
GPT-3.5
GPT-3.5 系列是一系列模型,从 2021 年第四季度开始就使用文本和代一起进行训练。以下模型属于 GPT-3.5 系列:
- code-davinci-002 是一个基础模型,非常适合纯代码完成任务
- text-davinci-002 是一个基于 code-davinci-002 的 InstructGPT 模型
- text-davinci-003 是对 text-davinci-002 的改进
- gpt-3.5-turbo-0301 是对 text-davinci-003 的改进,针对聊天进行了优化
InstructGPT
以 3 种不同方式训练的 InstructGPT 模型变体:
训练方法模型模型名字SFT
监督微调人类示范 davinci-instruct-beta1
davinci-instruct-beta
1FeedME
对人工编写的演示和模型样本进行监督微调,这些模型样本被人工标注者在总体质量得分上评分为 7/7
text-davinci-001
,
text-davinci-002
,
text-curie-001
,
text-babbage-001
PPO
使用人类比较训练的奖励模型进行强化学习
text-davinci-003
SFT 和 PPO 模型的训练与 InstructGPT 论文中的模型类似。 FeedME(“feedback made easy”的缩写)模型是通过从我们所有的模型中提取最佳完成度来训练的。我们的模型通常在训练时使用最佳可用数据集,因此使用相同训练方法的不同引擎可能会在不同数据上进行训练。
ChatGPT
ChatGPT和InstructGPT是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。
OpenAI 官网
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
其实GPT-3.5-turbo* 就是ChatGPT的模型的名字。

OpenAI相关研究论文
这些是我们今天在 API 中提供的研究论文中最接近的模型。请注意,并非 API 中可用的所有模型都对应于一篇论文,即使对于下面列出的模型,也可能存在细微差异,无法准确复制论文。
论文发表时间在论文中的模型名字在API中模型的名字参数数量[2005.14165] Language Models are Few-Shot Learners22 Jul 2020GPT-3 175Bdavinci175BGPT-3 6.7Bcurie6.7BGPT-3 1Bbabbage1B[2107.03374] Evaluating Large Language Models Trained on Code14 Jul 2021Codex 12Bcode-cushman-001312B[2201.10005] Text and Code Embeddings by Contrastive Pre-Training14 Jan 2022GPT-3 unsupervised cpt-text 175Btext-similarity-davinci-001175BGPT-3 unsupervised cpt-text 6Btext-similarity-curie-0016BGPT-3 unsupervised cpt-text 1.2BNo close matching model on API1.2B[2009.01325] Learning to summarize from human feedback15 Feb 2022GPT-3 6.7B pretrainNo close matching model on API6.7BGPT-3 2.7B pretrainNo close matching model on API2.7BGPT-3 1.3B pretrainNo close matching model on API1.3B[2203.02155] Training language models to follow instructions with human feedback4 Mar 2022InstructGPT-3 175B SFTdavinci-instruct-beta175BInstructGPT-3 175BNo close matching model on API175BInstructGPT-3 6BNo close matching model on API6BInstructGPT-3 1.3BNo close matching model on API1.3B
其它
强化学习
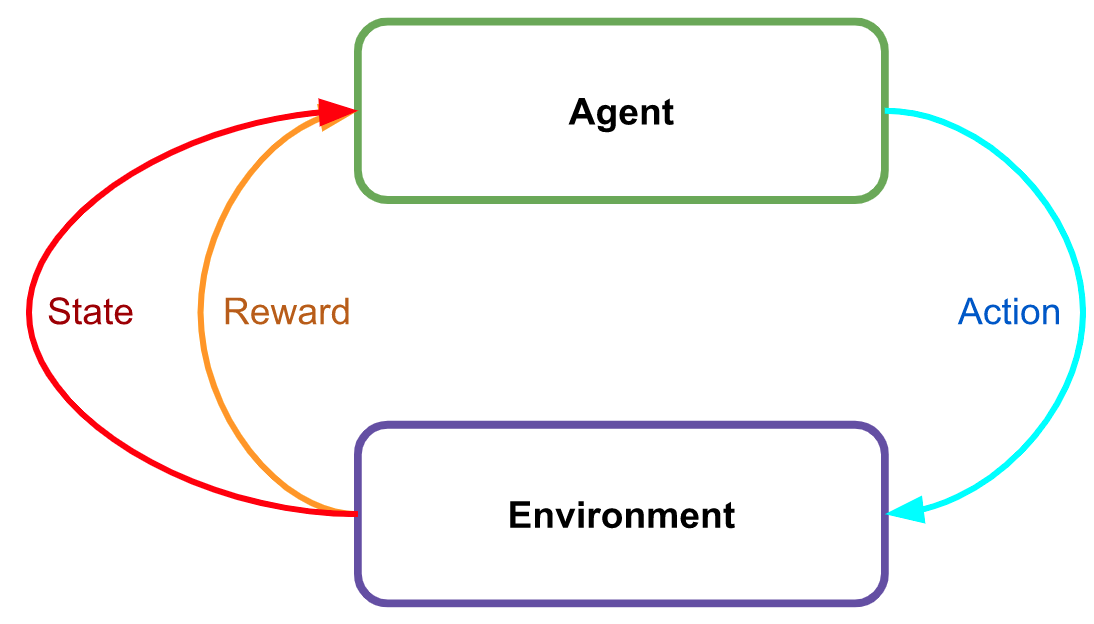
通常,强化学习看起来像这样。 环境会为每个动作产生奖励
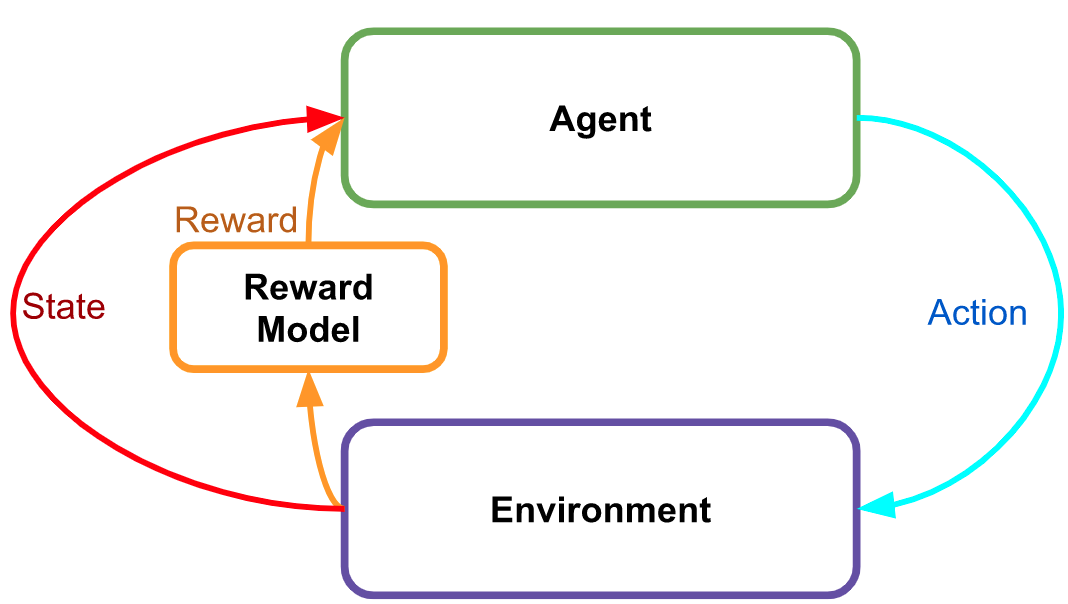
InstructGPT
版权归原作者 茫茫人海一粒沙 所有, 如有侵权,请联系我们删除。