
Llama2是Meta最新开源的语言大模型,训练数据集2万亿token,上下文长度是由Llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,最重要的是,该模型可用于研究和商业用途。
一、准备工作
1、本文选择部署的模型是Llama2-chat-13B-Chinese-50W(模型的下载地址为:https://huggingface.co/RicardoLee/Llama2-chat-13B-Chinese-50W)
2、由于大部分笔记本电脑无法满足大模型Llama2的部署条件,因此可以选用autodl平台(算力云)作为部署平台。注:收费,但比阿里云便宜的多
二、在autodl平台租用实例
注册账号,进行登录。点击右上角的“控制台”进入个人控制台。点击左侧“容器实例”进入页面。再点击“租用新实例”进行实例的租用。

进入“租用新实例”页面后,计算方式选择“按量计费”,地区选择“北京C区”,主机选择算力型号为“V100-32GB”的即可。

镜像选择“基础镜像”:PyTorch/2.0.0/3.8(ubuntu20.04)/11.8

最后点击“立即创建”。

等待一会儿,状态变为“运行中”后,点击“关机”
三、克隆大模型Llama2到数据盘
点击实例右侧的“更多”,选择“无卡模型开机”。下载数据无需GPU,选择无卡模式开机价格更低。
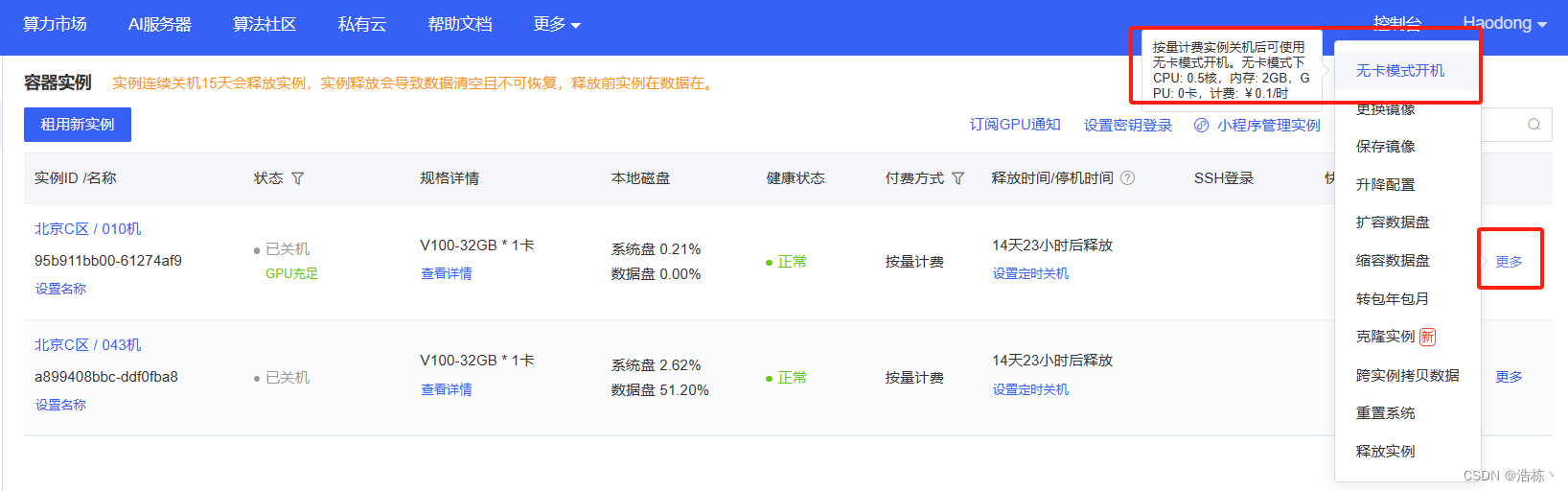
开机之后,点击快捷工具中“JupyterLab”进入JupyterLab。

其中autodl-tmp是数据盘,用于存储较大的文件,剩余三个为系统盘。在本次实验中,Llama2大模型文件存储在autodl-tmp.

接下来新建一个文件夹“Llama2”,用于存储执行文件。
然后进入到autodl-tmp内,下载Llama2-chat-13B-Chinese-50W,依次运行以下代码。
1、安装git-lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
运行结果图

2、克隆大模型Llama2到数据盘
克隆过程中需要链接VPN,可以使用云平台自带的学术加速功能,运行以下代码即可。
source /etc/network_turbo

运行以下代码对大模型进行克隆:
git clone https://huggingface.co/RicardoLee/Llama2-chat-13B-Chinese-50W
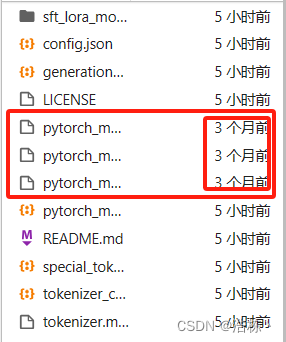
运行一会儿后卡住不动或报错,观察左侧发现,有三个文件未下载。

三个文件都比较大,分别为9.6G、9.6G、6.4G。如果因为网络原因无法下载这个三个文件,那么可以进入到huggingface官网将模型下载到本地,然后再上传至云平台。(进入huggingface需要链接VPN,如有需要可直接三连私信赠送源文件)
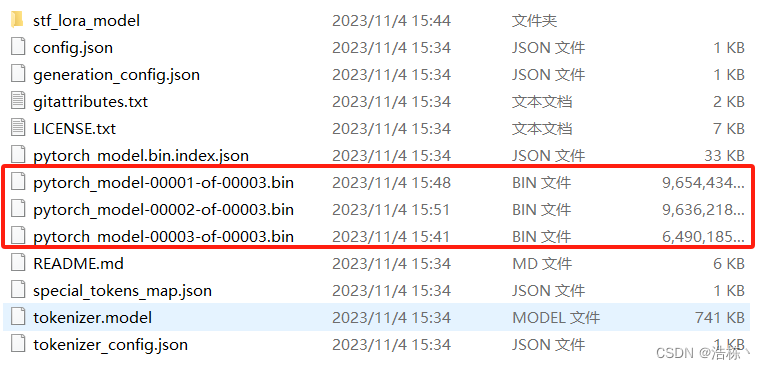
或者运行下面代码依次单独下载(记得cd到Llama2-chat-13B-Chinese-50W/目录下进行下载):
wget https://huggingface.co/RicardoLee/Llama2-chat-13B-Chinese-50W/resolve/main/pytorch_model-00001-of-00003.bin
wget https://huggingface.co/RicardoLee/Llama2-chat-13B-Chinese-50W/resolve/main/pytorch_model-00002-of-00003.bin
wget https://huggingface.co/RicardoLee/Llama2-chat-13B-Chinese-50W/resolve/main/pytorch_model-00003-of-00003.bin
运行结果图(如果速度过慢,请设置学术加速)

下载完毕后,需要注意,如果显示为“N个月前”即表示成功下载,如果是最近日期(如3分钟前),说明下载过程中出现了问题,那么需要重新下载。
四、下载并部署gradio
随着ChatGPT等机器人对话框架的流行,让一个名为gradio的框架也火热起来,这个框架可以开启一个http服务,并且带输入输出界面,可以让对话类的人工智能项目快速运行。gradio号称可以快速部署ai可视化项目。
1、下载执行文件gradio_demo.py和requirements.txt
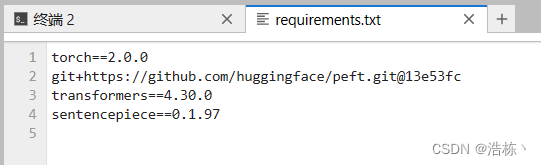
2、修改requrement.txt里的torch版本为2.0.0,然后安装requirements.txt
修改requrement.txt里的torch版本为2.0.0,修改完后记得点击Ctrl+S进行保存。
切换到Llama2目录下,执行以下代码,安装requirements.txt
pip install -r requirements.txt
运行结果图(如果报错,请设置学术加速)
3、注释gradio.py里59、60、61行,手动安装相关包
把gradio.py里59、60、61行注释掉,然后手动安装gradio和gradio_demo.py里import的包:

安装gradio:
pip install gradio -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com

安装bitsandbytes:
pip install bitsandbytes

安装accelerate:
pip install accelerate

安装scipy:
pip install scipy

完成以上步骤之后,关闭“JupyterLab”并关机。
五、有卡模式开机,运行大模型
返回到AutoDL控制台,点击“开机”。开机之后,点击快捷工具中“JupyterLab”进入JupyterLab。
首先cd到文件夹Llama2下,并设置学术加速。

运行大模型:
python gradio_demo.py --base_model /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --tokenizer_path /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --gpus 0
运行结果:

点击红色框中的链接,即可出现对话页面。
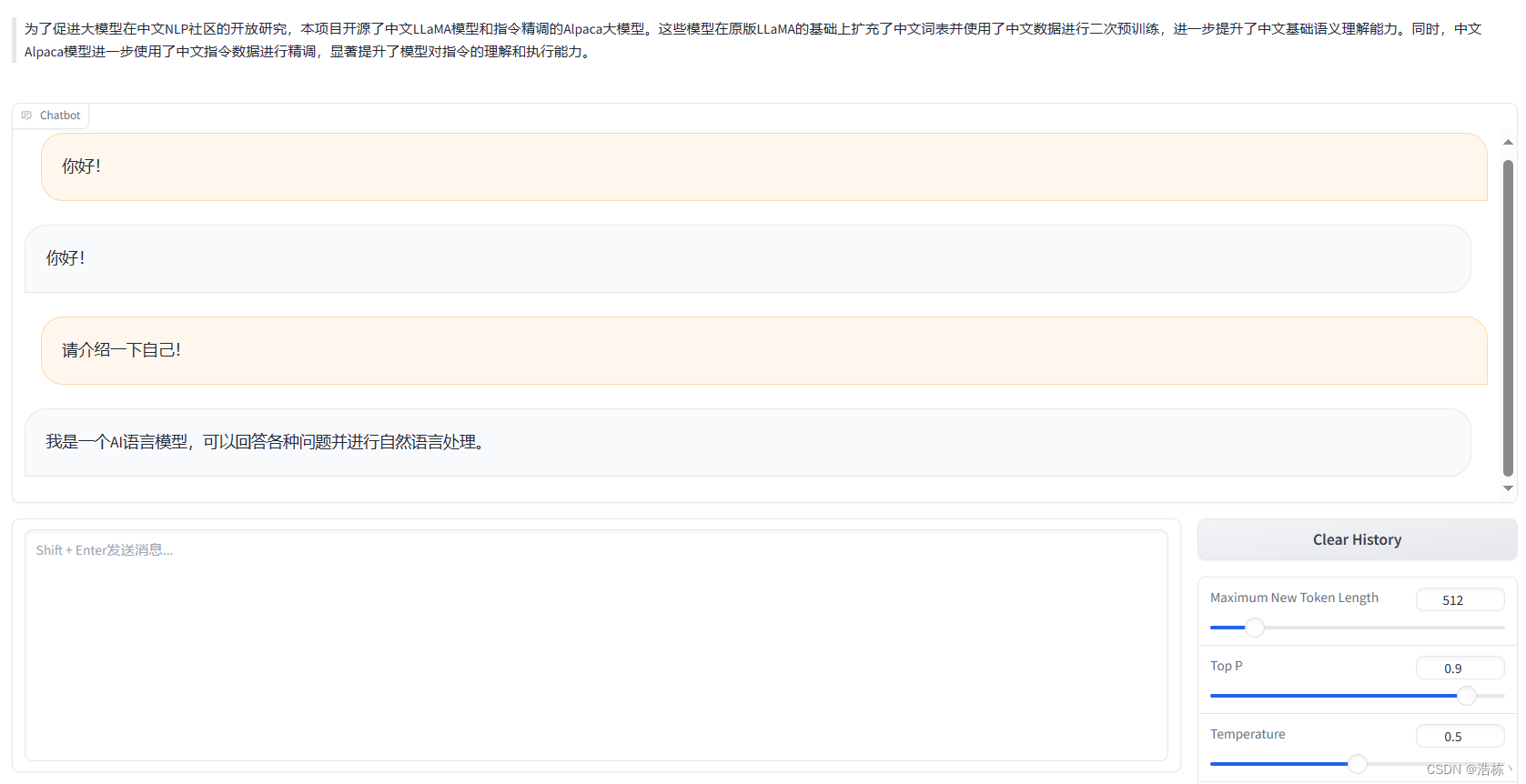
至此,你已成功部署Llama2-chat-13B-Chinese-50W!
六、可能会出现的问题
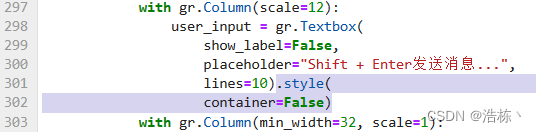
1、第五步(有卡模式开机,运行大模型),当输入代码运行后,出现报错。
报错内容:
Vocab of the base model: 49954
Vocab of the tokenizer: 49954
Traceback (most recent call last):
File "gradio_demo.py", line 298, in <module>
user_input = gr.Textbox(
AttributeError: 'Textbox' object has no attribute 'style'

解决办法:打开gradio_demo.py文件,删除第301、302行中阴影部分内容。删除之后点击Ctrl+S保存。
再次运行,报错消失。
感谢三连!
版权归原作者 Haodong丶 所有, 如有侵权,请联系我们删除。