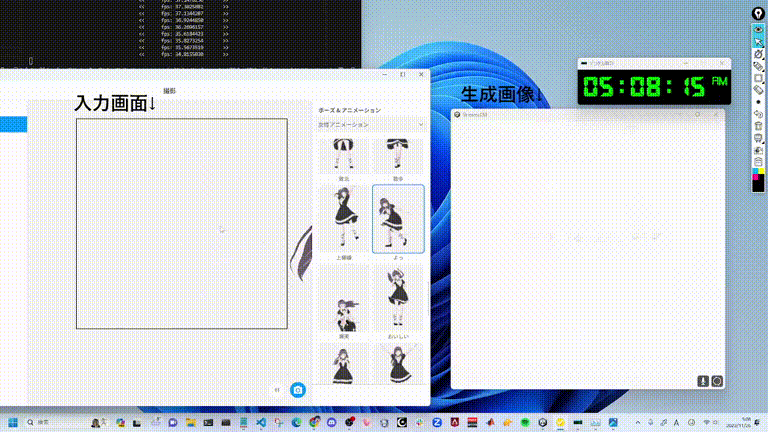
实时交互扩散的瓶颈
扩散模型的核心是通过顺序去噪过程发挥作用。此过程中的步骤数与输出质量和延迟直接相关。更多步骤可以提高质量,但也会增加处理延迟。
这在处理需要高吞吐量的连续输入流时会产生瓶颈。例如,像人工智能驱动的虚拟助理这样的用例需要亚秒级延迟才能获得无缝的对话体验。
现有的模型优化工作主要集中在减少扩散步骤的数量。但 StreamDiffusion 采用了一种正交方法——一种以管道级增强为中心的方法,以提高吞吐量。
游戏规则改变者:StreamDiffusion 管道
本文转载自: https://blog.csdn.net/iCloudEnd/article/details/135320880
版权归原作者 知识大胖 所有, 如有侵权,请联系我们删除。
版权归原作者 知识大胖 所有, 如有侵权,请联系我们删除。