
图像处理的概论
图像分析一般利用数学模型并结合图像处理的技术来分析底层特征和上层结构,到从而提取具有一定智能性的信息,其中对图片内容分析,图片内容识别和检测都离不开图像的分类。
图像分类目标:已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。
图像处理流程
图像分类
图像数据分析的内容是什么?内容分析,内容识别,检测都离不开图像的分类
分类目标:所谓图像分类问题,就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。
图像分类流程:
1.输入:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
2学习:这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型。
3.评价:让分类器来预测它未曾见过的图像的分类标签,把分类器预测的标签和图像真正的分类标签对比,并以此来评价分类器的质量。
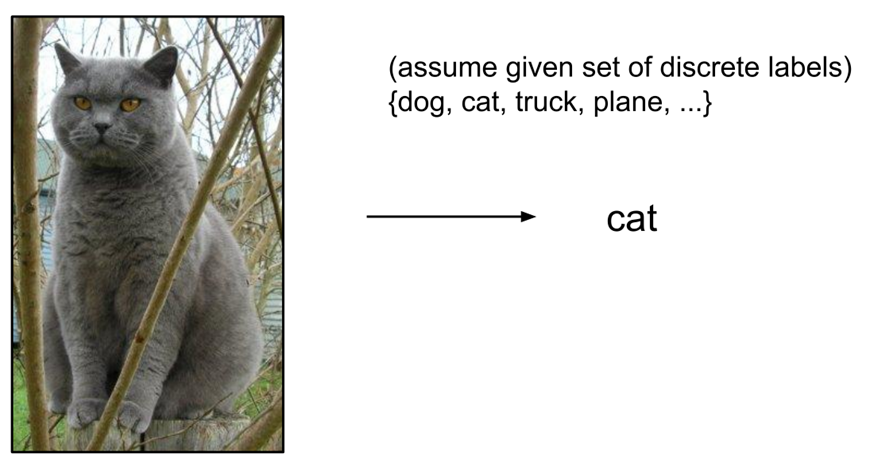 计算机通过训练集{dog(狗),cat(猫),truck(卡车),plane(飞机)}来学习dog,cat,truck,plane到底长什么样,有什么特征,之后预测这张它未曾见过的图像的分类标签,把分类器预测的标签和图像真正的分类标签对比,得出与分类标签cat匹配率最高。
计算机通过训练集{dog(狗),cat(猫),truck(卡车),plane(飞机)}来学习dog,cat,truck,plane到底长什么样,有什么特征,之后预测这张它未曾见过的图像的分类标签,把分类器预测的标签和图像真正的分类标签对比,得出与分类标签cat匹配率最高。
前面我们学习了机器学习的相关算法,作为底层的机器学习算法,它将会为我们提供一系列的算法支撑,最终帮助我们对图像数据进行训练,分类。
图像处理应用场景
图像相比文字能够提供更加生动、容易理解及更具艺术感的信息,是人们转递与交换信息的重要来源。
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。
图像分类在很多领域有广泛应用,包括安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类。
随着人类活动范围的不断扩大,图像分类的应用领域也将随之不断扩大,比如卫星影像,医学领域的图像识别等,通过计算机图像分类技术既节省人力,又加快了速度,还可以从照片中提取人工所不能发现的大量有用情报。

考古只是图像分类在卫星领域的一个很小的应用,现在世界各国都在利用陆地卫星所获取的图像进行资源调查(如森林调查、海洋泥沙和渔业调查、水资源调查等),灾害检测(如病虫害检测、水火检测、环境污染检测等),资源勘察(如石油勘查、矿产量探测、大型工程地理位置勘探分析等),农业规划(如土壤营养、水份和农作物生长、产量的估算等),城市规划(如地质结构、水源及环境分析等)。
 图像分类在生物医学工程方面的应用十分广泛,而且很有成效。除了上面介绍的痰液自动分析系统之外,还有一类是对医用显微图像的处理分析,如红细胞、白细胞分类,染色体分析,癌细胞识别等。此外,在X光肺部图像增晰、超声波图像处理、心电图分析、立体定向放射治疗,CT技术等医学诊断方面都广泛地应用图像处理技术。
图像分类在生物医学工程方面的应用十分广泛,而且很有成效。除了上面介绍的痰液自动分析系统之外,还有一类是对医用显微图像的处理分析,如红细胞、白细胞分类,染色体分析,癌细胞识别等。此外,在X光肺部图像增晰、超声波图像处理、心电图分析、立体定向放射治疗,CT技术等医学诊断方面都广泛地应用图像处理技术。
图像在计算机内的结构
图像在计算机中的结构
在进行图像分类前我们了解一下图像在计算机中的结构
对于计算机来说,图像是一个由数字组成的巨大的3维数组。
图像是对真实存在的或者人们想象的客观对象的一种表示方式,这种方式能被人的视觉系统感知。但是对计算机来说,每张图像都是由一个或者多个相同维度的数据通道构成。
以RGB彩色图像为例,每张图片都是由三个数据通道构成,分别为红、绿和蓝色通道。
而对于灰度图像,则只有一个通道。
多光谱图像一般有几个到几十个通道。高光谱图像具有几十到上百个通道。
我们主要介绍多通道情况下,最常见的红绿蓝(RGB)三通道,第一个维度是高度,第二个维度是宽度,第三个维度是通道数,即对于计算机来说,图像是一个由数字组成的巨大的3维数组。
 图像如何进行分类,计算机是通过数据(数值)进行公式运算和算法迭代的,那么我们应该如何理解图像呢?图像是一个图片,但是它不是数值,可是为什么我们的机器还可以运算呢?
图像如何进行分类,计算机是通过数据(数值)进行公式运算和算法迭代的,那么我们应该如何理解图像呢?图像是一个图片,但是它不是数值,可是为什么我们的机器还可以运算呢?
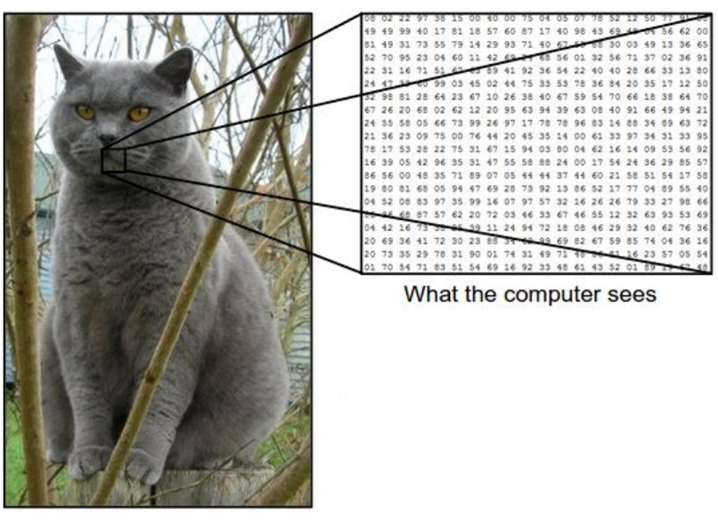
因为在计算机里面读取的图片它是由数值矩阵构成的
图示的矩阵里,每个元素都是一个3维数组,分别代表这个像素上的三个通道的值。
最常见的RGB通道中,第一个元素就是红色(Red)的值,第二个元素是绿色(Green)的值,第三个元素是蓝色(Blue)。
对于RNG通道,其卷积表示为高度×宽度×通道数,即H×W×C的表达方式。
在这个例子中,猫的图像大小是宽248像素,高400像素,有3个颜色通道,分别是红、绿和蓝(简称RGB)。如此,该图像就包含了248X400X3=297600个数字,每个数字都是在范围0-255之间的整型,其中0表示全黑,255表示全白。
1.在计算机中图像以三维数组的形式表达;
2.机器学习就是通过算法,使得机器能从大量历史数据中学习规律,从而对新的样本做智能识别或对未来做预测,机器学习算法的输入可以是数组。
3.能否将这些数组放入机器学习算法中,通过比较数组的距离进行分类,最终通过机器学习算法实现图像分类?
图像与机器学习的关系
 要使机器学习实现图像分类,我们再回忆一下机器学习,即机器学习的一个核心目标是从过往经验数据中推导出规律,并将这种规律应用于新的数据中。
要使机器学习实现图像分类,我们再回忆一下机器学习,即机器学习的一个核心目标是从过往经验数据中推导出规律,并将这种规律应用于新的数据中。
我们把机器从经验数据中推导并找到规律这一过程称之为“训练”,把将规律应用于新数据这一过程称为“预测”,其中的规律我们称为“模型”。
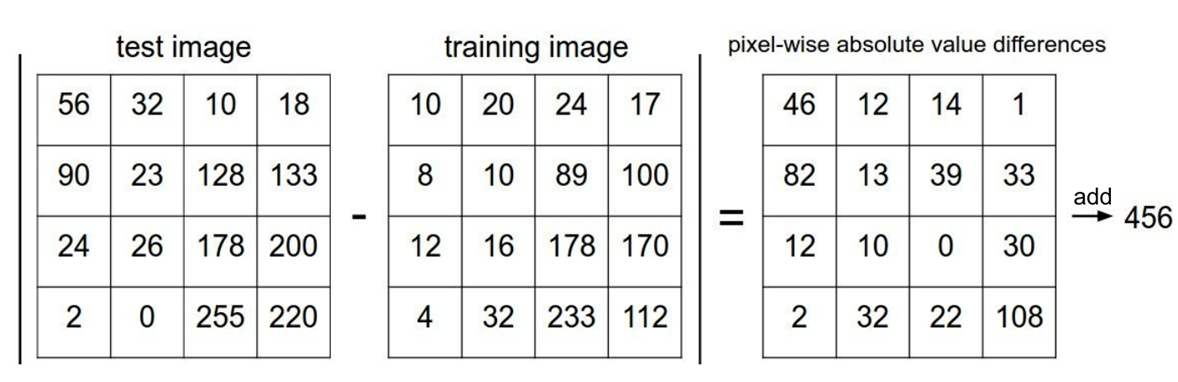
那么我们先从training image图像训练集合中发现一些规律和模型,然后将这些规律应用于新数据test image图像,进行预测,从分类标签集合中找出training image一个分类标签,最后把分类标签分配给该输入图像test image。
图像分类的简单实现
我们在进行线性分类前,先了解一下将会使用到的工具OpenCV
OpenCV是一个用于图像处理、分析、机器视觉方面的开源函数库
该库包含了横跨工业产品检测、医学图像处理、安防、用户界面、摄像头标定、三维成像、机器视觉,该库也包含了比较常用的一些机器学习算法
1.OpenCV的全称是Open Source Computer Vision Library,是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,是一个用于图像处理、分析、机器视觉方面的开源函数库。
2.该库不仅夸平台,跨语言,还包含了横跨工业产品检测、医学图像处理、安防、用户界面、摄像头标定、三维成像、机器视觉,同时包含了比较常用的一些机器学习算法。
环境配置地址:
- Anaconda:https://www.anaconda.com/download/
- Python_whl:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
安装和配置环境
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python==3.4.2.16
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python==3.4.2.16
第一个是Python的第三方库:OpenCV提供的API,用于处理图像相关的方法;第二个是用于图像特征转换的第三方库,这两个是配套使用的,如果我们在安装这些第三方库的时候直接使用:
pip install 库名
那么它会默认按最新版安装,但是由于特征提取算法在近些年有很多的算法包被申请了专利,并不是开源的,所以如果我们不指定版本直接按照默认版安装,后续可能会出现报错。
安装好之后,我们不仅可以在jupyter notebook下使用,也可以在pycharm下使用这个方法,下面就开始进入图像处理的知识。
cv2.imread(filepath,flags)# filepath:要读入图片的完整路径# flags:读入图片的标志# cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道# cv2.IMREAD_GRAYSCALE:读入灰度图片# cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道
#python语言中的OpenCV库的名称是cv2,可以直接import,即;import cv2
#使用函数cv2.imread()读取图片。第一个参数是文件路径;第二个参数指定以什么方式读取:#cv2.IMREAD_COLOR(1):加载彩色图片,这个是默认参数。#cv2.IMREAD_GRAYSCALE(0):以灰度模式加载图片。#cv2.IMREAD_UNCHANGED(-1):包括alpha。# Load input image -- 'table.jpg'
input_file ='D:/ml/flower.jpg'
img = cv2.imread(input_file)
使用函数cv2.imread()读取图片,直接返回numpy.ndarray 对象,通道顺序为BGR ,注意是BGR,通道值默认范围0-255。
使用函数cv2.imshow() 显示图像。窗口会自动调整为图像大小。第一个参数是窗口的名字,其次才是我们的图像。你可以创建多个窗口,只要你喜欢,但是必须给他们不同的名字。
cv2.imshow('image',img1)#也可以直接比较读取到的两张图片的BGR差异:print(img2-img))
CV.waitKey方法
# 使用函数cv2.imshow(wname,img)显示图像,第一个参数是显示图像的窗口的名字,第二个参数是要显示的图像(imread读入的图像),窗口大小自动调整为图片大小import cv2
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()# cv2.waitKey顾名思义等待键盘输入,单位为毫秒,即等待指定的毫秒数看是否有键盘输入,若在等待时间内按下任意键则返回按键的ASCII码,程序继续运行。若没有按下任何键,超时后返回-1。参数为0表示无限等待。不调用waitKey的话,窗口会一闪而逝,看不到显示的图片。
cv2.destroyAllWindow()#销毁所有窗口
cv2.destroyWindow(wname)#销毁指定窗口
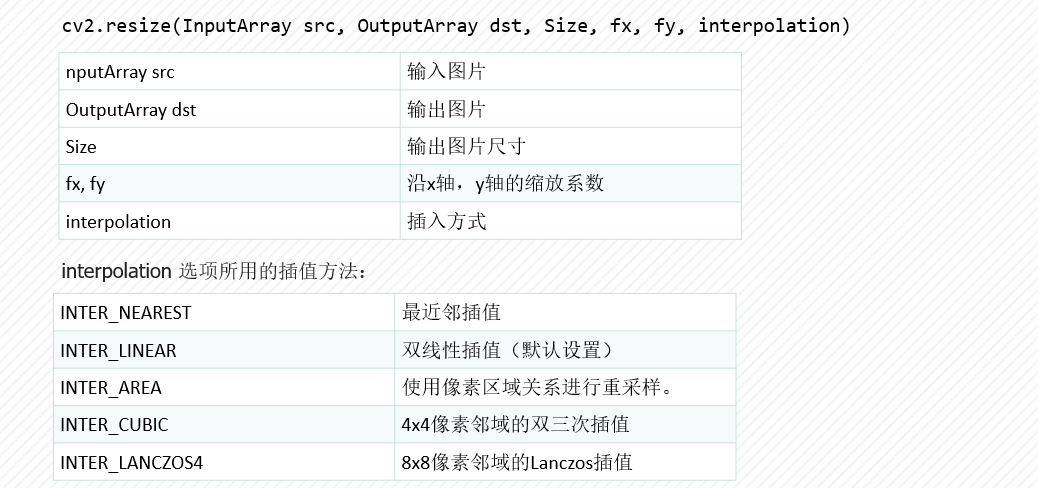
图像缩放
采用插值的思想!
#图片缩放
height, width = img.shape[:2]
size =(int(width*0.3),int(height*0.5))
img= cv2.resize(img, size, interpolation=cv2.INTER_AREA)
cv2.imshow('img_shrink', img)
cv2.waitKey(0)
图像混合
#图像混合(需要图片大小以及通道数一致)
img1 = cv2.imread('lena_small.jpg')
img2 = cv2.imread('opencv-logo-white.png')
res = cv2.addWeighted(img1,0.6, img2,0.4,0)#第一个参数是图像变量,第二个是该图像的权重
src1, src2:需要融合相加的两副大小和通道数相等的图像 alpha:src1的权重 beta:src2的权重
gamma:gamma修正系数,不需要修正设置为0
dst:可选参数,输出结果保存的变量,默认值为None,如果为非None,输出图像保存到dst对应实参中,其大小和通道数与输入图像相同,图像的深度(即图像像素的位数)由dtype参数或输入图像确认
dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如RGB用三个字节表示,则为24位),选默认值None表示与源图像保持一致。
返回值:融合相加的结果图像
CV.imwrite 保存图像
使用函数cv2.imwrite(file,img,num)保存一个图像
第一个参数是要保存的文件名,第二个参数是要保存的图像。可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像的质量,用0 - 100的整数表示,默认95;对于png ,第三个参数表示的是压缩级别。默认为3.
cv2.IMWRITE_JPEG_QUALITY类型为 long ,必须转换成 int
cv2.IMWRITE_PNG_COMPRESSION, 从0到9 压缩级别越高图像越小
cv2.imwrite('./img/1.png',img,[int( cv2.IMWRITE_JPEG_QUALITY),95])
cv2.imwrite('1.png',img,[int(cv2.IMWRITE_PNG_COMPRESSION),9])
CV2.flip
# 使用函数cv2.flip(img,flipcode)翻转图像,flipcode控制翻转效果。# flipcode = 0:沿x轴翻转# flipcode > 0:沿y轴翻转# flipcode < 0:x,y轴同时翻转import cv2
img = cv2.imread('flower.jpg')
imgflip = cv2.flip(img,1)
cv2.imshow(img)
cv2.waitKey(0)
每文一语
开启新的生活!
版权归原作者 王小王-123 所有, 如有侵权,请联系我们删除。